18 Executor 才是执行 SQL 语句的幕后推手(下)
在上一讲中,我们首先介绍了模板方法模式的相关知识,然后介绍了 Executor 接口的核心方法,最后分析了 BaseExecutor 抽象类是如何利用模板方法模式为其他 Executor 抽象了一级缓存和事务管理的能力。这一讲,我们再来介绍剩余的四个重点 Executor 实现。
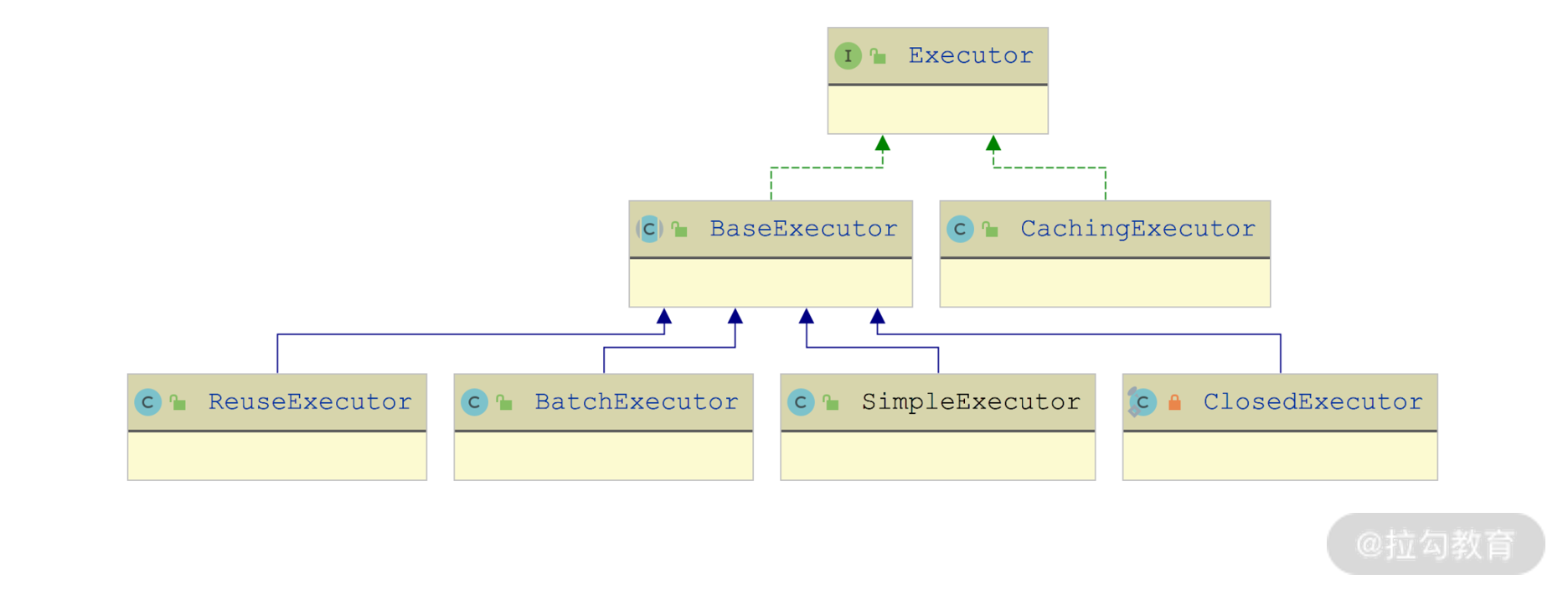
Executor 接口继承关系图
SimpleExecutor
我们来看 BaseExecutor 的第一个子类—— SimpleExecutor,同时它也是 Executor 接口最简单的实现。
正如上一讲中分析的那样,BaseExecutor 通过模板方法模式实现了读写一级缓存、事务管理等不随场景变化的基础方法,在 SimpleExecutor、ReuseExecutor、BatchExecutor 等实现类中,不再处理这些不变的逻辑,而只要关注 4 个 do/*() 方法的实现即可。
这里我们重点来看 SimpleExecutor 中 doQuery() 方法的实现逻辑。
- 通过 newStatementHandler() 方法创建 StatementHandler 对象,其中会根据 MappedStatement.statementType 配置创建相应的 StatementHandler 实现对象,并添加 RoutingStatementHandler 装饰器。
- 通过 prepareStatement() 方法初始化 Statement 对象,其中还依赖 ParameterHandler 填充 SQL 语句中的占位符。
- 通过 StatementHandler.query() 方法执行 SQL 语句,并通过我们前面[14]和[15]讲介绍的 DefaultResultSetHandler 将 ResultSet 映射成结果对象并返回。
doQuery() 方法的核心代码实现如下所示:
public List doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException { Statement stmt = null; try { Configuration configuration = ms.getConfiguration(); // 创建StatementHandler对象,实际返回的是RoutingStatementHandler对象(我们在第16讲介绍过) // 其中根据MappedStatement.statementType选择具体的StatementHandler实现 StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql); // 完成StatementHandler的创建和初始化,该方法会调用StatementHandler.prepare()方法创建 // Statement对象,然后调用StatementHandler.parameterize()方法处理占位符 stmt = prepareStatement(handler, ms.getStatementLog()); // 调用StatementHandler.query()方法,执行SQL语句,并通过ResultSetHandler完成结果集的映射 return handler.query(stmt, resultHandler); } finally { closeStatement(stmt); } }
SimpleExecutor 中的 doQueryCursor()、update() 等方法实现与 doQuery() 方法的实现基本类似,这里不再展开介绍,你若感兴趣的话可以参考源码进行分析。
ReuseExecutor
你如果有过 JDBC 优化经验的话,可能会知道重用 Statement 对象是一种常见的优化手段,主要目的是减少 SQL 预编译开销,同时还会降低 Statement 对象的创建和销毁频率,这在一定程度上可以提升系统性能。
ReuseExecutor 这个 BaseExecutor 实现就实现了重用 Statement 的优化,ReuseExecutor 维护了一个 statementMap 字段(HashMap类型)来缓存已有的 Statement 对象,该缓存的 Key 是 SQL 模板,Value 是 SQL 模板对应的 Statement 对象。这样在执行相同 SQL 模板时,我们就可以复用 Statement 对象了。
ReuseExecutor 中的 do/*() 方法实现与前面介绍的 SimpleExecutor 实现完全一样,两者唯一的区别在于其中依赖的 prepareStatement() 方法:SimpleExecutor 每次都会创建全新的 Statement 对象,ReuseExecutor 则是先尝试查询 statementMap 缓存,如果缓存命中,则会重用其中的 Statement 对象。
另外,在事务提交/回滚以及 Executor 关闭的时候,需要同时关闭 statementMap 集合中缓存的全部 Statement 对象,这部分逻辑是在 doFlushStatements() 方法中实现的,核心代码如下:
public List doFlushStatements(boolean isRollback) { // 关闭statementMap集合中缓存的全部Statement对象 for (Statement stmt : statementMap.values()) { closeStatement(stmt); } // 清空statementMap集合 statementMap.clear(); return Collections.emptyList(); }
BatchExecutor
批处理是 JDBC 编程中的另一种优化手段。
JDBC 在执行 SQL 语句时,会将 SQL 语句以及实参通过网络请求的方式发送到数据库,一次执行一条 SQL 语句,一方面会减小请求包的有效负载,另一个方面会增加耗费在网络通信上的时间。通过批处理的方式,我们就可以在 JDBC 客户端缓存多条 SQL 语句,然后在 flush 或缓存满的时候,将多条 SQL 语句打包发送到数据库执行,这样就可以有效地降低上述两方面的损耗,从而提高系统性能。
不过,有一点需要特别注意:每次向数据库发送的 SQL 语句的条数是有上限的,如果批量执行的时候超过这个上限值,数据库就会抛出异常,拒绝执行这一批 SQL 语句,所以我们需要控制批量发送 SQL 语句的条数和频率。
BatchExecutor 是用于实现批处理的 Executor 实现,其中维护了一个 List
集合(statementList 字段)用来缓存一批 SQL,每个 Statement 可以写入多条 SQL。
我们知道 JDBC 的批处理操作只支持 insert、update、delete 等修改操作,也就是说 BatchExecutor 对批处理的实现集中在 doUpdate() 方法中。在 doUpdate() 方法中追加一条待执行的 SQL 语句时,BatchExecutor 会先将该条 SQL 语句与最近一次追加的 SQL 语句进行比较,如果相同,则追加到最近一次使用的 Statement 对象中;如果不同,则追加到一个全新的 Statement 对象,同时会将新建的 Statement 对象放入 statementList 缓存中。
下面是 BatchExecutor.doUpdate() 方法的核心逻辑:
public int doUpdate(MappedStatement ms, Object parameterObject) throws SQLException { final Configuration configuration = ms.getConfiguration(); // 创建StatementHandler对象 final StatementHandler handler = configuration.newStatementHandler(this, ms, parameterObject, RowBounds.DEFAULT, null, null); final BoundSql boundSql = handler.getBoundSql(); // 获取此次追加的SQL模板 final String sql = boundSql.getSql(); final Statement stmt; // 比较此次追加的SQL模板与最近一次追加的SQL模板,以及两个MappedStatement对象 if (sql.equals(currentSql) && ms.equals(currentStatement)) { // 两者相同,则获取statementList集合中最后一个Statement对象 int last = statementList.size() - 1; stmt = statementList.get(last); applyTransactionTimeout(stmt); handler.parameterize(stmt); // 设置实参 // 查找该Statement对象对应的BatchResult对象,并记录用户传入的实参 BatchResult batchResult = batchResultList.get(last); batchResult.addParameterObject(parameterObject); } else { Connection connection = getConnection(ms.getStatementLog()); // 创建新的Statement对象 stmt = handler.prepare(connection, transaction.getTimeout()); handler.parameterize(stmt);// 设置实参 // 更新currentSql和currentStatement currentSql = sql; currentStatement = ms; // 将新创建的Statement对象添加到statementList集合中 statementList.add(stmt); // 为新Statement对象添加新的BatchResult对象 batchResultList.add(new BatchResult(ms, sql, parameterObject)); } handler.batch(stmt); return BATCH_UPDATE_RETURN_VALUE; }
这里使用到的 BatchResult 用于记录批处理的结果,一个 BatchResult 对象与一个 Statement 对象对应,BatchResult 中维护了一个 updateCounts 字段(int[] 数组类型)来记录关联 Statement 对象执行批处理的结果。
添加完待执行的 SQL 语句之后,我们再来看一下 doFlushStatements() 方法,其中会通过 Statement.executeBatch() 方法批量执行 SQL,然后 SQL 语句影响行数以及数据库生成的主键填充到相应的 BatchResult 对象中返回。下面是其核心实现:
public List doFlushStatements(boolean isRollback) throws SQLException { try { // 用于储存批处理的结果 List results = new ArrayList<>(); // 如果明确指定了要回滚事务,则直接返回空集合,忽略statementList集合中记录的SQL语句 if (isRollback) { return Collections.emptyList(); } for (int i = 0, n = statementList.size(); i < n; i++) { // 遍历statementList集合 Statement stmt = statementList.get(i);// 获取Statement对象 applyTransactionTimeout(stmt); BatchResult batchResult = batchResultList.get(i); // 获取对应BatchResult对象 try { // 调用Statement.executeBatch()方法批量执行其中记录的SQL语句,并使用返回的int数组 // 更新BatchResult.updateCounts字段,其中每一个元素都表示一条SQL语句影响的记录条数 batchResult.setUpdateCounts(stmt.executeBatch()); MappedStatement ms = batchResult.getMappedStatement(); List
