11 高级技巧之日志分析:利用 Linux 指令分析 Web 日志 著名的黑客、自由软件运动的先驱理查德.斯托曼说过,“编程不是科学,编程是手艺”。可见,要想真正搞好编程,除了学习理论知识,还需要在实际的工作场景中进行反复的锤炼。
所以今天我们将结合实际的工作场景,带你利用 Linux 指令分析 Web 日志,这其中包含很多小技巧,掌握了本课时的内容,将对你将来分析线上日志、了解用户行为和查找问题有非常大地帮助。
本课时将用到一个大概有 5W 多条记录的
nginx 日志文件,你可以在GitHub上下载。 下面就请你和我一起,通过分析这个
nginx 日志文件,去锤炼我们的手艺。
第一步:能不能这样做?
当我们想要分析一个线上文件的时候,首先要思考,能不能这样做? 这里你可以先用
htop 指令看一下当前的负载。如果你的机器上没有
htop ,可以考虑用
yum 或者
apt 去安装。
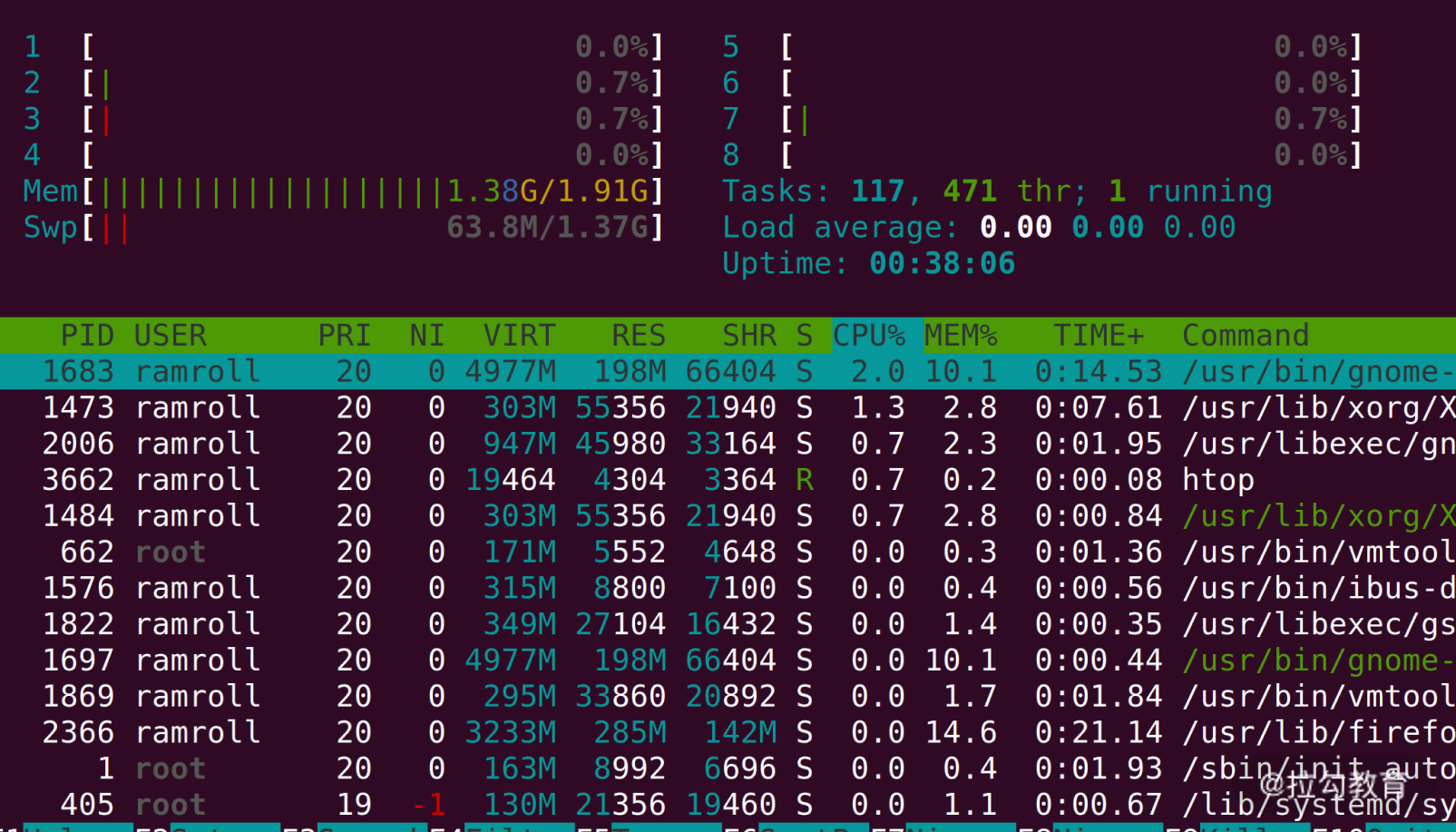
如上图所示,我的机器上 8 个 CPU 都是 0 负载,
2G 的内存用了一半多,还有富余。 我们用
wget 将目标文件下载到本地(如果你没有 wget,可以用
yum 或者
apt 安装)。 wget 某网址(自己替代)
然后我们用
ls 查看文件大小。发现这只是一个 7M 的文件,因此对线上的影响可以忽略不计。如果文件太大,建议你用
scp 指令将文件拷贝到闲置服务器再分析。下图中我使用了
–block-size 让
ls 以
M 为单位显示文件大小。

确定了当前机器的
CPU 和内存允许我进行分析后,我们就可以开始第二步操作了。
第二步:LESS 日志文件
在分析日志前,给你提个醒,记得要
less 一下,看看日志里面的内容。之前我们说过,尽量使用
less 这种不需要读取全部文件的指令,因为在线上执行
cat 是一件非常危险的事情,这可能导致线上服务器资源不足。
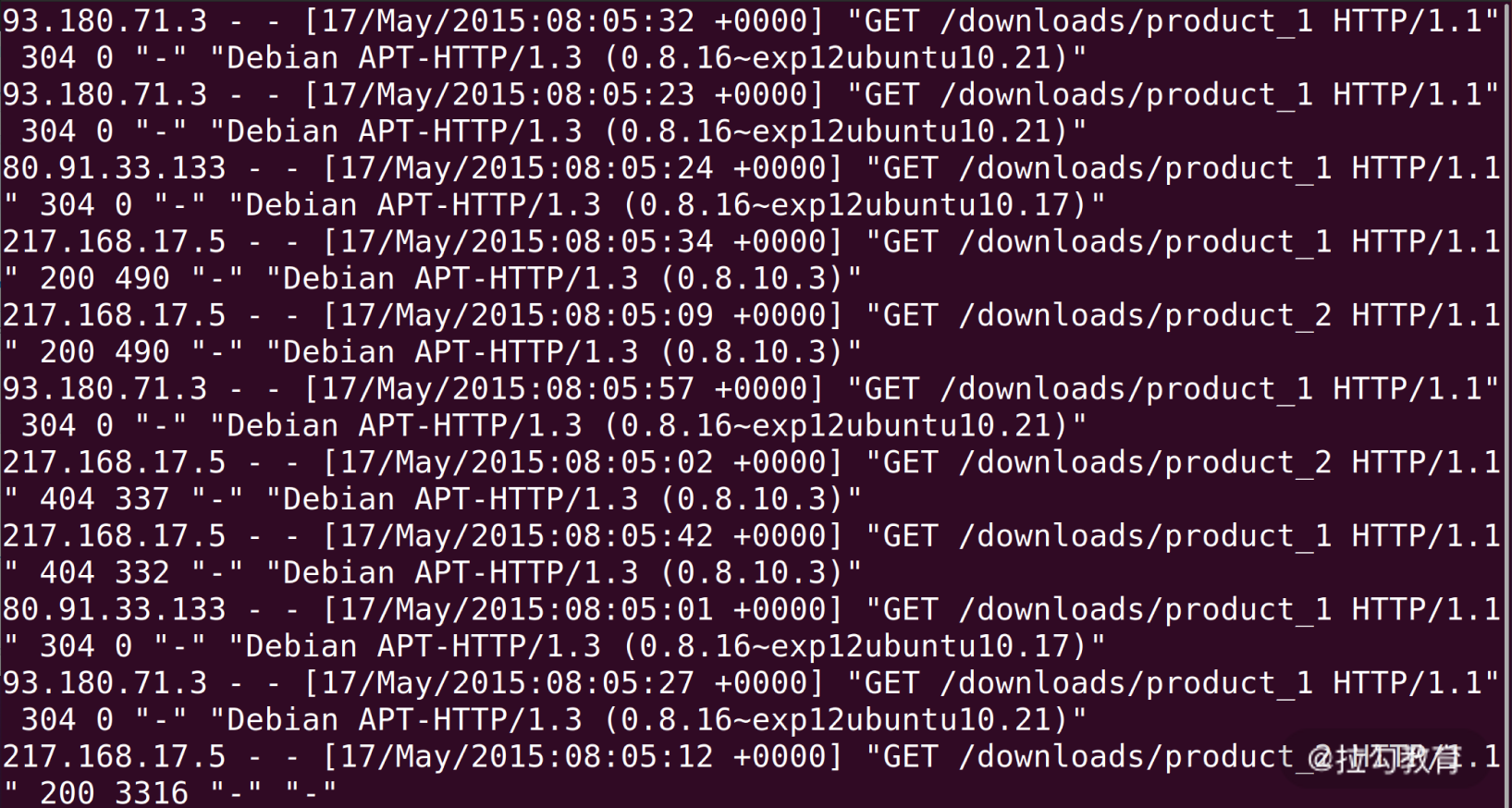
如上图所示,我们看到
nginx 的
access_log 每一行都是一次用户的访问,从左到右依次是:
- IP 地址;
- 时间;
- HTTP 请求的方法、路径和协议版本、返回的状态码;
- User Agent。
第三步:PV 分析
PV(Page View),用户每访问一个页面就是一次
Page View 。对于
nginx 的
acess_log 来说,分析 PV 非常简单,我们直接使用
wc -l 就可以看到整体的
PV 。

如上图所示:我们看到了一共有 51462 条 PV。
第四步:PV 分组
通常一个日志中可能有几天的 PV,为了得到更加直观的数据,有时候需要按天进行分组。为了简化这个问题,我们先来看看日志中都有哪些天的日志。
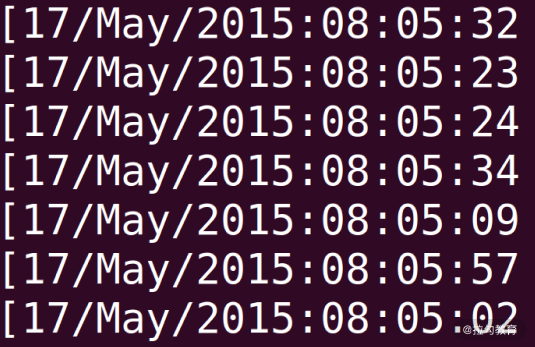
使用
awk ‘{print $4}’ access.log | less 可以看到如下结果。
awk 是一个处理文本的领域专有语言。这里就牵扯到领域专有语言这个概念,英文是Domain Specific Language。领域专有语言,就是为了处理某个领域专门设计的语言。比如awk是用来分析处理文本的DSL,html是专门用来描述网页的DSL,SQL是专门用来查询数据的DSL……大家还可以根据自己的业务设计某种针对业务的DSL。
你可以看到我们用
$4 代表文本的第 4 列,也就是时间所在的这一列,如下图所示:
我们想要按天统计,可以利用
awk 提供的字符串截取的能力。
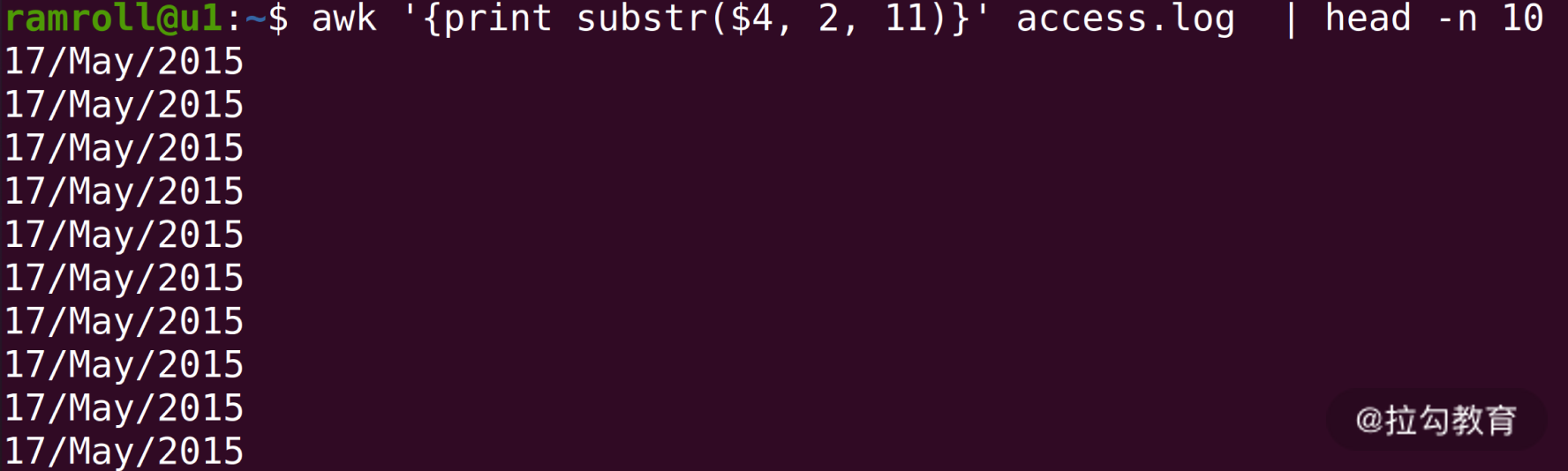
上图中,我们使用
awk 的
substr 函数,数字
2 代表从第 2 个字符开始,数字
11 代表截取 11 个字符。
接下来我们就可以分组统计每天的日志条数了。
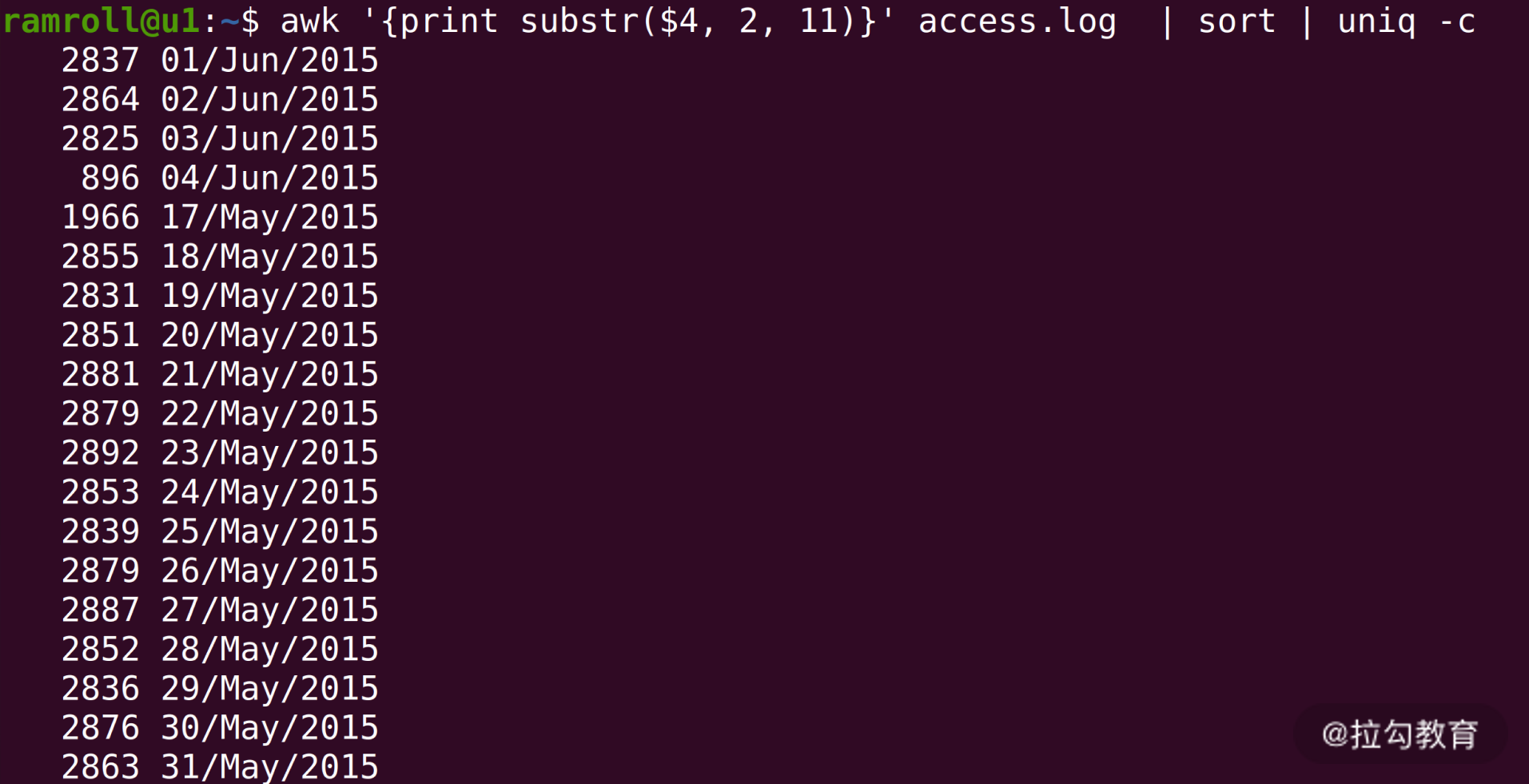
上图中,使用
sort 进行排序,然后使用
uniq -c 进行统计。你可以看到从 2015 年 5 月 17 号一直到 6 月 4 号的日志,还可以看到每天的 PV 量大概是在 2000~3000 之间。
第五步:分析 UV
接下来我们分析 UV。UV(Uniq Visitor),也就是统计访问人数。通常确定用户的身份是一个复杂的事情,但是我们可以用 IP 访问来近似统计 UV。

上图中,我们使用 awk 去打印
$1 也就是第一列,接着
sort 排序,然后用
uniq 去重,最后用
wc -l 查看条数。 这样我们就知道日志文件中一共有
2660 个 IP,也就是
2660 个 UV。
第六步:分组分析 UV
接下来我们尝试按天分组分析每天的 UV 情况。这个情况比较复杂,需要较多的指令,我们先创建一个叫作
sum.sh 的
bash 脚本文件,写入如下内容: /#!/usr/bin/bash awk ‘{print substr($4, 2, 11) “ “ $1}’ access.log |\ sort | uniq |\ awk ‘{uv[$1]++;next}END{for (ip in uv) print ip, uv[ip]}’
具体分析如下。
- 文件首部我们使用
/#! ,表示我们将使用后面的
/usr/bin/bash 执行这个文件。
- 第一次
awk 我们将第 4 列的日期和第 1 列的
ip 地址拼接在一起。
- 下面的
sort 是把整个文件进行一次字典序排序,相当于先根据日期排序,再根据 IP 排序。
- 接下来我们用
uniq 去重,日期 +IP 相同的行就只保留一个。
- 最后的
awk 我们再根据第 1 列的时间和第 2 列的 IP 进行统计。
为了理解最后这一行描述,我们先来简单了解下
awk 的原理。
awk 本身是逐行进行处理的。因此我们的
next 关键字是提醒
awk 跳转到下一行输入。 对每一行输入,
awk 会根据第 1 列的字符串(也就是日期)进行累加。之后的
END 关键字代表一个触发器,就是 END 后面用 {} 括起来的语句会在所有输入都处理完之后执行——当所有输入都执行完,结果被累加到
uv 中后,通过
foreach 遍历
uv 中所有的
key ,去打印
ip 和
ip 对应的数量。
编写完上面的脚本之后,我们保存退出编辑器。接着执行
chmod +x ./sum.sh ,给
sum.sh 增加执行权限。然后我们可以像下图这样执行,获得结果:
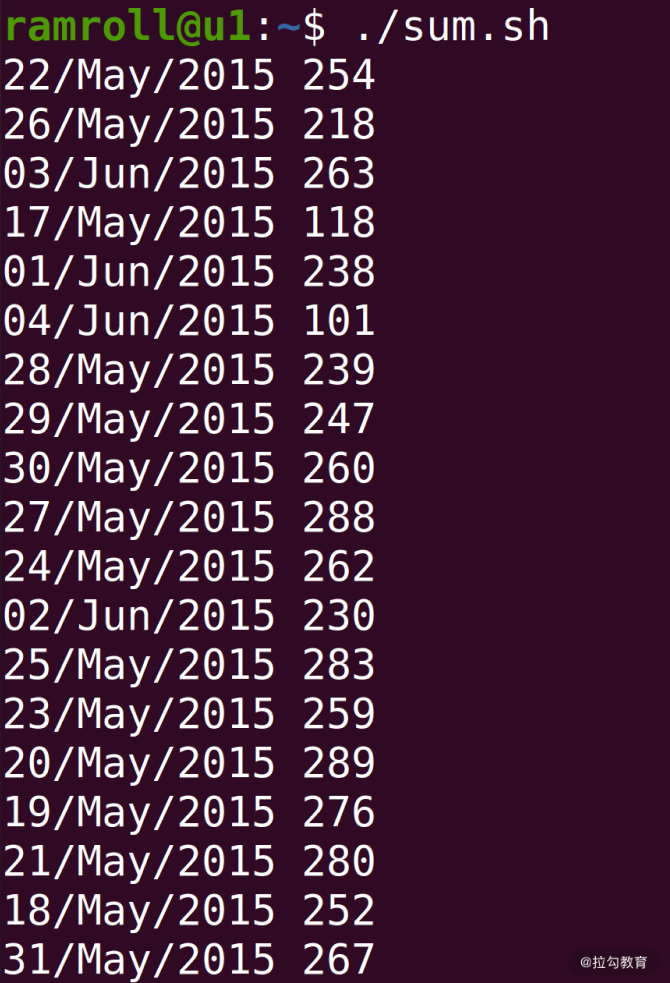
如上图,
IP 地址已经按天进行统计好了。
总结
今天我们结合一个简单的实战场景——Web 日志分析与统计练习了之前学过的指令,提高熟练程度。此外,我们还一起学习了新知识——功能强大的
awk 文本处理语言。在实战中,我们对一个
nginx 的
access_log 进行了简单的数据分析,直观地获得了这个网站的访问情况。
我们在日常的工作中会遇到各种各样的日志,除了 nginx 的日志,还有应用日志、前端日志、监控日志等等。你都可以利用今天学习的方法,去做数据分析,然后从中得出结论。
参考资料
https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/%e9%87%8d%e5%ad%a6%e6%93%8d%e4%bd%9c%e7%b3%bb%e7%bb%9f-%e5%ae%8c/11%20%20%e9%ab%98%e7%ba%a7%e6%8a%80%e5%b7%a7%e4%b9%8b%e6%97%a5%e5%bf%97%e5%88%86%e6%9e%90%ef%bc%9a%e5%88%a9%e7%94%a8%20Linux%20%e6%8c%87%e4%bb%a4%e5%88%86%e6%9e%90%20Web%20%e6%97%a5%e5%bf%97.md
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
