14 非线性降维:流形学习 “云行雨施,品物流形”,这是儒家经典《易经》对万物流变的描述。两千多年之后,“流形”一词被数学家借鉴,用于命名与欧几里得空间局部同胚的拓扑空间。
虽然流形这个词本身有着浓厚的学院派味道,但它的思想你却一点儿不会陌生。最著名的流形模型恐怕非瑞士卷(Swiss roll)莫属。如图所示的瑞士卷是常见的糕点,只是它的名字未必像它的形状一样广为人知。瑞士卷实际上是一张卷起来的薄蛋糕片,虽然卷曲的操作将它从二维形状升级成了三维形状,但这个多出来的空间维度并没有产生关于原始结构的新信息,所以瑞士卷实际上就是嵌入三维空间的二维流形。
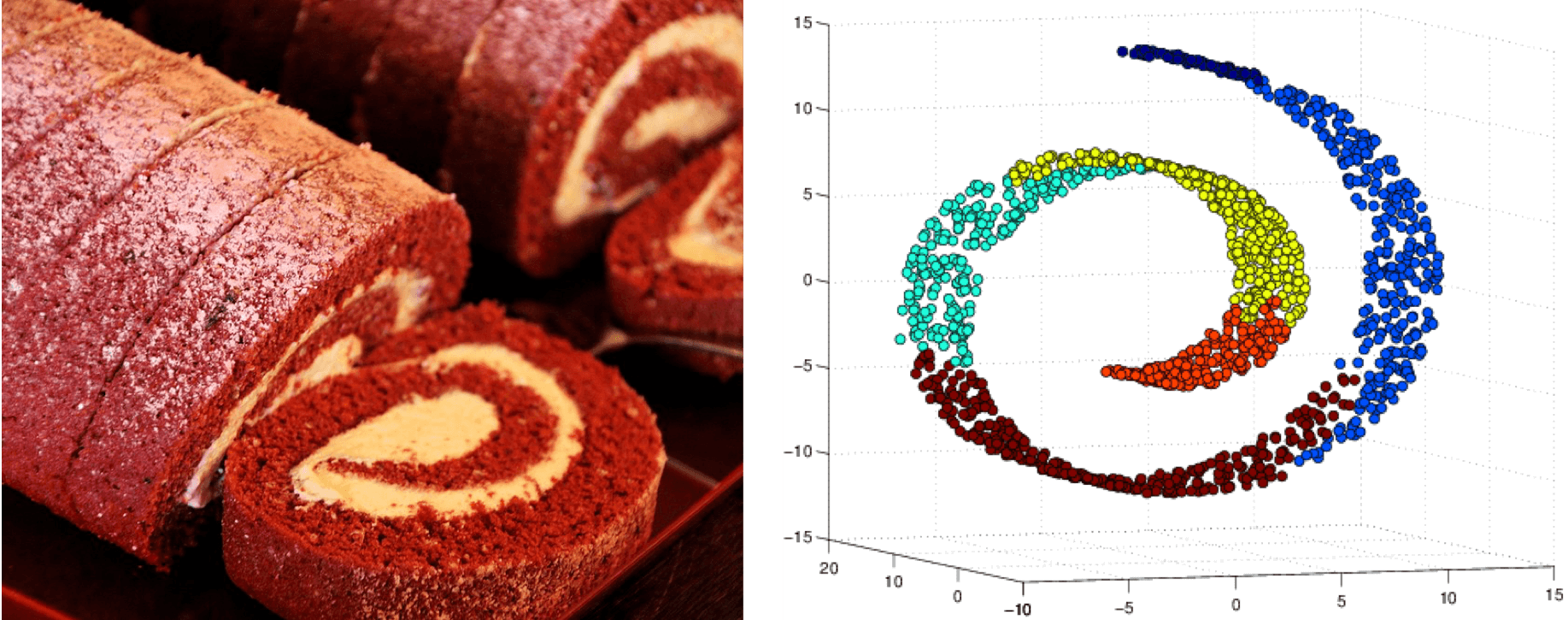
瑞士卷(左)与瑞士卷流形(右)示意图
图片来自维基百科与http://yinsenm.github.io/figure/STAT545/Swiss.png
{kind=link}
在机器学习中,流形(manifold)指的是嵌入在高维数据空间中的低维子空间,它的维数是低维数据变化的自由度(degree of freedom of variability),也叫作固有维度(intrinsic dimensionality)。流形学习(manifold learning)正是通过挖掘数据的内在结构实现向固有维度的降维,从而找到与高维原数据对应的低维嵌入流形。
和主成分分析相比,流形可以是线性的,但更多是非线性的。正因如此,流形学习通常被视为非线性降维方法的代表。它不仅能够缓解维数灾难的影响,还具有比线性降维方法更强的特征表达能力。除了非线性外,流形学习的方法一般还是非参数的,这使流形能够更加自由地表示数据的固有维度和聚类特性,但也让它对噪声更加敏感。
要将数据从高维空间映射到低维流形上,首先要确定低维流形的结构,其次要确定高维空间到低维流形的映射关系。可在实际问题中,不管是流形结构还是流形维数都不是已知的,因此有必要做出一些先验假设以缩小问题的解空间。当关于流形的假设聚焦在数据的几何性质上时,就可以得到多维缩放(multiple dimensional scaling)算法。
在确定流形结构时,多维缩放让高维空间上的样本之间的距离在低维空间上尽可能得以保持,以距离重建误差的最小化为原则计算所有数据点两两之间的距离矩阵。根据降维前后距离保持不变的特点,距离矩阵又可以转化为内积矩阵。利用和主成分分析类似的方法可以从高维空间上的内积矩阵构造出从低维空间到高维空间的嵌入,其数学细节在此就不赘述了。
可是,原始高维空间与约化低维空间距离的等效性是不是一个合理的假设呢?想象一下你手边有个地球仪,这个三维的球体实际上也是由二维的世界地图卷成,因而可以约化成一个二维的流形。如果要在流形上计算北京和纽约两个城市的距离,就要在地球仪上勾出两点之间的“直线”,也就是沿着地球表面计算出的两个城市之间的直线距离。但需要注意的是,这条地图上的直线在二维流形上是体现为曲线的。
这样计算出的流形上的距离是否等于三维空间中的距离呢?答案是否定的。北京和纽约两点在三维空间中的欧氏距离对应的是三维空间中的直线,而这条直线位于地球仪的内部——按照这种理解距离的方式,从北京去纽约应该坐一趟穿越地心的直达地铁。这说明多维缩放方法虽然考虑了距离的等效性,却没能将这种等效性放在数据特殊结构的背景下去考虑。它忽略了高维空间中的直线距离在低维空间上不可到达的问题,得到的结果也就难以真实反映数据的特征。
吸取了多维缩放的经验教训,美国斯坦福大学的约书亚·泰宁鲍姆(Joshua Tenenbaum)等人提出了等度量映射的非线性降维方法。等度量映射(isometric mapping)以数据所在的低维流形与欧氏空间子集的等距性为基础。在流形上,描述距离的指标是测地距离(geodesic distance),它就是在地图上连接北京和纽约那条直线的距离,也就是流形上两点之间的固有距离。
在流形结构和维度未知的前提下,测地距离是没法直接计算的。等度量映射对这个问题的解决方法是利用流形与欧氏空间局部同胚的性质,根据欧氏距离为每个点找到近邻点(neighbors),直接用欧氏距离来近似近邻点之间的测地距离。
在这种方法中,测地距离的计算就像是奥运火炬,在每一个火炬手,也就是每一个近邻点之间传递。将每个火炬手所走过的路程,也就是每两个近邻点之间的欧氏距离求和,得到的就是测地距离的近似。
在每一组近邻点之间建立连接就可以让所有数据点共同构成一张带权重的近邻连接图。在这张图上,相距较远的两点的测地距离就被等效为连接这两点的最短路径,这个问题可以使用图论和网络科学中发展非常成熟的Dijkstra算法来求解。计算出距离矩阵后,等度量映射的运算和多维缩放就完全一致了。
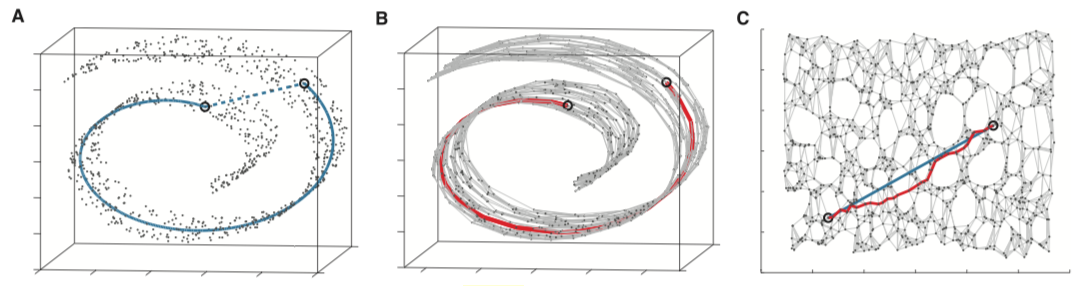
等距离映射原理示意图
图A表示测地距离与欧氏距离的区别,图B表示利用近邻点近似计算测地距离,图C表示真实测地距离与近似测地距离的比较,图片来自A global geometric framework for nonlinear dimensionality reduction, Science, vol. 290, 2319-2323
等度量映射关注的是全局意义上数据的几何结构,如果只关注数据在某些局部上的结构,其对应的方法就是局部线性嵌入。
局部线性嵌入(locally linear embedding)由伦敦大学学院的萨姆·洛维思(Sam Roweis)等人提出,其核心思想是待求解的低维流形在局部上是线性的,每个数据点都可以表示成近邻点的线性组合。求解流形的降维过程就是在保持每个邻域中的线性系数不变的基础上重构原数据点,使重构误差最小。
局部线性嵌入的实现包括两个步骤:在确定一个数据点的近邻点后,首先根据最小均方误差来计算用近邻点表示数据点的最优权值,需要注意的是所有权值之和是等于1的;接下来就要根据计算出的权值来重构原数据点在低维空间上的表示,其准则是重构的近邻点在已知权值下的线性组合与重构数据点具有最小均方误差。对重构映射的求解最终也可以转化为矩阵的特征值求解。
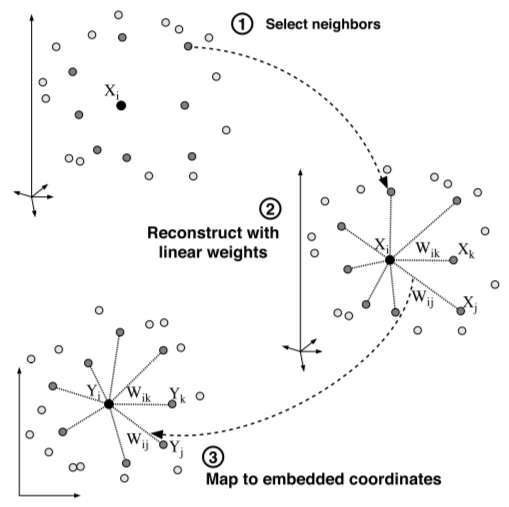
局部线性嵌入原理示意图
图A表示为数据点(X_i)选择近邻点,图B表示将(X_i)表示为近邻点的线性组合并计算系数(W_{i \cdot}),图C表示保持(W_{i \cdot})不变重构数据点(Y_i),图片来自Nonlinear dimensionality reduction by locally linear embedding, Science, vol. 290, 2323-2326
将两种典型的流形学习算法加以比较,不难发现它们的区别在于对流形与欧氏空间关系的理解上。流形与欧氏空间就像两个平行世界,将它们联系起来的羁绊是拓扑性质的保持。
等度量映射理如其名,它将距离视为空间变换过程中的不变量,强调的是不同数据点关系的不变性,以及数据全局结构的完整保持。打个比方,如果把全局结构看作一个拼图玩具,等度量映射的任务就是将每一块拼图所代表的邻域正确组合,从而构成完美的完整图案。
相比之下,局部线性嵌入在乎的只有数据关系在某个邻域上的不变性。数据点可以用它的邻近点在最小二乘意义下最优的线性组合表示,这个局部几何性质是不会改变的。可是在邻域之外,局部线性嵌入并不考虑相距较远的数据点之间关系的保持,颇有些“各人自扫门前雪,莫管他人瓦上霜”的意味。显然,局部线性嵌入在拼图时更加随意,只要把所有的拼图块按嵌入关系连成一片就可以了,至于拼出什么奇形怪状都不在话下。

基于全局信息的等度量映射(左)和基于局部信息的局部线性嵌入(右)
不管是等度量映射还是局部线性嵌入,都以几何性质作为同构的基础。如果要从概率角度理解流形学习,最具代表性的例子非随机近邻嵌入莫属。随机近邻嵌入(stochastic neighbor embedding)的核心特点是保持降维前后数据的概率分布不变,它将高维空间上数据点之间的欧氏距离转化为服从正态分布的条件概率
| [ p_{j | i} = \dfrac{\exp (- | x_i - x_j | ^ 2 / 2 \sigma_i^2)}{\sum_{k \ne i} \exp (- | x_i - x_j | ^ 2 / 2 \sigma_i^2} ] |
上式中的(\sigma_i)是困惑度参数(perplexity),可以近似地看成近邻点的数目。这个概率表达式来描述不同数据点之间的相似性。简单地说,相距越近的点形成近邻的概率越大,相似的概率也就越大。这就像我们在上学时按照身高排队一样,站在一起的人身高会更加接近,位于队首和队尾两个极端的人则会有较大的身高差。
映射到低维空间后,随机近邻嵌入按照和高维空间相同的方式计算低维空间上的条件概率,并要求两者尽可能地相似,也就是尽可能地保持数据间的相似性。重构的依据是让交叉熵(cross entropy),也就是KL散度(Kullback-Leibler divergence)最小化。
但KL散度不对称的特性会导致相聚较远的点体现为较大的散度差,为了使KL散度最小化,数据点映射到低维空间之后就会被压缩到极小的范围中。这就像一群学生突然被紧急集合到操场上,挤在一起之后根本分不清哪些人来自于哪个班,这就是所谓的拥挤问题(crowding problem)。
为了解决拥挤问题,深度学习的泰斗乔弗雷·辛顿和他的学生提出了(t)分布随机近邻嵌入((t)-distributed stochastic neighbor embedding)。
| 新算法主要做出了两点改进:首先是将由欧氏距离推导出的条件概率改写成对称的形式,也就是(p_{ij} = p_{ji} = (p_{i | j} + p_{j | i}) / 2),其次是令低维空间中的条件概率服从(t)分布(高维空间中的正态分布保持不变)。这两种改进的目的是一样的,那就是让相同结构的数据点在低维空间上更加致密,不同结构的数据点则更加疏远。事实证明,这一目的达到了。 |
线性可以看成是非线性的特例,从这个角度出发,概率主成分分析其实也可以归结到广义的流形学习范畴中。还记得前一篇文章的图片吗?两个满足正态分布的隐变量使数据分布呈现出类似煎饼的椭圆形状,这张煎饼实际上就是流形。煎饼所在的超平面显示的只是数据的投影,之所以选择这个平面来投影是因为数据的变化集中在这里。相比之下,数据在垂直于超平面的方向上方差较小,因而这些变化在降维时可以忽略不计。
既然都能实现数据的降维,那么以主成分分析为代表的线性方法和以流形学习为代表的非线性方法各自的优缺点在哪里呢?一言以蔽之,线性方法揭示数据的规律,非线性方法则揭示数据的结构。
主成分分析可以去除属性之间的共线性,通过特征提取揭示数据差异的本质来源,这为数据的分类提供了翔实的依据;而流形学习虽然不能解释非线性变化的意义,却可以挖掘出高维数据的隐藏结构并在二维或三维空间中直观显示,是数据可视化的利器,而不同的隐藏结构又可以作为特征识别的参考。
Scikit-learn中包括了执行流形学习的manifold模块,将常用的流形学习方法打包成内置类,调用Isomap、LocallyLinearEmbedding和TSNE等类就可以计算对应的流形,算法的细节都被隐藏在函数内部,只需要输入对应的参数即可。
用以上算法将多元线性回归的英超数据集投影到二维流形上,由于数据集中的数据点较少,各种算法中近邻点的数目都被设置为2个,得到的结果如下。可以看出,三种方式计算出的流形中似乎都存在这一些模式,但说明这些模式的意义可就不像将它们计算出来那么简单了。
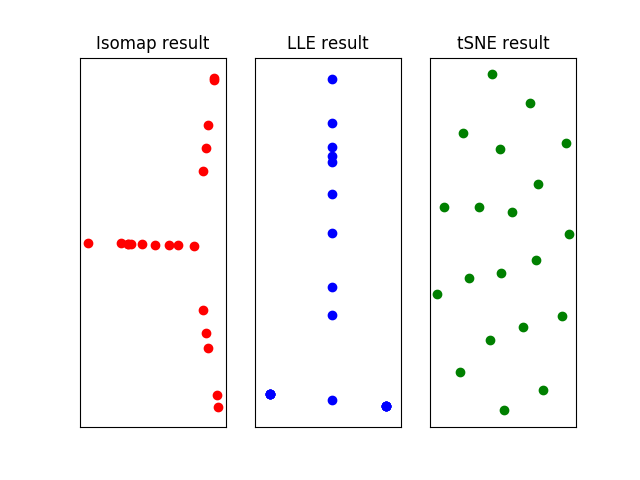
对英超数据集进行非线性降维的结果,使用的算法从左到右分别为等距离映射、局部线性嵌入和(t)分布随机近邻嵌入
今天我和你分享了几种典型的流形学习方法,但没有过多涉及这些方法的数学细节,感兴趣的话,你可以参考不同算法的原始论文。今天的内容要点如下:
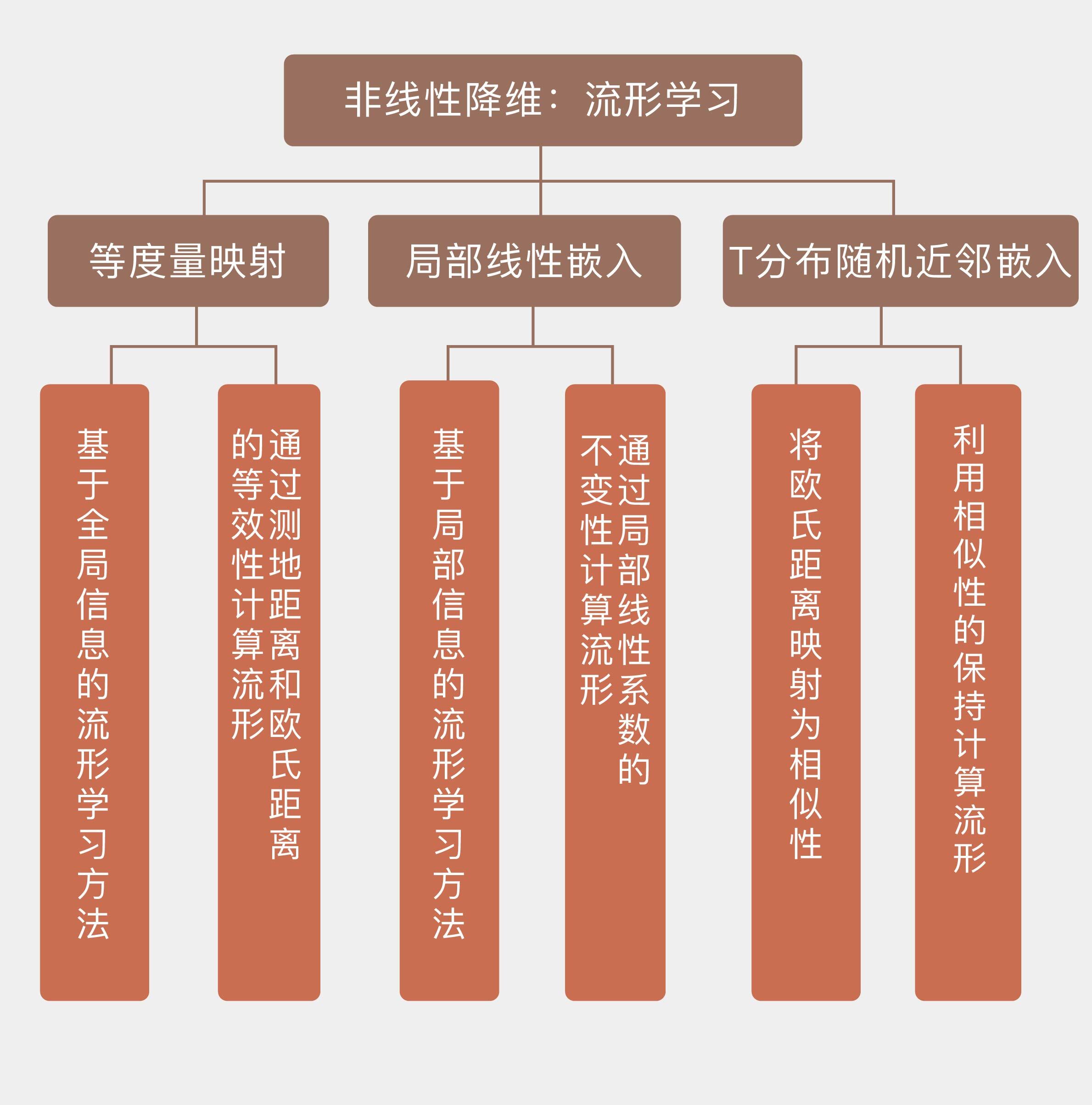
- 流形学习是非线性的降维方法,目的在于找到与高维数据对应的低维嵌入流形;
- 等度量映射是基于全局信息的流形学习方法,通过测地距离和欧氏距离的等效性计算流形;
- 局部线性嵌入是基于局部信息的流形学习方法,通过局部线性系数的不变性计算流形;
- (t)分布随机近邻嵌入将欧氏距离映射为相似性,利用相似性的保持计算流形。
从前文中英超数据集的流形可以看出,当现实中复杂的高维数据被映射到二维或三维流形上时,大呼神奇之后如何对得到的结果加以解释又是个棘手的问题。那么你觉得流形学习到底具有哪些实在的作用呢?
欢迎分享你的观点。
参考资料
https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/%e6%9c%ba%e5%99%a8%e5%ad%a6%e4%b9%a040%e8%ae%b2/14%20%e9%9d%9e%e7%ba%bf%e6%80%a7%e9%99%8d%e7%bb%b4%ef%bc%9a%e6%b5%81%e5%bd%a2%e5%ad%a6%e4%b9%a0.md
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
