03 数组与链表:存储设计的基石有哪些? 你好,我是丁威。
从这节课开始,我们就要进行基础篇的学习了。想要熟练使用中间件解决各种各样的问题,首先需要掌握中间件的基础知识。
我认为,中间件主要包括如下三方面的基础:数据结构、JUC 和 Netty,接下来的两节课,我们先讲数据结构。
数据结构主要解决的是数据的存储方式问题,是程序设计的基座。
按照重要性和复杂程度,我选取了数组和链表、键值对 (HashMap)、红黑树、LinkedHashMap 和 PriorityQueue 几种数据结构重点解析。其中,数组与链表是最底层的两种结构,是后续所有数据结构的基础。
我会带你分析每种结构的存储结构、新增元素和搜索元素的方式、扩容机制等,让你迅速抓住数据结构底层的特性。当然,我还会结合一些工业级实践,带你深入理解这些容器背后蕴含的设计理念。
说明一下,数据结构其实并不区分语言,但为了方便阐述,这节课我主要基于 Java 语言进行讲解。
数组
我们先来看下数组。
数组是用于储存多个相同类型数据的集合,它具有顺序性,并且也要求内存空间必须连续。高级编程语言基本都会提供数组的实现。
为了更直观地了解数组的内存布局,我们假设从操作系统申请了 128 字节的内存空间,它的数据结构可以参考下面这张图:
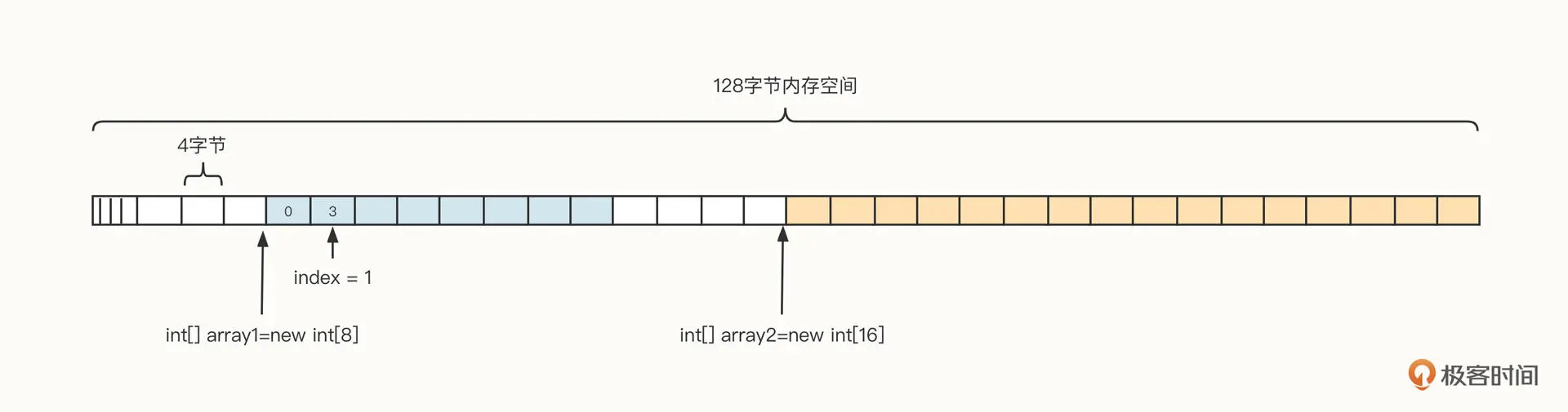
结合这张图我们可以看到,在 Java 中,数组通常包含下面几个部分。
- 引用:每一个变量都会在栈中存储数组的引用,我们可以通过引用对数组进行操作,对应上图的 array1、array2。
- 容量:数组在创建时需要指定容量,一旦创建,无法修改,也就是说,数组并不能自动扩容。
- 下标:数组可以通过下标对数组中的元素进行随机访问,例如 array1[0]表示访问数组中的第一个元素,下标从 0 开始,其最大值为容量减一。
在后面的讲解中,你能看到很多数据结构都是基于数组而构建的。
那么数组有哪些特性呢?这里我想介绍两个我认为最重要的点:内存连续性和随机访问效率高。
我们先来看下内存连续性。
内存连续性的意思是,数组在向操作系统申请内存时,申请的必须是连续的内存空间。我们还是继续用上面这个例子做说明。我们已经创建了 array1、array2 两个数组,如果想要再申请一个拥有五个 int 元素的数组,能把这五个元素拆开,分别放在数组 1 的前面和后面吗?你可以看看下面这张示意图。
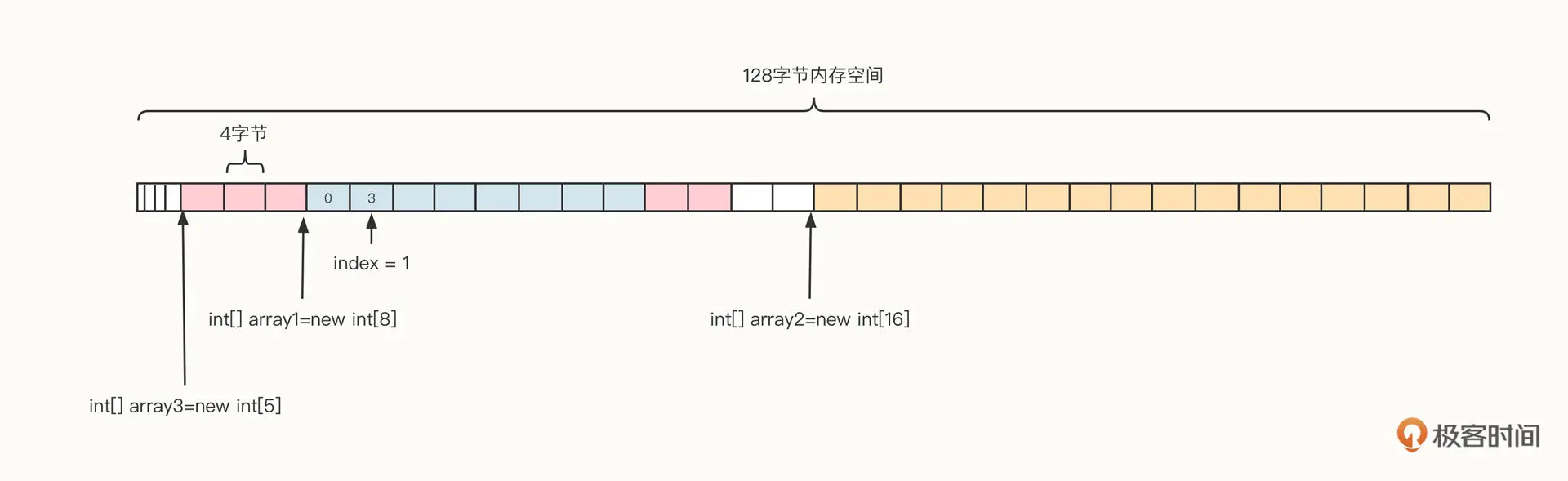
答案当然是不可以。
虽然当前内存中剩余可用空间为 32 个字节,乍一看上去有充足的内存。但是,因为不存在连续的 20 字节的空间,所以不能直接创建 array3。
当我们想要创建 20 字节长度的 array3 时,在 Java 中会触发一次内存回收,如果垃圾回收器支持整理特性,那么垃圾回收器对内存进行回收后,我们就可以得到一个新的布局:
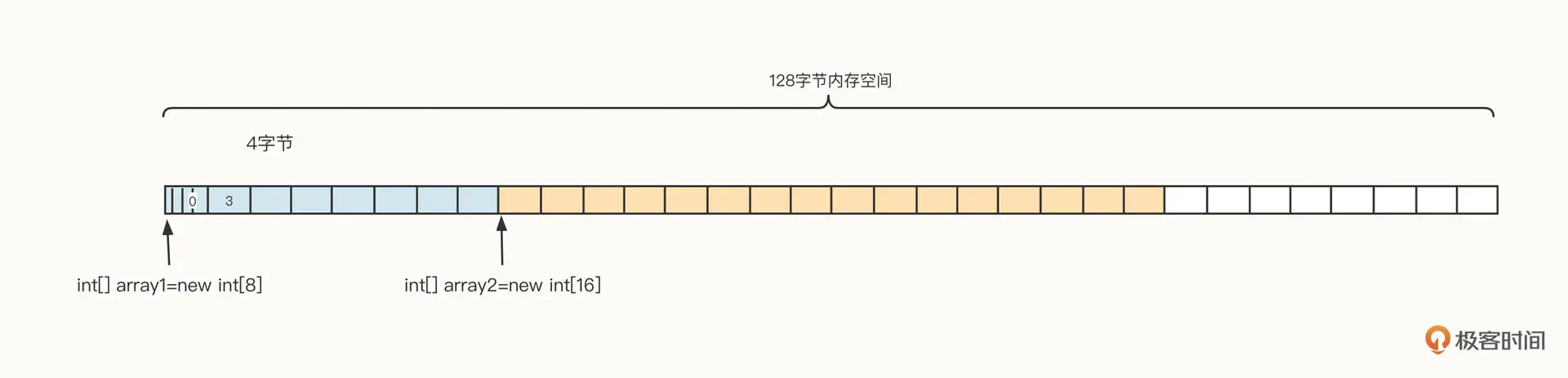
经过内存整理后就能创建数组 3 了。也就是说,如果内存管理不当,确实容易产生内存碎片,从而影响性能。
那我们为什么要把内存设计为连续的呢?换句话说,连续内存有什么好处呢?
这就不得不提到数组一个无可比拟的优势了:数组的随机访问性能极好。连续内存确保了地址空间的连续性,寻址非常简单高效。
举个例子,我们创建一个存放 int 数据类型的数组,代码如下: int[] array1 = new int[10];
然后我们看下 JVM 中的布局:
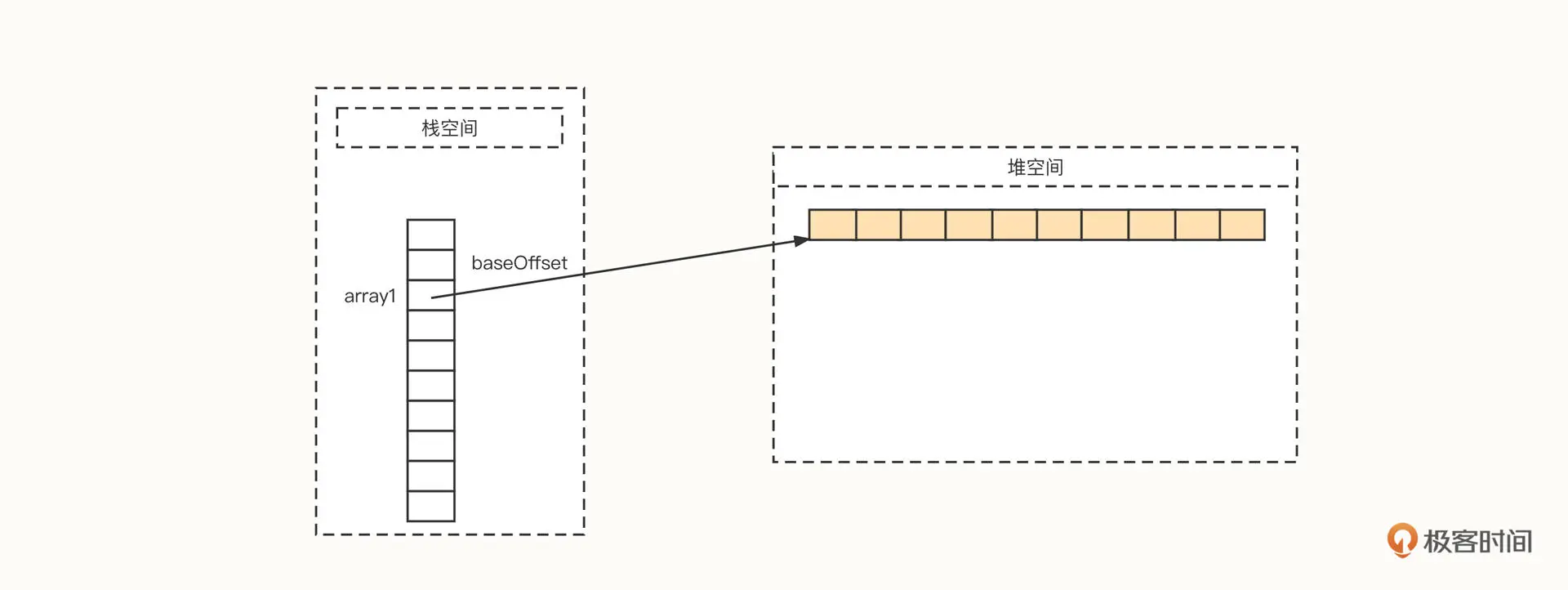
可以看到,首先内存管理器在栈空间会分配一段空间,用它存储数组在物理内存的起始地址,这个起始地址我们用 baseOffset 表示。如果是 64 位操作系统,默认一个变量使用 8 字节,如果采用了指针压缩技术,可以减少到 4 字节。
数组能够高效地随机访问数组中的元素,主要原因是它能够根据下标快速计算出真实的物理地址,寻找算法为“baseOffset + index /* size”。
其中,size 为数组中单个元素的长度,是一个常量。在上面这个数组中,存储的元素是 int 类型的数据,所以 size 为 4。因此,我们根据数组下标就可以迅速找到对应位置存储的数据。
数组这种高效的访问机制在中间件领域有着非常广泛的应用,大名鼎鼎的消息中间件 RocketMQ 在它的文件设计中就灵活运用了这个特性。
RocketMQ 为了追求消息写入时极致的顺序写,会把所有主题的消息全部顺序写入到 commitlog 文件中。也就是说,commitlog 文件中混杂着各个主题的消息,但消息消费时,需要根据主题、队列、消费位置向消息服务器拉取消息。如果想从 commitlog 文件中读取消息,则需要遍历 commitlog 文件中的所有消息,检索性能非常低下。
一开始,为了提高检索效率,RocketMQ 引入了 ConsumeQueue 文件,可以理解为 commitlog 文件按照主题创建索引。
为了在消费端支持消息按 tag 进行消息过滤,索引数据中需要包含消息的 tag 信息,它的数据类型是 String,索引文件遵循{topic}/{queueId},也就是按照主题、队列两级目录存储。单个索引文件的存储结构设计如下图所示:
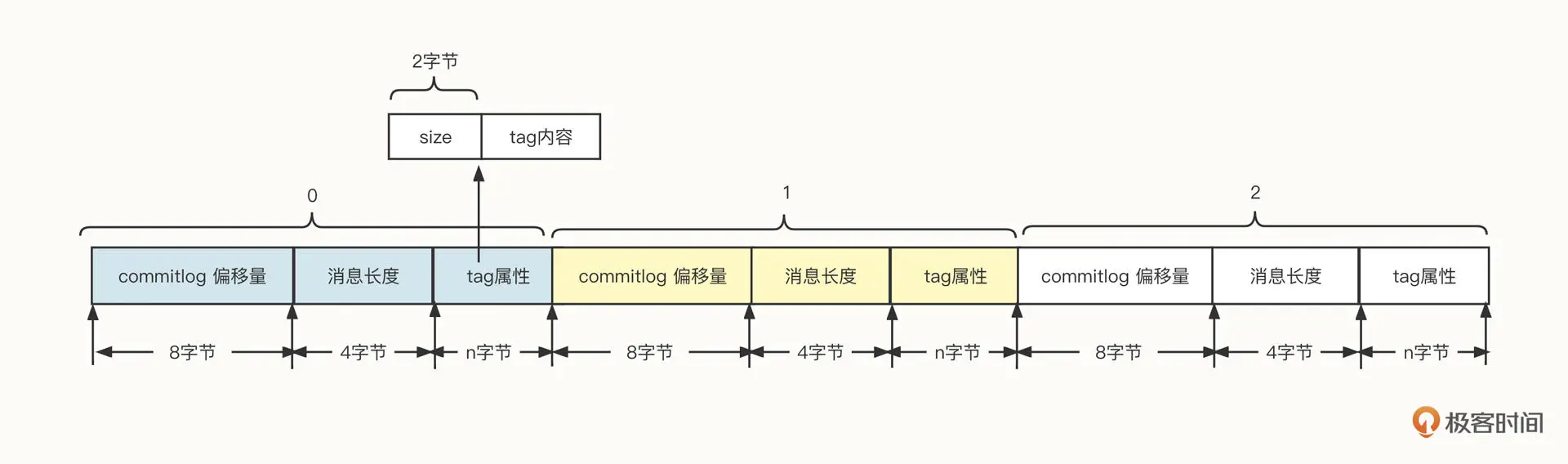
索引文件中,每一条消息都包含偏移量、消息长度和 tag 内容 3 个字段。
- commitlog 偏移量
可以根据该值快速从 commitlog 文件中找到消息,这也是索引文件的意义。
- 消息长度
消息的长度,知道它可以方便我们快速提取一条完整的消息。
- tag 内容
由于消息的 tag 是由用户定义的,例如 tagA、createorder 等,它的长度可变。在文件存储领域,一般存储可变长的数据,通常会采用“长度字段 + 具体内容”的存储方式。其中用来存储内容的长度使用固定长度,它是用来记录后边内容的长度。
回到消息消费这个需求,我们根据主题、消费组,消息位置 (队列中存储的第 N 条消息),能否快速找到消息呢?例如输入 topic:order_topic、queueId:0,offset:2,能不能马上找到第 N 条消息?
答案是可以找到,但不那么高效。原因是,我们根据 topic、queueid,能非常高效地找到对应的索引文件。我们只需要找到对应的 topic 文件夹,然后在它的子目录中找到对应的队列 id 文件夹就可以了。但要想从索引文件中找到具体条目,我们还是必须遍历索引文件中的每一个条目,直到到达 offset 的条目,才能取出对应的 commitlog 偏移量。
那是否有更高效的索引方式呢?
当然有,我们可以将每一个条目设计成固定长度,然后按照数组下标的方式进行检索。
为了实现每一个条目定长,我们在这里不存储 tag 的原始字符串,而是存储原始字符串的 hashCode,这样就可以确保定长了。你可以看看下面这张设计图:
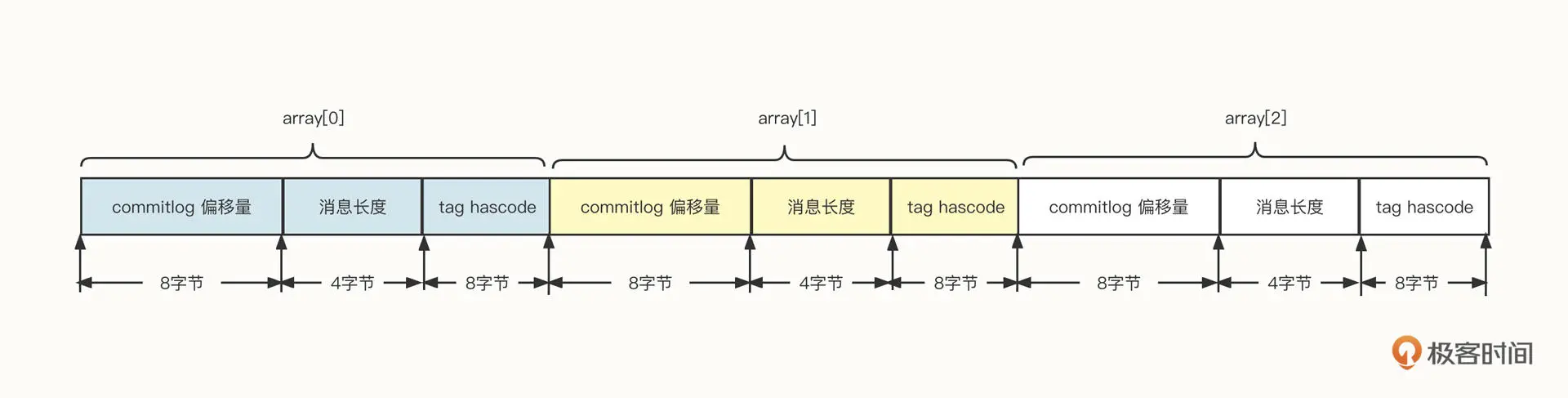
基于这种设计,如果给定一个 offset,我们再想快速提取一条索引就变得非常简单了。
首先,根据 offset /* 20(每一个条目的长度),定位到需要查找条目的起始位置,用 startOffset 表示。
然后,从 startOffset 位置开始读取 20 个字节的长度,就可以得到物理偏移量、消息长度和 tag 的 hashCode 了。
接着,我们可以通过 hashCode 进行第一次过滤,如果遇到 hash 冲突,就让客户端再根据消息的 tag 字符串精确过滤一遍。
这种方式,显然借鉴了数组高效访问数据的设计理念,是数组实现理念在文件存储过程中的经典运用。
总之,正是由于数组具有内存连续性,具有随机访问的特性,它在存储设计领域的应用才非常广泛,我们后面介绍的 HashMap 也引入了数组。
ArrayList
不过,数组从严格意义上来说是面向过程编程中的产物,而 Java 是一门面向对象编程的语言,所以,直接使用数组容易破坏面向对象的编程范式,故面向对象编程语言都会对数组进行更高级别的抽象,在 Java 中对应的就是 ArrayList。
我会从数据存储结构、扩容机制、数据访问特性三个方面和你一起来探究一下 ArrayList。
首先我们来看一下 ArrayList 的底层存储结构,你可以先看下这个示意图:

从图中可以看出,ArrayList 的底层数据直接使用了数组,是对数组的抽象。
ArrayList 相比数组,增加了一个特性,它支持自动扩容。其扩容机制如下图所示:
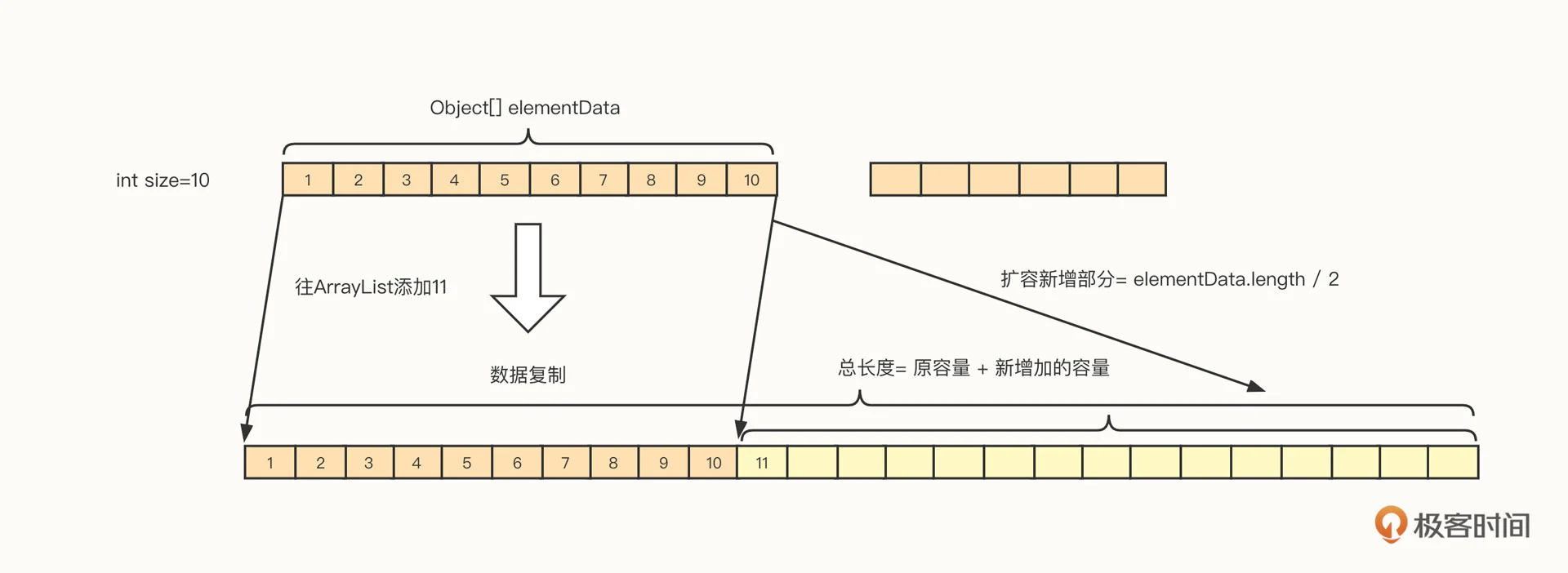
扩容的实现有三个要点。
- 扩容后的容量 = 原容量 +(原容量)/ 2,以 1.5 倍进行扩容。
- 内部要创建一个新的数组,数组长度为扩容后的新长度。
- 需要将原数组中的内容拷贝到新的数组,即扩容过程中存在内存复制等较重的操作。
注意,只在当前无剩余空间时才会触发扩容。在实际的使用过程中,我们要尽量做好容量评估,减少扩容的发生。因为扩容的成本还是比较高的,存储的数据越多,扩容的成本越高。
接下来,我们来看一下 ArrayList 的数据访问特性。
- 顺序添加元素的效率高
ArrayList 顺序添加元素,如果不需要扩容,直接将新的数据添加到 elementData[size]位置,然后 size 加一即可(其中,size 表示当前数组中存储的元素个数)。
ArrayList 添加元素的时间复杂度为 O(1),也就是说它不会随着存储数据的大小而改变,是非常高效的存储方式。
- 中间位置插入 / 删除元素的效率低
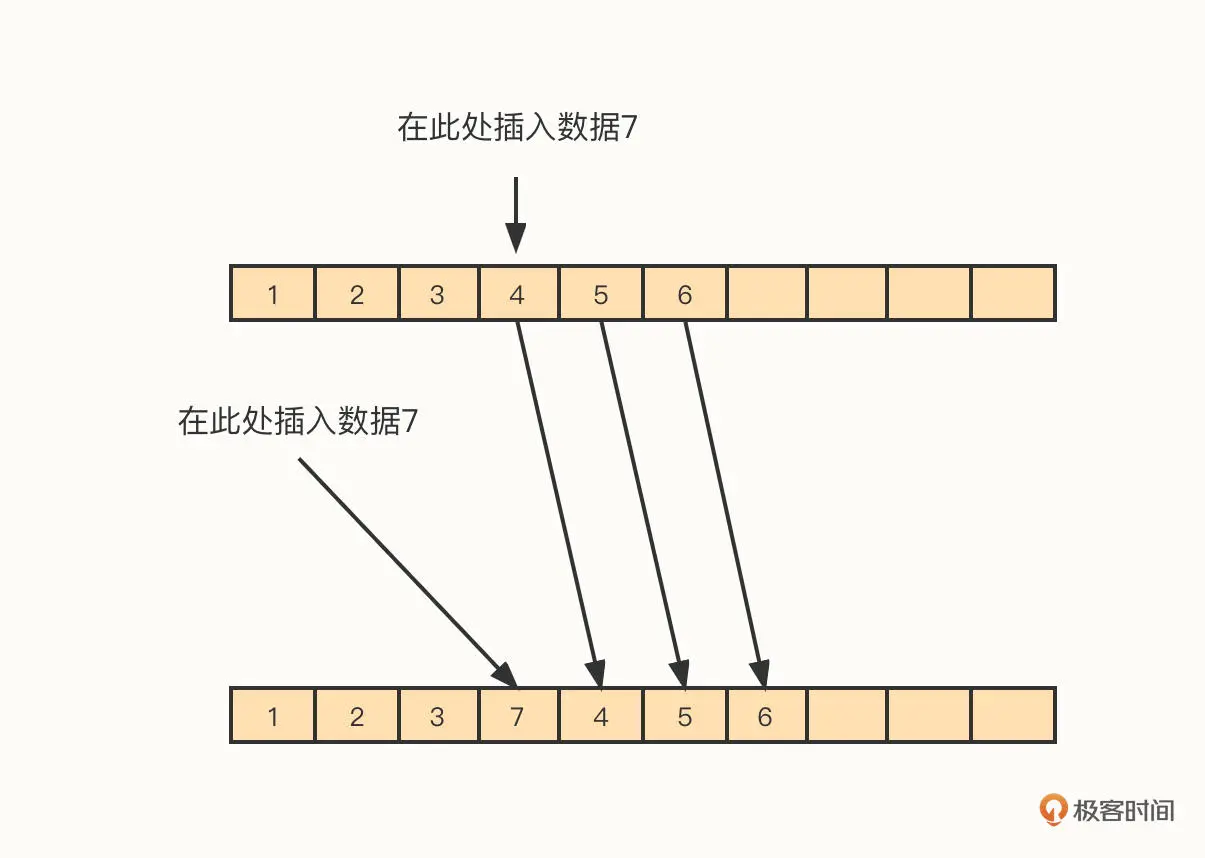
在插入元素时,我们将需要插入数据的下标用 index 表示,将 index 之后的依次向后移动 (复制到 index + 1),然后将新数据存储在下标 index 的位置。
删除操作与插入类似,只是一个数据是往后移,而删除动作是往前移。
ArrayList 在中间位置进行删除的时间复杂度为 O(n),这是一个比较低效的操作。
- 随机访问性能高
由于 ArrayList 的底层就是数组,因此它拥有高效的随机访问数据特性。
LinkedList
除了 ArrayList,在数据结构中,还有一种也很经典的数据结构:链表。LinkedList 就是链表的具体实现。
我们先来看一下 LinkedList 的底层存储结构,最后再对比一下它和 ArrayList 的差异。
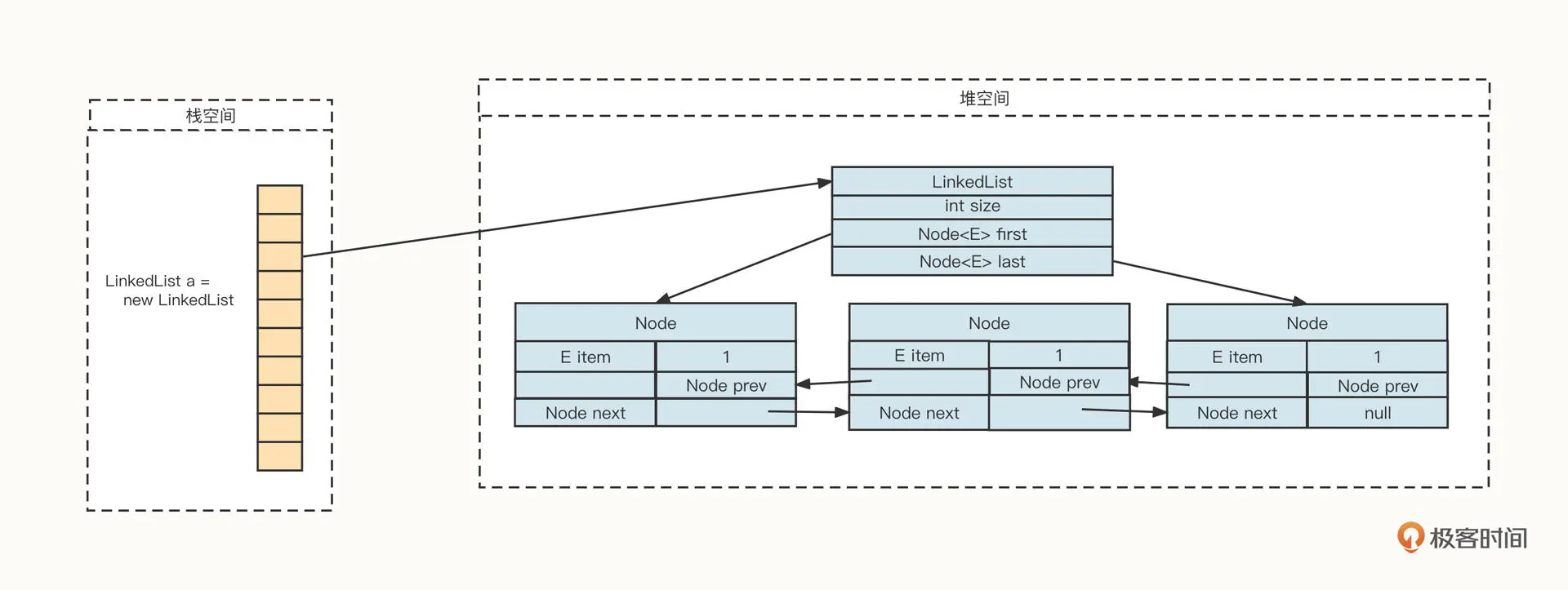
从上面这张图你可以看到,一个 LinkedList 对象在内存中通常由两部分组成:LinkedList 对象和由 Node 节点组成的链条。
一个 LinkedList 对象在内存中主要包含 3 个字段。
- int size:链表中当前存在的 Node 节点数,主要用来判断是否为空、判断随机访问位点是否存在;
- Node first:指向链表的头节点;
- Node last:指向链表的尾节点。
再来说说由 Node 节点组成的链条。Node 节点用于存储真实的数据,并维护两个指针。分别解释一下。
- E item:拥有存储用户数据;
- Node prev:前驱节点,指向当前节点的前一个指针;
- Node last:后继节点,指向当前节点的下一个节点。
由这两部分构成的链表具有一个非常典型的特征:内存的申请无须连续性。这就减少了内存申请的限制。
接下来我们来看看如何操作链表。对于链表的操作主要有两类,一类是在链表前后添加或删除节点,一类是在链表中间添加或删除数据。
当你想要在链表前后添加或删除节点时,因为我们在 LinkedList 对象中持有链表的头尾指针,可以非常快地定位到头部或尾部节点。也就是说,这时如果我们想要增删数据,都只需要更新相关的前驱或后继节点就可以了,具体操作如下图所示:
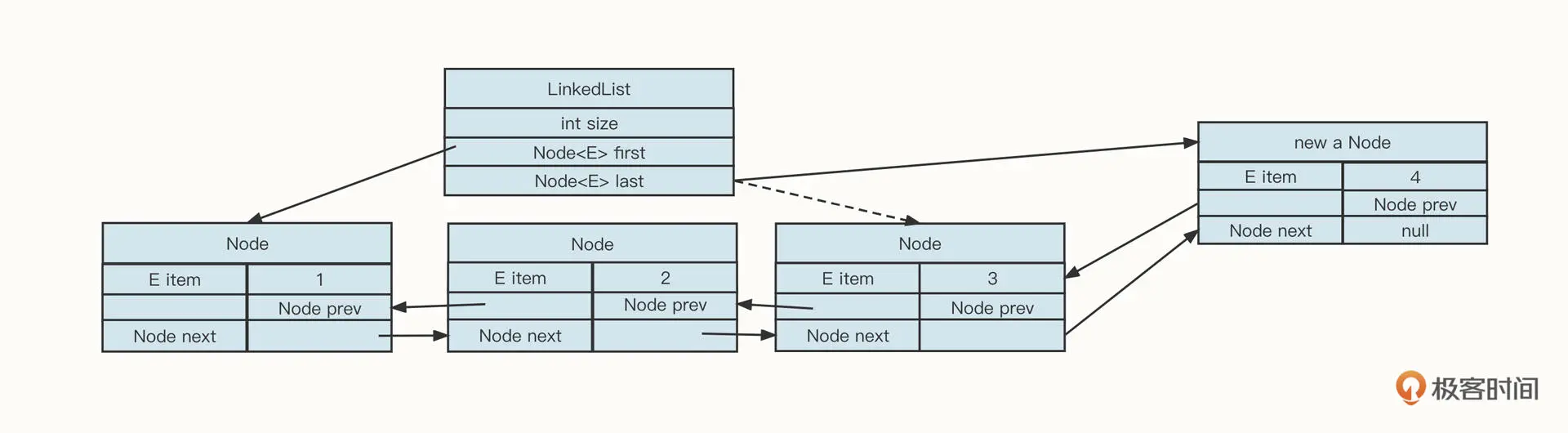
举个例子,如果我们向尾部节点添加节点,它的代码是这样的: Node oldLastNode = list.last; //添加数据之前原先的尾部节点 Node newNode = new Node(); newNode.item = 4;//设置用户的值 oldLastNode.next = newNode; // 将原先尾部节点的next指针更新为新添加的节点 newNode.prev = oldLastNode; // 新添加的节点的prev指向源尾部节点,通过这两步,使新加入的节点添加到链表中 list.last = newNode; // 更新LinkedList的尾部节点为新添加节点
在链表的尾部、头部添加和删除数据,时间复杂度都是 O(1),比 ArrayList 在尾部添加节点效率要高。因为当 ArrayList 需要扩容时,会触发数据的大量复制,而 LinkedList 是一个无界队列,不存在扩容问题。
如果要在链表的中间添加或删除数据,我们首先需要遍历链表,找到操作节点。因为链表是非连续内存,无法像数组那样直接根据下标快速定位到内存地址。
例如,在下标 index 为 1 的后面插入新的数据,它的操作示例图如下:
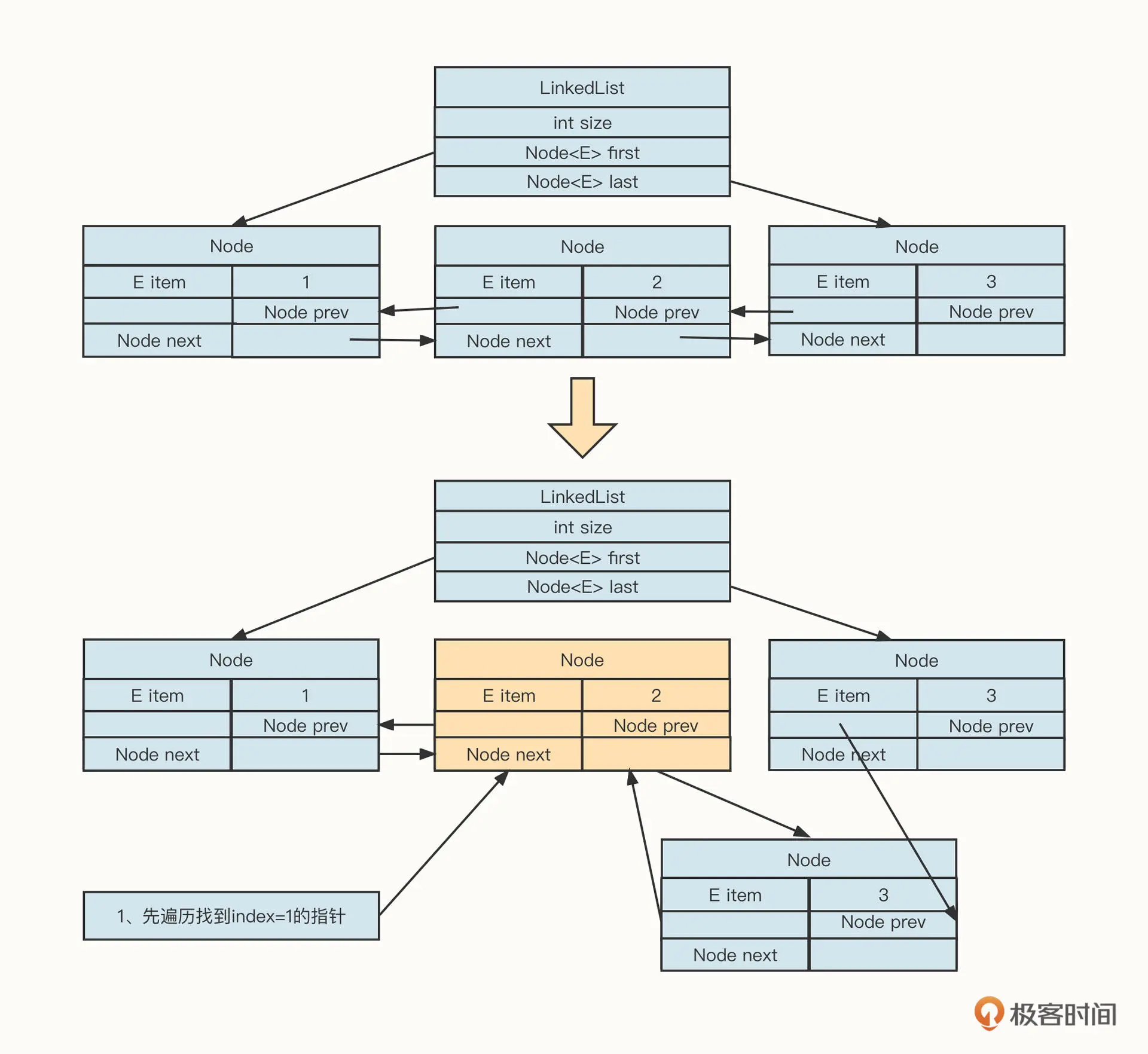
我们从上往下看。插入新节点的第一步是需要从头节点开始遍历,找到下标为 i=1 的节点,然后在该节点的后面插入节点,最后执行插入节点的逻辑。
插入节点的具体实现主要是为了维护链表中相关操作节点的前驱与后继节点。
遍历链表、查询操作节点的时间复杂度为 O(n),然后基于操作节点进行插入与删除动作的时间复杂度为 O(1)。
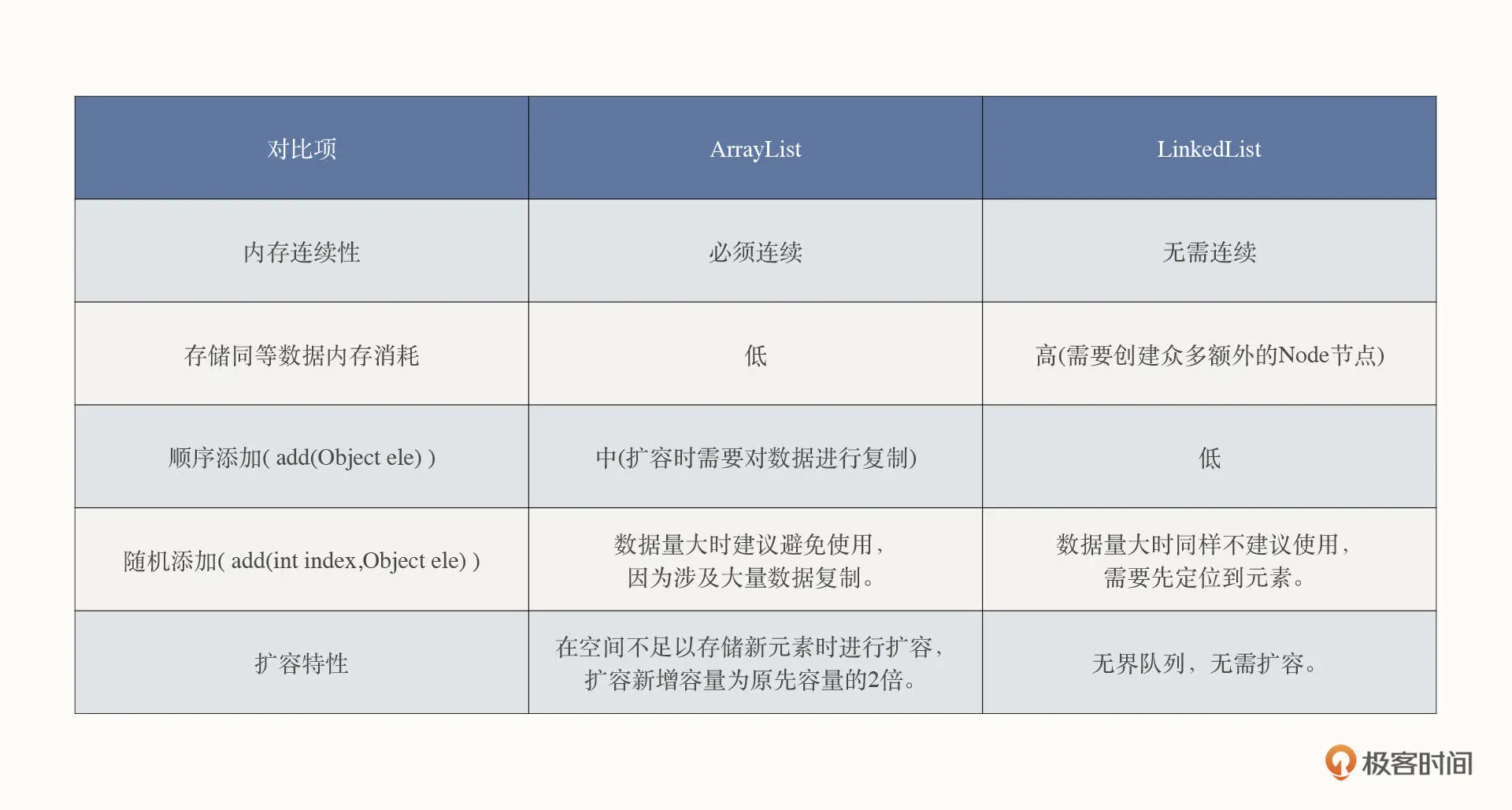
关于链表的知识点就讲到这里。由于链表与数组是数据结构中两种最基本的存储结构,为了让你更直观地了解二者的差异,我也给你画了一个表格,对两种数据结构做了对比:
HashMap
无论是链表还是数组都是一维的,在现实世界中有一种关系也非常普遍:关联关系。关联关系在计算机领域主要是用键值对来实现,HashMap 就是基于哈希表 Map 接口的具体实现。
JDK1.8 版本之前,HashMap 的底层存储结构如下图所示:
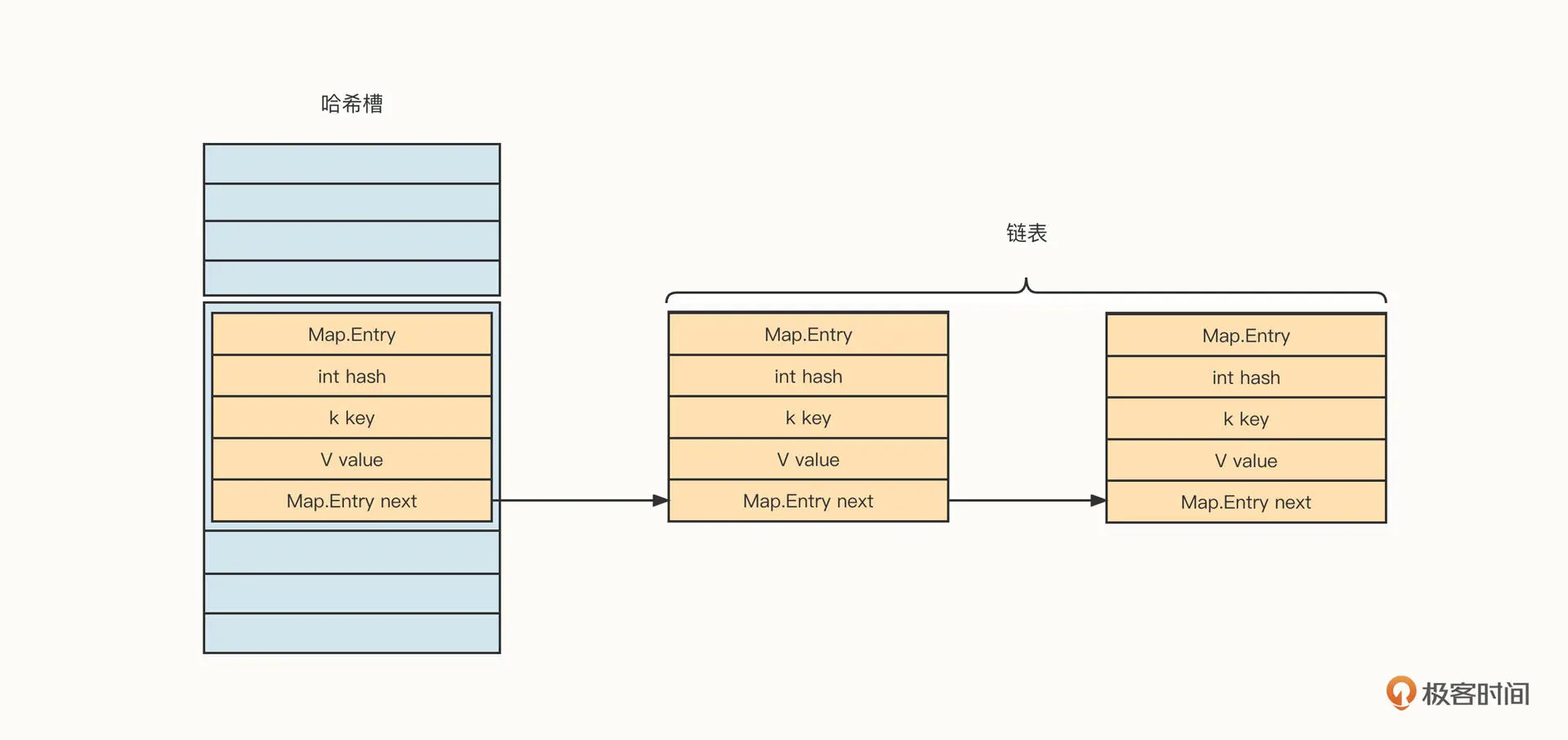
HashMap 的存储结构主体是哈希槽与链表的组合,类似一个抽屉。
我们向 HashMap 中添加一个键值对,用这个例子对 HashMap 的存储结构做进一步说明。
HashMap 内部持有一个 Map.Entry[]的数组,俗称哈希槽。当我们往 HashMap 中添加一个键值对时,HashMap 会根据 Key 的 hashCode 与槽的总数进行取模,得出槽的位置 (也就是数组的下标),然后判断槽中是否已经存储了数据。如果未存储数据,则直接将待添加的键值对存入指定的槽;如果槽中存在数据,那就将新的数据加入槽对应的链表中,解决诸如哈希冲突的问题。
在 HashMap 中,单个键值对用一个 Map.Entry 结构表示,具体字段信息如下。
- K key:存储的 Key,后续可以用该 Key 进行查找
- V value:存储的 Value;
- int hash:Key 的哈希值;
- Ma.Entry :next 链表。
到这里,你可以停下来思考一下,当哈希槽中已经存在数据时,新加入的元素是存储在链表的头部还是尾部呢?
答案是放在头部。代码如下: //假设新放入的槽位下标用 index 表示,哈希槽用 hashArray 表示 Map.Entry newEntry = new Map.Entry(key,value); newEntry.next = hashArray[index]; hashArray[index] = newEntry;
我们将新增加的元素放到链表的头部,也就是直接放在哈希槽中,然后用 next 指向原先存在于哈希槽中的元素。
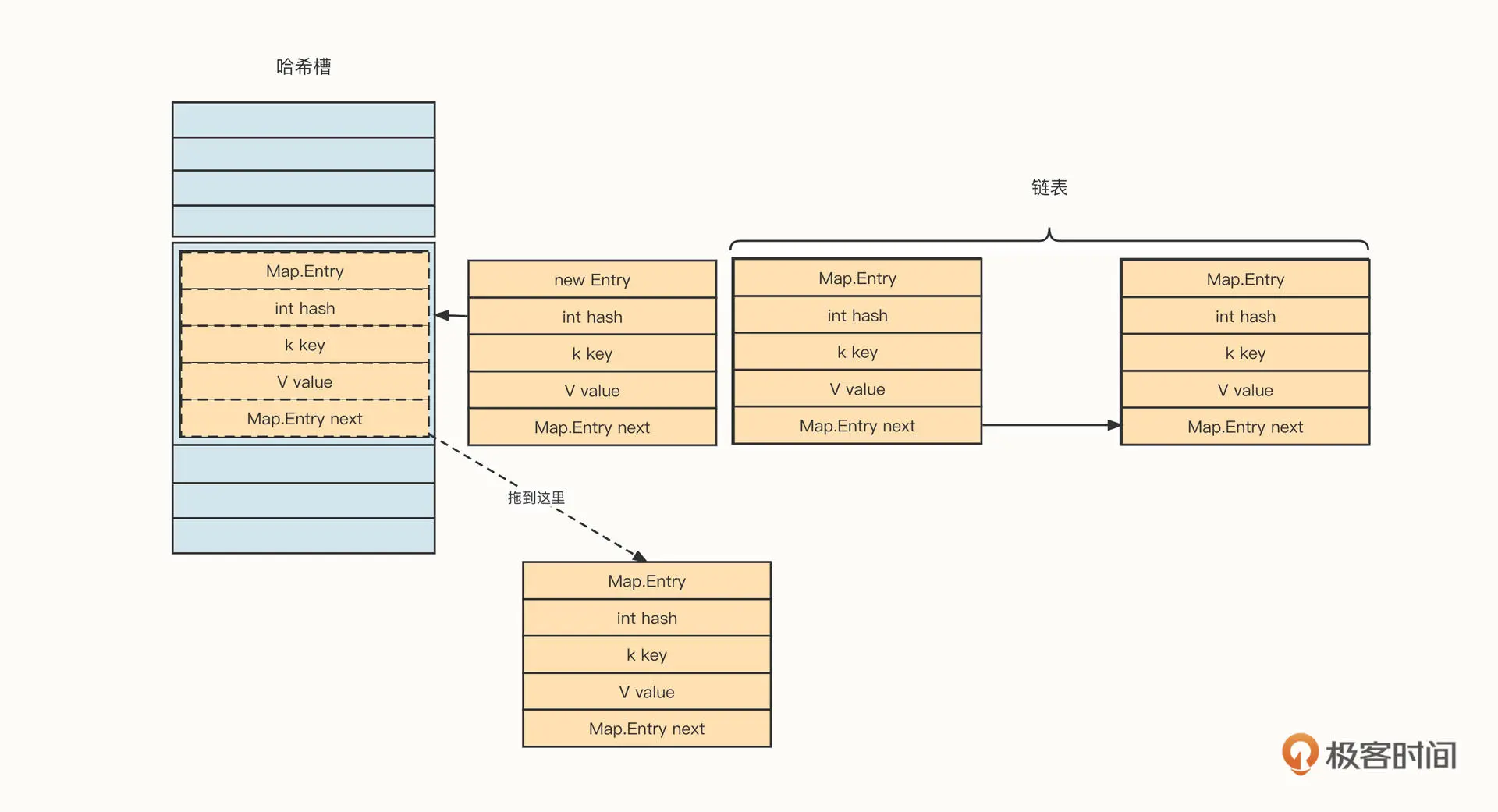
这种方式的妙处在于,只涉及两个指针的修改。如果我们把新增加的元素放入链表的头部,链表的复杂度为 O(1)。相反,如果我们把新元素放到链表的尾部,那就需要遍历整条链表,写入复杂度会有所提高,随着哈希表中存储的数据越来越多,那么新增数据的性能将随着链表长度的增加而逐步降低。
介绍完添加元素,我们来看一下元素的查找流程,也就是如何根据 Key 查找到指定的键值对。
首先,计算 Key 的 hashCode,然后与哈希槽总数进行取模,得到对应哈希槽下标。
然后,访问哈希槽中对应位置的数据。如果数据为空,则返回“未找到元素”。如果哈希槽对应位置的数据不为空,那我们就要判断 Key 值是否匹配了。如果匹配,则返回当前数据;如果不匹配,则需要遍历哈希槽,如果遍历到链表尾部还没有匹配到任何元素,则返回“未找到元素”。
说到这里,我们不难得出这样一个结论:如果没有发生哈希槽冲突,也就是说如果根据 Key 可以直接命中哈希槽中的元素,数据读取访问性能非常高。但如果需要从链表中查找数据,则性能下降非常明显,时间复杂度将从 O(1) 提升到 O(n),这对查找来说就是一个“噩梦”。
一旦出现这种情况,HashMap 的结构会变成下面这个样子:
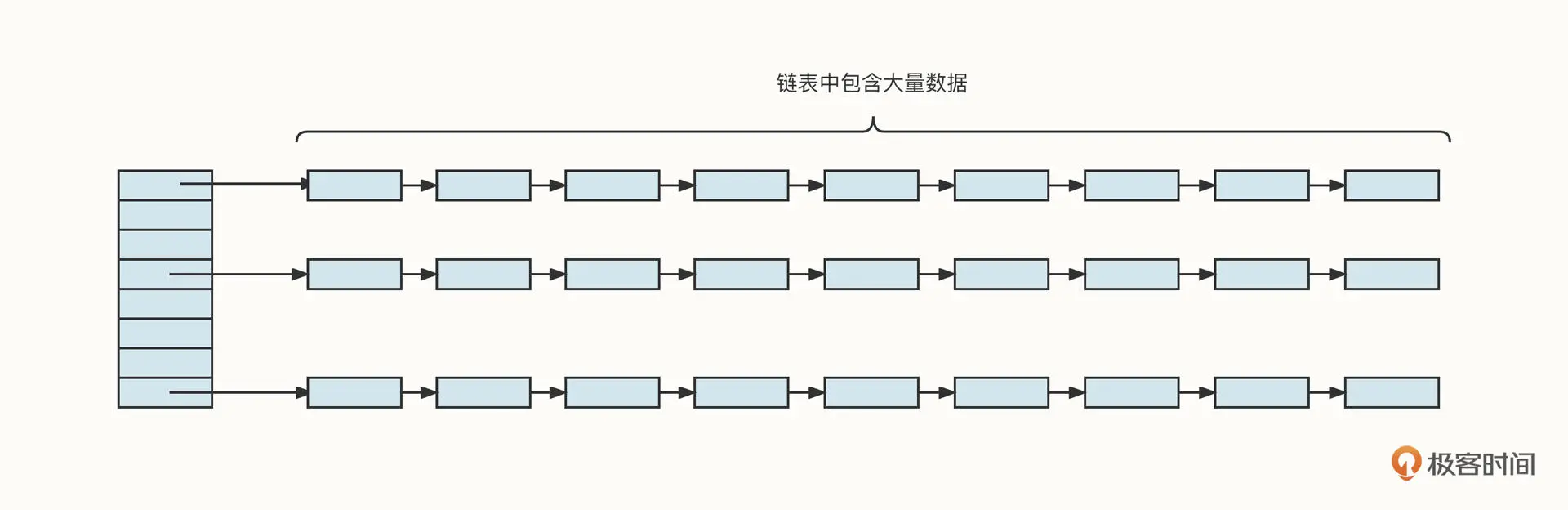
怎么解决这个问题呢?JDK 的设计者们给出了两种优化策略。
第一种,对 Hash 槽进行扩容,让数据尽可能分布到哈希槽上,但不能解决因为哈希冲突导致的链表变长的问题。
第二种,当链表达到指定长度后,将链表结构转换为红黑树,提升检索性能 (JDK8 开始引入)。
我们先来通过源码深入探究一下 HashMap 的扩容机制。HashMap 的扩容机制由 resize 方法实现,该方法主要分成两个部分,上半部分处理初始化或扩容容量计算,下半部分处理扩容后的数据复制 (重新布局)。
上半部分的具体源码如下: /// /* Initializes or doubles table size. If null, allocates in /* accord with initial capacity target held in field threshold. /* Otherwise, because we are using power-of-two expansion, the /* elements from each bin must either stay at same index, or move /* with a power of two offset in the new table. /* /* @return the table // final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap « 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr « 1; // double threshold } else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; else { // zero initial threshold signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR / DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { float ft = (float)newCap /* loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({“rawtypes”,”unchecked”}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; //此处省略数据复制相关代码 }
为了方便你对代码进行理解,我画了一个与之对应的流程图:
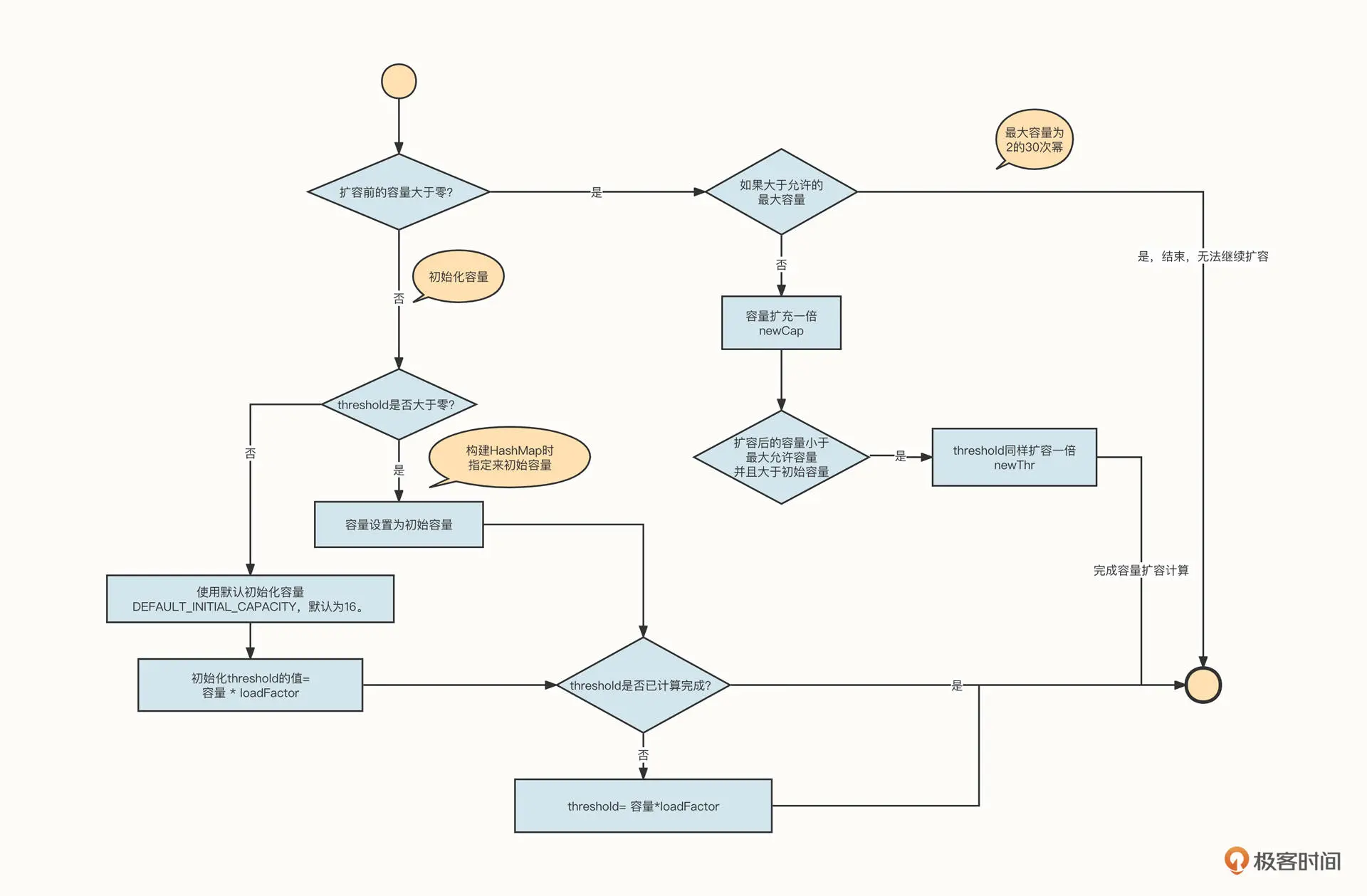
总结一下扩容的要点。
- HashMap 的容量并无限制,但超过 2 的 30 次幂后不再扩容哈希槽。
- 哈希槽是按倍数扩容的。
- HashMap 在不指定容量时,默认初始容量为 16。
HashMap 并不是在无容量可用的时候才扩容。它会先设置一个扩容临界值,当 HashMap 中的存储的数据量达到设置的阔值时就触发扩容,这个阔值用 threshold 表示。
我们还引入了一个变量 loadFactor 来计算阔值,阔值 = 容量 /*loadFactor。其中,loadFactor 表示加载因子,默认为 0.75。
加载因子的引入与 HashMap 哈希槽的存储结构与存储算法有关。
HashMap 在出现哈希冲突时,会引入一个链表,形成“数组 + 链表”的存储结构。这带来的效果就是,如果 HashMap 有 32 个哈希槽,当前存储的数据也刚好有 32 个,这些数据却不一定全会落在哈希槽中,因为可能存在 hash 值一样但是不同 Key 的数据,这时,数据就会进入到链表中。
前面我们也提到过,数据放入链表就容易引起查找性能的下降,所以,HashMap 的设计者为了将数据尽可能地存储到哈希槽中,会提前进行扩容,用更多的空间换来检索性能的提高。
我们再来看一下扩容的下半部分代码。
我们先来看下这段代码: @SuppressWarnings({“rawtypes”,”unchecked”}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } }
这段代码不难理解,就是按照扩容后的容量创建一个新的哈希槽数组,遍历原先的哈希槽 (数组),然后将数据重新放入到新的哈希槽中,为了保证链表中数据的顺序性,在扩容时采用尾插法。
除了扩容,JDK8 之后的版本还有另外一种提升检索能力的措施,那就是在链表长度超过 8 时,将链表演变为红黑树。这时的时间复杂度为 O(2lgN),可以有效提升效率。
关于红黑树,我会在下节课详细介绍。
总结
这节课,我们介绍了数组、ArrayList、LinkedList、HashMap 这几种数据结构。
数组,由于其内存的连续性,可以通过下标的方式高效随机地访问数组中的元素。
数组与链表可以说是数据结构中两种最基本的数据结构,这节课,我们详细对比了两种数据结构的存储特性。
哈希表是我们使用得最多的数据结构,它的底层的设计也很具技巧性。哈希表充分考虑到数组与链表的优劣,扬长避短,HashMap 就是这两者的组合体。为了解决链表检索性能低下的问题,HashMap 内部又引入了扩容与链表树化两种方式进行性能提升,提高了使用的便利性,降低了使用门槛。
课后题
最后,我也给你留两道思考题吧!
1、业界在解决哈希冲突时除了使用链表外,还有其他什么方案?请你对这两者的差异进行简单的对比。
2、HashMap 中哈希槽的容量为什么必须为 2 的倍数?如果不是很理解,推荐你先学习一下位运算,然后在留言区告诉我你的答案。
我们下节课再见!
参考资料
https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/%e4%b8%ad%e9%97%b4%e4%bb%b6%e6%a0%b8%e5%bf%83%e6%8a%80%e6%9c%af%e4%b8%8e%e5%ae%9e%e6%88%98/03%20%20%e6%95%b0%e7%bb%84%e4%b8%8e%e9%93%be%e8%a1%a8%ef%bc%9a%e5%ad%98%e5%82%a8%e8%ae%be%e8%ae%a1%e7%9a%84%e5%9f%ba%e7%9f%b3%e6%9c%89%e5%93%aa%e4%ba%9b%ef%bc%9f.md
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
