09 Page Cache:为什么我的容器内存使用量总是在临界点 你好,我是程远。
上一讲,我们讲了Memory Cgroup是如何控制一个容器的内存的。我们已经知道了,如果容器使用的物理内存超过了Memory Cgroup里的memory.limit_in_bytes值,那么容器中的进程会被OOM Killer杀死。
不过在一些容器的使用场景中,比如容器里的应用有很多文件读写,你会发现整个容器的内存使用量已经很接近Memory Cgroup的上限值了,但是在容器中我们接着再申请内存,还是可以申请出来,并且没有发生OOM。
这是怎么回事呢?今天这一讲我就来聊聊这个问题。
问题再现
我们可以用这里的代码做个容器镜像,然后用下面的这个脚本启动容器,并且设置容器Memory Cgroup里的内存上限值是100MB(104857600bytes)。
#!/bin/bash
docker stop page_cache;docker rm page_cache
if [ ! -f ./test.file ]
then
dd if=/dev/zero of=./test.file bs=4096 count=30000
echo "Please run start_container.sh again "
exit 0
fi
echo 3 > /proc/sys/vm/drop_caches
sleep 10
docker run -d --init --name page_cache -v $(pwd):/mnt registry/page_cache_test:v1
CONTAINER_ID=$(sudo docker ps --format "{{.ID}}\t{{.Names}}" | grep -i page_cache | awk '{print $1}')
echo $CONTAINER_ID
CGROUP_CONTAINER_PATH=$(find /sys/fs/cgroup/memory/ -name "*$CONTAINER_ID*")
echo 104857600 > $CGROUP_CONTAINER_PATH/memory.limit_in_bytes
cat $CGROUP_CONTAINER_PATH/memory.limit_in_bytes
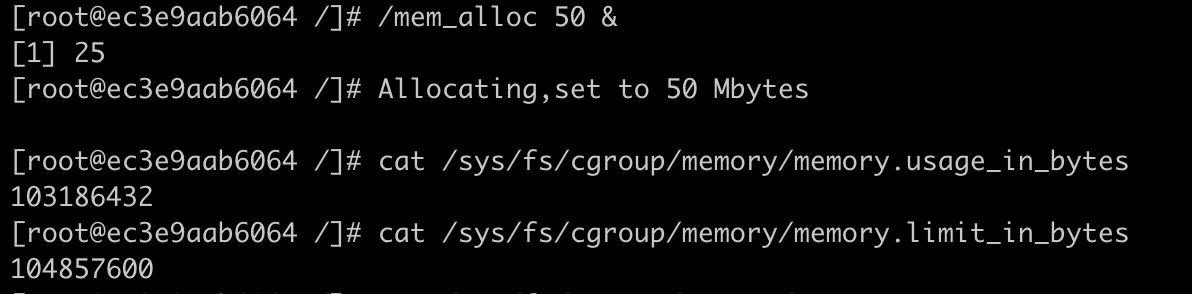
把容器启动起来后,我们查看一下容器的Memory Cgroup下的memory.limit_in_bytes和memory.usage_in_bytes这两个值。
如下图所示,我们可以看到容器内存的上限值设置为104857600bytes(100MB),而这时整个容器的已使用内存显示为104767488bytes,这个值已经非常接近上限值了。
我们把容器内存上限值和已使用的内存数值做个减法,104857600–104767488= 90112bytes,只差大概90KB左右的大小。

但是,如果这时候我们继续启动一个程序,让这个程序申请并使用50MB的物理内存,就会发现这个程序还是可以运行成功,这时候容器并没有发生OOM的情况。
这时我们再去查看参数memory.usage_in_bytes,就会发现它的值变成了103186432bytes,比之前还少了一些。那这是怎么回事呢?
知识详解:Linux系统有那些内存类型?
要解释刚才我们看到的容器里内存分配的现象,就需要先理解Linux操作系统里有哪几种内存的类型。
因为我们只有知道了内存的类型,才能明白每一种类型的内存,容器分别使用了多少。而且,对于不同类型的内存,一旦总内存增高到容器里内存最高限制的数值,相应的处理方式也不同。
Linux内存类型
Linux的各个模块都需要内存,比如内核需要分配内存给页表,内核栈,还有slab,也就是内核各种数据结构的Cache Pool;用户态进程里的堆内存和栈的内存,共享库的内存,还有文件读写的Page Cache。
在这一讲里,我们讨论的Memory Cgroup里都不会对内核的内存做限制(比如页表,slab等)。所以我们今天主要讨论与用户态相关的两个内存类型,RSS和Page Cache。
RSS
先看什么是RSS。RSS是Resident Set Size的缩写,简单来说它就是指进程真正申请到物理页面的内存大小。这是什么意思呢?
应用程序在申请内存的时候,比如说,调用malloc()来申请100MB的内存大小,malloc()返回成功了,这时候系统其实只是把100MB的虚拟地址空间分配给了进程,但是并没有把实际的物理内存页面分配给进程。
上一讲中,我给你讲过,当进程对这块内存地址开始做真正读写操作的时候,系统才会把实际需要的物理内存分配给进程。而这个过程中,进程真正得到的物理内存,就是这个RSS了。
比如下面的这段代码,我们先用malloc申请100MB的内存。
p = malloc(100 * MB);
if (p == NULL)
return 0;
然后,我们运行top命令查看这个程序在运行了malloc()之后的内存,我们可以看到这个程序的虚拟地址空间(VIRT)已经有了106728KB(~100MB),但是实际的物理内存RSS(top命令里显示的是RES,就是Resident的简写,和RSS是一个意思)在这里只有688KB。

接着我们在程序里等待30秒之后,我们再对这块申请的空间里写入20MB的数据。
sleep(30);
memset(p, 0x00, 20 /* MB)
当我们用memset()函数对这块地址空间写入20MB的数据之后,我们再用top查看,这时候可以看到虚拟地址空间(VIRT)还是106728,不过物理内存RSS(RES)的值变成了21432(大小约为20MB), 这里的单位都是KB。

所以,通过刚才上面的小实验,我们可以验证RSS就是进程里真正获得的物理内存大小。
对于进程来说,RSS内存包含了进程的代码段内存,栈内存,堆内存,共享库的内存, 这些内存是进程运行所必须的。刚才我们通过malloc/memset得到的内存,就是属于堆内存。
具体的每一部分的RSS内存的大小,你可以查看/proc/[pid]/smaps文件。
Page Cache
每个进程除了各自独立分配到的RSS内存外,如果进程对磁盘上的文件做了读写操作,Linux还会分配内存,把磁盘上读写到的页面存放在内存中,这部分的内存就是Page Cache。
Page Cache的主要作用是提高磁盘文件的读写性能,因为系统调用read()和write()的缺省行为都会把读过或者写过的页面存放在Page Cache里。
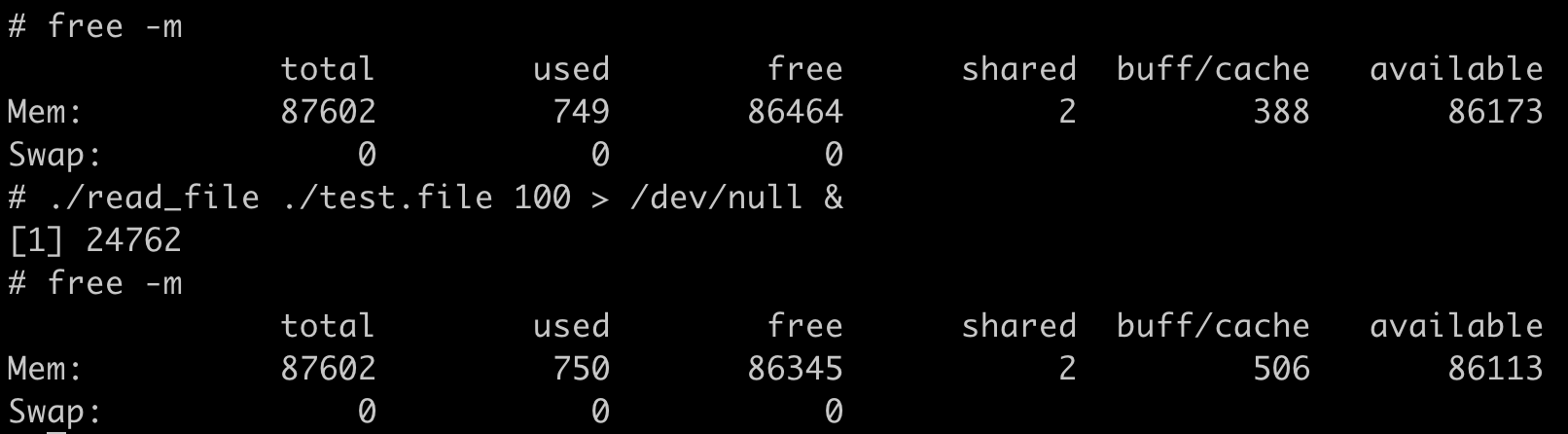
还是用我们这一讲最开始的的例子:代码程序去读取100MB的文件,在读取文件前,系统中Page Cache的大小是388MB,读取后Page Cache的大小是506MB,增长了大约100MB左右,多出来的这100MB,正是我们读取文件的大小。
在Linux系统里只要有空闲的内存,系统就会自动地把读写过的磁盘文件页面放入到Page Cache里。那么这些内存都被Page Cache占用了,一旦进程需要用到更多的物理内存,执行malloc()调用做申请时,就会发现剩余的物理内存不够了,那该怎么办呢?
这就要提到Linux的内存管理机制了。 Linux的内存管理有一种内存页面回收机制(page frame reclaim),会根据系统里空闲物理内存是否低于某个阈值(wartermark),来决定是否启动内存的回收。
内存回收的算法会根据不同类型的内存以及内存的最近最少用原则,就是LRU(Least Recently Used)算法决定哪些内存页面先被释放。因为Page Cache的内存页面只是起到Cache作用,自然是会被优先释放的。
所以,Page Cache是一种为了提高磁盘文件读写性能而利用空闲物理内存的机制。同时,内存管理中的页面回收机制,又能保证Cache所占用的页面可以及时释放,这样一来就不会影响程序对内存的真正需求了。
RSS & Page Cache in Memory Cgroup
学习了RSS和Page Cache的基本概念之后,我们下面来看不同类型的内存,特别是RSS和Page Cache是如何影响Memory Cgroup的工作的。
我们先从Linux的内核代码看一下,从mem_cgroup_charge_statistics()这个函数里,我们可以看到Memory Cgroup也的确只是统计了RSS和Page Cache这两部分的内存。
RSS的内存,就是在当前Memory Cgroup控制组里所有进程的RSS的总和;而Page Cache这部分内存是控制组里的进程读写磁盘文件后,被放入到Page Cache里的物理内存。
Memory Cgroup控制组里RSS内存和Page Cache内存的和,正好是memory.usage_in_bytes的值。
当控制组里的进程需要申请新的物理内存,而且memory.usage_in_bytes里的值超过控制组里的内存上限值memory.limit_in_bytes,这时我们前面说的Linux的内存回收(page frame reclaim)就会被调用起来。
那么在这个控制组里的page cache的内存会根据新申请的内存大小释放一部分,这样我们还是能成功申请到新的物理内存,整个控制组里总的物理内存开销memory.usage_in_bytes 还是不会超过上限值memory.limit_in_bytes。
解决问题
明白了Memory Cgroup中内存类型的统计方法,我们再回过头看这一讲开头的问题,为什么memory.usage_in_bytes与memory.limit_in_bytes的值只相差了90KB,我们在容器中还是可以申请出50MB的物理内存?
我想你应该已经知道答案了,容器里肯定有大于50MB的内存是Page Cache,因为作为Page Cache的内存在系统需要新申请物理内存的时候(作为RSS)是可以被释放的。
知道了这个答案,那么我们怎么来验证呢?验证的方法也挺简单的,在Memory Cgroup中有一个参数memory.stat,可以显示在当前控制组里各种内存类型的实际的开销。
那我们还是拿这一讲的容器例子,再跑一遍代码,这次要查看一下memory.stat里的数据。
第一步,我们还是用同样的脚本来启动容器,并且设置好容器的Memory Cgroup里的memory.limit_in_bytes值为100MB。
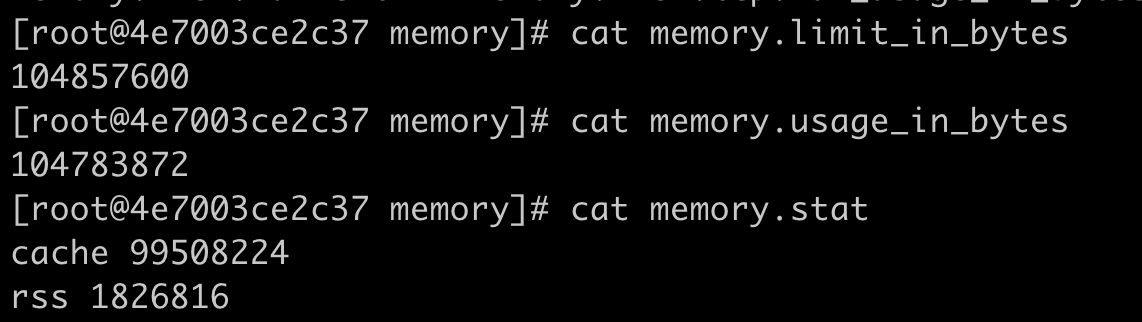
启动容器后,这次我们不仅要看memory.usage_in_bytes的值,还要看一下memory.stat。虽然memory.stat里的参数有不少,但我们目前只需要关注”cache”和”rss”这两个值。
我们可以看到,容器启动后,cache,也就是Page Cache占的内存是99508224bytes,大概是99MB,而RSS占的内存只有1826816bytes,也就是1MB多一点。
这就意味着,在这个容器的Memory Cgroup里大部分的内存都被用作了Page Cache,而这部分内存是可以被回收的。
那么我们再执行一下我们的mem_alloc程序,申请50MB的物理内存。
我们可以再来查看一下memory.stat,这时候cache的内存值降到了46632960bytes,大概46MB,而rss的内存值到了54759424bytes,54MB左右吧。总的memory.usage_in_bytes值和之前相比,没有太多的变化。
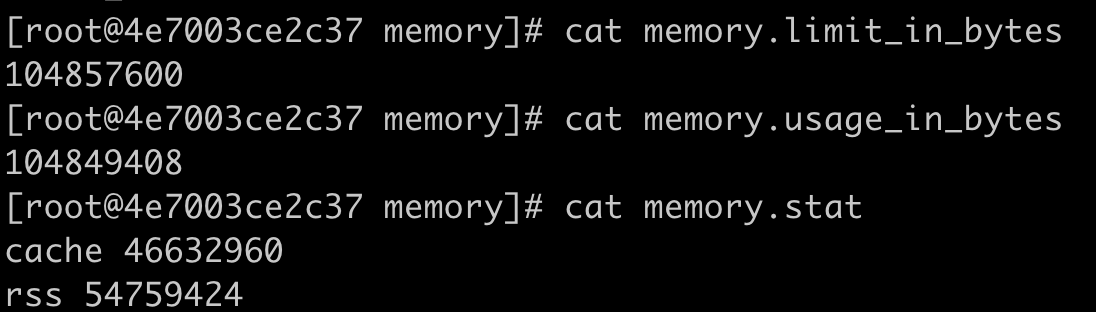
从这里我们发现,Page Cache内存对我们判断容器实际内存使用率的影响,目前Page Cache完全就是Linux内核的一个自动的行为,只要读写磁盘文件,只要有空闲的内存,就会被用作Page Cache。
所以,判断容器真实的内存使用量,我们不能用Memory Cgroup里的memory.usage_in_bytes,而需要用memory.stat里的rss值。这个很像我们用free命令查看节点的可用内存,不能看”free”字段下的值,而要看除去Page Cache之后的”available”字段下的值。
重点总结
这一讲我想让你知道,每个容器的Memory Cgroup在统计每个控制组的内存使用时包含了两部分,RSS和Page Cache。
RSS是每个进程实际占用的物理内存,它包括了进程的代码段内存,进程运行时需要的堆和栈的内存,这部分内存是进程运行所必须的。
Page Cache是进程在运行中读写磁盘文件后,作为Cache而继续保留在内存中的,它的目的是为了提高磁盘文件的读写性能。
当节点的内存紧张或者Memory Cgroup控制组的内存达到上限的时候,Linux会对内存做回收操作,这个时候Page Cache的内存页面会被释放,这样空出来的内存就可以分配给新的内存申请。
正是Page Cache内存的这种Cache的特性,对于那些有频繁磁盘访问容器,我们往往会看到它的内存使用率一直接近容器内存的限制值(memory.limit_in_bytes)。但是这时候,我们并不需要担心它内存的不够, 我们在判断一个容器的内存使用状况的时候,可以把Page Cache这部分内存使用量忽略,而更多的考虑容器中RSS的内存使用量。
思考题
在容器里启动一个写磁盘文件的程序,写入100MB的数据,查看写入前和写入后,容器对应的Memory Cgroup里memory.usage_in_bytes的值以及memory.stat里的rss/cache值。
欢迎在留言区写下你的思考或疑问,我们一起交流探讨。如果这篇文章让你有所收获,也欢迎你分享给更多的朋友,一起学习进步。
参考资料
https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/%e5%ae%b9%e5%99%a8%e5%ae%9e%e6%88%98%e9%ab%98%e6%89%8b%e8%af%be/09%20Page%20Cache%ef%bc%9a%e4%b8%ba%e4%bb%80%e4%b9%88%e6%88%91%e7%9a%84%e5%ae%b9%e5%99%a8%e5%86%85%e5%ad%98%e4%bd%bf%e7%94%a8%e9%87%8f%e6%80%bb%e6%98%af%e5%9c%a8%e4%b8%b4%e7%95%8c%e7%82%b9.md
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
