08 答疑解惑:缓存失效的策略应该怎么定? 十一黄金周的时候,极客时间团队邀请到了前阿里巴巴高级技术专家许令波专门撰写了《如何设计一个秒杀系统》专栏,希望带你透彻理解秒杀系统的各个关键技术点,并借助“秒杀”这个互联网高并发场景中的典型代表,带你了解如何打造一个超大流量并发读写、高性能,以及高可用的系统架构。
专栏虽然只有短短7篇,但却持续获得大量用户的支持和赞誉。留言区,我们更是可以看到大量从学习角度或业务角度出发提出的各种问题。为此,我们也特别邀请专栏作者许令波就一些关键或普遍的问题进一步“加餐”解答,希望能够给你更好的帮助。
| **1. “06 | 秒杀系统‘减库存’设计的核心逻辑”一文中,很多用户比较关注应用层排队的问题,大家主要的疑问就是应用层用队列接受请求,然后结果怎么返回的问题。** |
其实我这里所说的排队,更多地是说在服务端的服务调用之间采用排队的策略。例如,秒杀需要调用商品服务、调用价格优惠服务或者是创建订单服务,由于调用这些服务出现性能瓶颈,或者由于热点请求过于集中导致远程调用的连接数都被热点请求占据,那么那些正常的商品请求(非秒杀商品)就得不到服务器的资源了,这样对整个网站来说是不公平的。
再比如说,正常整个网站上每秒只有几万个请求,这几万个请求可能是非常分散的,那么假如现在有一个秒杀商品,这个秒杀商品带来的瞬间请求一下子就打满了我们的服务器资源,这样就会导致那些正常的几万个请求得不到正常的服务,这个情况对系统来说是绝对不合理的,也是应该避免的。
所以我们设计了一些策略,把秒杀系统独立出来,部署单独的一些服务器,也隔离了一些热点的数据库,等等。但是实际上不能把整个秒杀系统涉及的所有系统都独立部署一套,不然这样代价太大。
既然不能所有系统都独立部署一套,势必就会存在一部分系统不能区分秒杀请求和正常请求,那么要如何防止前面所说的问题出现呢?通常的解决方案就是在部分服务调用的地方对请求进行Hash分组,来限制一部分热点请求过多地占用服务器资源,分组的策略就可以根据商品ID来进行Hash,热点商品的请求始终会进入一个分组中,这样就解决了前面的问题。
我看问的问题很多是说对秒杀的请求进行排队如何把结果通知给用户,我并不是说在用户HTTP请求时采用排队的策略(也就是把用户的所有秒杀请求都放到一个队列进行排队,然后在队列里按照进入队列的顺序进行选择,先到先得),虽然这看起来还是一个挺合理的设计,但是实际上并没有必要这么做!
为什么?因为我们服务端接受请求本身就是按照请求顺序处理的,而且这个处理在Web层是实时同步的,处理的结果也会立马就返回给用户。但是我前面也说了,整个请求的处理涉及很多服务调用也涉及很多其他的系统,也会有部分的处理需要排队,所以可能有部分先到的请求由于后面的一些排队的服务拖慢,导致最终整个请求处理完成的时间反而比较后面的请求慢的情况。
这种情况理论上的确存在,你可能会说这样可能会不公平,但是这的确没有办法,这种所谓的“不公平”,并不是由于人为设置的因素导致的。
你可能会问(如果你一定要问),采用请求队列的方式能不能做?我会说“能”,但是有两点问题:
- 一是体验会比较差,因为是异步的方式,在页面中搞个倒计时,处理的时间会长一点;
- 二是如果是根据入队列的时间来判断谁获得秒杀商品,那也太没有意思了,没有运气成分不也就没有惊喜了?
至于大家在纠结异步请求如何返回结果的问题,其实有多种方案。
- 一是页面中采用轮询的方式定时主动去服务端查询结果,例如每秒请求一次服务端看看有没有处理结果(现在很多支付页面都采用了这种策略),这种方式的缺点是服务端的请求数会增加不少。
- 二是采用主动push的方式,这种就要求服务端和客户端保持连接了,服务端处理完请求主动push给客户端,这种方式的缺点是服务端的连接数会比较多。
还有一个问题,就是如果异步的请求失败了,怎么办?对秒杀来说,我觉得如果失败了直接丢弃就好了,最坏的结果就是这个人没有抢到而已。但是你非要纠结的话,就要做异步消息的持久化以及重试机制了,要保证异步请求的最终正确处理一般都要借助消息系统,即消息的最终可达,例如阿里的消息中间件是能承诺只要客户端消息发送成功,那么消息系统一定会保证消息最终被送到目的地,即消息不会丢。因为客户端只要成功发送一条消息,下游消费方就一定会消费这条消息,所以也就不存在消息发送失败的问题了。
| **2. 在“02 | 如何才能做好动静分离?有哪些方案可选?”一文中,有介绍静态化的方案中关于Hash分组的问题。** |
大家可能通常理解Hash分组,像Cache这种可能一个key对应的数据只存在于一个实例中,这样做其实是为了保证缓存命中率,因为所有请求都被路由到一个缓存实例中,除了第一次没有命中外,后面的都会命中。
但是这样也存在一个问题,就是如果热点商品过于集中,Cache就会成为瓶颈,这时单个实例也支撑不了。像秒杀这个场景中,单个商品对Cache的访问会超过20w次,一般单Cache实例都扛不住这么大的请求量。所以需要采用一个分组中有多个实例缓存相同的数据(冗余)的办法来支撑更大的访问量。
你可能会问:一个商品数据存储在多个Cache实例中,如何保证数据一致性呢?(关于失效问题大家问得也比较多,后面再回答。)这个专栏中提的Hash分组都是基于Nginx+Varnish实现的,Nginx把请求的URL中的商品ID进行Hash并路由到一个upstream中,这个upstream挂载一个Varnish分组(如下图所示)。这样,一个相同的商品就可以随机访问一个分组的任意一台Varnish机器了。
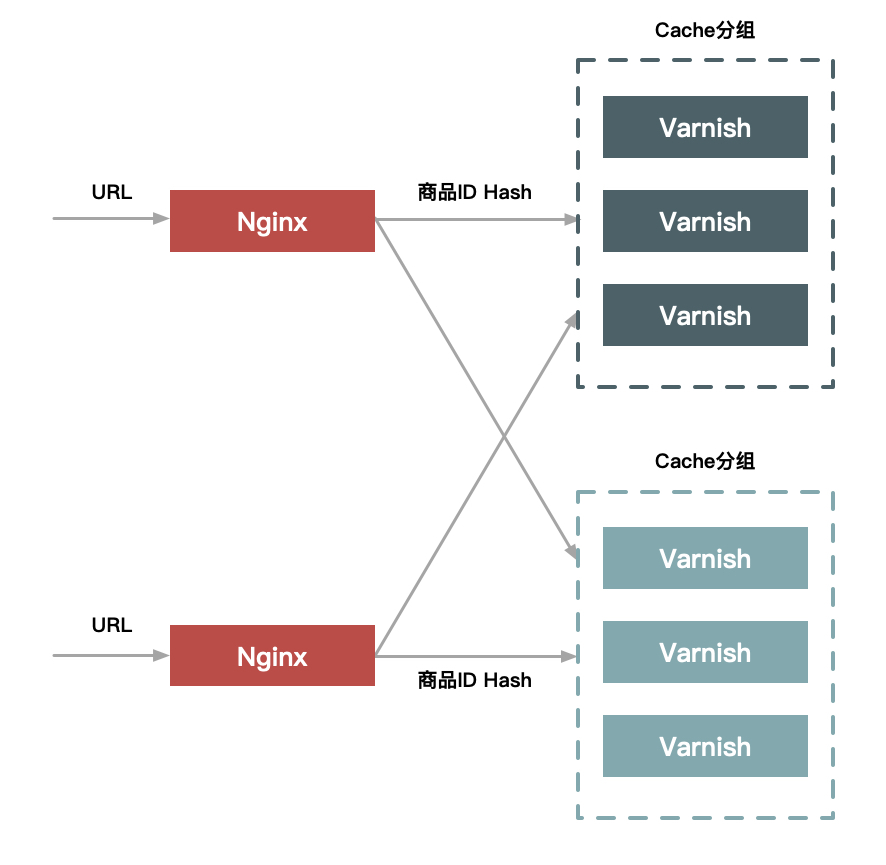
另外一个问题,关于Hash分组大家关注比较多的是命中率的问题,就是Cache机器越多命中率会越低。
这个其实很好理解,Cache实例越多,那么这些Cache缓存数据需要访问的次数也就越多。例如我有3个Redis实例,需要3个Redis实例都缓存商品A,那么至少需要访问3次才行,而且是这3次访问刚好落到不同的Redis实例中。那么从第4次访问开始才会被命中,如果仅仅是一个Redis实例,那么第二次访问时其实就能命中了。所以理论上Cache实例多会影响命中率。
你可能还会问,如果访问量足够大,那么只是影响前几次命中率而已,是的,如果Cache一直不失效的话是这样的,但是在实际的生产环境中Cache失效是很频繁发生的事情。很多情况下,还没等到所有Cache实例填满,该商品就已经失效了。所以,我们要根据商品的重复访问量来合理地设置Cache分组。
| **3. 在“02 | 如何才能做好动静分离?有哪些方案可选?”和“04 | 流量削峰这事应该怎么做?”两篇文章中,关于Cache失效的问题。** |
首先,咱们要有个共识,有Cache的地方就必然存在失效问题。为啥要失效?因为要保证数据的一致性。所以要用到Cache必然会问如何保证Cache和DB的数据一致性,如果Cache有分组的话,还要保证一个分组中多个实例之间数据的一致性,就像保证MySQL的主从一致一样。
其实,失效有主动失效和被动失效两种方式。
- 被动失效,主要处理如模板变更和一些对时效性不太敏感数据的失效,采用设置一定时间长度(如只缓存3秒钟)这种自动失效的方式。当然,你也要开发一个后台管理界面,以便能够在紧急情况下手工失效某些Cache。
- 主动失效,一般有Cache失效中心监控数据库表变化发送失效请求、系统发布也需要清空Cache数据等几种场景。其中失效中心承担了主要的失效功能,这个失效中心的逻辑图如下:
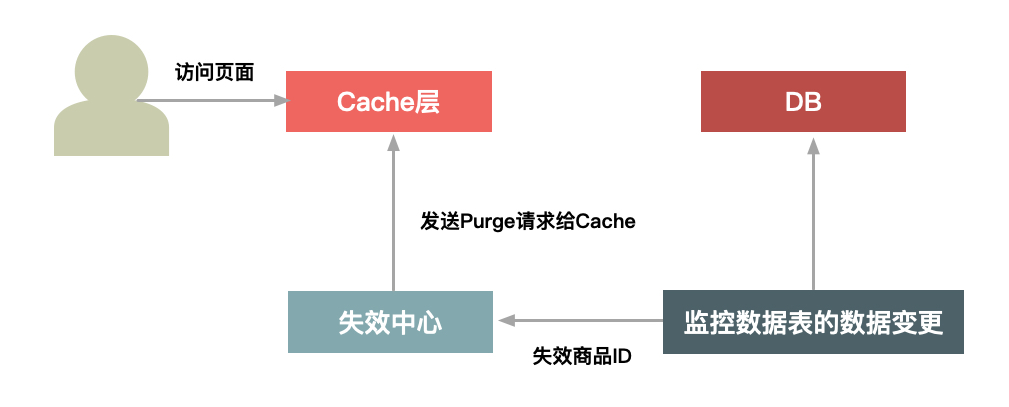
失效中心会监控关键数据表的变更(有个中间件来解析MySQL的binglog,然后发现有Insert、Update、Delete等操作时,会把变更前的数据以及要变更的数据转成一个消息发送给订阅方),通过这种方式来发送失效请求给Cache,从而清除Cache数据。如果Cache数据放在CDN上,那么也可以采用类似的方式来设计级联的失效结构,采用主动发请求给Cache软件失效的方式,如下图所示:
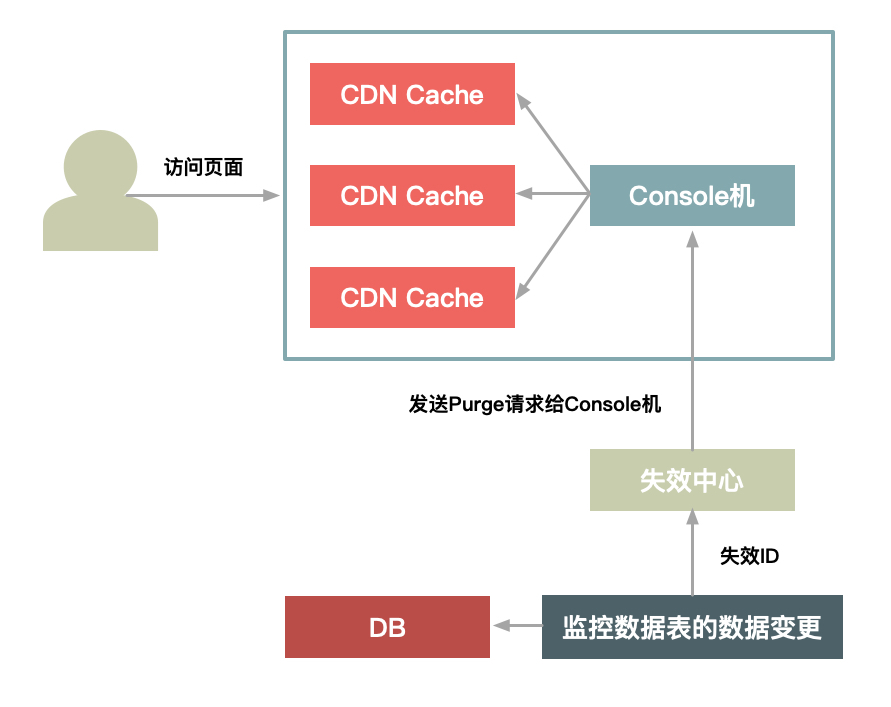
这种失效有失效中心将失效请求发送给每个CDN节点上的Console机,然后Console机来发送失效请求给每台Cache机器。
参考资料
https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/%e5%a6%82%e4%bd%95%e8%ae%be%e8%ae%a1%e4%b8%80%e4%b8%aa%e7%a7%92%e6%9d%80%e7%b3%bb%e7%bb%9f/08%20%e7%ad%94%e7%96%91%e8%a7%a3%e6%83%91%ef%bc%9a%e7%bc%93%e5%ad%98%e5%a4%b1%e6%95%88%e7%9a%84%e7%ad%96%e7%95%a5%e5%ba%94%e8%af%a5%e6%80%8e%e4%b9%88%e5%ae%9a%ef%bc%9f.md
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
