22 朴素贝叶斯:如何让计算机学会自动分类? 你好,我是黄申。今天我们来聊聊朴素贝叶斯。
在开始正式的内容之前,我想问你一个问题,你是如何区分苹果、甜橙和西瓜的?你可能要说了,这个问题还用得着讲吗?是不是你们博士都喜欢将简单的问题复杂化?还真不是,如果你将计算机想象成一个两三岁的孩子,你会怎么教一个孩子区分这些水果呢?
比如我曾经就和一个小朋友有过这样一段对话:
小朋友:黄叔叔,你和我讲讲,什么样的水果才是苹果呀?
我:圆形的、绿色的水果。
小朋友:那西瓜也是圆形的、绿色的呀?
我:嗯……苹果也有可能是黄色或红色的,但西瓜不是。
小朋友:那甜橙也是圆形的、黄色的呀?
我:好吧,你看到的大部分情况下的甜橙都是黄色的,而苹果只有很少情况(少数品种)是黄色的。而且你还可以尝尝,它们的味道也是不同的。

哈哈,你是不是觉得想要描述清楚,并没有想象中的那么容易?但是,在这个对话中,有两点我觉得你需要关注一下:
- 我使用了“可能”“大部分情况”“很少情况”等等这种词语,这些词包含了概率的概念;
- 我使用了多个条件来判断一个水果属于哪个类别。
基于此,我接下来就要聊聊,我们是如何通过数学的思想和方法,系统性地解决这个问题的。其中,朴素贝叶斯(Naive Bayesian)就提供了一个切实可行的方案。不过,在深入了解它之前,我们还需要做点准备工作。
如何将原始信息转化为计算机能看懂的数据?
事实上,计算机并不像两三岁的小孩那样,可以看到水果的颜色、形状和纹理,或者能尝到水果的味道。我们需要将水果的特征转化为计算机所能理解的数据。最常用的方式就是提取现实世界中的对象之属性,并将这些转化为数字。
以水果为例,你会提取它们的哪些属性呢?我会考虑这些,比如:形状、外皮颜色、斑马纹理、重量、握感、口感。我手边刚好有一个苹果、一个甜橙和一个西瓜,我把它们的属性分别统计了一下,你可以看看。
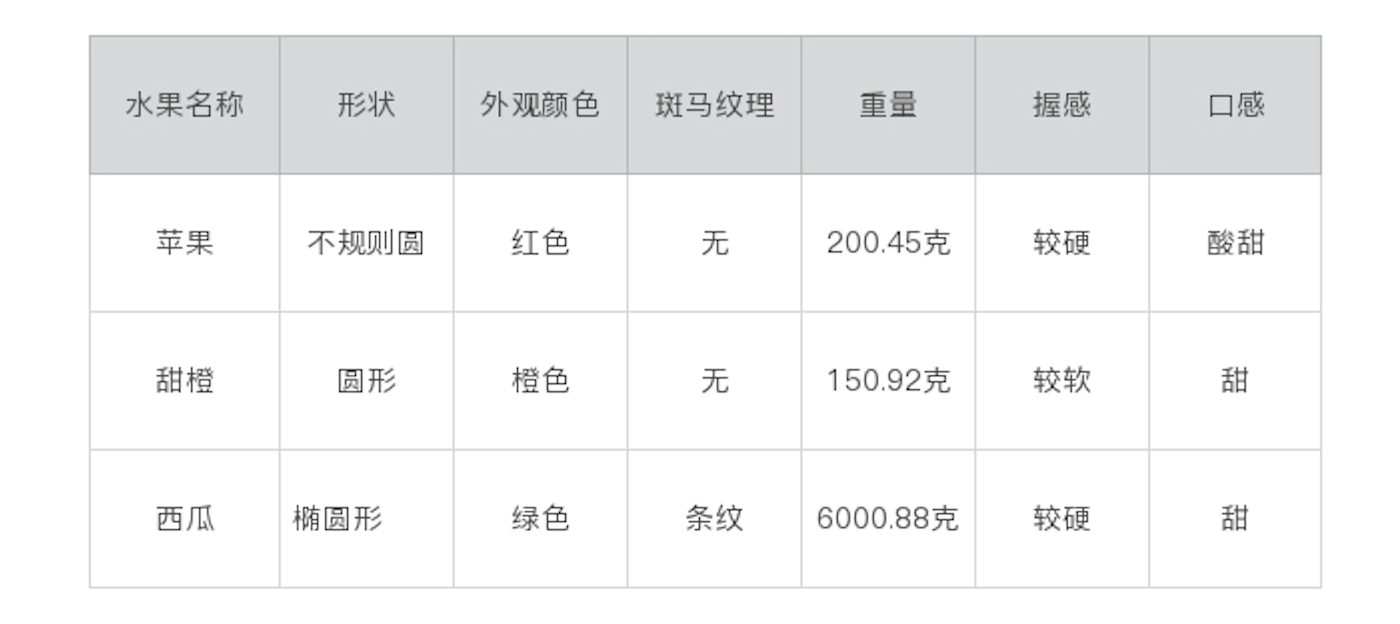
然后,我们需要这些属性转化为计算机能够理解的东西——数字,也就是说,我给每种属性都定义了具体的数值,用来代表它们的具体属性。
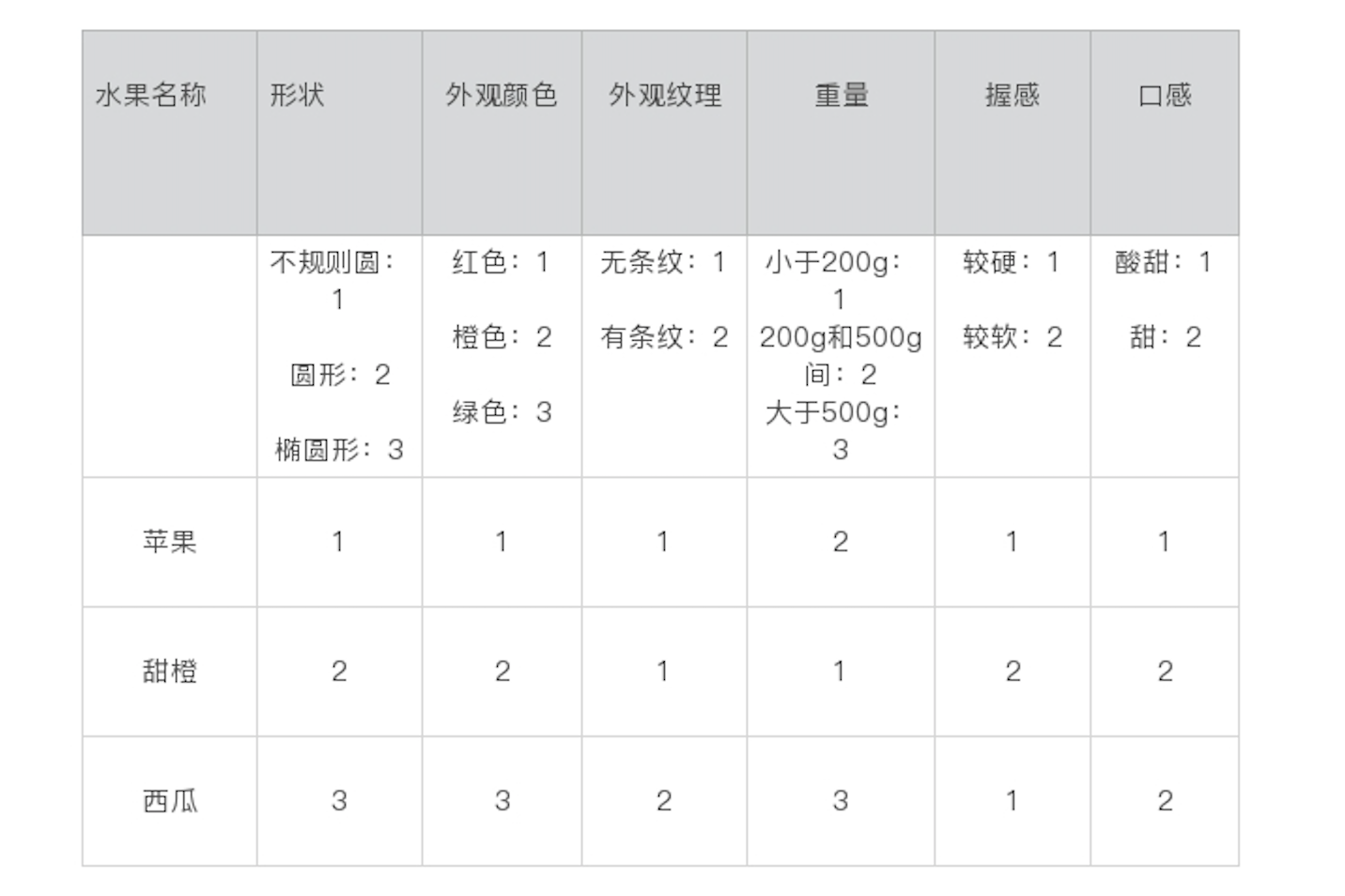
比较细心的话,你可能已经发现了,我偷偷地把重量由连续值转化成了离散值,这是因为朴素贝叶斯处理的都是离散值。
好了,仅仅3个水果还不足以构成朴素贝叶斯分类所需的训练样本。为了保证训练的质量,我们可以继续扩展到10个水果。
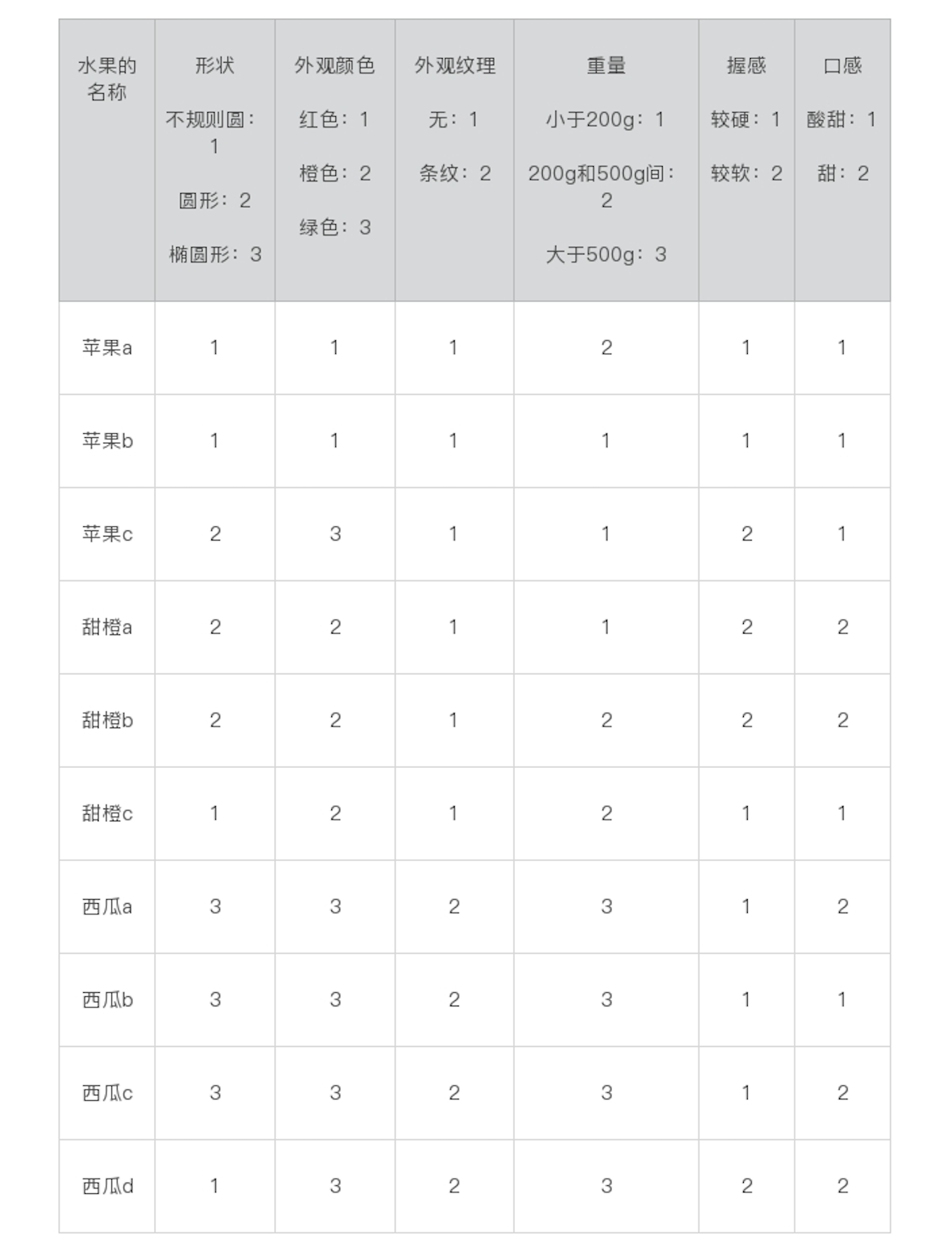
朴素贝叶斯的核心思想
我们现在已经拿到了这10个水果的数据,那如果现在我手上有一个新的水果,它也有一定的形状、颜色、口感等等,你怎么判断它是哪种水果呢?
之前的文章我们讲过先验概率、后验概率、条件概率和贝叶斯法则,它们是朴素贝叶斯分类的核心组成部分。通过贝叶斯法则,我们可以根据先验概率和条件概率,推导出后验概率。首先让我们快速回想一下贝叶斯公式。
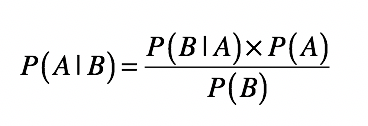
上一节,我已经详细解释了这个公式的推导和每一部分的含义,这里再强调一下贝叶斯定理的核心思想:用先验概率和条件概率估计后验概率。
那具体到这里的分类问题,我们该如何运用这个公式呢?为了便于理解,我们可以将上述公式改写成这样:
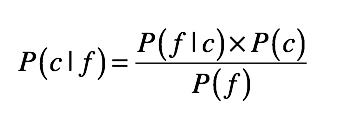
| 其中,c表示一个分类(class),f表示属性对应的数据字段(field)。如此一来,等号左边的P(c | f)就是待分类样本中,出现属性值f时,样本属于类别c的概率。而等号右边的P(f | c)是根据训练数据统计,得到分类c中出现属性f的概率。P©是分类c在训练数据中出现的概率,P(f)是属性f在训练样本中出现的概率。 |
看到这里,你可能要问了,这里的贝叶斯公式只描述了单个属性值属于某个分类的概率,可是我们要分析的水果每个都有很多属性啊,这该怎么办呢?
别急,朴素贝叶斯在这里就要发挥作用了。这是基于一个简单假设建立的一种贝叶斯方法,并假定数据对象的不同属性对其归类影响时是相互独立的。此时若数据对象o中同时出现属性fi与fj,则对象o属于类别c的概率就是这样:
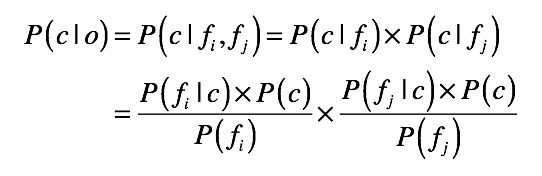
现在,我们应该已经可以用10个水果的数据,来建立朴素贝叶斯模型了。
其中,苹果的分类中共包含3个数据实例,对于形状而言,出现2次不规则圆、1次圆形和0次椭圆形,因此各自的统计概率为0.67、0.33和0.00。我们将这些值称为,给定一个水果分类时,出现某个属性值的条件概率。以此类推,所有的统计结果就是下面这个表格中这样:
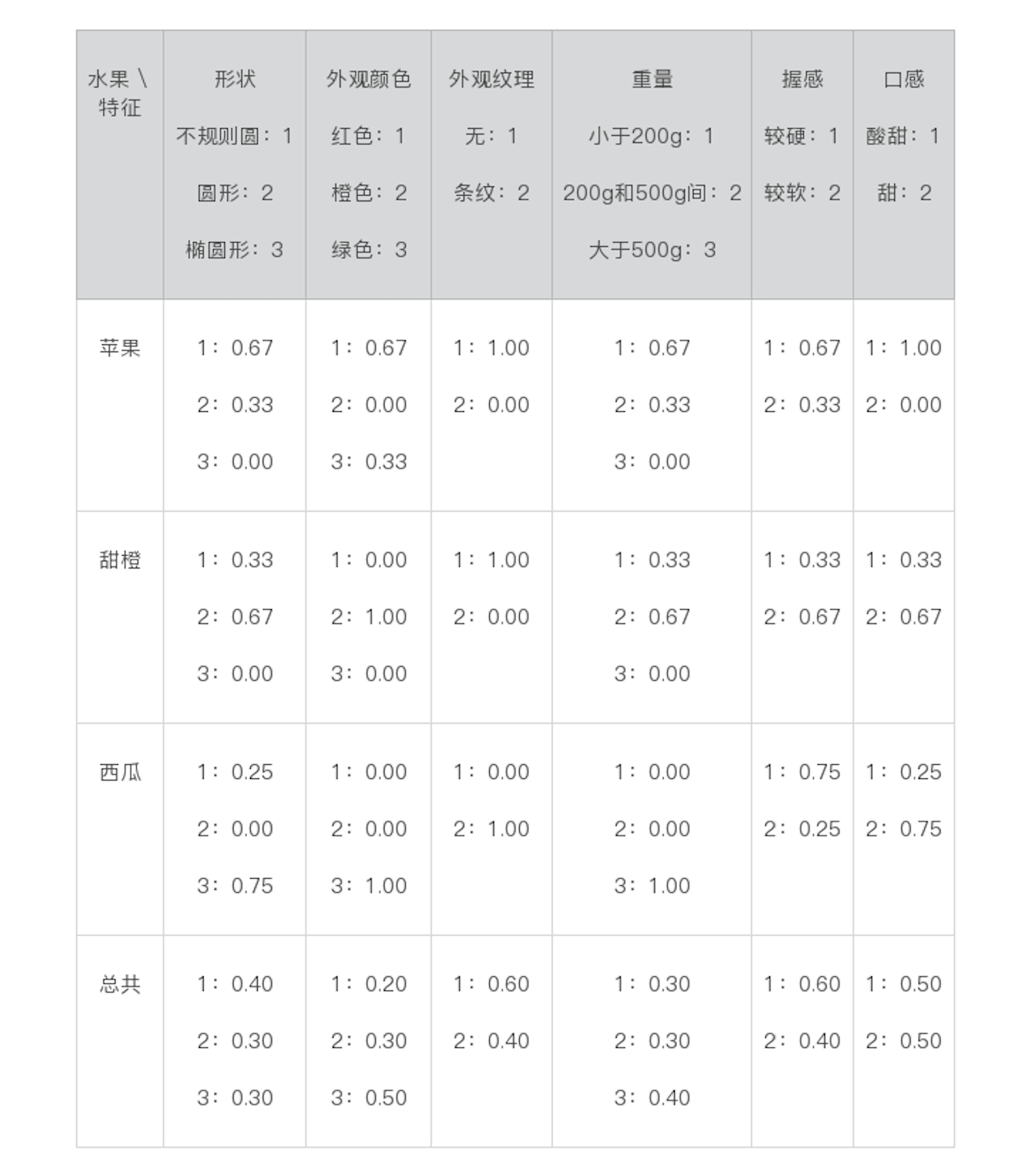
对于上表中出现的0.00概率,在做贝叶斯公式中的乘积计算时,会出现结果为0的情况,因此我们通常取一个比这个数据集里最小统计概率还要小的极小值,来代替“零概率”。比如,我们这里取0.01。在填充训练数据中从来没有出现过的属性值的时候,我们就会使用这种技巧,我们给这种技巧起个名字就叫作平滑(Smoothing)。
有了这些条件概率,以及各类水果和各个属性出现的先验概率,我们已经建立起了朴素贝叶斯模型。现在,我们就可以用它进行朴素贝叶斯分类了。
假设我们有一个新的水果,它的形状是圆形,口感是甜的,那么根据朴素贝叶斯,它属于苹果、甜橙和西瓜的概率分别是多少呢?我们先来计算一下,它属于苹果的概率有多大。

其中,apple表示分类为苹果,shape-2表示形状属性的值为2(也就是圆形),taste-2表示口感属性的值为2。以此类推,我们还可计算该水果属于甜橙和西瓜的概率。

比较这三个数值,0.00198<0.00798<0.26934,所以计算机可以得出的结论,该水果属于甜橙的可能性是最大的,或者说,这个水果最有可能是甜橙。
你可能已经注意到了,这几个公式里的概率乘积通常都非常小,在物品的属性非常多的时候,这个乘积可能就小到计算机无法处理的地步。因此,在实际运用中,我们还会采用一些数学手法进行转换(比如取log将小数转换为绝对值大于1的负数),原理都是一样的。
内容比较多,我稍微总结一下。朴素贝叶斯分类主要包括这几个步骤:
- 准备数据:针对水果分类这个案例,我们搜集了若干水果的实例,并从水果的常见属性入手,将其转化为计算机所能理解的数据。这种数据也被称为训练样本。
- 建立模型:通过手头上水果的实例,我们让计算机统计每种水果、属性出现的先验概率,以及在某个水果分类下某种属性出现的条件概率。这个过程也被称为基于样本的训练。
- 分类新数据:对于一个新水果的属性数据,计算机根据已经建立的模型进行推导计算,得到该水果属于每个分类的概率,实现了分类的目的。这个过程也被称为预测。
朴素贝叶斯分类VS其他分类算法
用朴素贝叶斯进行分类的内容差不多就是这样,你可能要问了,朴素贝叶斯是唯一的分类算法吗?现实中需要分类的场景那么多,朴素贝叶斯都适用吗?确实,我们有很多种分类算法,它们也都有各自的优劣。我这里就把朴素贝叶斯和常用的几种分类算法做个总结和比较。
- 和KNN最近邻相比,朴素贝叶斯需要更多的时间进行模型的训练,但是它在对新的数据进行分类预测的时候,通常效果更好、用时更短。
- 和决策树相比,朴素贝叶斯并不能提供一套易于人类理解的规则,但是它可以提供决策树通常无法支持的模糊分类(一个对象可以属于多个分类)。
- 和SVM支持向量机相比,朴素贝叶斯无法直接支持连续值的输入。所以,在前面的案例中,我将连续值转化成了离散值,便于朴素贝叶斯进行处理。
为了便于你理解记忆,我这里也做一下总结。
如果一个分类的应用场景中,待分类对象的属性值大部分都是离散的(或者很容易转化为离散的)、需要支持模糊分类,并且需要快速可靠的实时分类,那么这种场景通常就非常适合使用朴素贝叶斯方法。
总结
今天我从一个看似非常简单的判断水果的例子出发,介绍了如何通过物体的属性及其数值,让计算机理解现实世界中的事物,并通过朴素贝叶斯方法来对其进行分类。
在朴素贝叶斯方法的推导过程中,我给你讲了如何使用贝叶斯法则,将后验概率的估计转换为先验概率和条件概率。朴素贝叶斯训练过程包括基于样本数据的先验概率和条件概率统计,分类过程就包括了使用贝叶斯法则,结合新样本的属性数据以及训练好的模型数据,进行最终的预测。
最后,我将朴素贝叶斯和其他常见分类算法,比如KNN近邻、决策树、SVM向量机,做了对比。朴素贝叶斯适用离散属性值中,训练过程耗时长但是分类预测速度快,支持模糊分类。这一节的内容比较偏理论,下一节,我会着重来讲朴素贝叶斯的应用场景,告诉你哪些场合下更适合使用朴素贝叶斯法。
思考题
除了文本分类,你还知道什么地方可以使用朴素贝叶斯方法来处理分类问题?
欢迎留言和我分享,也欢迎你在留言区写下今天的学习笔记。你可以点击“请朋友读”,把今天的内容分享给你的好友,和他一起精进。
参考资料
https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/%e7%a8%8b%e5%ba%8f%e5%91%98%e7%9a%84%e6%95%b0%e5%ad%a6%e5%9f%ba%e7%a1%80%e8%af%be/22%20%e6%9c%b4%e7%b4%a0%e8%b4%9d%e5%8f%b6%e6%96%af%ef%bc%9a%e5%a6%82%e4%bd%95%e8%ae%a9%e8%ae%a1%e7%ae%97%e6%9c%ba%e5%ad%a6%e4%bc%9a%e8%87%aa%e5%8a%a8%e5%88%86%e7%b1%bb%ef%bc%9f.md
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
