15 如何搭建一个可靠的监控系统?
[专栏第7期]我给你讲解了监控系统的实现原理,先来简单回顾一下,一个监控系统的组成主要涉及四个环节:数据收集、数据传输、数据处理和数据展示。不同的监控系统实现方案,在这四个环节所使用的技术方案不同,适合的业务场景也不一样。
目前,比较流行的开源监控系统实现方案主要有两种:以ELK为代表的集中式日志解决方案,以及Graphite、TICK和Prometheus等为代表的时序数据库解决方案。接下来我就以这几个常见的监控系统实现方案,谈谈它们的实现原理,分别适用于什么场景,以及具体该如何做技术选型。
ELK
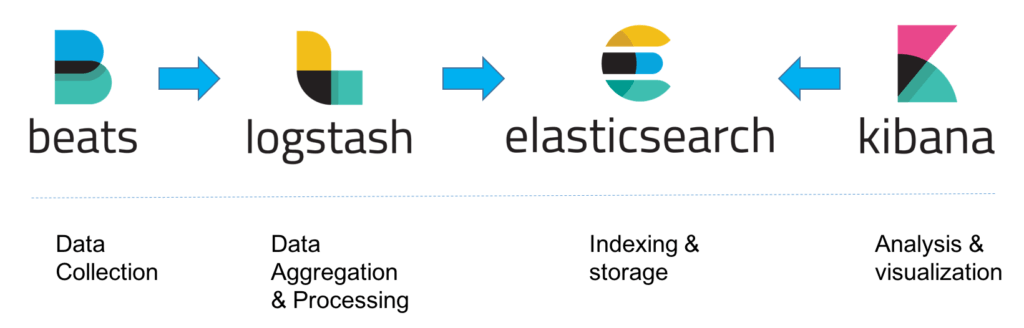
ELK是Elasticsearch、Logstash、Kibana三个开源软件产品首字母的缩写,它们三个通常配合使用,所以被称为ELK Stack,它的架构可以用下面的图片来描述。
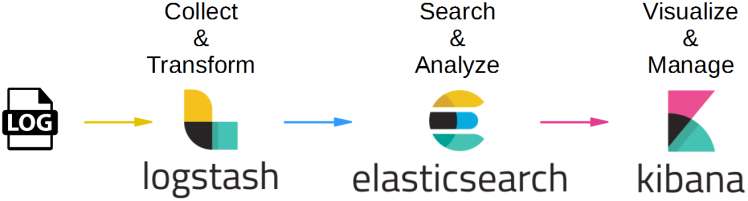 - (图片来源:[https://cdn-images-1.medium.com/max/1600/1/mwSvtVy_qGz0nTjaYbvwpw.png](https://cdn-images-1.medium.com/max/1600/1mwSvtVy_qGz0nTjaYbvwpw.png))
- (图片来源:[https://cdn-images-1.medium.com/max/1600/1/mwSvtVy_qGz0nTjaYbvwpw.png](https://cdn-images-1.medium.com/max/1600/1mwSvtVy_qGz0nTjaYbvwpw.png))
这三个软件的功能也各不相同。
- Logstash负责数据收集和传输,它支持动态地从各种数据源收集数据,并对数据进行过滤、分析、格式化等,然后存储到指定的位置。
- Elasticsearch负责数据处理,它是一个开源分布式搜索和分析引擎,具有可伸缩、高可靠和易管理等特点,基于Apache Lucene构建,能对大容量的数据进行接近实时的存储、搜索和分析操作,通常被用作基础搜索引擎。
- Kibana负责数据展示,也是一个开源和免费的工具,通常和Elasticsearch搭配使用,对其中的数据进行搜索、分析并且以图表的方式展示。
这种架构因为需要在各个服务器上部署Logstash来从不同的数据源收集数据,所以比较消耗CPU和内存资源,容易造成服务器性能下降,因此后来又在Elasticsearch、Logstash、Kibana之外引入了Beats作为数据收集器。相比于Logstash,Beats所占系统的CPU和内存几乎可以忽略不计,可以安装在每台服务器上做轻量型代理,从成百上千或成千上万台机器向Logstash或者直接向Elasticsearch发送数据。
其中,Beats支持多种数据源,主要包括:
- Packetbeat,用来收集网络流量数据。
- Topbeat,用来收集系统、进程的CPU和内存使用情况等数据。
- Filebeat,用来收集文件数据。
- Winlogbeat,用来收集Windows事件日志收据。
Beats将收集到的数据发送到Logstash,经过Logstash解析、过滤后,再将数据发送到Elasticsearch,最后由Kibana展示,架构就变成下面这张图里描述的了。
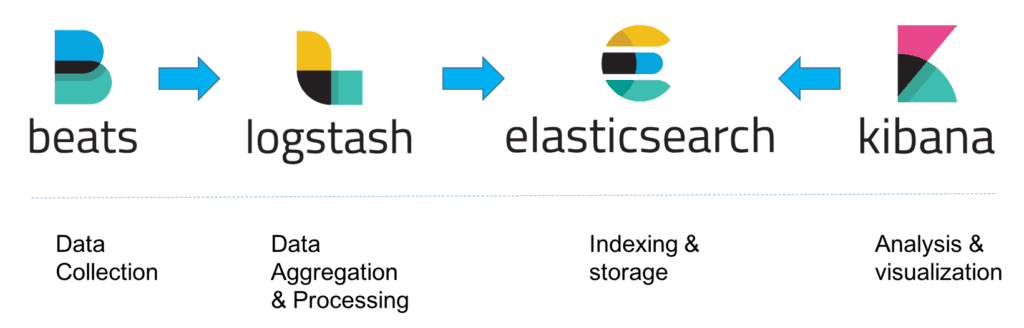 - (图片来源:https://logz.io/wp-content/uploads/2018/08/image21-1024x328.png)
- (图片来源:https://logz.io/wp-content/uploads/2018/08/image21-1024x328.png)
Graphite
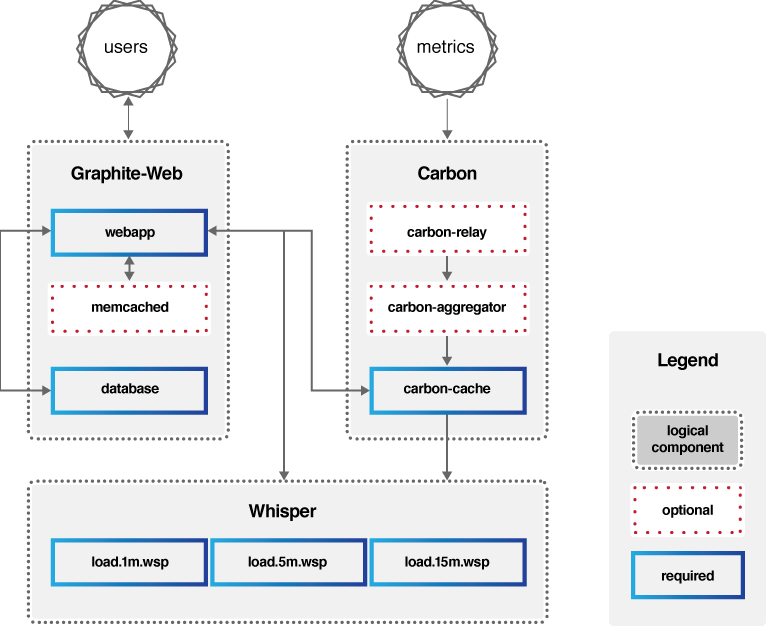
Graphite的组成主要包括三部分:Carbon、Whisper、Graphite-Web,它的架构可以用下图来描述。
- Carbon:主要作用是接收被监控节点的连接,收集各个指标的数据,将这些数据写入carbon-cache并最终持久化到Whisper存储文件中去。
- Whisper:一个简单的时序数据库,主要作用是存储时间序列数据,可以按照不同的时间粒度来存储数据,比如1分钟1个点、5分钟1个点、15分钟1个点三个精度来存储监控数据。
- Graphite-Web:一个Web App,其主要功能绘制报表与展示,即数据展示。为了保证Graphite-Web能及时绘制出图形,Carbon在将数据写入Whisper存储的同时,会在carbon-cache中同时写入一份数据,Graphite-Web会先查询carbon-cache,如果没有再查询Whisper存储。
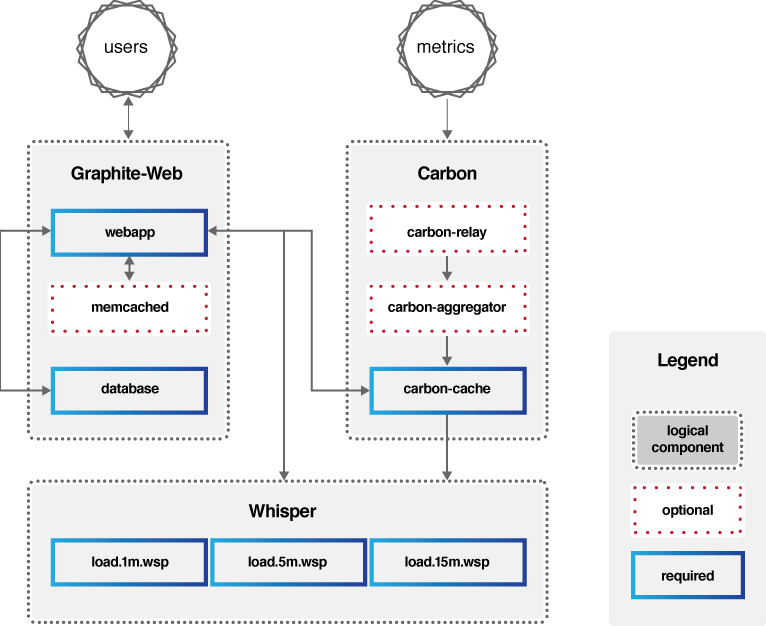 - (图片来源:https://graphiteapp.org/img/architecture_diagram.png)
- (图片来源:https://graphiteapp.org/img/architecture_diagram.png)
也就是说Carbon负责数据处理,Whisper负责数据存储,Graphite-Web负责数据展示,可见Graphite自身并不包含数据采集组件,但可以接入StatsD等开源数据采集组件来采集数据,再传送给Carbon。
其中Carbon对写入的数据格式有一定的要求,比如:
servers.www01.cpuUsage 42 1286269200 products.snake-oil.salesPerMinute 123 1286269200 [one minute passes] servers.www01.cpuUsageUser 44 1286269260 products.snake-oil.salesPerMinute 119 1286269260
其中“servers.www01.cpuUsage 42 1286269200”是“key” + 空格分隔符 + “value + 时间戳”的数据格式,“servers.www01.cpuUsage”是以“.”分割的key,代表具体的路径信息,“42”是具体的值,“1286269200”是当前的Unix时间戳。
Graphite-Web对外提供了HTTP API可以查询某个key的数据以绘图展示,查询方式如下。
http://graphite.example.com/render?target=servers.www01.cpuUsage& width=500&height=300&from=-24h
这个HTTP请求意思是查询key“servers.www01.cpuUsage”在过去24小时的数据,并且要求返回500/*300大小的数据图。
除此之外,Graphite-Web还支持丰富的函数,比如:
target=sumSeries(products./*.salesPerMinute)
代表了查询匹配规则“products./*.salesPerMinute”的所有key的数据之和。
TICK
TICK是Telegraf、InfluxDB、Chronograf、Kapacitor四个软件首字母的缩写,是由InfluxData开发的一套开源监控工具栈,因此也叫作TICK Stack,它的架构可以看用下面这张图来描述。
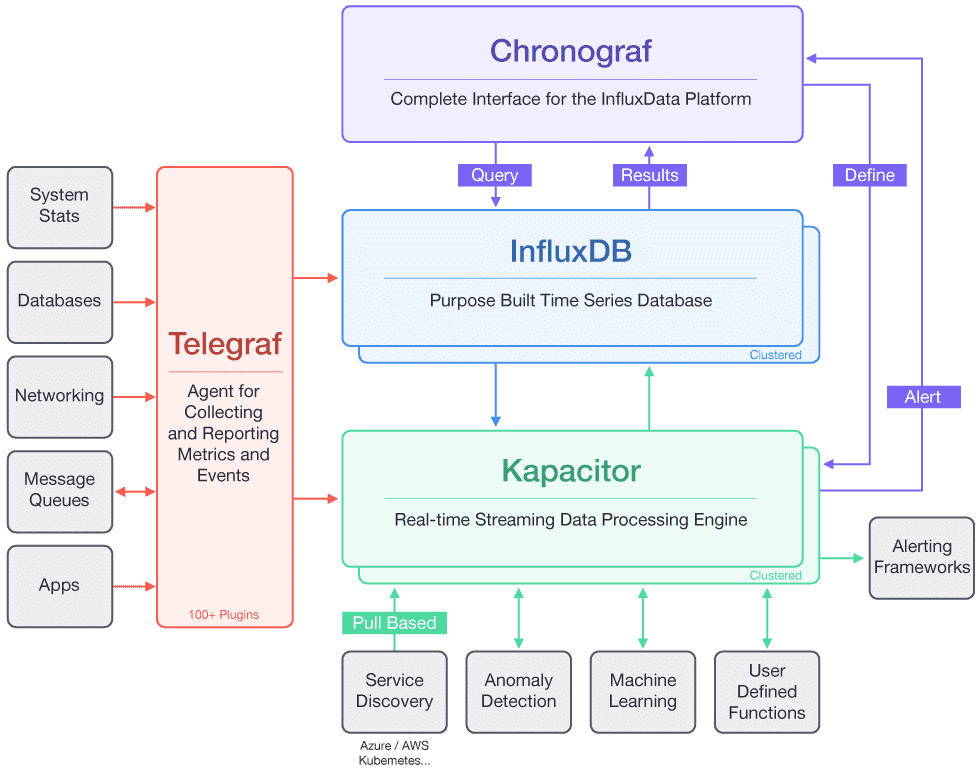 - (图片来源:https://2bjee8bvp8y263sjpl3xui1a-wpengine.netdna-ssl.com/wp-content/uploads/Tick-Stack-Complete.png)
- (图片来源:https://2bjee8bvp8y263sjpl3xui1a-wpengine.netdna-ssl.com/wp-content/uploads/Tick-Stack-Complete.png)
从这张图可以看出,其中Telegraf负责数据收集,InfluxDB负责数据存储,Chronograf负责数据展示,Kapacitor负责数据告警。
这里面,InfluxDB对写入的数据格式要求如下。
[,=...] =[,=...] [unix-nano-timestamp]
下面我用一个具体示例来说明它的格式。
cpu,host=serverA,region=us_west value=0.64 1434067467100293230
其中,“cpu,host=serverA,region=us_west value=0.64 1434067467100293230”代表了host为serverA、region为us_west的服务器CPU的值是0.64,时间戳是1434067467100293230,时间精确到nano。
## Prometheus
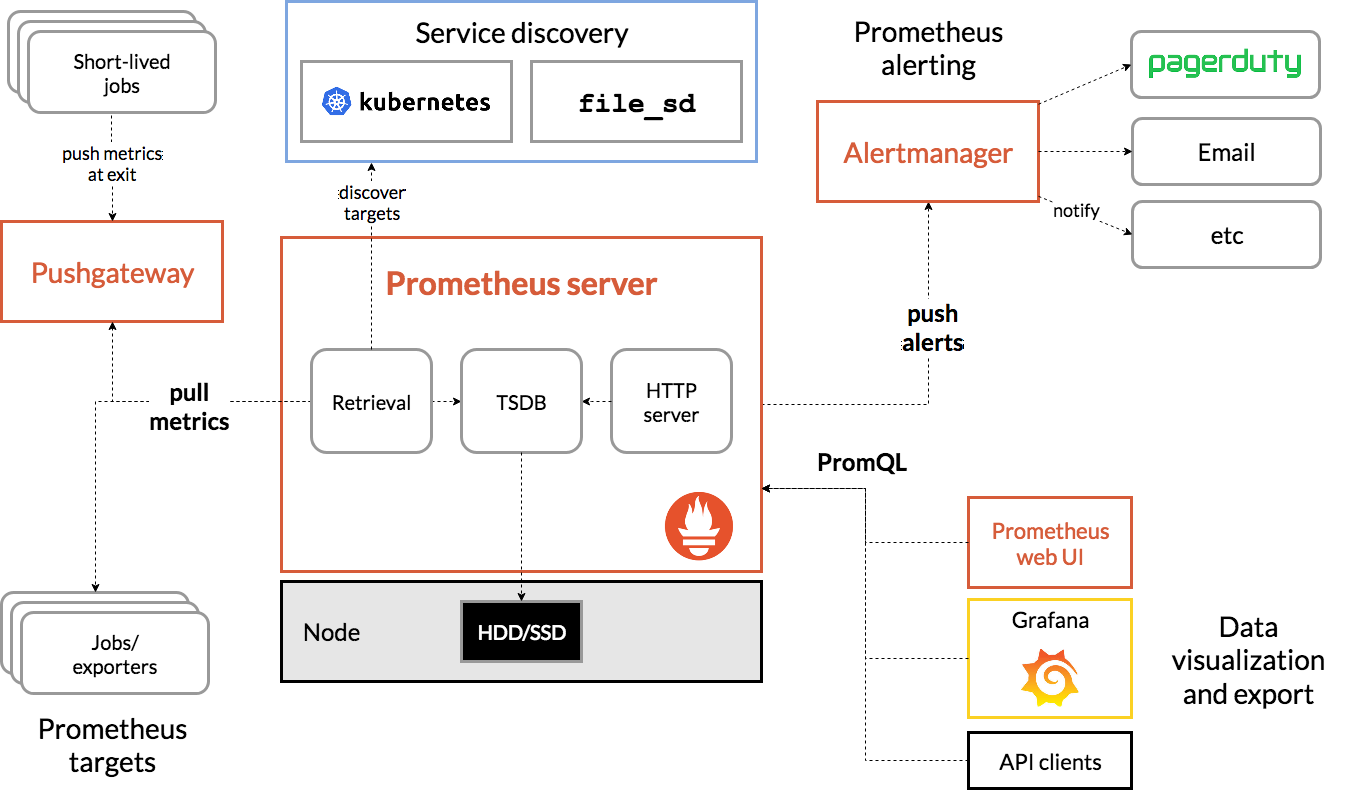
还有一种比较有名的时间序数据库解决方案Prometheus,它是一套开源的系统监控报警框架,受Google的集群监控系统Borgmon启发,由工作在SoundCloud的Google前员工在2012年创建,后来作为社区开源项目进行开发,并于2015年正式发布,2016年正式加入CNCF(Cloud Native Computing Foundation),成为受欢迎程度仅次于Kubernetes的项目,它的架构可以用下图来描述。
- (图片来源:[https://prometheus.io/assets/architecture.png](https://prometheus.io/assets/architecture.png))
从这张图可以看出,Prometheus主要包含下面几个组件:
* Prometheus Server:用于拉取metrics信息并将数据存储在时间序列数据库。
* Jobs/exporters:用于暴露已有的第三方服务的metrics给Prometheus Server,比如StatsD、Graphite等,负责数据收集。
* Pushgateway:主要用于短期jobs,由于这类jobs存在时间短,可能在Prometheus Server来拉取metrics信息之前就消失了,所以这类的jobs可以直接向Prometheus Server推送它们的metrics信息。
* Alertmanager:用于数据报警。
* Prometheus web UI:负责数据展示。
它的工作流程大致是:
* Prometheus Server定期从配置好的jobs或者exporters中拉取metrics信息,或者接收来自Pushgateway发过来的metrics信息。
* Prometheus Server把收集到的metrics信息存储到时间序列数据库中,并运行已经定义好的alert.rules,向Alertmanager推送警报。
* Alertmanager根据配置文件,对接收的警报进行处理,发出告警。
* 通过Prometheus web UI进行可视化展示。
Prometheus存储数据也是用的时间序列数据库,格式如下。
{
{kind=link}
{kind=link}
{kind=link}
