05 容器CPU(1):怎么限制容器的CPU使用? 你好,我是程远。今天我们来聊一聊容器里僵尸进程这个问题。
说起僵尸进程,相信你并不陌生。很多面试官经常会问到这个知识点,用来考察候选人的操作系统背景。通过这个问题,可以了解候选人对Linux进程管理和信号处理这些基础知识的理解程度,他的基本功扎不扎实。
所以,今天我们就一起来看看容器里为什么会产生僵尸进程,然后去分析如何怎么解决。
通过这一讲,你就会对僵尸进程的产生原理有一个清晰的认识,也会更深入地理解容器init进程的特性。
问题再现
我们平时用容器的时候,有的同学会发现,自己的容器运行久了之后,运行ps命令会看到一些进程,进程名后面加了标识。那么你自然会有这样的疑问,这些是什么进程呢?
你可以自己做个容器镜像来模拟一下,我们先下载这个例子,运行
make image 之后,再启动容器。
在容器里我们可以看到,1号进程fork出1000个子进程。当这些子进程运行结束后,它们的进程名字后面都加了标识。
从它们的Z stat(进程状态)中我们可以知道,这些都是僵尸进程(Zombie Process)。运行top命令,我们也可以看到输出的内容显示有
1000 zombie
进程。
/# docker run –name zombie-proc -d registry/zombie-proc:v1 02dec161a9e8b18922bd3599b922dbd087a2ad60c9b34afccde7c91a463bde8a /# docker exec -it zombie-proc bash /# ps aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.0 4324 1436 ? Ss 01:23 0:00 /app-test 1000 root 6 0.0 0.0 0 0 ? Z 01:23 0:00 [app-test]
那么问题来了,什么是僵尸进程?它们是怎么产生的?僵尸进程太多会导致什么问题?想要回答这些问题,我们就要从进程状态的源头学习,看看僵尸进程到底处于进程整个生命周期里的哪一环。
知识详解
Linux的进程状态
无论进程还是线程,在Linux内核里其实都是用 task_struct{}这个结构来表示的。它其实就是任务(task),也就是Linux里基本的调度单位。为了方便讲解,我们在这里暂且称它为进程。
那一个进程从创建(fork)到退出(exit),这个过程中的状态转化还是很简单的。
下面这个图是 《Linux Kernel Development》这本书里的Linux进程状态转化图。
我们从这张图中可以看出来,在进程“活着”的时候就只有两个状态:运行态(TASK_RUNNING)和睡眠态(TASK_INTERRUPTIBLE,TASK_UNINTERRUPTIBLE)。
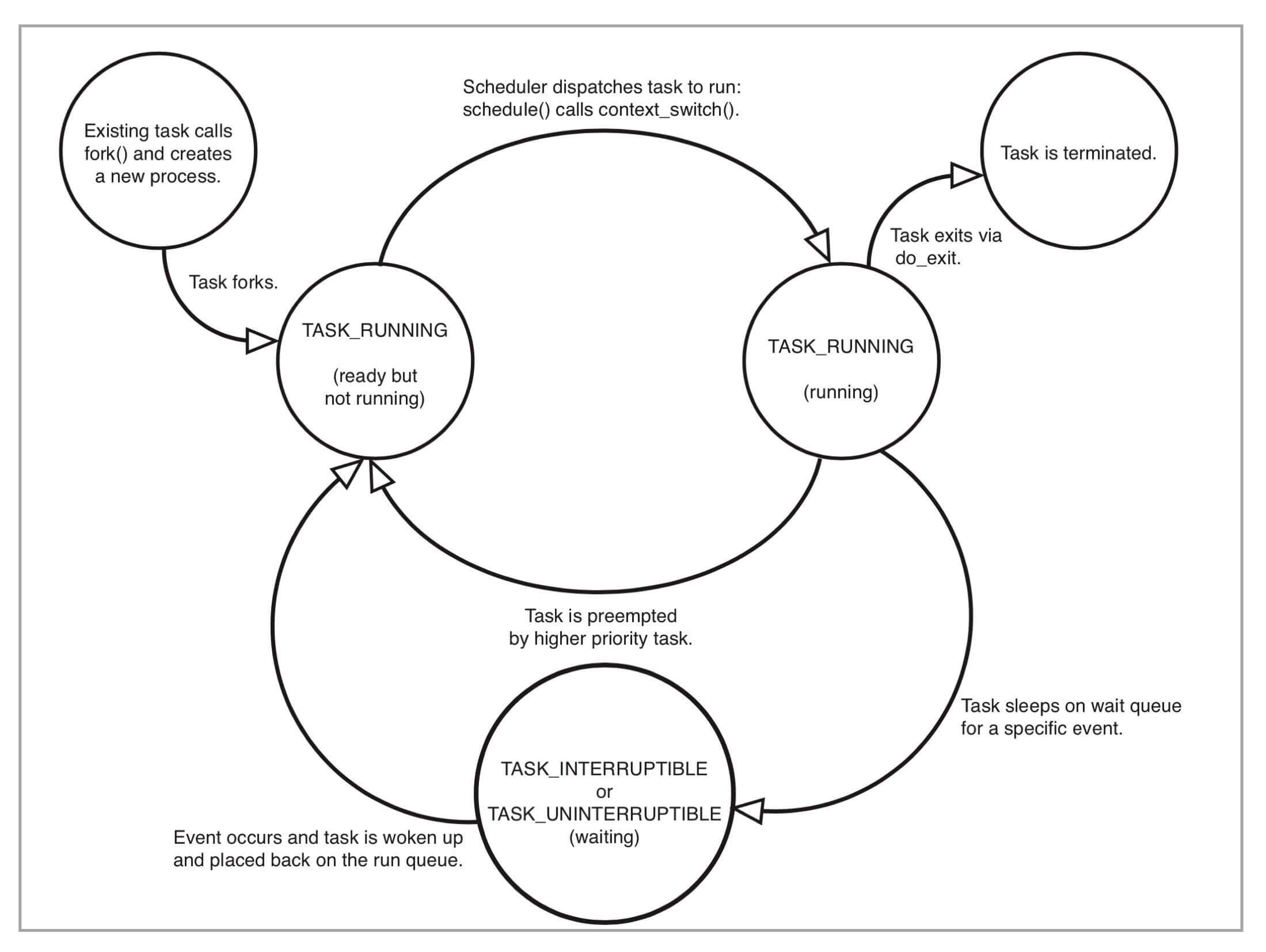
那运行态和睡眠态这两种状态分别是什么意思呢?
运行态的意思是,无论进程是正在运行中(也就是获得了CPU资源),还是进程在run queue队列里随时可以运行,都处于这个状态。
我们想要查看进程是不是处于运行态,其实也很简单,比如使用ps命令,可以看到处于这个状态的进程显示的是R stat。
睡眠态是指,进程需要等待某个资源而进入的状态,要等待的资源可以是一个信号量(Semaphore), 或者是磁盘I/O,这个状态的进程会被放入到wait queue队列里。
这个睡眠态具体还包括两个子状态:一个是可以被打断的(TASK_INTERRUPTIBLE),我们用ps查看到的进程,显示为S stat。还有一个是不可被打断的(TASK_UNINTERRUPTIBLE),用ps查看进程,就显示为D stat。
这两个子状态,我们在后面的课程里碰到新的问题时,会再做详细介绍,这里你只要知道这些就行了。
除了上面进程在活的时候的两个状态,进程在调用do_exit()退出的时候,还有两个状态。
一个是 EXIT_DEAD,也就是进程在真正结束退出的那一瞬间的状态;第二个是 EXIT_ZOMBIE状态,这是进程在EXIT_DEAD前的一个状态,而我们今天讨论的僵尸进程,也就是处于这个状态中。
限制容器中进程数目
理解了Linux进程状态之后,我们还需要知道,在Linux系统中怎么限制进程数目。因为弄清楚这个问题,我们才能更深入地去理解僵尸进程的危害。
一台Linux机器上的进程总数目是有限制的。如果超过这个最大值,那么系统就无法创建出新的进程了,比如你想SSH登录到这台机器上就不行了。
这个最大值可以我们在 /proc/sys/kernel/pid_max这个参数中看到。
Linux内核在初始化系统的时候,会根据机器CPU的数目来设置pid_max的值。
比如说,如果机器中CPU数目小于等于32,那么pid_max就会被设置为32768(32K);如果机器中的CPU数目大于32,那么pid_max就被设置为 N/*1024 (N就是CPU数目)。
对于Linux系统而言,容器就是一组进程的集合。如果容器中的应用创建过多的进程或者出现bug,就会产生类似fork bomb的行为。
这个fork bomb就是指在计算机中,通过不断建立新进程来消耗系统中的进程资源,它是一种黑客攻击方式。这样,容器中的进程数就会把整个节点的可用进程总数给消耗完。
这样,不但会使同一个节点上的其他容器无法工作,还会让宿主机本身也无法工作。所以对于每个容器来说,我们都需要限制它的最大进程数目,而这个功能由pids Cgroup这个子系统来完成。
而这个功能的实现方法是这样的:pids Cgroup通过Cgroup文件系统的方式向用户提供操作接口,一般它的Cgroup文件系统挂载点在 /sys/fs/cgroup/pids。
在一个容器建立之后,创建容器的服务会在/sys/fs/cgroup/pids下建立一个子目录,就是一个控制组,控制组里最关键的一个文件就是pids.max。我们可以向这个文件写入数值,而这个值就是这个容器中允许的最大进程数目。
我们对这个值做好限制,容器就不会因为创建出过多进程而影响到其他容器和宿主机了。思路讲完了,接下来我们就实际上手试一试。
下面是对一个Docker容器的pids Cgroup的操作,你可以跟着操作一下。 /# pwd /sys/fs/cgroup/pids /# df ./ Filesystem 1K-blocks Used Available Use% Mounted on cgroup 0 0 0 - /sys/fs/cgroup/pids /# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 7ecd3aa7fdc1 registry/zombie-proc:v1 “/app-test 1000” 37 hours ago Up 37 hours frosty_yalow /# pwd /sys/fs/cgroup/pids/system.slice/docker-7ecd3aa7fdc15a1e183813b1899d5d939beafb11833ad6c8b0432536e5b9871c.scope /# ls cgroup.clone_children cgroup.procs notify_on_release pids.current pids.events pids.max tasks /# echo 1002 > pids.max /# cat pids.max 1002
解决问题
刚才我给你解释了两个基本概念,进程状态和进程数目限制,那我们现在就可以解决容器中的僵尸进程问题了。
在前面Linux进程状态的介绍里,我们知道了,僵尸进程是Linux进程退出状态的一种。
从内核进程的do_exit()函数我们也可以看到,这时候进程task_struct里的mm/shm/sem/files等文件资源都已经释放了,只留下了一个stask_struct instance空壳。
就像下面这段代码显示的一样,从进程对应的/proc/ 文件目录下,我们也可以看出来,对应的资源都已经没有了。 /# cat /proc/6/cmdline /# cat /proc/6/smaps /# cat /proc/6/maps /# ls /proc/6/fd
并且,这个进程也已经不响应任何的信号了,无论SIGTERM(15)还是SIGKILL(9)。例如上面pid 6的僵尸进程,这两个信号都已经被响应了。
| /# kill -15 6 /# kill -9 6 /# ps -ef | grep 6 root 6 1 0 13:59 ? 00:00:00 [app-test] |
当多个容器运行在同一个宿主机上的时候,为了避免一个容器消耗完我们整个宿主机进程号资源,我们会配置pids Cgroup来限制每个容器的最大进程数目。也就是说,进程数目在每个容器中也是有限的,是一种很宝贵的资源。
既然进程号资源在宿主机上是有限的,显然残留的僵尸进程多了以后,给系统带来最大问题就是它占用了进程号。这就意味着,残留的僵尸进程,在容器里仍然占据着进程号资源,很有可能会导致新的进程不能运转。
这里我再次借用开头的那个例子,也就是一个产生了1000个僵尸进程的容器,带你理解一下这个例子中进程数的上限。我们可以看一下,1个init进程+1000个僵尸进程+1个bash进程 ,总共就是1002个进程。
如果pids Cgroup也限制了这个容器的最大进程号的数量,限制为1002的话,我们在pids Cgroup里可以看到,pids.current == pids.max,也就是已经达到了容器进程号数的上限。
这时候,如果我们在容器里想再启动一个进程,例如运行一下ls命令,就会看到
Resource temporarily unavailable 的错误消息。已经退出的无用进程,却阻碍了有用进程的启动,显然这样是不合理的。
具体代码如下: /#/#/# On host /# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 09e6e8e16346 registry/zombie-proc:v1 “/app-test 1000” 29 minutes ago Up 29 minutes peaceful_ritchie /# pwd /sys/fs/cgroup/pids/system.slice/docker-09e6e8e1634612580a03dd3496d2efed2cf2a510b9688160b414ce1d1ea3e4ae.scope /# cat pids.max 1002 /# cat pids.current 1002 /#/#/# On Container [root@09e6e8e16346 /]/# ls bash: fork: retry: Resource temporarily unavailable bash: fork: retry: Resource temporarily unavailable
所以,接下来我们还要看看这些僵尸进程到底是怎么产生的。因为只有理解它的产生机制,我们才能想明白怎么避免僵尸进程的出现。
我们先看一下刚才模拟僵尸进程的那段小程序。这段程序里,父进程在创建完子进程之后就不管了,这就是造成子进程变成僵尸进程的原因。
/#include
前面我们通过分析,发现子进程变成僵尸进程的原因在于父进程“不负责”,那找到原因后,我们再想想,如何来解决。
其实解决思路很好理解,就好像熊孩子犯了事儿,你要去找他家长来管教,那子进程在容器里“赖着不走”,我们就需要让父进程出面处理了。
所以,在Linux中的进程退出之后,如果进入僵尸状态,我们就需要父进程调用wait()这个系统调用,去回收僵尸进程的最后的那些系统资源,比如进程号资源。
那么,我们在刚才那段代码里,主进程进入sleep(100)之前,加上一段wait()函数调用,就不会出现僵尸进程的残留了。 for (i = 0; i < total; i++) { int status; wait(&status); }
而容器中所有进程的最终父进程,就是我们所说的init进程,由它负责生成容器中的所有其他进程。因此,容器的init进程有责任回收容器中的所有僵尸进程。
前面我们知道了wait()系统调用可以回收僵尸进程,但是wait()系统调用有一个问题,需要你注意。
wait()系统调用是一个阻塞的调用,也就是说,如果没有子进程是僵尸进程的话,这个调用就一直不会返回,那么整个进程就会被阻塞住,而不能去做别的事了。
不过这也没有关系,我们还有另一个方法处理。Linux还提供了一个类似的系统调用waitpid(),这个调用的参数更多。
其中就有一个参数WNOHANG,它的含义就是,如果在调用的时候没有僵尸进程,那么函数就马上返回了,而不会像wait()调用那样一直等待在那里。
比如社区的一个容器init项目tini。在这个例子中,它的主进程里,就是不断在调用带WNOHANG参数的waitpid(),通过这个方式清理容器中所有的僵尸进程。 int reap_zombies(const pid_t child_pid, int/* const child_exitcode_ptr) { pid_t current_pid; int current_status; while (1) { current_pid = waitpid(-1, ¤t_status, WNOHANG); switch (current_pid) { case -1: if (errno == ECHILD) { PRINT_TRACE(“No child to wait”); break; } …
重点总结
今天我们讨论的问题是容器中的僵尸进程。
首先,我们先用代码来模拟了这个情况,还原了在一个容器中大量的僵尸进程是如何产生的。为了理解它的产生原理和危害,我们先要掌握两个知识点:
- Linux进程状态中,僵尸进程处于EXIT_ZOMBIE这个状态;
- 容器需要对最大进程数做限制。具体方法是这样的,我们可以向Cgroup中 pids.max这个文件写入数值(这个值就是这个容器中允许的最大进程数目)。
掌握了基本概念之后,我们找到了僵尸进程的产生原因。父进程在创建完子进程之后就不管了。
所以,我们需要父进程调用wait()或者waitpid()系统调用来避免僵尸进程产生。
关于本节内容,你只要记住下面三个主要的知识点就可以了:
- 每一个Linux进程在退出的时候都会进入一个僵尸状态(EXIT_ZOMBIE);
- 僵尸进程如果不清理,就会消耗系统中的进程数资源,最坏的情况是导致新的进程无法启动;
- 僵尸进程一定需要父进程调用wait()或者waitpid()系统调用来清理,这也是容器中init进程必须具备的一个功能。
思考题
如果容器的init进程创建了子进程B,B又创建了自己的子进程C。如果C运行完之后,退出成了僵尸进程,B进程还在运行,而容器的init进程还在不断地调用waitpid(),那C这个僵尸进程可以被回收吗?
欢迎留言和我分享你的想法。如果你的朋友也被僵尸进程占用资源而困扰,欢迎你把这篇文章分享给他,也许就能帮他解决一个问题。
参考资料
https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/%e5%ae%b9%e5%99%a8%e5%ae%9e%e6%88%98%e9%ab%98%e6%89%8b%e8%af%be/05%20%e5%ae%b9%e5%99%a8CPU%ef%bc%881%ef%bc%89%ef%bc%9a%e6%80%8e%e4%b9%88%e9%99%90%e5%88%b6%e5%ae%b9%e5%99%a8%e7%9a%84CPU%e4%bd%bf%e7%94%a8%ef%bc%9f.md
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
