01 统计基础(上):系统掌握指标的统计属性 你好,我是博伟。
在学习、解决技术问题的时候,我们都知道有这么一句话“知其然知其所以然”。那么,A/B测试的“所以然”是什么呢?在我看来,就是A/B测试背后的计算原理,知道A/B测试为什么要这么设计,最佳实践中为什么要选择这样的指标、那样的检验方法。
那说到A/B测试背后的计算原理,我们首先得知道,A/B测试的理论基础是假设检验(Hypothesis Testing)。可以说,假设检验,贯穿了A/B测试从实验设计到分析测试结果的整个流程。
如果要一句话解释“假设检验”的话,就是选取一种合适的检验方法,去验证在A/B测试中我们提出的假设是否正确。现在,你只要知道“假设检验”中,最重要也最核心的是“检验”就可以了,因为选取哪种检验方法,取决于指标的统计属性。
也就是说,理解指标的统计属性,是我们掌握假设检验和A/B测试的前提,也是“知其所以然”的第一步。
而至于深入理解并用好“假设检验”的任务,我们就留着下一讲去完成吧。
指标的统计属性,指的是什么?
在实际业务中,我们常用的指标其实就是两类:
- 均值类的指标,比如用户的平均使用时长、平均购买金额、平均购买频率,等等。
- 概率类的指标,比如用户点击的概率(点击率)、转化的概率(转化率)、购买的概率(购买率),等等。
很明显,这些指标都是用来表征用户行为的。而用户的行为是非常随机的,这也就意味着这些指标是由一系列随机事件组成的变量,也就是统计学中的随机变量(Random Variable)。
“随机”就代表着可以取不同的数值。比如,一款社交App每天的使用时间,对轻度用户来说可能不到1小时,而对重度用户来说可能是4、5小时以上。那么问题来了,在统计学中,怎么表征呢?
没错,我们可以用概率分布(Probability Distribution),来表征随机变量取不同值的概率和范围。所以,A/B测试指标的统计属性,其实就是要看这些指标到底服从什么概率分布。
在这里,我可以先告诉你结论:在数量足够大时,均值类指标服从正态分布;概率类指标本质上服从二项分布,但当数量足够大时,也服从正态分布。
看到这两个结论你可能会有很多问题:
- 什么是正态分布?什么是二项分布?
- “数量足够大”具体是需要多大的数量?
- 概率类指标,为什么可以既服从二项分布又服从正态分布?
不要着急,我这就来一一为你解答。
正态分布(Normal Distribution)
正态分布是A/B测试的指标中最主要的分布,是计算样本量大小和分析测试结果的前提。
在统计上,如果一个随机变量x的概率密度函数(Probability Density Function)是:
[- f(x)=\frac{1}{\sigma \sqrt{2 \pi}} e^{-\frac{1}{2}\left(\frac{x-\mu}{\sigma}\right)^{2}}- ]
[- \begin{aligned}- \mu &=\frac{x_{1}+x_{2}+\cdots+x_{n}}{n} \\\- \sigma &=\sqrt{\frac{\sum_{i}^{n}\left(x_{i}-\mu\right)^{2}}{n}}- \end{aligned}- ]
那么,x就服从正态分布。
其中 ,μ为x的平均值(Mean),σ为x的标准差(Standard Deviation),n为随机变量x的个数,xi为第i个x的值。
随机变量x服从正态分布时的直方图(Histogram)如下:
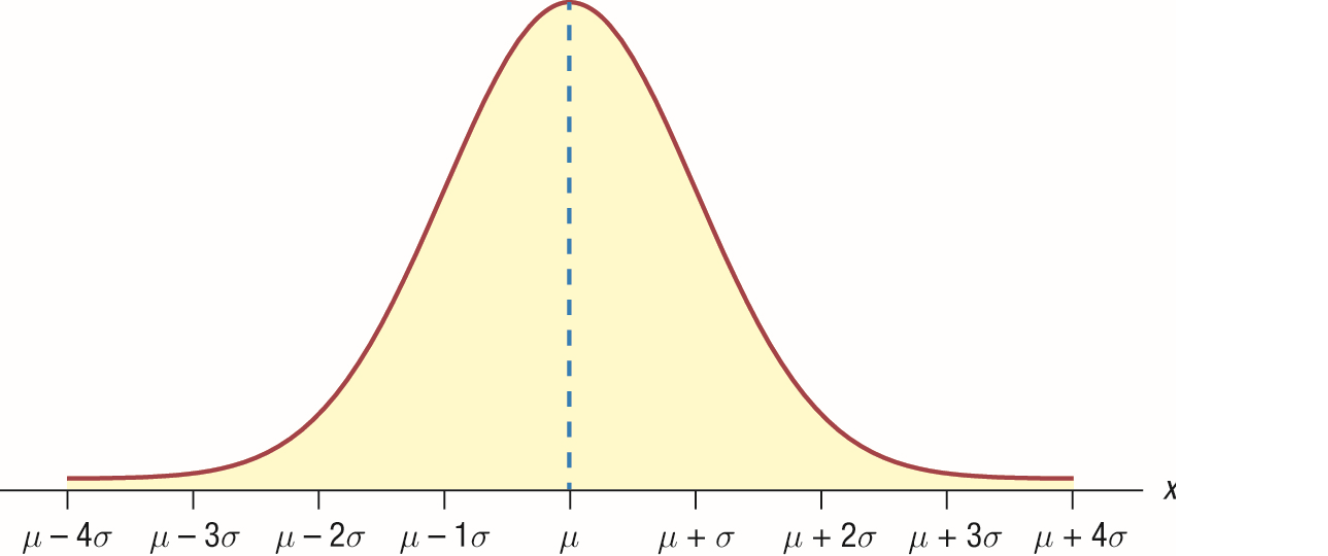
直方图是表征随机变量分布的图表,其中横轴为x可能的取值,纵轴为每个值出现的概率。通过直方图你可以看到,距离平均值μ越近的值出现的概率越高。
除了平均值μ,你还能在直方图和概率密度函数中看到另一个非常重要的参数:标准差σ。σ通过计算每个随机变量的值和平均值μ的差值,来表征随机变量的离散程度(偏离平均值的程度)。
接下来,我们就来看看标准差σ是怎么影响随机变量的分布的。
为了方便理解,我们用Python做一个简单的模拟,选取服从正态分布的随机变量x,其平均值μ=0;分别把x的标准差σ设置为1.0、2.0、3.0、4.0, 然后分别做出直方图。对应的Python代码和直方图如下: from scipy.stats import norm import numpy as np import matplotlib.pyplot as plt /#/# 构建图表 fig, ax = plt.subplots() x = np.linspace(-10,10,100) sigma = [1.0, 2.0, 3.0, 4.0] for s in sigma: ax.plot(x, norm.pdf(x,scale=s), label=’σ=%.1f’ % s) /#/# 加图例 ax.set_xlabel(‘x’) ax.set_ylabel(‘Density’) ax.set_title(‘Normal Distribution’) ax.legend(loc=’best’, frameon=True) ax.set_ylim(0,0.45) ax.grid(True)
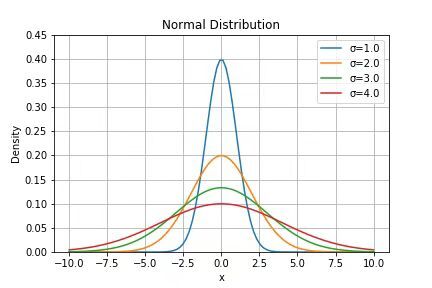
通过这个直方图去看标准差σ对随机变量分布的影响,是不是就更直观了?σ越大,x偏离平均值μ的程度越大,x的取值范围越广,波动性越大,直方图越向两边分散。
咱们再举个生活中的例子来理解标准差。在一次期末考试中,有A和B两个班的平均分都是85分。其中,A班的成绩范围在70~100分,通过计算得到成绩的标准差是5分;B的成绩范围在50~100分,计算得到的成绩标准差是10分。你看,A班的成绩分布范围比较小,集中在85分左右,所以标准差也就更小。
说到标准差,你应该还会想到另一个用来表征随机变量离散程度的概念,就是方差(Variance)。其实,方差就是标准差的平方。所以,标准差σ和方差在表征离散程度上其实是可以互换的。
有了方差和标准差,我们就可以描述业务指标的离散程度了,但要计算出业务指标的波动范围(我会在第4讲展开具体的计算方法),我们还差一步。这一步就是z分数。
要解释z分数,就要引出一种特殊的正态分布,也就是标准正态分布(Standard Normal Distribution),其实就是平均值μ=0、标准差σ=1的正态分布。
标准正态分布的直方图如下所示:
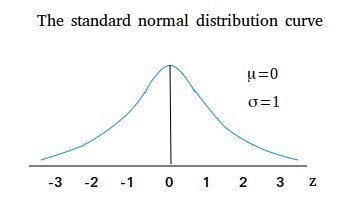
这里的横轴就是z分数(Z Score),也叫做标准分数(Standard Score):
[- \mathrm{z} \text { score }=\frac{x-\mu}{\sigma}- ]
事实上,任何一个正态分布都可以通过标准化(Standardization)变成标准正态分布。而标准化的过程,就是按照上面这个公式把随机变量x变为z分数。不同z分数的值,代表x的不同取值偏离平均值μ多少个标准差σ。比如,当z分数等于1时,说明该值偏离平均值1个标准差σ。
我们再用一个社交App业务指标的例子,来强化下对正态分布的理解。
现在有一个社交App,我们想要了解用户日均使用时间t的概率分布。根据现有的数据,1万个用户在一个月内每天使用App的时间,我们做出了一个直方图:
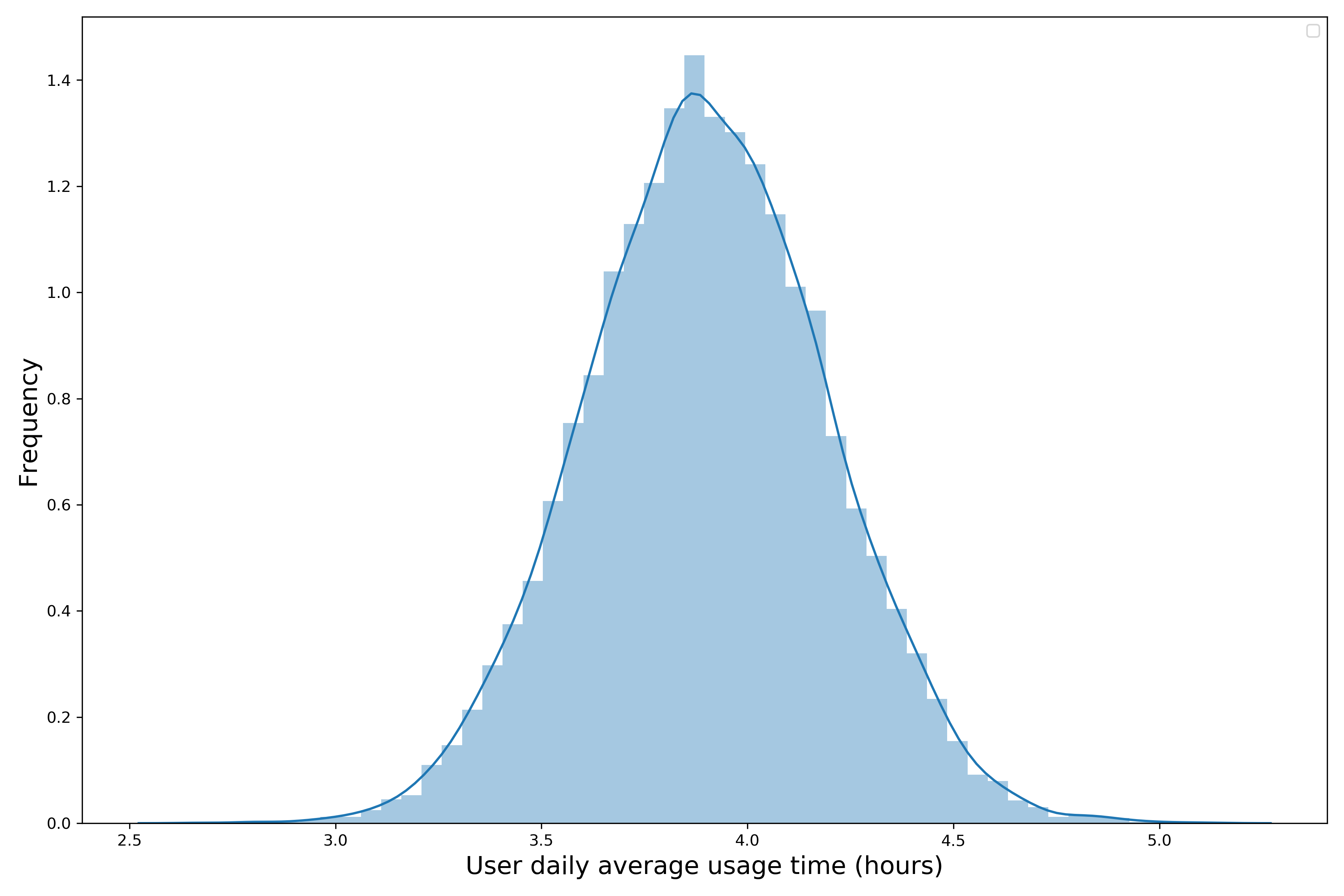
可以看出,这1万个用户的日均使用时间t,大约在3-5小时这个范围,而且是近似正态分布的钟形曲线,说明t的分布也可以近似为正态分布。
中心极限定理(Central Limit Theorem)
这其实是均值类变量的特性:当样本量足够大时,均值类变量会趋近于正态分布。这背后的理论基础,就是中心极限定理。
中心极限定理的数学证明和推理过程十分复杂,但不用害怕,我们只要能理解它的大致原理就可以了:不管随机变量的概率分布是什么,只要取样时的样本量足够大,那么这些样本的平均值的分布就会趋近于正态分布。
那么,这个足够大的样本量到底是多大呢?
统计上约定俗成的是,样本量大于30就属于足够大了。在现在的大数据时代,我们的样本量一般都能轻松超过30这个阈值,所以均值类指标可以近似为正态分布。
到这里,“数量足够大”具体是需要多大的数量,以及什么是正态分布,这两个问题我们就都明白了。接下来,我们再学习下什么是二项分布,之后我们就可以理解为什么概率类指标可以既服从二项分布又服从正态分布了。
二项分布(Binomial Distribution)
业务中的概率类指标,具体到用户行为时,结果只有两种:要么发生,要么不发生。比如点击率,就是用来表征用户在线上点击特定内容的概率,一个用户要么点击,要么不点击,不会有第三种结果发生。
这种只有两种结果的事件叫做二元事件(Binary Event)。二元事件在生活中很常见,比如掷硬币时只会出现正面或者反面这两种结果,所以统计学中有专门有一个描述二元事件概率分布的术语,也就是二项分布(Binomial Distribution)。
这里我们还是结合着社交App的例子,来学习下二元分布。
这款社交App在网上投放了广告,来吸引人们点击广告从而下载App。现在我们想通过数据看看App下载率的分布情况:
下载率 = 通过广告下载App的用户数量 / 看到广告的用户数量。
因为单个二元事件的结果,只能是发生或者不发生,发生的概率要么是100%要么是0%,所以我们要分析下载率就必须把数据进行一定程度的聚合。这里,我们就以分钟为单位来举例,先计算每分钟的下载率,再看它们的概率分布。
我们有一个月的用户及下载数据,一个月一共有43200分钟(60/24/30),因为我们关注的是每分钟的下载率,所以一共有43200个数据点。通过数据分析发现,每分钟平均有10个人会看到广告,下载率集中分布在0-30%之间。
下图是每分钟下载率的概率分布:
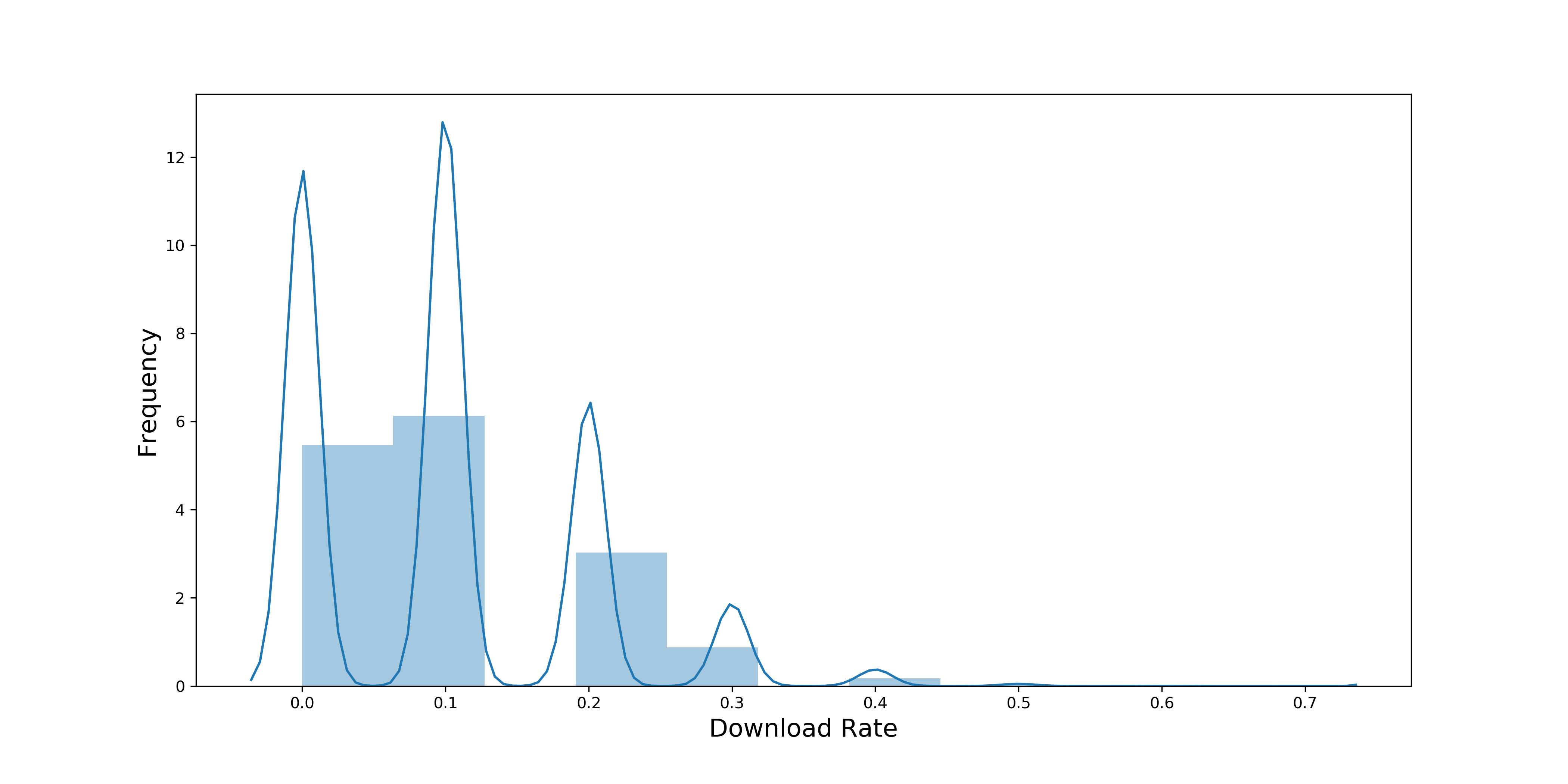
你可能会说,概率在某种程度上也是平均值,可以把这里的下载率理解为“看到广告的用户的平均下载量”,那我们已经有43200个数据点了,样本量远远大于30,但为什么下载率的分布没有像中心极限定理说的那样趋近于正态分布呢?
这是因为在二项分布中,中心极限定理说的样本量,指的是计算概率的样本量。在社交App的例子中,概率的样本量是10,因为平均每分钟有10人看到广告,还没有达到中心极限定理中说的30这个阈值。所以,我们现在要提高这个样本量,才能使下载率的分布趋近正态分布。
提高样本量的方法也很简单,可以计算每小时的下载率。因为每小时平均有600人看到广告,这样我们的样本量就从10提高到了600。下图是每小时下载率的概率分布:
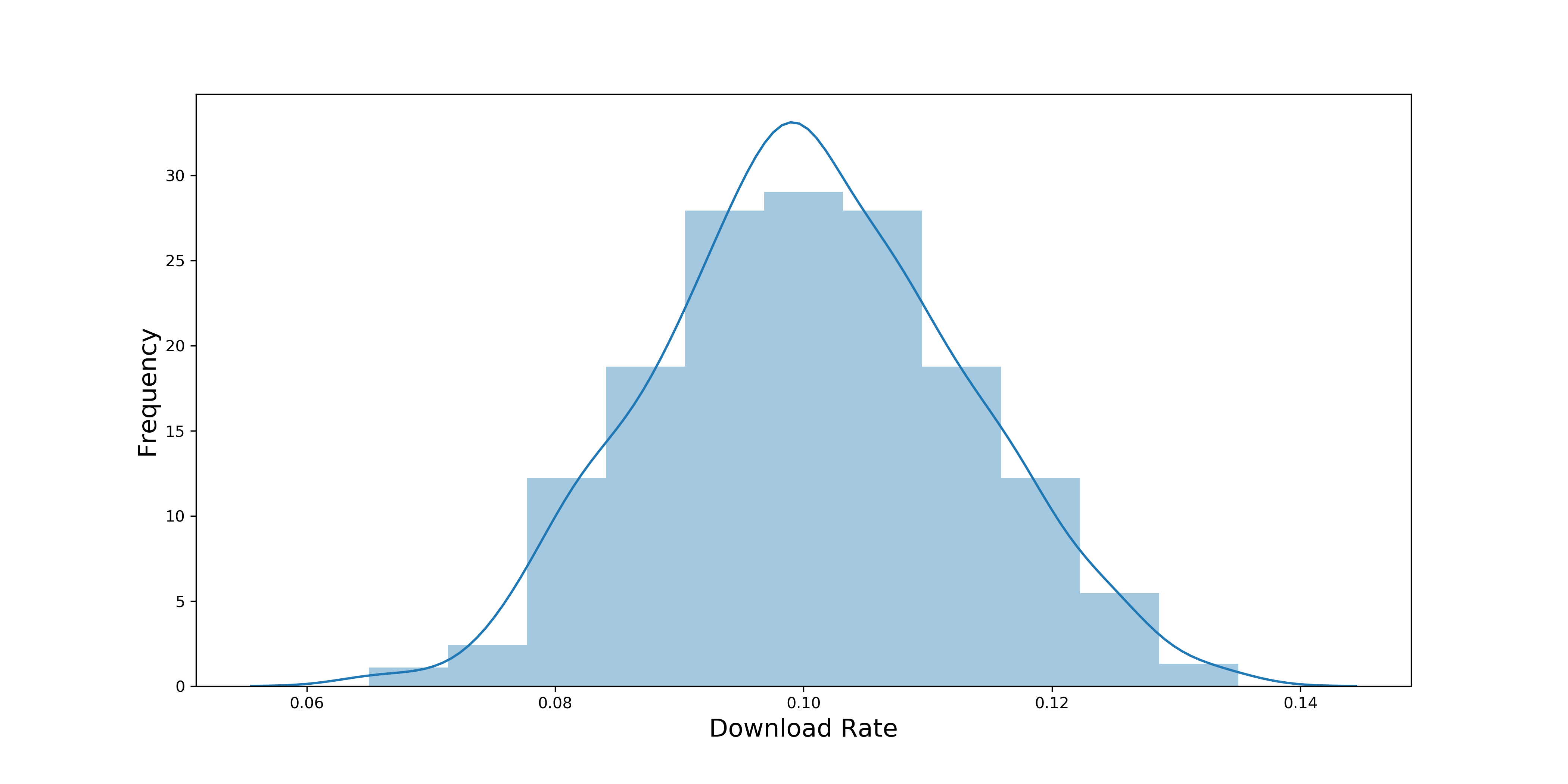
现在再看这张直方图,每小时下载率的分布是不是就趋近于正态分布了!图中下载率的平均值大约为10%。
在二项分布中,有一个从实践中总结出的经验公式:min(np,n(1-p)) >= 5。其中,n为样本大小,p为概率的平均值。
这个公式的意思是说,np或者n(1-p)中相对较小的一方大于等于5,只有二项分布符合这个公式时,才可以近似于正态分布。这是中心极限定理在二项分布中的变体。
在我们的例子中,计算每分钟下载率的概率分布时,np=10/10%=1,小于5,所以不能近似成正态分布;计算每小时下载率的概率分布时,np=600/10%=60,大于等于5,所以可以近似成正态分布。
我们可以利用这个公式来快速判断概率类指标是不是可以近似成正态分布。不过你也可以想象在实践中的A/B测试,由于样本量比较大,一般都会符合以上公式的。
小结
今天这节课,我们主要学习了A/B测试和假设检验的前提,也就是指标的统计属性。我给你总结成了一个定理、两个分布和三个概念:
- 一个定理:中心极限定理。
- 两个分布:正态分布和二项分布。
- 三个概念:方差,标准差和z分数。
生活中随机变量的分布有很多种,今天我重点给你介绍了正态分布和二项分布,它们分别对应的是最普遍的两类业务指标:均值类和概率类。
而且你要知道,有了中心极限定理,我们就可以把业务中的大部分指标都近似成正态分布了。这一点非常重要,因为A/B测试中的很多重要步骤,比如计算样本量大小和分析测试结果,都是以指标为正态分布为前提的。
同时,你还可以用通过方差和标准差来了解业务指标的离散程度,再结合z分数就可以计算出业务指标的波动范围了。只有理解了指标的波动范围,才能够帮助我们得到更加准确的测试结果。
在下节课中,我们继续学习A/B测试的统计基础,也就是假设检验及其相关的统计概念。
思考题
我在刚开始接触概率类指标的二项分布时对于其如何能近似成正态分布很迷惑,大家可以在这里聊一聊在学习A/B测试的统计过程中有什么难理解的地方,以及是如何解决的?
欢迎在留言区写下你的思考和想法,我们可以一起交流讨论。如果你觉得有所收获,欢迎你把课程分享给你的同事或朋友,一起共同进步!
参考资料
https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/AB%20%e6%b5%8b%e8%af%95%e4%bb%8e%200%20%e5%88%b0%201/01%20%e7%bb%9f%e8%ae%a1%e5%9f%ba%e7%a1%80%ef%bc%88%e4%b8%8a%ef%bc%89%ef%bc%9a%e7%b3%bb%e7%bb%9f%e6%8e%8c%e6%8f%a1%e6%8c%87%e6%a0%87%e7%9a%84%e7%bb%9f%e8%ae%a1%e5%b1%9e%e6%80%a7.md
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
