39 移动开发新大陆: 边缘智能计算的趋势 你好,我是张绍文。今天文章的作者黄振是算法领域的专家,过去曾经和他合作过移动端的AI项目,无论是他的算法水平,还是工程上的能力,都让我深感佩服。今天我非常幸运地请到他来给我们分享关于移动边缘智能计算的认识。
如果说过去几年移动开发是那头在风口上的猪,现在这个风口明显已经转移到AI,最明显的是国内应届生都纷纷涌向了AI方向。那作为移动开发,我们如何在AI浪潮之下占据自己的一席之地?
以我个人看法来看,即使目前AI在移动端的落地场景有限,但是AI这个“坑”我们是一定要跳的。我们可以尝试使用TensorFlow这些框架去做一些简单的Demo,逐步加深对深度学习的理解。
Google的TensorFlow Lite、Facebook的Cafe2、腾讯的NCNN和FatherCNN、小米的MACE、百度的Paddle-Mobile,各个公司都开源了自己的移动深度学习框架。移动端未来必然是深度学习一个非常重要的战场,移动开发们需要发挥自己的平台特长。我们对于这些移动深度学习框架的优化应该更有发言权,要做到既有算法思维,也有更加强大的工程能力。就像之前黄振合作的项目中,整个框架的性能优化也是由我们来主导,使用了大量ARM NEON指令和汇编进行优化。
大家好,我是黄振,目前在一家大型互联网公司从事算法工作。我一直在关注边缘智能计算,正好过去也开展过移动端机器学习的项目,期间也接触了不少Android开发的同学。在一起合作期间,我也在思考AI和Android开发可以相结合的点,也看到团队中不少Android开发同学展现出的机器学习技术的开发能力。正好应绍文邀请,在Android开发专栏和你分享一下我对移动端机器学习的认识,希望对你有所帮助。
目前,技术的发展有两个趋势。一个趋势是,随着5G网络的发展,物联网使“万物互联”成为可能。物联网时代,也是云计算和边缘计算并存的世界,且边缘计算将扮演重要的角色。边缘计算是与云计算相反的计算范式,指的是在网络边缘节点(终端设备)进行数据处理和分析。边缘计算之所以重要,原因在于:首先,在物联网时代,将有数十亿的终端设备持续采集数据,带来的计算量将是云计算所不能承受的;其次,终端设备的计算能力不断提高,并不是所有的计算都需要在云端完成;再有,将数据传回云端计算再将结果返回终端的模式,不可避免存在时延,不仅影响用户体验,有些场景也是不可接受的;最后,随着用户对数据安全和隐私的重视,也会要求在终端进行数据加工和计算。
另一个趋势是,人工智能技术的迅速发展。最近几年,以深度学习为代表的人工智能技术取得了突破性的进展,不仅在社会上引起了人们的兴趣和关注,同时也正在重塑商业的格局。人工智能技术的重大价值在于,借助智能算法和技术,将之前必须人工才能完成的工作进行机器化,用机器的规模化解放人工,突破人力生产要素的瓶颈,从而大幅提高生产效率。在商业社会,“规模化”技术将释放巨大的能量、创造巨大的价值,甚至重塑商业的竞争,拓展整个商业的外部边界。
边缘计算既然有计算能力,在很多应用场景中就会产生智能计算的需求,两者结合在一起,就形成了边缘智能计算。
移动端机器学习的开发技术
目前,移动端机器学习的应用技术主要集中在图像处理、自然语言处理和语音处理。在具体的应用上,包括但不限于视频图像的物体检测、语言翻译、语音助手、美颜等,在自动驾驶、教育、医疗、智能家居和物联网等方面有巨大的应用需求。
1. 计算框架
因为深度学习算法具有很多特定的算法算子,为了提高移动端开发和模型部署的效率,各大厂都开发了移动端深度学习的计算框架,例如谷歌的TensorFlow Lite、Facebook的Caffe2等,Android开发的同学还是挺有必要去了解这些计算框架的。为了培养兴趣这方面的兴趣并获得感性的认识,你可以挑选一个比较成熟的大厂框架,例如TensorFlow Lite,在手机开发一个物体检测的Demo练练手。
在实际项目中,TensorFlow Lite和Caffe2等通常运行比较慢。在网上可以很容易找到各个计算框架的对比图。如果要真正入门的话,在这里我推荐大家使用NCNN框架。NCNN是腾讯开源的计算框架,优点比较明显,代码结构清晰、文件不大,而且运行效率高。强烈推荐有兴趣的Android开发同学把源码阅读几遍,不仅有助于理解深度学习常用的算法,也有助于理解移动端机器学习的计算框架。
阅读NCNN源码抓住三个最基础的数据结构,Mat、Layer和Net。其中,Mat用于存储矩阵的值,神经网络中的每个输入、输出以及权重,都是用Mat来存储的。Layer实际上表示操作,所以每个Layer都必须有前向操作函数(forward函数),所有算子,例如,卷积操作(convolution)、LSTM操作等都是从Layer派生出来的。Net用来表示整个网络,将所有数据节点和操作结合起来。
在阅读NCNN源码的同时,建议大家也看些关于卷积神经网络算法的入门资料,会有助于理解。
2. 计算性能优化
在实际项目中,如果某个路径成为时间开销的瓶颈,通常可以将该节点用NDK去实现。但在通常情况下,移动端机器学习的计算框架已经是NDK实现的,这时改进的方向是采用ARM NEON指令+汇编进行优化。
NEON是适用于ARM Cortex-A系列处理器的一种128Bit SIMD(Single Instruction, Multiple Data,单指令、多数据)扩展结构。ARM NEON指令之所有能达到性能优化的目的,关键就在于单指令多数据。如下图所示:
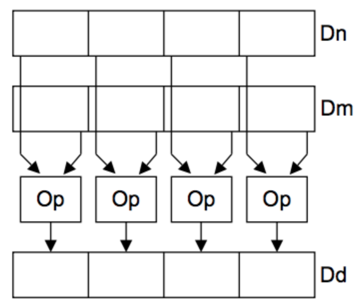
两个操作数各有128Bit,各包含4个32Bit的同类型的寄存器,通过如下所示的一条指令,就可以实现4个32Bit数据的并行计算,从而达到性能优化的效果。 VADDQ.S32 Q0,Q1,Q2
我们曾经用NDK的方式实现了深度学习算法中的PixelShuffle操作,后来采用ARM NEON+汇编优化的方式,计算的效率提升40倍,效果还是很显著的。
如果还想进一步提高计算的性能,可以采用Int 8量化的方法。在深度学习里面,大多数运算都是基于Float 32类型进行的,Float 32是32Bit,128Bit的寄存器一次可以存储4个Float 32类型数据;相比之下,Int 8类型的数据可以存储16个。结合前面提到的单指令多数据,如果采用Int 8类型的数据,单条指令可以同时执行16个Int 8数据的运算,从而大大提高了并行性。
但是,将Float 32类型的数值量化到Int 8表达,不可避免会影响到数据的精度,而且量化的过程也是需要时间开销的,这些都是需要注意的地方。关于量化的方法,感兴趣的同学可以阅读这篇论文。
如果设备具有GPU,还可以应用OpenCL进行GPU加速,例如小米开源的移动端机器学习框架MACE。
移动端机器学习的算法技术
对于刚开始学习算法的同学,我一直主张不要把算法想象得太复杂,也不要想得太数学化,否则容易让人望而生畏。数学是思维逻辑的表达,我们希望用数学帮助我们理解算法。我们要能够达到对算法的直观理解,从直观上知道和理解为什么这个算法会有这样的效果,只有这样才算是真正掌握了算法。相反,对于一个算法,如果你只记住了数学推导,没形成直观的理解,是不能够灵活应用的。
1. 算法设计
深度学习的图像处理具有很广的应用,而且比较直观和有趣,建议你可以从深度学习的图像处理入手。深度学习的图像处理,最基本的知识是卷积神经网络,所以你可以先学习卷积神经网络。网上有很多关于卷积神经网络的介绍,这里就不赘述了。
理解卷积神经网络关键是理解卷积神经网络的学习机制,理解为什么能够学习。想要理解这一点,首先需要明确两个关键点“前向传播”和“反向传播”。整个神经网络在结构和激活函数确定之后,所谓“训练”或者“学习”的过程,其实就是在不断地调整神经网络的每个权重,让整个网络的计算结果趋近于期望值(目标值)。前向传播是从输入端开始计算,目标是得到网络的输出结果,再将输出结果和目标值相比较,得到结果误差。之后将结果误差沿着网络结构反向传播拆解到每个节点,得到每个节点的误差,然后根据每个节点的误差调整该节点的权重。“前向传播”的目的是得到输出结果,“反向传播”的目的是通过反向传播误差来调整权重。通过两者互相交替迭代,希望达到输出结果和目标值一致。
理解卷积神经网络之后,我们可以动手实现手写字体识别的示例。掌握之后,可以接着学习深度学习里的物体检测算法,例如YOLO、Faster R-CNN等,最后可以动手用TensorFlow都写一遍,跑跑训练数据、调调参数,边动手边理解。在学习过程中,要特别留意算法模型的设计思想和解决思路。
2. 效果优化
效果优化指提升算法模型的准确率等指标,通常的方式有以下几种:
- 优化训练数据
- 优化算法设计
- 优化模型训练方式
优化训练数据
因为算法模型是从训练数据中学习的,模型无法学习到训练数据之外的模式。所以,在选择训练数据时要特别小心,必须使得训练数据包含实际场景中会出现的模式。精心挑选或标注训练数据,会有效提升模型的效果。训练数据的标注对效果非常重要,以至于有创业公司专门从事数据标注,还获得了不少融资。
优化算法设计
根据问题采用更好的算法模型,采用深度学习模型而不是传统的机器学习模型,采用具有更高特征表达能力的模型等,例如使用残差网络或DenseNet提高网络的特征表达能力。
优化模型训练方式
优化模型训练方式包括采用哪种损失函数、是否使用正则项、是否使用Dropout结构、使用哪种梯度下降算法等。
3. 计算量优化
虽然我们在框架侧做了大量的工作来提高计算性能,但是如果在算法侧能够减少计算量,那么整体的计算实时性也会提高。从模型角度,减少计算量的思路有两种,一种是设计轻量型网络模型,一种是对模型进行压缩。
轻量型网络设计
学术界和工业界都设计了轻量型卷积神经网络,在保证模型精度的前提下,大幅减少模型的计算量,从而减少模型的计算开销。这种思路的典型代表是谷歌提出的MobileNet,从名字上也可以看出设计的目标是移动端使用的网络结构。MobileNet是将标准的卷积神经网络运算拆分成Depthwise卷积运算和Pointwise卷积运算,先用Depthwise卷积对输入各个通道分别进行卷积运算,然后用Pointwise卷积实现各个通道间信息的融合。
模型压缩
模型压缩包括结构稀疏化和蒸馏两种方式。
在逻辑回归算法中,我们通过引入正则化,使得某些特征的系数近似为0。在卷积神经网络中,我们也希望通过引入正则化,使得卷积核的系数近似为0。与普通的正则化不同的是,在结构稀疏化中,我们希望正则化实现结构性的稀疏,比如某几个通道的卷积核的系数全部近似为0,从而可以将这几个通道的卷积核剪枝掉,减少不必要的计算开销。
蒸馏方法有迁移学习的意思,就是设计一个简单的网络,通过训练的方式,使得该简单的网络具有目标网络近似的表示能力,从而达到“蒸馏”的效果。
Android开发同学的机会
移动端机器学习的计算框架和算法,前者负责模型计算的性能,减少时间开销;后者主要负责模型的精度,还可以通过一些算法设计减少算法的计算量,从而达到减少时间开销的目的。
需要注意的是,在移动端机器学习中,算法模型的训练通常是在服务器端进行的。目前,终端设备通常不负责模型的训练。在使用时,由终端设备加载训练结果模型,执行前向计算得到模型的计算结果。
但是前面讲了那么多行业趋势和机器学习的基本技术,那对于移动开发的同学来说,如何进入这个“热门”的领域呢?移动端机器学习是边缘智能计算范畴的一个领域,而且移动端开发是Android开发同学特别熟悉的领域,所以这也是Android开发同学的一个发展机会,转型进入边缘智能计算领域。Android开发同学可以发挥自己的技术专业优势,先在边缘计算的终端设备程序开发中站稳脚跟,在未来的技术分工体系中有个坚固的立足点;同时,逐步学习深度学习算法,以备将来往前迈一步,进入边缘智能计算领域,创造更高的技术价值。
可能在大部分情况下,Android开发同学在深度学习算法领域,跟专业的算法同学相比,不具有竞争优势,所以我们千万不要放弃自己所专长的终端设备的开发经验。对大多数Android开发同学而言,“专精Android开发 + 懂深度学习算法”才是在未来技术分工中,创造最大价值的姿势。
对于学习路径,我建议Android开发同学可以先学习卷积神经网络的基础知识(结构、训练和前向计算),然后阅读学习NCNN开源框架,掌握计算性能的优化方法,把开发技术掌握好。同时,可以逐步学习算法技术,主要学习各种常见的深度学习算法模型,并重点学习近几年出现轻量型神经网络算法。总之,Android开发同学要重点掌握提高计算实时性的开发技术和算法技术,兼顾学习深度学习算法模型。
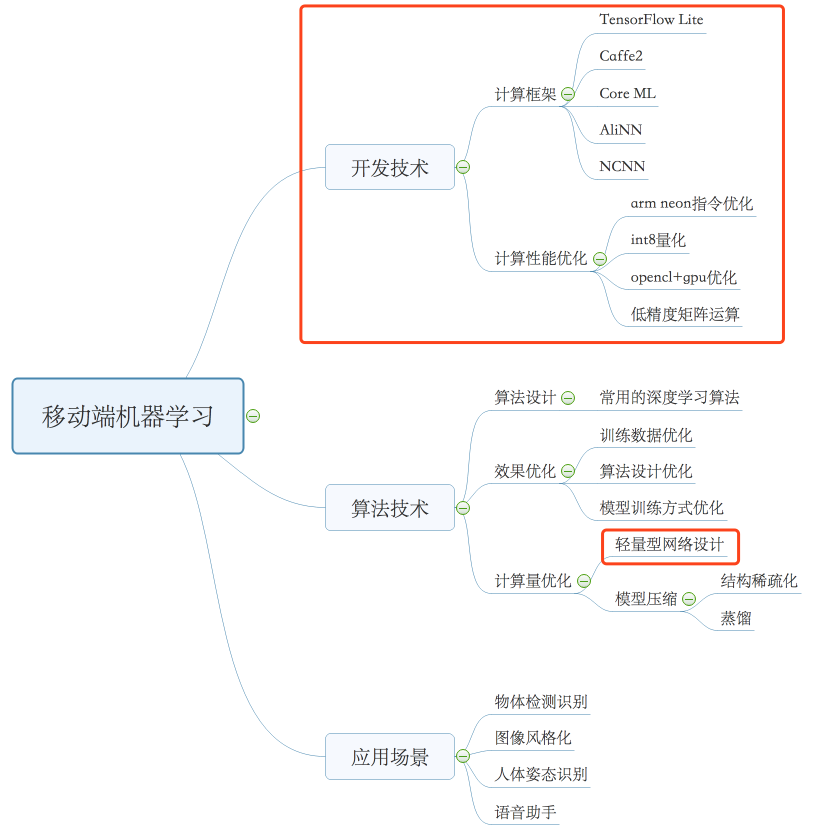
基于前面的描述,我梳理了移动端机器学习的技术大图供你参考。图中红圈的部分,是我建议Android开发同学重点掌握的内容。
欢迎你点击“请朋友读”,把今天的内容分享给好友,邀请他一起学习。我也为认真思考、积极分享的同学准备了丰厚的“学习加油礼包”,期待与你一起切磋进步哦。
参考资料
https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/Android%e5%bc%80%e5%8f%91%e9%ab%98%e6%89%8b%e8%af%be/39%20%e7%a7%bb%e5%8a%a8%e5%bc%80%e5%8f%91%e6%96%b0%e5%a4%a7%e9%99%86%ef%bc%9a%20%e8%be%b9%e7%bc%98%e6%99%ba%e8%83%bd%e8%ae%a1%e7%ae%97%e7%9a%84%e8%b6%8b%e5%8a%bf.md
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
