34 连续序列化模型:线性动态系统 在隐马尔可夫模型中,一般的假设是状态和观测都是离散的随机变量。如果假定隐藏的状态变量满足连续分布,那么得到的就是线性动态系统。虽然这个概念更多地出现在信号处理与控制论中,看起来和机器学习风马牛不相及,但是从马尔可夫性和贝叶斯概率的角度观察,线性系统也是一类重要的处理序列化数据的模型。
线性动态系统(linear dynamical system)的作用可以通过下面这个例子来说明。假设一个传感器被用于测量未知的物理量(z),但测量结果(x)会受到零均值高斯噪声的影响。在单次测量中,根据最大似然可以得到,对未知的(z)最优的估计值就是测量结果本身,也就是令(z = x)。可是如果可以对(z)进行多次重复测量的话,就可以通过求解这些结果的平均来平滑掉随机噪声的影响,从而计算出更加精确的估计。
可一旦多次测量结果是在不同的时间点上测出的,也就是时间序列(x_1, x_2, \cdots, x_N)时,问题就没有那么简单了,因为这种情况下需要将未知变量(z)的时变特性考虑进去,前一时刻的(z)和后一时刻的(z)就不一样了。如果还是像上面那样直接对不同时刻的测量结果求均值的话,虽然随机噪声的影响可以被平滑掉,但变量本身的时变特性又会作为另一种噪声出现在结果中。
这种按倒葫芦起了瓢的结果显然不是我们想要的。要想获得更精确的估计,可以根据(z)的具体变化特性采用不同的策略。如果变量(z)具有慢变的特性,也就是它的波动周期远远大于测量周期,那么不同时刻的测量结果中的差别几乎全部来源于随机噪声,变量本身并不会出现多少波动。这时就可以将平滑窗口的长度,也就是用于求平均的测量结果的数目取得大一些,以取得更好的抑制随机噪声的效果。
反过来,如果变量本身是快速变化的,这时就要适当地调小平滑窗口,同时给相距较近的测量结果赋予更大的平滑权重。如果变量变化的时间尺度比相邻测量之间的时间间隔还要小,两次测量之间都能变量都能经历多次波动,就只能以测量结果作为最优的估计了。
上面的描述只是定性的说明,如果要在此基础上对最优的平滑参数进行定量计算的话,就需要对系统的时间演化和测量过程进行概率式的建模,其模型就是线性动态系统。
线性动态系统也是一种动态贝叶斯网络,其中的显式变量和隐藏变量都是连续变量,它们之间的依赖关系则是线性高斯的条件分布。最典型的线性动态系统是用于描述一个或一组高斯噪声影响下的实值变量随时间变化的过程,可以用以下的条件概率表示:
| [ P({\bf X}^{(n)} | {\bf X}^{(n - 1)}) = \mathscr{N} ({\bf A}{\bf X}^{(n - 1)}, {\bf Q}), P({\bf O}^{(n)} | {\bf X}^{(n)}) = \mathscr{N} ({\bf H}{\bf X}^{(n)}, {\bf R}) ] |
其中(\bf X)是(n)维的隐藏状态变量,(\bf O)是(m)维的观测变量,(\bf A)是定义了模型的线性转化规则的(n)维方阵,(\bf Q)是定义了状态随时间演化过程中的高斯噪声的(n)维方阵,(\bf H)是定义了从状态到观测的线性转化规则的(n \times m)维矩阵,(\bf R)是定义了观测结果中高斯噪声的(m)维方阵。隐藏状态变量初始的取值({\bf X}^{(0)})也满足高斯分布,其概率密度可以写成
| [ P({\bf X}^{(0)}) = \mathscr{N} ({\bf X}^{(0)} | \boldsymbol \mu_0, V_0) ] |
如果将线性动态系统放在状态空间表象(state space representation)下观察,上面的条件概率就可以改写成状态方程的形式
[ {\bf X}^{(n)} = {\bf A}{\bf X}^{(n - 1)} + {\bf w} ]
[ {\bf O}^{(n)} = {\bf H}{\bf X}^{(n)} + {\bf v} ]
[ {\bf X}^{(0)} = {\bf t}^{(0)} + {\bf u} ]
其中({\bf w}, {\bf v}, {\bf u})都是均值为0的高斯分布。
对原始的线性动态系统模型的一种扩展方式是将系统中的初始状态({\bf X}^{(0)})从单个的高斯分布改写为高斯混合模型。如果高斯混合模型中包含(K)个成分,那么后面所有状态也会是多个高斯分布的混合,通过求解边界概率依然可以对模型进行概率推断。
除了状态本身的概率分布外,从状态到观测的观测概率也可以写成高斯混合模型的形式。如果观测概率是(K)个高斯分布的混合,那么初始状态({\bf X}^{(0)})的后验概率同样是(K)个高斯分布的混合。随着时序的推进,后验概率的表示会变的越来越复杂。在时刻(n),状态({\bf X}^{(n)})的后验概率数目可以达到(K ^ n)个,这时参数的指数式增长就会削弱模型的实用性。
从隐马尔可夫模型和线性系统出发,可以定义出一些非传统机器学习意义上的概念。如果要根据截至目前的观测结果来估计隐藏变量,这样的问题就是滤波问题(filtering);如果要根据一串完整的观测序列来估计隐藏变量,这样的问题就是平滑问题(smoothing)。滤波和平滑对隐变量的估计都属于概率图模型推断任务的范畴,在离散的隐马尔可夫模型和连续的线性动态系统中都可以实现。
另一个只适用于离散模型的运算是译码(decoding),其任务是根据观测序列找到后验概率最大的隐变量序列。这些术语被更广泛地应用在通信和信息处理之中,但是站在更宏观的角度看,它们也可以归结到广义的机器学习范畴之中。
如果要在离散的时间序列上分析连续分布的状态和观测结果的话,需要使用线性卡尔曼滤波器这个数学工具。线性卡尔曼滤波器(linear Kalman filter)的作用是根据一串包含统计噪声和干扰的观测结果来计算出单一的、但是更加精确的观测估计。在某个时间点上,给定截止目前所获得的所有证据,可以计算出关于系统的当前状态的置信状态(belief state),其中包含了最大的信息量。在离散的时序上,时刻(n)的置信状态可以定义为
| [ \sigma^{(n)}({\bf X}^{(n)}) = P({\bf X}^{(n)} | o^{(0: n)}) ] |
其中({\bf X}^{(n)})表示当前的状态,(o^{(0: n-1)})表示之前所有的观测。在线性高斯的依赖关系下,置信状态服从高斯分布,因而可以用参数有限的均值向量和协方差矩阵来表示,具有紧凑的形式。卡尔曼滤波器的作用就是对置信状态的均值和协方差进行更新,更新的过程可以分成两个步骤:首先根据目前所有可用的观测计算出隐藏状态变量的置信,这个置信叫作先验置信状态(prior belief state),其表达式可以写成
| [ \sigma^{(\cdot n+1)}({\bf X}^{(n+1)}) = P({\bf X}^{(n+1)} | o^{(0: n)}) = \sum\limits_{\bf X}^{(n)} P({\bf X}^{(n+1)} | {\bf X}^{(n)}) \sigma^{(n)}({\bf X}^{(n)}) ] |
式子中上标的(\cdot)是先验置信状态的标志。接下来,在这个先验置信状态的条件下要考虑最近的观测结果,根据推测出的先验置信状态和当前的观测结果共同确定当前的置信状态,其表达式可以写成
| [ \sigma^{(n+1)}({\bf X}^{(n+1)}) = P({\bf X}^{(n+1)} | o^{(0: n)}, o^{(n+1)}) = \dfrac{P(o^{(n+1)} | {\bf X}^{(n+1)})\sigma^{(\cdot n+1)}({\bf X}^{(n+1)})}{P(o^{(n+1)} | o^{(0: n)})} ] |
这个递归过滤的过程对随时间变化的置信状态进行动态更新,可以看成是递归贝叶斯估计在多元高斯分布中的应用。递归贝叶斯估计(recursive Bayesian estimation)通过对不同时间观测值的递归使用来估计未知的概率分布,是隐马尔可夫模型中常用的推理方法。线性卡尔曼滤波器就是递归贝叶斯估计在连续分布的状态变量上的推广。
在卡尔曼滤波过程中,先验置信状态的更新由状态转移更新(state transition update)来表示。以上面的线性系统为例,直观上看,先验置信状态的新均值(\mu^{\cdot t+1})是将状态转移的线性变换(\bf A)应用在上个时间点的均值(\mu^{\cdot t})上,新的协方差矩阵(\Sigma^{\cdot t+1})也是将状态转移的线性变换(\bf A)应用在上个时间点的协方差(\Sigma^{\cdot t})上,再加上噪声的协方差(\bf Q)。总而言之,一个变换就可以将状态更新全部概括。
和状态转移更新相比,确定当前置信状态的观测更新(observation update)要复杂一些。置信状态的均值可以表示为先验置信的均值加上来源于观测结果的修正项,这个修正项是观测残差(observation residual),也就是期望观测值和实际观测值之间区别的加权,加权系数是被称为卡尔曼增益(Kalman gain)的系数矩阵(\bf K)。
置信状态的协方差也是对先验置信的协方差进行修正,修正的方式是减去卡尔曼增益加权后的期望协方差。在数学推导中,置信状态的参数表达式可以写成
[ {\bf K}^{(n+1)} = \Sigma^{(\cdot n+1)}{\bf H}^T ({\bf H} \Sigma^{(\cdot n+1)}{\bf H}^T + {\bf R})^{-1} ]
[ \mu^{(n+1)} = \mu^{(\cdot n+1)} + {\bf K}^{(n+1)}({\bf o}^{(n+1)} - {\bf H} \Sigma^{(\cdot n+1)}) ]
[ \Sigma^{(n+1)} = ({\bf I} - {\bf K}^{(n+1)}{\bf H})\Sigma^{(\cdot n+1)} ]
卡尔曼增益是卡尔曼滤波器中的核心参数,它体现的是观测的重要性。当表示测量误差的协方差矩阵(\bf R)趋近于0时,卡尔曼增益会收敛到状态-观测矩阵的逆({\bf H}^{-1}),这意味着真实的观测结果在置信状态的更新中扮演着越发重要的角色,预测的观测结果的地位则会不断下降。在此基础上进一步可以得到,置信状态在更新后,其协方差趋近于0,表示当前的状态几乎是确定的。
反过来,当先验置信的协方差矩阵(\Sigma^{(\cdot n+1)})趋近于0时,计算出的卡尔曼增益也会趋近于0。这种情况下,在置信更新中占据主导地位的就变成了对分布的预测结果,后验置信和先验置信的统计特性几乎完全一致,观测结果反而变得无足轻重。随着时序的推移,置信状态最终会收敛到某个分布上,系统的不确定性也会呈现出稳定的状态。
上面介绍的是最原始的卡尔曼滤波器,其原理可以推广到更加复杂的情况中。如果将状态转移和状态到观测的关系建模为非线性关系,并用泰勒展开中的一阶导数和二阶导数进行局部的线性化处理,这样的卡尔曼滤波器就是扩展卡尔曼滤波器(extended Kalman filter)。
另一种用于非线性动态的改进是无迹卡尔曼滤波器(unscented Kalman filter),它是通过无迹变换来对非线性动态进行线性化。两者的具体细节在此就不介绍了,感兴趣的话你可以自行查阅资料了解。
无论是扩展卡尔曼还是无迹卡尔曼,都是对非线性特性的确定性近似(deterministic approximation)。它们放弃了精确计算的追求,转而以确定的方式求解近似的结果。这里的确定性指的是只要用相同的方式进行近似,每次得到的结果都是一样的。如果用随机的方式来对非线性特性做出近似,对应的方法就是粒子滤波(particle filter)。
粒子滤波的任务也是根据观测结果估计隐藏的状态。它并不通过复杂的积分计算出准确的结果,而是对总体的分布进行采样,用样本的经验分布来代替总体的真实分布,用样本的均值来代替总体的积分运算。
由于这种方法和蒙特卡洛采样的思路近似,因而也被称为序贯蒙特卡洛(sequential Monte Carlo)。作为一种非参数方法,粒子滤波可以用来建模任意形式的概率分布,虽然效果未必有多好,很多情况下却是唯一可行的方法。
粒子滤波用样本的平均值来代替总体分布的数学期望,但这里的平均值不是一般的平均,每个样本点都被赋予一个权值,样本及其权重共同构成了粒子滤波中的“粒子”。整个粒子滤波的过程就是动态调整样本的权重,使经验分布不断接近真实分布的过程,具体的数学细节在这里就不讨论了。
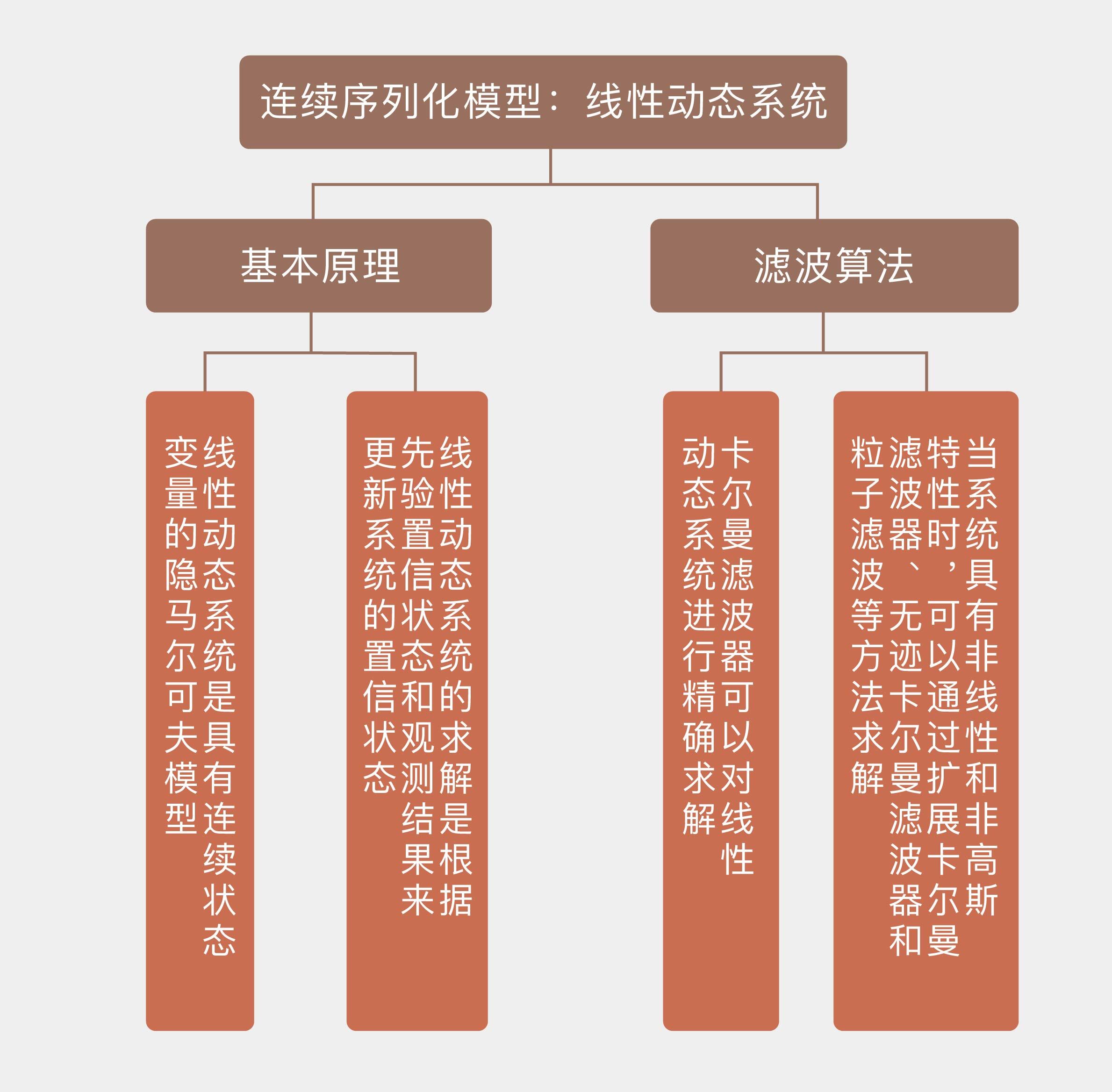
今天我和你分享了线性动态系统和一些滤波算法的基本原理,包含以下四个要点:
- 线性动态系统是具有连续状态变量的隐马尔可夫模型,所有条件概率都是线性高斯分布;
- 线性动态系统的求解是根据先验置信状态和观测结果来更新系统的置信状态;
- 卡尔曼滤波器可以对线性动态系统进行精确求解;
- 当系统具有非线性和非高斯特性时,可以通过扩展卡尔曼滤波器、无迹卡尔曼滤波器和粒子滤波等方法求解。
卡尔曼滤波器及其变种在动态的运动目标跟踪中有广泛的应用,是机器人感知、定位与导航的一种重要方法。
你可以查阅资料,了解卡尔曼滤波器具体的应用方式,并在这里分享你的见解。
参考资料
https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/%e6%9c%ba%e5%99%a8%e5%ad%a6%e4%b9%a040%e8%ae%b2/34%20%e8%bf%9e%e7%bb%ad%e5%ba%8f%e5%88%97%e5%8c%96%e6%a8%a1%e5%9e%8b%ef%bc%9a%e7%ba%bf%e6%80%a7%e5%8a%a8%e6%80%81%e7%b3%bb%e7%bb%9f.md
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
