23 大数据基准测试可以带来什么好处? 2012年的时候,Hadoop已经日趋成熟,Intel的大数据团队也正准备寻找新的技术研究方向。当时,我们对比测试了多个新出来的大数据技术产品,最终选择了Spark重点跟进参与。现在看来,这是一个明智的决定,作出这个决定是基于大数据基准测试,而使用的对比测试工具就是我今天要讲的大数据基准测试工具HiBench。
大数据作为一个生态体系,不但有各种直接进行大数据处理的平台和框架,比如HDFS、MapReduce、Spark,还有很多周边的支撑工具,而大数据基准测试工具就是其中一个大类。
大数据基准测试的应用
大数据基准测试的主要用途是对各种大数据产品进行测试,检验大数据产品在不同硬件平台、不同数据量、不同计算任务下的性能表现。
上面这样讲大数据基准测试的用途可能比较教条,我举两个例子你就能明白它的应用有多么重要了。
还是回到2012年,当时Hive只能做离线的SQL查询计算,无法满足数据分析师实时交互查询的需求,业界需要一款更快的ad hoc query(即席查询,一种非预设查询的SQL访问)工具。在这种情况下,Cloudera推出了准实时SQL查询工具Impala。Impala兼容Hive的Hive QL语法和Hive MetaSotre,也支持Hive存储在HDFS的数据表,但是放弃了Hive较慢的MapReduce执行引擎,而是基于MPP(Massively Parallel Processing,大规模并行处理)的架构思想重新开发了自己的执行引擎,从而获得更快的查询速度。
由于Cloudera在大数据领域的巨大权威,加上人们对快速SQL查询的期待,Impala在刚推出的时候,受到大数据业界的极大瞩目。当时,我也立即用四台服务器部署了一个小集群,利用大数据基准测试工具HiBench对Impala和Hive做了一个对比测试。
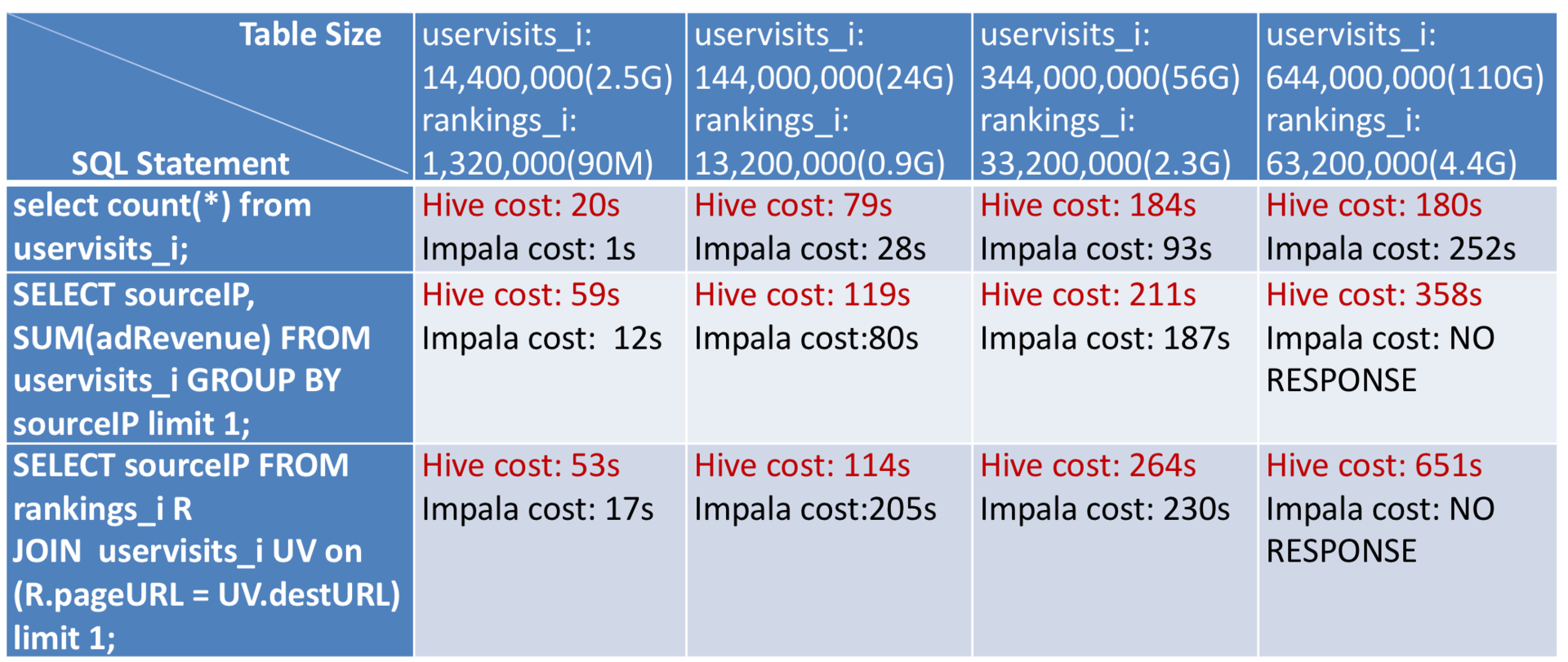
但是经过对比测试以后,我发现情况并不乐观。Impala性能有优势的地方在于聚合查询,也就是用group by查询的SQL语句;而对于连接查询,也就是用join查询的SQL语句性能表现很差。我进一步阅读Impala的源代码,对设计原理和架构进行分析后,得出了自己的看法,我认为适合Impala的应用场景有两类:
- 一类是简单统计查询,对单表数据进行聚合查询,查看数据分布规律。
- 一类是预查询,在进行全量数据的SQL查询之前,对抽样数据进行快速交互查询,验证数据分析师对数据的判断,方便数据分析师后续设计全量数据的查询SQL,而全量数据的SQL还是要运行在Hive上。
这样Impala就有点尴尬了,它的定位似乎只是Hive的附属品。这就好比Impala是餐前开胃菜和餐后甜点,而正餐依然是Hive。
但是Cloudera却对Impala寄予厚望,后来我和Cloudera的工程师聊天,得知他们投入了公司近一半的工程师到Impala的开发上,我还是有点担心。事实上,这么多年过去了,Impala经过不断迭代,相比最开始的性能有了很大改进,但是我想,Impala依然没有承担起Cloudera对它的厚望。
跟Impala相对应的是,同样是2012年,Intel大数据团队用大数据基准测试工具HiBench对Spark和MapReduce做了对比测试后发现,Spark运行性能有令人吃惊的表现。当时Intel大数据团队的负责人戴老师(Jason Dai)立即飞到美国,跟当时开发Spark的UC Berkeley的AMP实验室交流,表示Intel愿意参与到Spark的开发中。Spark也极其希望有业界巨头能够参与其中,开发代码尚在其次,重要的是有了Intel这样的巨头背书,Spark会进一步得到业界的认可和接受。
所以Intel成了Spark最早的参与者,加速了Spark的开发和发展。当2013年Spark加入Apache的开源计划,并迅速成为Apache的顶级项目,风靡全球的大数据圈子时,Intel作为早期参与者,也得到了业界的肯定,使Intel在大数据领域可以保持持续的影响力。
在这个案例里,所有各方都是赢家,Spark、Intel、Apache,乃至整个大数据行业,我作为Intel参与Spark早期开发的工程师,也都因此而受益。这也是我关于工作的一个观点:好的工作不光是对公司有利,对员工也是有利的。工作不是公司在压榨员工的过程,而是公司创造价值,同时员工实现自我价值的过程。
而如何才能创造出好的工作也不只是公司的责任,主要还是要靠员工自己,去发现哪些事情能够让自己、公司、社会都获益,然后去推动这些事情的落实,虽然有的时候推动比发现更困难。同时拥有发现和推动能力的人,毫无例外都是一些出类拔萃的人,比如专栏前面也提到的Intel的戴老师,这些人都是我工作的榜样。
大数据基准测试工具HiBench
大数据基准测试工具有很多,今天我重点为你介绍前面我多次提到的,也是Intel推出的大数据基准测试工具HiBench。
HiBench内置了若干主要的大数据计算程序作为基准测试的负载(workload)。
- Sort,对数据进行排序大数据程序。
- WordCount,前面多次提到过,词频统计大数据计算程序。
- TeraSort,对1TB数据进行排序,最早是一项关于软件和硬件的计算力的竞赛,所以很多大数据平台和硬件厂商进行产品宣传的时候会用TeraSort成绩作为卖点。
- Bayes分类,机器学习分类算法,用于数据分类和预测。
- k-means聚类,对数据集合规律进行挖掘的算法。
- 逻辑回归,数据进行预测和回归的算法。
- SQL,包括全表扫描、聚合操作(group by)、连接操作(join)几种典型查询SQL。
- PageRank,Web排序算法。
此外还有十几种常用大数据计算程序,支持的大数据框架包括MapReduce、Spark、Storm等。
对于很多非大数据专业人士而言,HiBench的价值不在于对各种大数据系统进行基准测试,而是学习大数据、验证自己大数据平台性能的工具。
对于一个刚刚开始入门大数据的工程师而言,在自己的电脑上部署了一个伪分布式的大数据集群可能并不复杂,对着网上的教程,顺利的话不到1个小时就可以拥有自己的大数据集群。
但是,接下来呢?开发MapReduce程序、打包、部署、运行,可能这里每一步都会遇到很多挫折。即使一切顺利,但顾名思义对于“大数据”来说,需要大量的数据才有意义,那数据从哪儿来呢?如果想用一些更复杂的应用体验下大数据的威力,可能遇到的挫折就更多了,所以很多人在安装了Hadoop以后,然后就放弃了大数据。
对于做大数据平台的工程师,如果等到使用者来抱怨自己维护的大数据平台不稳定、性能差的时候,可能就有点晚了,因为这些消息可能已经传到老板那里了。所以必须自己不停地跑一些测试,了解大数据平台的状况。
有了HiBench,这些问题都很容易就可以解决,HiBench内置了主要的大数据程序,支持多种大数据产品。最重要的是使用特别简单,初学者可以把HiBench当作学习工具,可以很快运行起各种数据分析和机器学习大数据应用。大数据工程师也可以用HiBench测试自己的大数据平台,验证各种大数据产品的性能。
HiBench使用非常简单,只需要三步:
1.配置,配置要测试的数据量、大数据运行环境和路径信息等基本参数。
2.初始化数据,生成准备要计算的数据,比如要测试1TB数据的排序,那么就生成1TB数据。
3.执行测试,运行对应的大数据计算程序。
具体初始化和执行命令也非常简单,比如要生成数据,只需要运行bin目录下对应workload的prepare.sh就可以自动生成配置大小的数据。 bin/workloads/micro/terasort/prepare/prepare.sh
要执行大数据计算,运行run.sh就可以了。
bin/workloads/micro/terasort/hadoop/run.sh bin/workloads/micro/terasort/spark/run.sh
小结
同一类技术问题的解决方案绝不会只有一个,技术产品也不会只有一个,比如大数据领域,从Hadoop到Spark再到Flink,各种大数据产品层出不穷,那么如何对比测试这些大数据产品,在不同的应用场景中它们各自的优势是什么?这个时候就需要用到基准测试工具,通过基准测试工具,用最小的成本得到我们想测试的结果。
所以除了大数据,在很多技术领域都有基准测试,比如数据库、操作系统、计算机硬件等。前几年手机领域的竞争聚焦在配置和性能上,各路发烧友们比较手机优劣的时候,口头禅就是“跑个分试试”,这也是一种基准测试。
因此基准测试对这些产品而言至关重要,甚至攸关生死。得到业界普遍认可的基准测试工具就是衡量这些产品优劣的标准,如果能使基准测试对自己的产品有利,更是涉及巨大的商业利益。我在Intel开始做SQL引擎开发,后来做Spark开发,需要调查各种数据库和大数据的基准测试工具,也就是在那个时候,我发现华为这家公司还是很厉害的,在很多基准测试标准的制定者和开发者名单中,都能看到华为的名字,而且几乎是唯一的中国公司。
有时候我们想要了解一个大数据产品的性能和用法,看了各种资料花了很多时间,最后得到的可能还是一堆不靠谱的N手信息。但自己跑一个基准测试,也许就几分钟的事,再花点时间看看测试用例,从程序代码到运行脚本,很快就能了解其基本用法,更加省时、高效。
思考题
今天文章的Impala VS Hive的基准测试报告里,发现当数量很大的时候做join查询,Impala会失去响应,是因为Impala比Hive更消耗内存,当内存不足时,就会失去响应。你能否从Impala的架构和技术原理角度分析为什么Impala比Hive更消耗内存?
欢迎你点击“请朋友读”,把今天的文章分享给好友。也欢迎你写下自己的思考或疑问,与我和其他同学一起讨论。
参考资料
https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/%e4%bb%8e0%e5%bc%80%e5%a7%8b%e5%ad%a6%e5%a4%a7%e6%95%b0%e6%8d%ae/23%20%e5%a4%a7%e6%95%b0%e6%8d%ae%e5%9f%ba%e5%87%86%e6%b5%8b%e8%af%95%e5%8f%af%e4%bb%a5%e5%b8%a6%e6%9d%a5%e4%bb%80%e4%b9%88%e5%a5%bd%e5%a4%84%ef%bc%9f.md
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
