26 数据存储:NoSQL与RDBMS如何取长补短、相辅相成? 今天,我来和你聊聊数据存储的常见错误。
近几年,各种非关系型数据库,也就是 NoSQL 发展迅猛,在项目中也非常常见。其中不乏一些使用上的极端情况,比如直接把关系型数据库(RDBMS)全部替换为 NoSQL,或是在不合适的场景下错误地使用 NoSQL。
其实,每种 NoSQL 的特点不同,都有其要着重解决的某一方面的问题。因此,我们在使用 NoSQL 的时候,要尽量让它去处理擅长的场景,否则不但发挥不出它的功能和优势,还可能会导致性能问题。
NoSQL 一般可以分为缓存数据库、时间序列数据库、全文搜索数据库、文档数据库、图数据库等。今天,我会以缓存数据库 Redis、时间序列数据库 InfluxDB、全文搜索数据库 ElasticSearch 为例,通过一些测试案例,和你聊聊这些常见 NoSQL 的特点,以及它们擅长和不擅长的地方。最后,我也还会和你说说 NoSQL 如何与 RDBMS 相辅相成,来构成一套可以应对高并发的复合数据库体系。
取长补短之 Redis vs MySQL
Redis 是一款设计简洁的缓存数据库,数据都保存在内存中,所以读写单一 Key 的性能非常高。
我们来做一个简单测试,分别填充 10 万条数据到 Redis 和 MySQL 中。MySQL 中的 name 字段做了索引,相当于 Redis 的 Key,data 字段为 100 字节的数据,相当于 Redis 的 Value:
@SpringBootApplication @Slf4j public class CommonMistakesApplication { //模拟10万条数据存到Redis和MySQL public static final int ROWS = 100000; public static final String PAYLOAD = IntStream.rangeClosed(1, 100).mapToObj(__ -> “a”).collect(Collectors.joining(“”)); @Autowired private StringRedisTemplate stringRedisTemplate; @Autowired private JdbcTemplate jdbcTemplate; @Autowired private StandardEnvironment standardEnvironment; public static void main(String[] args) { SpringApplication.run(CommonMistakesApplication.class, args); } @PostConstruct public void init() { //使用-Dspring.profiles.active=init启动程序进行初始化 if (Arrays.stream(standardEnvironment.getActiveProfiles()).anyMatch(s -> s.equalsIgnoreCase(“init”))) { initRedis(); initMySQL(); } } //填充数据到MySQL private void initMySQL() { //删除表 jdbcTemplate.execute(“DROP TABLE IF EXISTS r;”); //新建表,name字段做了索引 jdbcTemplate.execute(“CREATE TABLE r (\n” + “ id bigint(20) NOT NULL AUTO_INCREMENT,\n” + “ data varchar(2000) NOT NULL,\n” + “ name varchar(20) NOT NULL,\n” + “ PRIMARY KEY (id),\n” + “ KEY name (name) USING BTREE\n” + “) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;”); //批量插入数据 String sql = “INSERT INTO r (data,name) VALUES (?,?)”; jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() { @Override public void setValues(PreparedStatement preparedStatement, int i) throws SQLException { preparedStatement.setString(1, PAYLOAD); preparedStatement.setString(2, “item” + i); } @Override public int getBatchSize() { return ROWS; } }); log.info(“init mysql finished with count {}”, jdbcTemplate.queryForObject(“SELECT COUNT(/) FROM r”, Long.class)); } //填充数据到Redis private void initRedis() { IntStream.rangeClosed(1, ROWS).forEach(i -> stringRedisTemplate.opsForValue().set(“item” + i, PAYLOAD)); log.info(“init redis finished with count {}”, stringRedisTemplate.keys(“item/”)); } }
启动程序后,输出了如下日志,数据全部填充完毕:
[14:22:47.195] [main] [INFO ] [o.g.t.c.n.r.CommonMistakesApplication:80 ] - init redis finished with count 100000 [14:22:50.030] [main] [INFO ] [o.g.t.c.n.r.CommonMistakesApplication:74 ] - init mysql finished with count 100000
然后,比较一下从 MySQL 和 Redis 随机读取单条数据的性能。“公平”起见,像 Redis 那样,我们使用 MySQL 时也根据 Key 来查 Value,也就是根据 name 字段来查 data 字段,并且我们给 name 字段做了索引:
@Autowired private JdbcTemplate jdbcTemplate; @Autowired private StringRedisTemplate stringRedisTemplate; @GetMapping(“redis”) public void redis() { //使用随机的Key来查询Value,结果应该等于PAYLOAD Assert.assertTrue(stringRedisTemplate.opsForValue().get(“item” + (ThreadLocalRandom.current().nextInt(CommonMistakesApplication.ROWS) + 1)).equals(CommonMistakesApplication.PAYLOAD)); } @GetMapping(“mysql”) public void mysql() { //根据随机name来查data,name字段有索引,结果应该等于PAYLOAD Assert.assertTrue(jdbcTemplate.queryForObject(“SELECT data FROM r WHERE name=?”, new Object[]{(“item” + (ThreadLocalRandom.current().nextInt(CommonMistakesApplication.ROWS) + 1))}, String.class) .equals(CommonMistakesApplication.PAYLOAD)); }
在我的电脑上,使用 wrk 加 10 个线程 50 个并发连接做压测。可以看到,MySQL 90% 的请求需要 61ms,QPS 为 1460;而 Redis 90% 的请求在 5ms 左右,QPS 达到了 14008,几乎是 MySQL 的十倍:
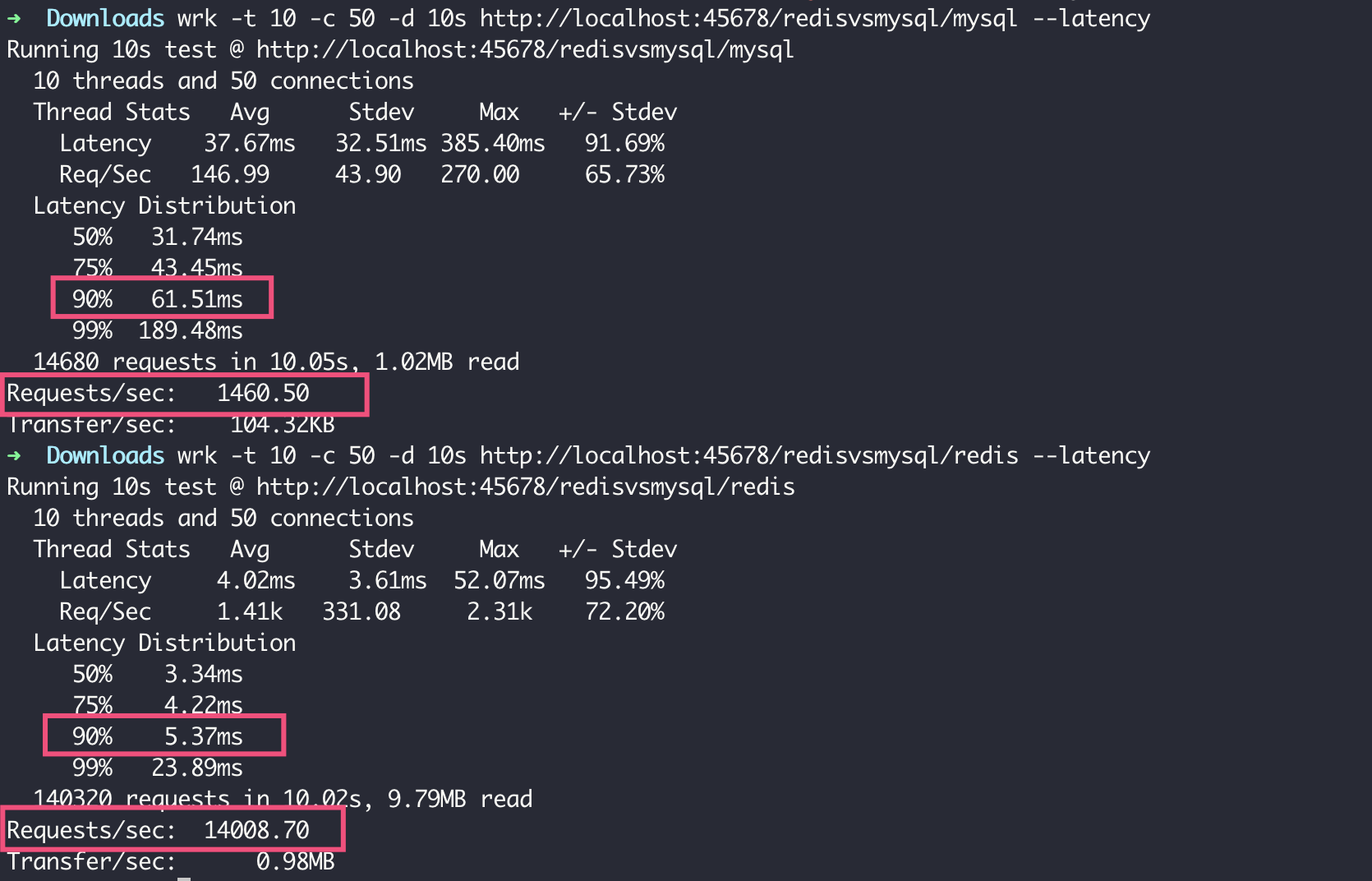
但 Redis 薄弱的地方是,不擅长做 Key 的搜索。对 MySQL,我们可以使用 LIKE 操作前匹配走 B+ 树索引实现快速搜索;但对 Redis,我们使用 Keys 命令对 Key 的搜索,其实相当于在 MySQL 里做全表扫描。
我写一段代码来对比一下性能:
@GetMapping(“redis2”) public void redis2() { Assert.assertTrue(stringRedisTemplate.keys(“item71/*”).size() == 1111); } @GetMapping(“mysql2”) public void mysql2() { Assert.assertTrue(jdbcTemplate.queryForList(“SELECT name FROM r WHERE name LIKE ‘item71%’”, String.class).size() == 1111); }
可以看到,在 QPS 方面,MySQL 的 QPS 达到了 Redis 的 157 倍;在延迟方面,MySQL 的延迟只有 Redis 的十分之一。
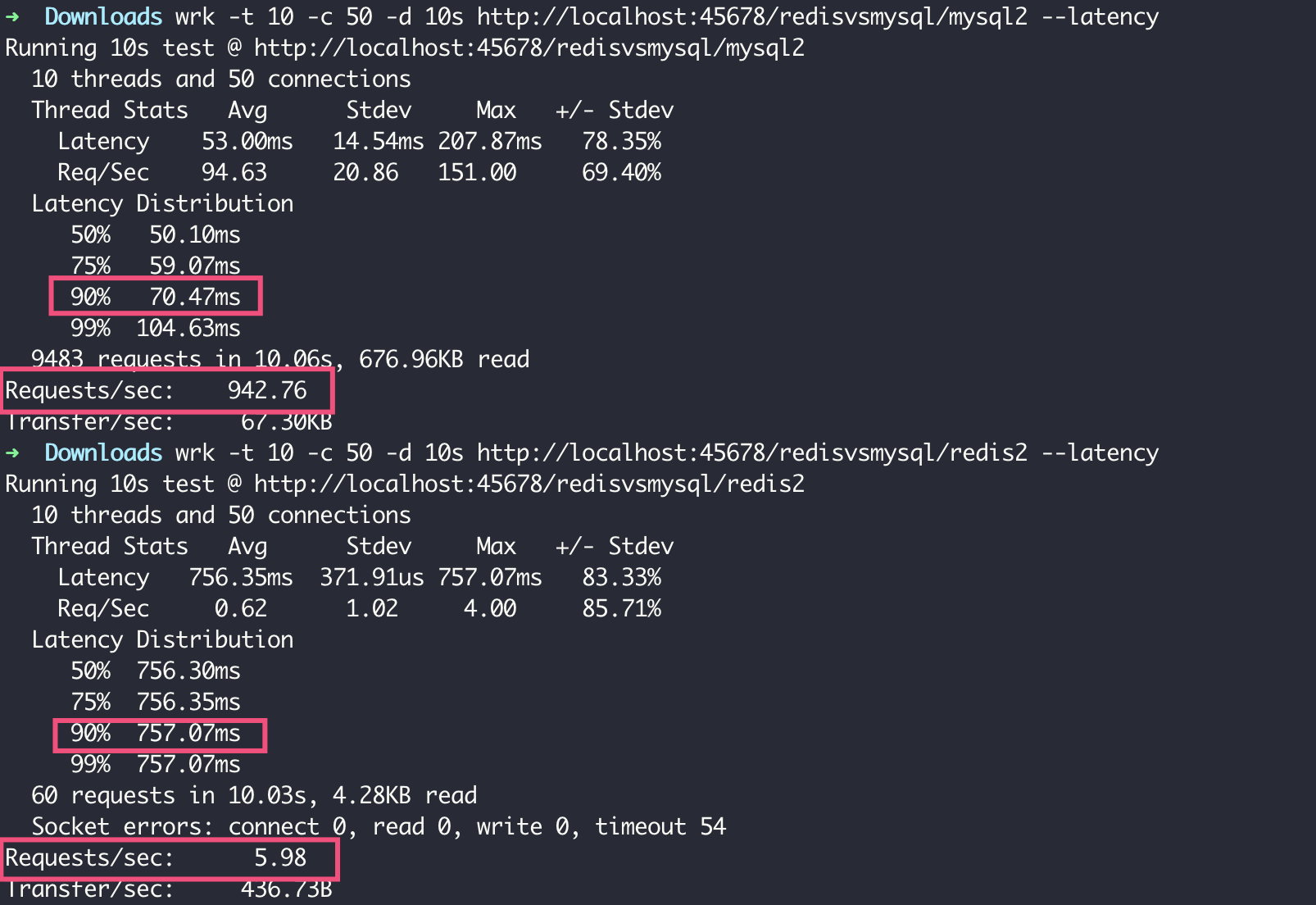
Redis 慢的原因有两个:
Redis 的 Keys 命令是 O(n) 时间复杂度。如果数据库中 Key 的数量很多,就会非常慢。
Redis 是单线程的,对于慢的命令如果有并发,串行执行就会非常耗时。
一般而言,我们使用 Redis 都是针对某一个 Key 来使用,而不能在业务代码中使用 Keys 命令从 Redis 中“搜索数据”,因为这不是 Redis 的擅长。对于 Key 的搜索,我们可以先通过关系型数据库进行,然后再从 Redis 存取数据(如果实在需要搜索 Key 可以使用 SCAN 命令)。在生产环境中,我们一般也会配置 Redis 禁用类似 Keys 这种比较危险的命令,你可以参考这里。
总结一下,正如“缓存设计”一讲中提到的,对于业务开发来说,大多数业务场景下 Redis 是作为关系型数据库的辅助用于缓存的,我们一般不会把它当作数据库独立使用。
此外值得一提的是,Redis 提供了丰富的数据结构(Set、SortedSet、Hash、List),并围绕这些数据结构提供了丰富的 API。如果我们好好利用这个特点的话,可以直接在 Redis 中完成一部分服务端计算,避免“读取缓存 -> 计算数据 -> 保存缓存”三部曲中的读取和保存缓存的开销,进一步提高性能。
取长补短之 InfluxDB vs MySQL
InfluxDB 是一款优秀的时序数据库。在“生产就绪”这一讲中,我们就是使用 InfluxDB 来做的 Metrics 打点。时序数据库的优势,在于处理指标数据的聚合,并且读写效率非常高。
同样的,我们使用一些测试来对比下 InfluxDB 和 MySQL 的性能。
在如下代码中,我们分别填充了 1000 万条数据到 MySQL 和 InfluxDB 中。其中,每条数据只有 ID、时间戳、10000 以内的随机值这 3 列信息,对于 MySQL 我们把时间戳列做了索引:
@SpringBootApplication @Slf4j public class CommonMistakesApplication { public static void main(String[] args) { SpringApplication.run(CommonMistakesApplication.class, args); } //测试数据量 public static final int ROWS = 10000000; @Autowired private JdbcTemplate jdbcTemplate; @Autowired private StandardEnvironment standardEnvironment; @PostConstruct public void init() { //使用-Dspring.profiles.active=init启动程序进行初始化 if (Arrays.stream(standardEnvironment.getActiveProfiles()).anyMatch(s -> s.equalsIgnoreCase(“init”))) { initInfluxDB(); initMySQL(); } } //初始化MySQL private void initMySQL() { long begin = System.currentTimeMillis(); jdbcTemplate.execute(“DROP TABLE IF EXISTS m;”); //只有ID、值和时间戳三列 jdbcTemplate.execute(“CREATE TABLE m (\n” + “ id bigint(20) NOT NULL AUTO_INCREMENT,\n” + “ value bigint NOT NULL,\n” + “ time timestamp NOT NULL,\n” + “ PRIMARY KEY (id),\n” + “ KEY time (time) USING BTREE\n” + “) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;”); String sql = “INSERT INTO m (value,time) VALUES (?,?)”; //批量插入数据 jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() { @Override public void setValues(PreparedStatement preparedStatement, int i) throws SQLException { preparedStatement.setLong(1, ThreadLocalRandom.current().nextInt(10000)); preparedStatement.setTimestamp(2, Timestamp.valueOf(LocalDateTime.now().minusSeconds(5 /* i))); } @Override public int getBatchSize() { return ROWS; } }); log.info(“init mysql finished with count {} took {}ms”, jdbcTemplate.queryForObject(“SELECT COUNT(/) FROM m”, Long.class), System.currentTimeMillis()-begin); } //初始化InfluxDB private void initInfluxDB() { long begin = System.currentTimeMillis(); OkHttpClient.Builder okHttpClientBuilder = new OkHttpClient().newBuilder() .connectTimeout(1, TimeUnit.SECONDS) .readTimeout(10, TimeUnit.SECONDS) .writeTimeout(10, TimeUnit.SECONDS); try (InfluxDB influxDB = InfluxDBFactory.connect(“http://127.0.0.1:8086”, “root”, “root”, okHttpClientBuilder)) { String db = “performance”; influxDB.query(new Query(“DROP DATABASE “ + db)); influxDB.query(new Query(“CREATE DATABASE “ + db)); //设置数据库 influxDB.setDatabase(db); //批量插入,10000条数据刷一次,或1秒刷一次 influxDB.enableBatch(BatchOptions.DEFAULTS.actions(10000).flushDuration(1000)); IntStream.rangeClosed(1, ROWS).mapToObj(i -> Point .measurement(“m”) .addField(“value”, ThreadLocalRandom.current().nextInt(10000)) .time(LocalDateTime.now().minusSeconds(5 / i).toInstant(ZoneOffset.UTC).toEpochMilli(), TimeUnit.MILLISECONDS).build()) .forEach(influxDB::write); influxDB.flush(); log.info(“init influxdb finished with count {} took {}ms”, influxDB.query(new Query(“SELECT COUNT(/*) FROM m”)).getResults().get(0).getSeries().get(0).getValues().get(0).get(1), System.currentTimeMillis()-begin); } } }
启动后,程序输出了如下日志:
[16:08:25.062] [main] [INFO ] [o.g.t.c.n.i.CommonMistakesApplication:104 ] - init influxdb finished with count 1.0E7 took 54280ms [16:11:50.462] [main] [INFO ] [o.g.t.c.n.i.CommonMistakesApplication:80 ] - init mysql finished with count 10000000 took 205394ms
InfluxDB 批量插入 1000 万条数据仅用了 54 秒,相当于每秒插入 18 万条数据,速度相当快;MySQL 的批量插入,速度也挺快达到了每秒 4.8 万。
接下来,我们测试一下。
对这 1000 万数据进行一个统计,查询最近 60 天的数据,按照 1 小时的时间粒度聚合,统计 value 列的最大值、最小值和平均值,并将统计结果绘制成曲线图: @Autowired private JdbcTemplate jdbcTemplate; @GetMapping(“mysql”) public void mysql() { long begin = System.currentTimeMillis(); //使用SQL从MySQL查询,按照小时分组 Object result = jdbcTemplate.queryForList(“SELECT date_format(time,’%Y%m%d%H’),max(value),min(value),avg(value) FROM m WHERE time>now()- INTERVAL 60 DAY GROUP BY date_format(time,’%Y%m%d%H’)”); log.info(“took {} ms result {}”, System.currentTimeMillis() - begin, result); } @GetMapping(“influxdb”) public void influxdb() { long begin = System.currentTimeMillis(); try (InfluxDB influxDB = InfluxDBFactory.connect(“http://127.0.0.1:8086”, “root”, “root”)) { //切换数据库 influxDB.setDatabase(“performance”); //InfluxDB的查询语法InfluxQL类似SQL Object result = influxDB.query(new Query(“SELECT MEAN(value),MIN(value),MAX(value) FROM m WHERE time > now() - 60d GROUP BY TIME(1h)”)); log.info(“took {} ms result {}”, System.currentTimeMillis() - begin, result); } }
因为数据量非常大,单次查询就已经很慢了,所以这次我们不进行压测。分别调用两个接口,可以看到 MySQL 查询一次耗时 29 秒左右,而 InfluxDB 耗时 980ms:
[16:19:26.562] [http-nio-45678-exec-1] [INFO ] [o.g.t.c.n.i.PerformanceController:31 ] - took 28919 ms result [{date_format(time,’%Y%m%d%H’)=2019121308, max(value)=9993, min(value)=4, avg(value)=5129.5639}, {date_format(time,’%Y%m%d%H’)=2019121309, max(value)=9990, min(value)=12, avg(value)=4856.0556}, {date_format(time,’%Y%m%d%H’)=2019121310, max(value)=9998, min(value)=8, avg(value)=4948.9347}, {date_format(time,’%Y%m%d%H’)… [16:20:08.170] [http-nio-45678-exec-6] [INFO ] [o.g.t.c.n.i.PerformanceController:40 ] - took 981 ms result QueryResult [results=[Result [series=[Series [name=m, tags=null, columns=[time, mean, min, max], values=[[2019-12-13T08:00:00Z, 5249.2468619246865, 21.0, 9992.0],…
在按照时间区间聚合的案例上,我们看到了 InfluxDB 的性能优势。但,我们肯定不能把 InfluxDB 当作普通数据库,原因是:
InfluxDB 不支持数据更新操作,毕竟时间数据只能随着时间产生新数据,肯定无法对过去的数据做修改;
从数据结构上说,时间序列数据数据没有单一的主键标识,必须包含时间戳,数据只能和时间戳进行关联,不适合普通业务数据。
此外需要注意,即便只是使用 InfluxDB 保存和时间相关的指标数据,我们也要注意不能滥用 tag。
InfluxDB 提供的 tag 功能,可以为每一个指标设置多个标签,并且 tag 有索引,可以对 tag 进行条件搜索或分组。但是,tag 只能保存有限的、可枚举的标签,不能保存 URL 等信息,否则可能会出现high series cardinality 问题,导致占用大量内存,甚至是 OOM。你可以点击这里,查看 series 和内存占用的关系。对于 InfluxDB,我们无法把 URL 这种原始数据保存到数据库中,只能把数据进行归类,形成有限的 tag 进行保存。
总结一下,对于 MySQL 而言,针对大量的数据使用全表扫描的方式来聚合统计指标数据,性能非常差,一般只能作为临时方案来使用。此时,引入 InfluxDB 之类的时间序列数据库,就很有必要了。时间序列数据库可以作为特定场景(比如监控、统计)的主存储,也可以和关系型数据库搭配使用,作为一个辅助数据源,保存业务系统的指标数据。
取长补短之 Elasticsearch vs MySQL
Elasticsearch(以下简称 ES),是目前非常流行的分布式搜索和分析数据库,独特的倒排索引结构尤其适合进行全文搜索。
简单来讲,倒排索引可以认为是一个 Map,其 Key 是分词之后的关键字,Value 是文档 ID/ 片段 ID 的列表。我们只要输入需要搜索的单词,就可以直接在这个 Map 中得到所有包含这个单词的文档 ID/ 片段 ID 列表,然后再根据其中的文档 ID/ 片段 ID 查询出实际的文档内容。
我们来测试一下,对比下使用 ES 进行关键字全文搜索、在 MySQL 中使用 LIKE 进行搜索的效率差距。
首先,定义一个实体 News,包含新闻分类、标题、内容等字段。这个实体同时会用作 Spring Data JPA 和 Spring Data Elasticsearch 的实体: @Entity @Document(indexName = “news”, replicas = 0) //@Document注解定义了这是一个ES的索引,索引名称news,数据不需要冗余 @Table(name = “news”, indexes = {@Index(columnList = “cateid”)}) //@Table注解定义了这是一个MySQL表,表名news,对cateid列做索引 @Data @AllArgsConstructor @NoArgsConstructor @DynamicUpdate public class News { @Id private long id; @Field(type = FieldType.Keyword) private String category;//新闻分类名称 private int cateid;//新闻分类ID @Column(columnDefinition = “varchar(500)”)//@Column注解定义了在MySQL中字段,比如这里定义title列的类型是varchar(500) @Field(type = FieldType.Text, analyzer = “ik_max_word”, searchAnalyzer = “ik_smart”)//@Field注解定义了ES字段的格式,使用ik分词器进行分词 private String title;//新闻标题 @Column(columnDefinition = “text”) @Field(type = FieldType.Text, analyzer = “ik_max_word”, searchAnalyzer = “ik_smart”) private String content;//新闻内容 }
接下来,我们实现主程序。在启动时,我们会从一个 csv 文件中加载 4000 条新闻数据,然后复制 100 份,拼成 40 万条数据,分别写入 MySQL 和 ES:
@SpringBootApplication @Slf4j @EnableElasticsearchRepositories(includeFilters = @ComponentScan.Filter(type = FilterType.ASSIGNABLE_TYPE, value = NewsESRepository.class)) //明确设置哪个是ES的Repository @EnableJpaRepositories(excludeFilters = @ComponentScan.Filter(type = FilterType.ASSIGNABLE_TYPE, value = NewsESRepository.class)) //其他的是MySQL的Repository public class CommonMistakesApplication { public static void main(String[] args) { Utils.loadPropertySource(CommonMistakesApplication.class, “es.properties”); SpringApplication.run(CommonMistakesApplication.class, args); } @Autowired private StandardEnvironment standardEnvironment; @Autowired private NewsESRepository newsESRepository; @Autowired private NewsMySQLRepository newsMySQLRepository; @PostConstruct public void init() { //使用-Dspring.profiles.active=init启动程序进行初始化 if (Arrays.stream(standardEnvironment.getActiveProfiles()).anyMatch(s -> s.equalsIgnoreCase(“init”))) { //csv中的原始数据只有4000条 List
由于我们使用了 Spring Data,直接定义两个 Repository,然后直接定义查询方法,无需实现任何逻辑即可实现查询,Spring Data 会根据方法名生成相应的 SQL 语句和 ES 查询 DSL,其中 ES 的翻译逻辑详见这里。
在这里,我们定义一个 countByCateidAndContentContainingAndContentContaining 方法,代表查询条件是:搜索分类等于 cateid 参数,且内容同时包含关键字 keyword1 和 keyword2,计算符合条件的新闻总数量: @Repository public interface NewsMySQLRepository extends JpaRepository<News, Long> { //JPA:搜索分类等于cateid参数,且内容同时包含关键字keyword1和keyword2,计算符合条件的新闻总数量 long countByCateidAndContentContainingAndContentContaining(int cateid, String keyword1, String keyword2); } @Repository public interface NewsESRepository extends ElasticsearchRepository<News, Long> { //ES:搜索分类等于cateid参数,且内容同时包含关键字keyword1和keyword2,计算符合条件的新闻总数量 long countByCateidAndContentContainingAndContentContaining(int cateid, String keyword1, String keyword2); }
对于 ES 和 MySQL,我们使用相同的条件进行搜索,搜素分类是 1,关键字是社会和苹果,然后输出搜索结果和耗时:
//测试MySQL搜索,最后输出耗时和结果 @GetMapping(“mysql”) public void mysql(@RequestParam(value = “cateid”, defaultValue = “1”) int cateid, @RequestParam(value = “keyword1”, defaultValue = “社会”) String keyword1, @RequestParam(value = “keyword2”, defaultValue = “苹果”) String keyword2) { long begin = System.currentTimeMillis(); Object result = newsMySQLRepository.countByCateidAndContentContainingAndContentContaining(cateid, keyword1, keyword2); log.info(“took {} ms result {}”, System.currentTimeMillis() - begin, result); } //测试ES搜索,最后输出耗时和结果 @GetMapping(“es”) public void es(@RequestParam(value = “cateid”, defaultValue = “1”) int cateid, @RequestParam(value = “keyword1”, defaultValue = “社会”) String keyword1, @RequestParam(value = “keyword2”, defaultValue = “苹果”) String keyword2) { long begin = System.currentTimeMillis(); Object result = newsESRepository.countByCateidAndContentContainingAndContentContaining(cateid, keyword1, keyword2); log.info(“took {} ms result {}”, System.currentTimeMillis() - begin, result); }
分别调用接口可以看到,ES 耗时仅仅 48ms,MySQL 耗时 6 秒多是 ES 的 100 倍。很遗憾,虽然新闻分类 ID 已经建了索引,但是这个索引只能起到加速过滤分类 ID 这一单一条件的作用,对于文本内容的全文搜索,B+ 树索引无能为力。
[22:04:00.951] [http-nio-45678-exec-6] [INFO ] [o.g.t.c.n.esvsmyql.PerformanceController:48 ] - took 48 ms result 2100 Hibernate: select count(news0.id) as col_0_0 from news news0_ where news0.cateid=? and (news0.content like ? escape ?) and (news0_.content like ? escape ?) [22:04:11.946] [http-nio-45678-exec-7] [INFO ] [o.g.t.c.n.esvsmyql.PerformanceController:39 ] - took 6637 ms result 2100
但 ES 这种以索引为核心的数据库,也不是万能的,频繁更新就是一个大问题。
MySQL 可以做到仅更新某行数据的某个字段,但 ES 里每次数据字段更新都相当于整个文档索引重建。即便 ES 提供了文档部分更新的功能,但本质上只是节省了提交文档的网络流量,以及减少了更新冲突,其内部实现还是文档删除后重新构建索引。因此,如果要在 ES 中保存一个类似计数器的值,要实现不断更新,其执行效率会非常低。
我们来验证下,分别使用 JdbcTemplate+SQL 语句、ElasticsearchTemplate+ 自定义 UpdateQuery,实现部分更新 MySQL 表和 ES 索引的一个字段,每个方法都是循环更新 1000 次:
@GetMapping(“mysql2”) public void mysql2(@RequestParam(value = “id”, defaultValue = “400000”) long id) { long begin = System.currentTimeMillis(); //对于MySQL,使用JdbcTemplate+SQL语句,实现直接更新某个category字段,更新1000次 IntStream.rangeClosed(1, 1000).forEach(i -> { jdbcTemplate.update(“UPDATE news SET category=? WHERE id=?”, new Object[]{“test” + i, id}); }); log.info(“mysql took {} ms result {}”, System.currentTimeMillis() - begin, newsMySQLRepository.findById(id)); } @GetMapping(“es2”) public void es(@RequestParam(value = “id”, defaultValue = “400000”) long id) { long begin = System.currentTimeMillis(); IntStream.rangeClosed(1, 1000).forEach(i -> { //对于ES,通过ElasticsearchTemplate+自定义UpdateQuery,实现文档的部分更新 UpdateQuery updateQuery = null; try { updateQuery = new UpdateQueryBuilder() .withIndexName(“news”) .withId(String.valueOf(id)) .withType(“_doc”) .withUpdateRequest(new UpdateRequest().doc( jsonBuilder() .startObject() .field(“category”, “test” + i) .endObject())) .build(); } catch (IOException e) { e.printStackTrace(); } elasticsearchTemplate.update(updateQuery); }); log.info(“es took {} ms result {}”, System.currentTimeMillis() - begin, newsESRepository.findById(id).get()); }
可以看到,MySQL 耗时仅仅 1.5 秒,而 ES 耗时 6.8 秒:

ES 是一个分布式的全文搜索数据库,所以与 MySQL 相比的优势在于文本搜索,而且因为其分布式的特性,可以使用一个大 ES 集群处理大规模数据的内容搜索。但,由于 ES 的索引是文档维度的,所以不适用于频繁更新的 OLTP 业务。
一般而言,我们会把 ES 和 MySQL 结合使用,MySQL 直接承担业务系统的增删改操作,而 ES 作为辅助数据库,直接扁平化保存一份业务数据,用于复杂查询、全文搜索和统计。接下来,我也会继续和你分析这一点。
结合 NoSQL 和 MySQL 应对高并发的复合数据库架构
现在,我们通过一些案例看到了 Redis、InfluxDB、ES 这些 NoSQL 数据库,都有擅长和不擅长的场景。那么,有没有全能的数据库呢?
我认为没有。每一个存储系统都有其独特的数据结构,数据结构的设计就决定了其擅长和不擅长的场景。
比如,MySQL InnoDB 引擎的 B+ 树对排序和范围查询友好,频繁数据更新的代价不是太大,因此适合 OLTP(On-Line Transaction Processing)。
又比如,ES 的 Lucene 采用了 FST(Finite State Transducer)索引 + 倒排索引,空间效率高,适合对变动不频繁的数据做索引,实现全文搜索。存储系统本身不可能对一份数据使用多种数据结构保存,因此不可能适用于所有场景。
虽然在大多数业务场景下,MySQL 的性能都不算太差,但对于数据量大、访问量大、业务复杂的互联网应用来说,MySQL 因为实现了 ACID(原子性、一致性、隔离性、持久性)会比较重,而且横向扩展能力较差、功能单一,无法扛下所有数据量和流量,无法应对所有功能需求。因此,我们需要通过架构手段,来组合使用多种存储系统,取长补短,实现 1+1>2 的效果。
我来举个例子。我们设计了一个包含多个数据库系统的、能应对各种高并发场景的一套数据服务的系统架构,其中包含了同步写服务、异步写服务和查询服务三部分,分别实现主数据库写入、辅助数据库写入和查询路由。
我们按照服务来依次分析下这个架构。
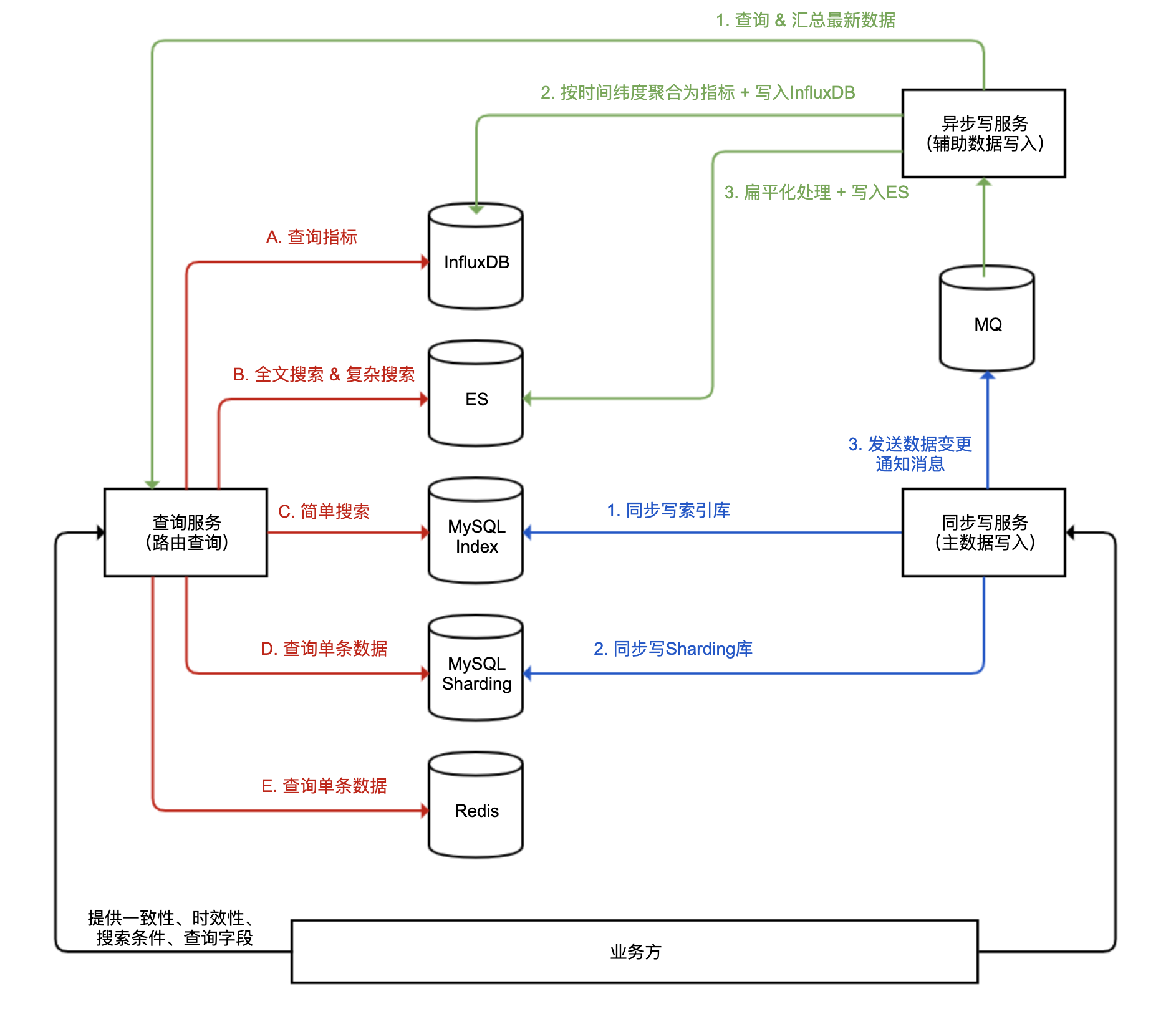
首先要明确的是,重要的业务主数据只能保存在 MySQL 这样的关系型数据库中,原因有三点:
RDBMS 经过了几十年的验证,已经非常成熟;
RDBMS 的用户数量众多,Bug 修复快、版本稳定、可靠性很高;
RDBMS 强调 ACID,能确保数据完整。
有两种类型的查询任务可以交给 MySQL 来做,性能会比较好,这也是 MySQL 擅长的地方:
按照主键 ID 的查询。直接查询聚簇索引,其性能会很高。但是单表数据量超过亿级后,性能也会衰退,而且单个数据库无法承受超大的查询并发,因此我们可以把数据表进行 Sharding 操作,均匀拆分到多个数据库实例中保存。我们把这套数据库集群称作 Sharding 集群。
按照各种条件进行范围查询,查出主键 ID。对二级索引进行查询得到主键,只需要查询一棵 B+ 树,效率同样很高。但索引的值不宜过大,比如对 varchar(1000) 进行索引不太合适,而索引外键(一般是 int 或 bigint 类型)性能就会比较好。因此,我们可以在 MySQL 中建立一张“索引表”,除了保存主键外,主要是保存各种关联表的外键,以及尽可能少的 varchar 类型的字段。这张索引表的大部分列都可以建上二级索引,用于进行简单搜索,搜索的结果是主键的列表,而不是完整的数据。由于索引表字段轻量并且数量不多(一般控制在 10 个以内),所以即便索引表没有进行 Sharding 拆分,问题也不会很大。
如图上蓝色线所示,写入两种 MySQL 数据表和发送 MQ 消息的这三步,我们用一个同步写服务完成了。我在“异步处理”中提到,所有异步流程都需要补偿,这里的异步流程同样需要。只不过为了简洁,我在这里省略了补偿流程。
然后,如图中绿色线所示,有一个异步写服务,监听 MQ 的消息,继续完成辅助数据的更新操作。这里我们选用了 ES 和 InfluxDB 这两种辅助数据库,因此整个异步写数据操作有三步:
MQ 消息不一定包含完整的数据,甚至可能只包含一个最新数据的主键 ID,我们需要根据 ID 从查询服务查询到完整的数据。
写入 InfluxDB 的数据一般可以按时间间隔进行简单聚合,定时写入 InfluxDB。因此,这里会进行简单的客户端聚合,然后写入 InfluxDB。
ES 不适合在各索引之间做连接(Join)操作,适合保存扁平化的数据。比如,我们可以把订单下的用户、商户、商品列表等信息,作为内嵌对象嵌入整个订单 JSON,然后把整个扁平化的 JSON 直接存入 ES。
对于数据写入操作,我们认为操作返回的时候同步数据一定是写入成功的,但是由于各种原因,异步数据写入无法确保立即成功,会有一定延迟,比如:
异步消息丢失的情况,需要补偿处理;
写入 ES 的索引操作本身就会比较慢;
写入 InfluxDB 的数据需要客户端定时聚合。
因此,对于查询服务,如图中红色线所示,我们需要根据一定的上下文条件(比如查询一致性要求、时效性要求、搜索的条件、需要返回的数据字段、搜索时间区间等)来把请求路由到合适的数据库,并且做一些聚合处理:
需要根据主键查询单条数据,可以从 MySQL Sharding 集群或 Redis 查询,如果对实时性要求不高也可以从 ES 查询。
按照多个条件搜索订单的场景,可以从 MySQL 索引表查询出主键列表,然后再根据主键从 MySQL Sharding 集群或 Redis 获取数据详情。
各种后台系统需要使用比较复杂的搜索条件,甚至全文搜索来查询订单数据,或是定时分析任务需要一次查询大量数据,这些场景对数据实时性要求都不高,可以到 ES 进行搜索。此外,MySQL 中的数据可以归档,我们可以在 ES 中保留更久的数据,而且查询历史数据一般并发不会很大,可以统一路由到 ES 查询。
监控系统或后台报表系统需要呈现业务监控图表或表格,可以把请求路由到 InfluxDB 查询。
重点回顾
今天,我通过三个案例分别对比了缓存数据库 Redis、时间序列数据库 InfluxDB、搜索数据库 ES 和 MySQL 的性能。我们看到:
Redis 对单条数据的读取性能远远高于 MySQL,但不适合进行范围搜索。
InfluxDB 对于时间序列数据的聚合效率远远高于 MySQL,但因为没有主键,所以不是一个通用数据库。
ES 对关键字的全文搜索能力远远高于 MySQL,但是字段的更新效率较低,不适合保存频繁更新的数据。
最后,我们给出了一个混合使用 MySQL + Redis + InfluxDB + ES 的架构方案,充分发挥了各种数据库的特长,相互配合构成了一个可以应对各种复杂查询,以及高并发读写的存储架构。
主数据由两种 MySQL 数据表构成,其中索引表承担简单条件的搜索来得到主键,Sharding 表承担大并发的主键查询。主数据由同步写服务写入,写入后发出 MQ 消息。
辅助数据可以根据需求选用合适的 NoSQL,由单独一个或多个异步写服务监听 MQ 后异步写入。
由统一的查询服务,对接所有查询需求,根据不同的查询需求路由查询到合适的存储,确保每一个存储系统可以根据场景发挥所长,并分散各数据库系统的查询压力。
今天用到的代码,我都放在了 GitHub 上,你可以点击这个链接查看。
思考与讨论
我们提到,InfluxDB 不能包含太多 tag。你能写一段测试代码,来模拟这个问题,并观察下 InfluxDB 的内存使用情况吗?
文档数据库 MongoDB,也是一种常用的 NoSQL。你觉得 MongoDB 的优势和劣势是什么呢?它适合用在什么场景下呢?
关于数据存储,你还有其他心得吗?我是朱晔,欢迎在评论区与我留言分享你的想法,也欢迎你把今天的内容分享给你的朋友或同事,一起交流。
参考资料
https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/Java%20%e4%b8%9a%e5%8a%a1%e5%bc%80%e5%8f%91%e5%b8%b8%e8%a7%81%e9%94%99%e8%af%af%20100%20%e4%be%8b/26%20%e6%95%b0%e6%8d%ae%e5%ad%98%e5%82%a8%ef%bc%9aNoSQL%e4%b8%8eRDBMS%e5%a6%82%e4%bd%95%e5%8f%96%e9%95%bf%e8%a1%a5%e7%9f%ad%e3%80%81%e7%9b%b8%e8%be%85%e7%9b%b8%e6%88%90%ef%bc%9f.md
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
