46 _ 容器的崛起(上):文件、访问、资源的隔离 你好,我是周志明。接下来的两节课,我会以容器化技术的发展为线索,带你从隔离与封装两个角度,去学习和了解容器技术。
今天,我们就先来学习下Linux系统中隔离技术的发展历程,以此为下节课理解“以容器封装应用”的思想打好前置基础。
隔离文件:chroot
首先要知道,人们使用容器的最初目的,并不是为了部署软件,而是为了隔离计算机中的各类资源,以便降低软件开发、测试阶段可能产生的误操作风险,或者是专门充当蜜罐,吸引黑客的攻击,以便监视黑客的行为。
容器的起点呢,可以追溯到1979年Version 7 UNIX系统中提供的chroot命令,这个命令是英文单词“Change Root”的缩写,它所具备的功能是当某个进程经过chroot操作之后,它的根目录就会被锁定在命令参数所指定的位置,以后它或者它的子进程就不能再访问和操作该目录之外的其他文件。
1991年,世界上第一个监控黑客行动的蜜罐程序就是使用chroot来实现的,那个参数指定的根目录当时被作者被戏称为“Chroot监狱”(Chroot Jail),而黑客突破chroot限制的方法就叫做Jailbreak。后来,FreeBSD 4.0系统重新实现了chroot命令,把它作为系统中进程沙箱隔离的基础,并将其命名为FreeBSD jail。
再后来,苹果公司又以FreeBSD为基础研发出了举世闻名的iOS操作系统,此时,黑客们就把绕过iOS沙箱机制,以root权限任意安装程序的方法称为“越狱”(Jailbreak),当然这些故事都是题外话了。
到了2000年,Linux Kernel 2.3.41版内核引入了pivot_root技术来实现文件隔离,pivot_root直接切换了根文件系统(rootfs),有效地避免了chroot命令可能出现的安全性漏洞。咱们课程后面要提到的容器技术,比如LXC、Docker等等,也都是优先使用pivot_root来实现根文件系统切换的。
不过时至今日,chroot命令依然活跃在Unix系统,以及几乎所有主流的Linux发行版中,同时也以命令行工具(chroot(8))或者系统调用(chroot(2) )的形式存在着,但无论是chroot命令还是pivot_root,它们都不能提供完美的隔离性。
其实原本按照Unix的设计哲学,一切资源都可以视为文件(In UNIX,Everything is a File),一切处理都可以视为对文件的操作,在理论上应该是隔离了文件系统就可以安枕无忧才对。
可是,哲学归哲学,现实归现实,从硬件层面暴露的低层次资源,比如磁盘、网络、内存、处理器,再到经操作系统层面封装的高层次资源,比如UNIX分时(UNIX Time-Sharing,UTS)、进程ID(Process ID,PID)、用户ID(User ID,UID)、进程间通信(Inter-Process Communication,IPC)等等,都存在着大量以非文件形式暴露的操作入口。
所以我才会说,以chroot为代表的文件隔离,仅仅是容器崛起之路的起点而已。
隔离访问:namespaces
那么到了2002年,Linux Kernel 2.4.19版内核引入了一种全新的隔离机制:Linux名称空间(Linux Namespaces)。
名称空间的概念在很多现代的高级程序语言中都存在,它主要的作用是避免不同开发者提供的API相互冲突,相信作为一名开发人员的你肯定不陌生。
Linux的名称空间是一种由内核直接提供的全局资源封装,它是内核针对进程设计的访问隔离机制。进程在一个独立的Linux名称空间中朝系统看去,会觉得自己仿佛就是这方天地的主人,拥有这台Linux主机上的一切资源,不仅文件系统是独立的,还有着独立的PID编号(比如拥有自己的0号进程,即系统初始化的进程)、UID/GID编号(比如拥有自己独立的root用户)、网络(比如完全独立的IP地址、网络栈、防火墙等设置),等等,此时进程的心情简直不能再好了。
事实上,Linux的名称空间是受“贝尔实验室九号项目”(一个分布式操作系统,“九号”项目并非代号,操作系统的名字就叫“Plan 9 from Bell Labs”,充满了赛博朋克风格)的启发而设计的,最初的目的依然只是为了隔离文件系统,而不是为了什么容器化的实现。这点我们从2002年发布时,Linux只提供了Mount名称空间,并且其构造参数为“CLONE_NEWNS”(即Clone New Namespace的缩写)而非“CLONE_NEWMOUNT”,就能看出一些端倪。
到了后来,要求系统隔离其他访问操作的呼声就愈发强烈,从2006年起,内核陆续添加了UTS、IPC等名称空间隔离,直到目前最新的Linux Kernel 5.6版内核为止,Linux名称空间支持了以下八种资源的隔离(内核的官网Kernel.org上仍然只列出了前六种,从Linux的Man命令能查到全部八种):
 阅读链接补充:- Hostname- Domain names
阅读链接补充:- Hostname- Domain names
如今,对文件、进程、用户、网络等各类信息的访问,都被囊括在Linux的名称空间中,即使一些今天仍有没被隔离的访问(比如syslog就还没被隔离,容器内可以看到容器外其他进程产生的内核syslog),在以后也可以跟随内核版本的更新纳入到这套框架之内。
现在,距离完美的隔离性就只差最后一步了:资源的隔离。
隔离资源:cgroups
如果要让一台物理计算机中的各个进程看起来像独享整台虚拟计算机的话,不仅要隔离各自进程的访问操作,还必须能独立控制分配给各个进程的资源使用配额。不然的话,一个进程发生了内存溢出或者占满了处理器,其他进程就莫名其妙地被牵连挂起,这样肯定算不上是完美的隔离。
而Linux系统解决以上问题的方案就是控制群组(Control Groups,目前常用的简写为cgroups),它与名称空间一样,都是直接由内核提供的功能,用于隔离或者说分配并限制某个进程组能够使用的资源配额。这里的资源配额包括了处理器时间、内存大小、磁盘I/O速度,等等,具体你可以参考下这里给出的表格:
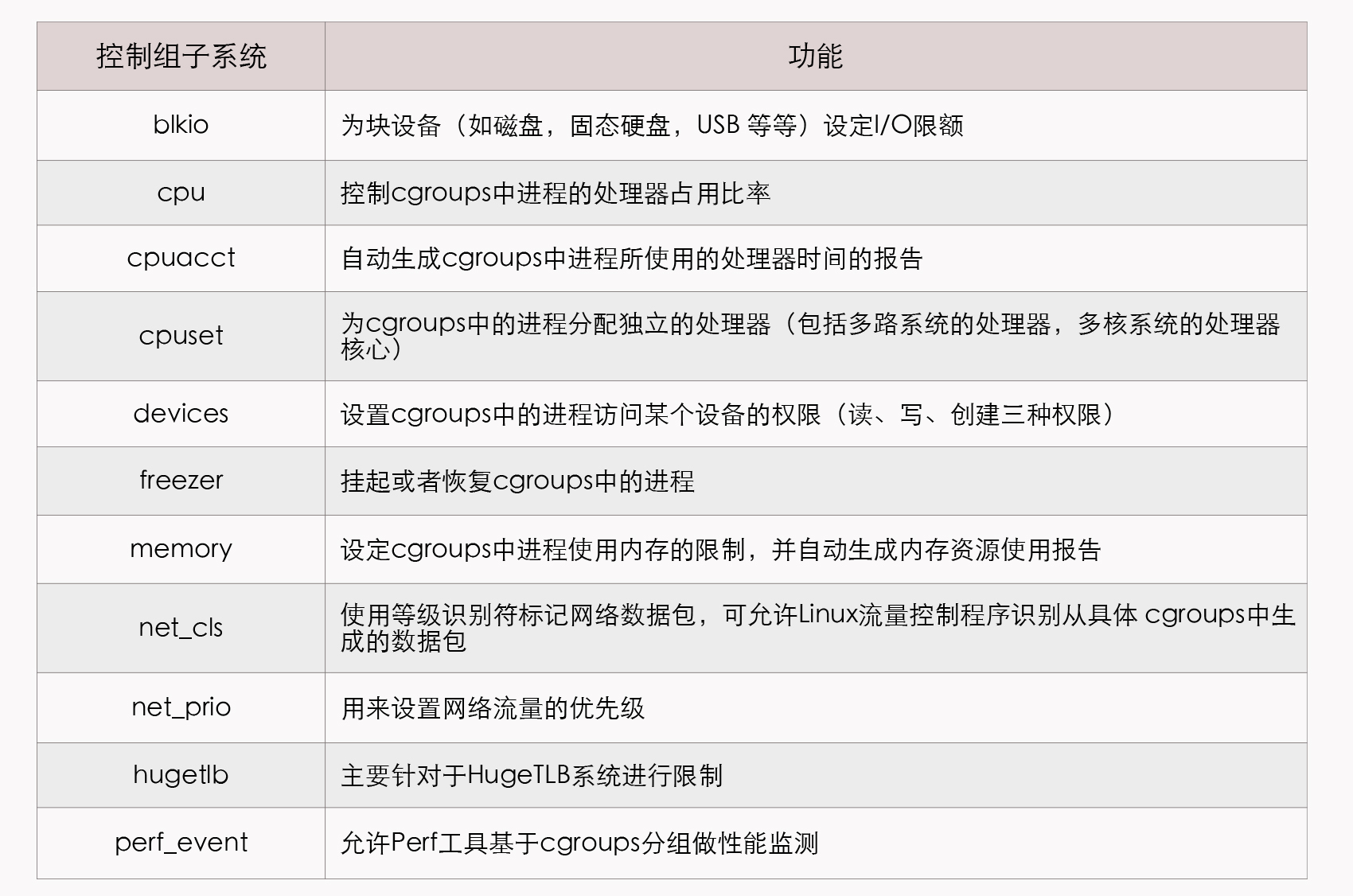
cgroups项目最早是由Google的工程师(主要是Paul Menage和Rohit Seth)在2006年发起的,当时取的名字就叫做“进程容器”(Process Containers),不过“容器”(Container)这个名词的定义在那时候还没有今天那么清晰,不同场景中常有不同的指向。
所以,为了避免混乱,到2007年这个项目才被重新命名为cgroups,在2008年合并到了2.6.24版的内核后正式对外发布,这一阶段的cgroups就被称为“第一代cgroups”。
后来,在2016年3月发布的Linux Kernel 4.5中,搭载了由Facebook工程师(主要是Tejun Heo)重新编写的“第二代cgroups”,其关键改进是支持Unified Hierarchy,这个功能可以让管理员更加清晰、精确地控制资源的层级关系。目前这两个版本的cgroups在Linux内核代码中是并存的,不过在下节课我会给你介绍的封装应用Docker,就暂时仅支持第一代的cgroups。
小结
这节课,我给你介绍了容器技术和思想的起源:chroot命令,这是计算机操作系统中最早的成规模的隔离技术。
此外,你现在也了解到了namespaces和cgroups对资源访问与资源配额的隔离,它们不仅是容器化技术的基础,在现代Linux操作系统中也已经成为了无可或缺的基石。理解了这些基础性的知识,是学习和掌握下节课中讲解的容器应用,即不同封装对象、封装思想的必要前提。
一课一思
请你思考一下:Docker的起源依赖于Linux内核提供的隔离能力,那Docker就是Linux专属的吗?Windows系统中是否有文件、访问、资源的隔离手段?是否存在Windows版本的容器运行时呢? 提示:你可以搜索关于Window Server Contianer的信息,与LXC(Linux Container)对比一下。
欢迎在留言区分享你的思考和见解。如果你觉得有收获,也欢迎把今天的内容分享给更多的朋友。感谢你的阅读,我们下一讲再见。
参考资料
https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/%e5%91%a8%e5%bf%97%e6%98%8e%e7%9a%84%e6%9e%b6%e6%9e%84%e8%af%be/46%20_%20%e5%ae%b9%e5%99%a8%e7%9a%84%e5%b4%9b%e8%b5%b7%ef%bc%88%e4%b8%8a%ef%bc%89%ef%bc%9a%e6%96%87%e4%bb%b6%e3%80%81%e8%ae%bf%e9%97%ae%e3%80%81%e8%b5%84%e6%ba%90%e7%9a%84%e9%9a%94%e7%a6%bb.md
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
