17 网络优化(下):大数据下网络该如何监控? 通过上一期的学习,我们对如何打造一个高质量的网络已经有了一个整体的认识。但是这就足够了吗?回想一下,一个网络请求从手机到后台服务器,会涉及基站、光纤、路由器这些硬件设施,也会跟运营商和服务器机房有关。
不论是基站故障、光纤被挖断、运营商挟持,还是我们的机房、CDN服务商出现故障,都有可能会引起用户网络出现问题。你有没有感觉线上经常突发各种千奇百怪的网络问题,很多公司的运维人员每天过得胆战心惊、疲于奔命。
“善良”的故障过了一段时间之后莫名其妙就好了,“顽固”的故障难以定位也难以解决。这些故障究竟是如何产生的?为什么突然就恢复了?它们影响了多少用户、哪些用户?想要解决这些问题离不开高质量的网络,而高质量的网络又离不开强大的监控。今天我们就一起来看看网络该如何监控吧。
移动端监控
对于移动端来说,我们可能会有各种各样的网络请求。即使使用了OkHttp网络库,也可能会有一些开发人员或者第三方组件使用了系统的网络库。那应该如何统一的监控客户端的所有的网络请求呢?
1. 如何监控网络
第一种方法:插桩。
为了兼容性考虑,我首先想到的还是插桩。360开源的性能监控工具ArgusAPM就是利用Aspect切换插桩,实现监控系统和OkHttp网络库的请求。
系统网络库的插桩实现可以参考TraceNetTrafficMonitor,主要利用Aspect的切面功能,关于OkHttp的拦截可以参考OkHttp3Aspect,它会更加简单一些,因为OkHttp本身就有代理机制。 @Pointcut(“call(public okhttp3.OkHttpClient build())”) public void build() { } @Around(“build()”) public Object aroundBuild(ProceedingJoinPoint joinPoint) throws Throwable { Object target = joinPoint.getTarget(); if (target instanceof OkHttpClient.Builder && Client.isTaskRunning(ApmTask.TASK_NET)) { OkHttpClient.Builder builder = (OkHttpClient.Builder) target; builder.addInterceptor(new NetWorkInterceptor()); } return joinPoint.proceed(); }
插桩的方法看起来很好,但是并不全面。如果使用的不是系统和OkHttp网络库,又或者使用了Native代码的网络请求,都无法监控到。
第二种方法:Native Hook。
跟I/O监控一样,这个时候我们想到了强大的Native Hook。网络相关的我们一般会Hook下面几个方法 :
- 连接相关:connect。
- 发送数据相关:send和sendto。
- 接收数据相关:recv和recvfrom。
Android在不同版本Socket的逻辑会有那么一些差异,以Android 7.0为例,Socket建连的堆栈如下: java.net.PlainSocketImpl.socketConnect(Native Method) java.net.AbstractPlainSocketImpl.doConnect java.net.AbstractPlainSocketImpl.connectToAddress java.net.AbstractPlainSocketImpl.connect java.net.SocksSocketImpl.connect java.net.Socket.connect com.android.okhttp.internal.Platform.connectSocket com.android.okhttp.Connection.connectSocket com.android.okhttp.Connection.connect
“socketConnect”方法对应的Native方法定义在PlainSocketImpl.c,查看makefile可以知道它们会编译在libopenjdk.so中。不过在Android 8.0,整个调用流程又完全改变了。为了兼容性考虑,我们直接PLT Hook内存的所有so,但是需要排除掉Socket函数本身所在的libc.so。
hook_plt_method_all_lib(“libc.so”, “connect”, (hook_func) &create_hook); hook_plt_method_all_lib(“libc.so, “send”, (hook_func) &send_hook); hook_plt_method_all_lib(“libc.so”, “recvfrom”, (hook_func) &recvfrom_hook); …
这种做法不好的地方在于会把系统的Local Socket也同时接管了,需要在代码中增加过滤条件。在今天的Sample中,我给你提供了一套简单的实现。其实无论是哪一种Hook,如果熟练掌握之后你会发现它并不困难。我们需要耐心地寻找,梳理清楚整个调用流程。
第三种方法:统一网络库。
尽管拿到了所有的网络调用,想想会有哪些使用场景呢?模拟网络数据、统计应用流量,或者是单独代理WebView的网络请求。

一般来说,我们不会非常关心第三方的网络请求情况,而对于我们应用自身的网络请求,最好的监控方法还是统一网络库。不过我们可以通过插桩和Hook这两个方法,监控应用中有哪些地方使用了其他的网络库,而不是默认的统一网络库。
在上一期内容中,我说过“网络质量监控”应该是客户端网络库中一个非常重要的模块,它也会跟大网络平台的接入服务共同协作。通过统一网络库的方式,的确无法监控到第三方的网络请求。不过我们可以通过其他方式拿到应用的整体流量使用情况,下面我们一起来看看。
2. 如何监控流量
应用流量监控的方法非常简单,一般通过TrafficStats类。TrafficState是Android API 8加入的接口,用于获取整个手机或者某个UID从开机算起的网络流量。至于如何使用,你可以参考Facebook一个历史比较久远的开源库network-connection-class。 getMobileRxBytes() //从开机开始Mobile网络接收的字节总数,不包括Wifi getTotalRxBytes() //从开机开始所有网络接收的字节总数,包括Wifi getMobileTxBytes() //从开机开始Mobile网络发送的字节总数,不包括Wifi getTotalTxBytes() //从开机开始所有网络发送的字节总数,包括Wifi
它的实现原理其实也非常简单,就是利用Linux内核的统计接口。具体来说,是下面两个proc接口。
// stats接口提供各个uid在各个网络接口(wlan0, ppp0等)的流量信息 /proc/net/xt_qtaguid/stats // iface_stat_fmt接口提供各个接口的汇总流量信息 proc/net/xt_qtaguid/iface_stat_fmt
TrafficStats的工作原理是读取proc,并将目标UID下面所有网络接口的流量相加。但如果我们不使用TrafficStats接口,而是自己解析proc文件呢?那我们可以得到不同网络接口下的流量,从而计算出WiFi、2G/3G/4G、VPN、热点共享、WiFi P2P等不同网络状态下的流量。
不过非常遗憾的是,Android 7.0之后系统已经不让我们直接去读取stats文件,防止开发者可以拿到其他应用的流量信息,因此只能通过TrafficStats拿到自己应用的流量信息。
除了流量信息,通过/proc/net我们还可以拿到大量网络相关的信息,例如网络信号强度、电平强度等。Android手机跟iPhone都有一个网络测试模式,感兴趣的同学可以尝试一下。
- iPhone:打开拨号界面,输入“/3001/#12345/#/”,然后按拨号键。
- Android手机:打开拨号界面,输入“//#//#4636/#//#/”,然后按拨号键(可进入工程测试模式,部分版本可能不支持)。
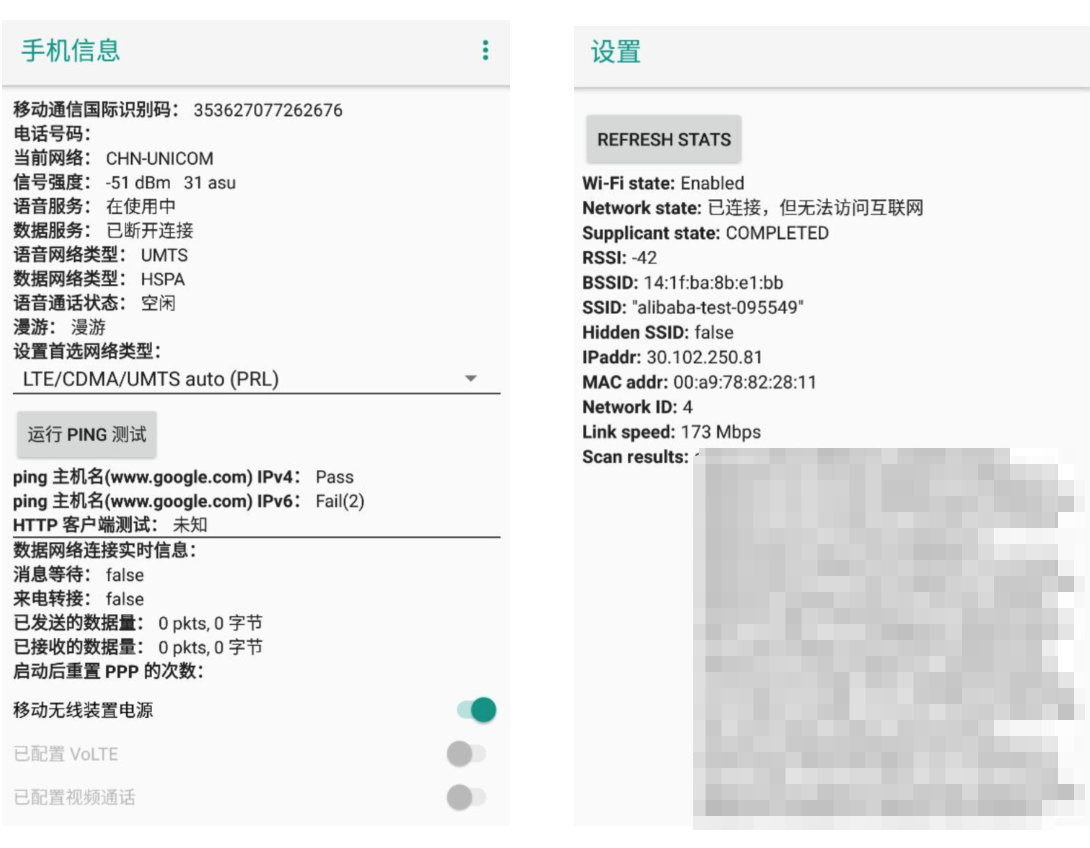
为什么系统可以判断此时的WiFi“已连接,但无法访问互联网”?回想一下专栏第15期我给你留的课后作业: iPhone的无线网络助理、小米和一加的自适应WLAN它们在检测WiFi不稳定时会自动切换到移动网络。那请你思考一下,它们是如何实现侦测,如何区分是应用后台服务器出问题还是WiFi本身有问题呢?
我看了一下同学们的回复,大部分同学认为需要访问一个公网IP的方式。其实对于手机厂商来说根据不需要,它在底层可以拿到的信息有很多。
- 网卡驱动层信息。如射频参数,可以用来判断WiFi的信号强度;网卡数据包队列长度,可以用来判断网络是否拥塞。
- 协议栈信息。主要是获取数据包发送、接收、时延和丢包等信息。
如果一个WiFi发送过数据包,但是没有收到任何的ACK回包,这个时候就可以初步判断当前的WiFi是有问题的。这样系统可以知道当前WiFi大概率是有问题的,它并不关心是不是因为我们后台服务器出问题导致的。
大网络平台监控
前面我讲了一些应用网络请求和流量的监控方法,但是还没真正回答应该如何去打造一套强大的网络监控体系。跟网络优化一样,网络监控不是客户端可以单独完成的,它也是整个大网络平台的一个重要组成部分。
不过首先我们需要在客观上承认这件事情做起来并不容易,因为网络问题会存在下面这些特点:
- 实时性。部分网络问题过时不候,可能很快就丢失现场。
- 复杂性。可能跟国家、地区、运营商、版本、系统、机型、CDN都有关,不仅维度多,数据量也巨大。
- 链路长。整个请求链条非常长,客户端故障、网链障络、服务故障都有可能。
因此所谓的网络监控,并不能保证可以明确找到故障的原因。而我们目标是希望快速发现问题,尽可能拿到更多的辅助信息,协助我们更容易地排查问题。
下面我分别从客户端与接入层的角度出发,一起来看看哪些信息可以帮助我们更好地发现问题和解决问题。
1. 客户端监控
客户端的监控使用统网络库的方式,你可以想想我们需要关心哪些内容:
- 时延。一般我们比较关心每次请求的DNS时间、建连时间、首包时间、总时间等,会有类似1秒快开率、2秒快开率这些指标。
- 维度。网络类型、国家、省份、城市、运营商、系统、客户端版本、机型、请求域名等,这些维度主要用于分析问题。
- 错误。DNS失败、连接失败、超时、返回错误码等,会有DNS失败率、连接失败率、网络访问的失败率这些指标。
通过这些数据,我们也可以汇总出应用的网络访问大图。例如在国内无论我们去到哪里都会问有没有WiFi,WiFi的占比会超过50%。这其实远远比海外高,在印度WiFi的占比仅仅只有15%左右。

同样的我们分版本、分国家、分运营商、分域名等各种各样的维度,来监控我们的时延和错误这些访问指标。
由于维度太多,每个维度的取值范围也很广,如果是实时计算整个数据量会非常非常大。对于客户端的上报数据,微信可以做到分钟级别的监控报警。不过为了运算简单我们会抛弃UV,只计算每一分钟部分维度的PV。
2. 接入层监控
客户端监控的数据会比接入层更加丰富,因为有可能会出现部分数据还没到达接入层就已经被打回,例如运营商劫持的情况。
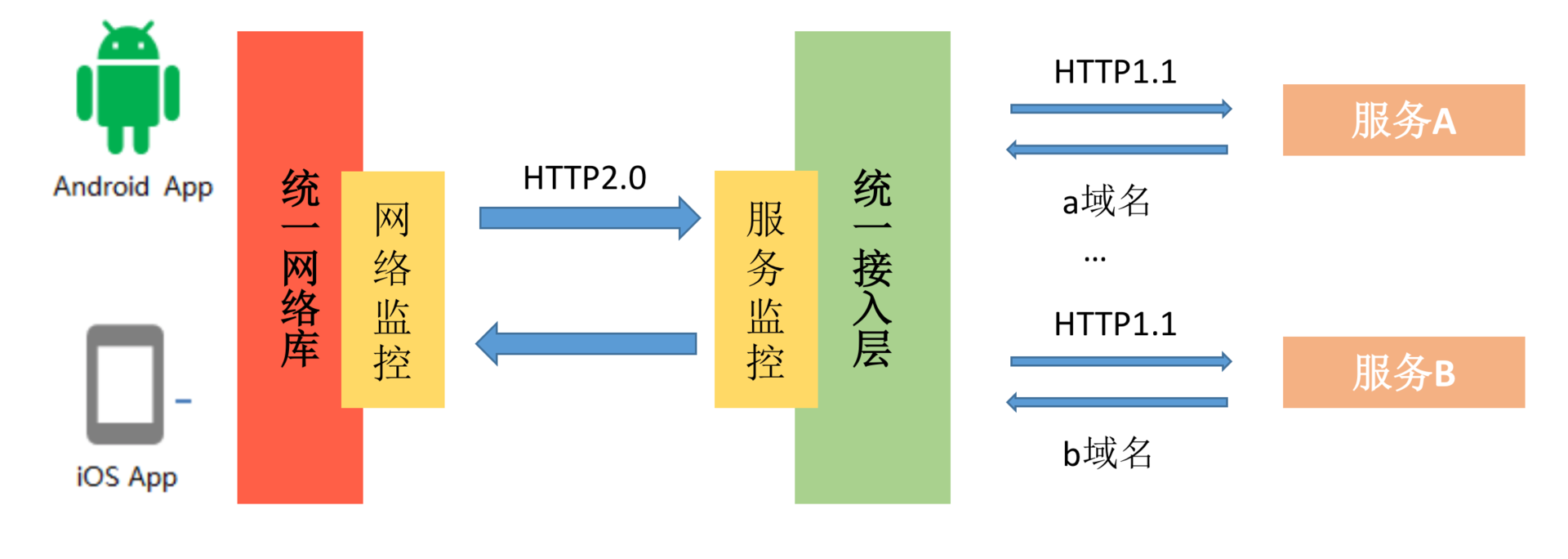
但是接入层的数据监控还是非常有必要的,主要的原因是:
- 实时性。客户端如果使用秒级的实时上报,对用户性能影响会比较大。服务端就不会存在这个问题,它很容易可以做到秒级的监控。
- 可靠性。如果出现某些网络问题,客户端的数据上报通道可能也会受到影响,客户端的数据不完全可靠。
那接入层应该关心哪些数据呢?一般来说,我们会比较关心服务的入口和出口流量、服务端的处理时延、错误率等。
3. 监控报警
无论是客户端还是接入层的监控,它们都是分层的。
- 实时监控。秒级或者分钟级别的实时监控的信息会相比少一些,例如只有访问量(PV)、错误率,没有去拆分几百个上千个维度,也没有独立访问用户数(UV),实时监控的目的是最快速度发现问题。
- 离线监控。小时或者天级别的监控我们可以拓展出全部的维度来做监控,它的目的是在监控的同时,可以更好地圈出问题的范围。
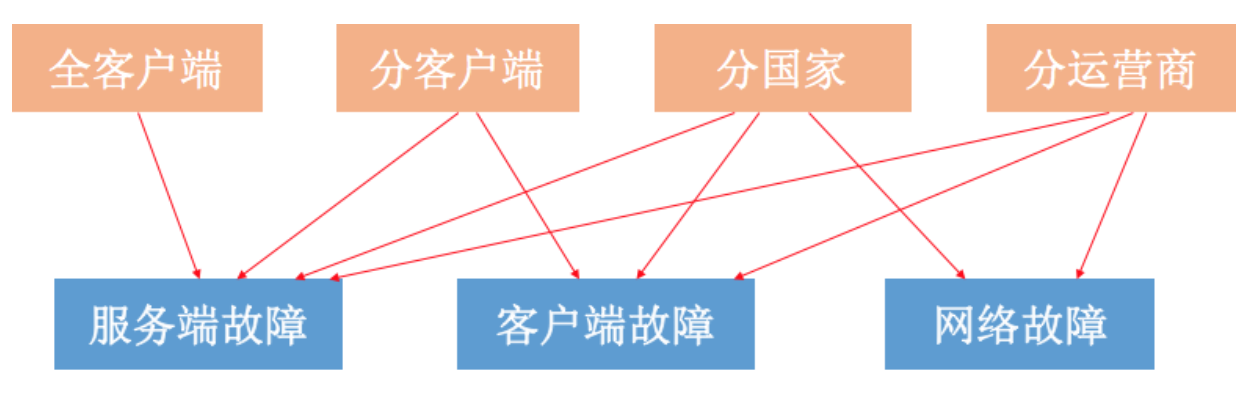
下面是一个简单根据客户端、国家以及运营商维度分析的示例。当然更多的时候是某一个服务出现问题,这个时候通过分域名或者错误码就可以很容易的找到原因。
那在监控的同时如何实现准确的自动化报警呢?这同样也是业界的一个难题,它的难度在于如果规则过于苛刻,可能会出现漏报;如果过于宽松,可能会出现太多的误报。
业界一般存在两种报警的算法,一套是基于规则,例如失败率与历史数据相比暴涨、流量暴跌等。另一种是基于时间序列算法或者神经网络的智能化报警,使用者不需要录入任何规则,只需有足够长的历史数据,就可以实现自动报警。智能化报警目前准确性也存在一些问题,在智能化基础上面添加少量规则可能会是更好的选择。
如果我们收到一个线上的网络报警,通过接入层和客户端的监控报表,也会有了一个大致的判断。那怎么样才能确定问题的最终原因?我们是否可以拿到用户完整的网络日志?甚至远程地诊断用户的网络情况?关于“网络日志和远程诊断,如何快速定位网络问题”,我会把它单独成篇放在专栏第二模块里,再来讲讲这个话题。
总结
监控、监控又是监控,很多性能优化工作其实都是“三分靠优化,七分靠监控”。
为什么监控这么重要呢?对于大公司来说,每一个项目参与人员可能成百上千人。并且大公司要的不是今天或者这个版本可以做好一些事情,而是希望保证每天每个版本都能持续保持应用的高质量。另一方面有了完善的分析和监控的平台,我们可以把复杂的事情简单化,把一些看起来“高不可攀”的优化工作,变成人人都可以做。
最后多谈两句我的感受,我们在工作的时候,希望你可以看得更远,从更高的角度去思考问题。多想想如果我能做好这件事情,怎么保证其他人不会犯错,或者让所有人都可以做得更好。
课后作业
对于网络问题,你尝试过哪些监控方法?有没有令你印象深刻的网络故障,最终又是通过什么方式解决的呢?欢迎留言跟我和其他同学一起讨论。
今天我们练习的Sample是通过PLT Hook,代理Socket相关的几个重要函数,这次还增加了一个一次性Hook所有已经加载Library的方法。 int hook_plt_method_all_lib(const char/* exclueLibname, const char/* name, hook_func hook) { if (refresh_shared_libs()) { // Could not properly refresh the cache of shared library data return -1; } int failures = 0; for (auto const& lib : allSharedLibs()) { if (strcmp(lib.first.c_str(), exclueLibname) != 0) { failures += hook_plt_method(lib.first.c_str(), name, hook); } } return failures; }
希望你通过这几次课后练习,可以学会将Hook技术应用到实践当中。
欢迎你点击“请朋友读”,把今天的内容分享给好友,邀请他一起学习。最后别忘了在评论区提交今天的作业,我也为认真完成作业的同学准备了丰厚的“学习加油礼包”,期待与你一起切磋进步哦。
参考资料
https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/Android%e5%bc%80%e5%8f%91%e9%ab%98%e6%89%8b%e8%af%be/17%20%e7%bd%91%e7%bb%9c%e4%bc%98%e5%8c%96%ef%bc%88%e4%b8%8b%ef%bc%89%ef%bc%9a%e5%a4%a7%e6%95%b0%e6%8d%ae%e4%b8%8b%e7%bd%91%e7%bb%9c%e8%af%a5%e5%a6%82%e4%bd%95%e7%9b%91%e6%8e%a7%ef%bc%9f.md
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
