26 特殊型:前端有哪些处理加载和渲染的特殊“模式”? 你好,我是石川。
在之前的几讲中,我们介绍完了经典的设计模式,今天我们来看看在JS中特有的一些设计模式。其实从函数式编程开始,我们就一直强调了前端所重视的响应式编程思想,所以我认为这个部分可以分三大块儿来系统地看下响应式编程在JS中的设计模式,分别是组件化、加载渲染和性能优化模式。下面,我们就来深入地了解下。
组件化的模式
首先,我们来看下组件化的设计模式。我想请你先思考这样一个问题:为什么说组件化在前端,特别是基于JS开发的React框架中,有着非常重要的位置呢?
随着Web和WebGL的逐渐普及,我们之前用的很多桌面应用都被网页版的应用替代,一是它可以达到和桌面应用类似的功能,二是这样节省了资源在我们的手机或是PC上的下载和存储,三是因为这样可以让我们随时随地访问我们需要的内容,只要有网络,输入一个URL便可以使用。而且在办公类的软件中它也大大增加了工作的协同,比如我们常用的QQ邮箱、Google Docs或石墨文档都可以看做是由组件组成的复杂的Web应用。
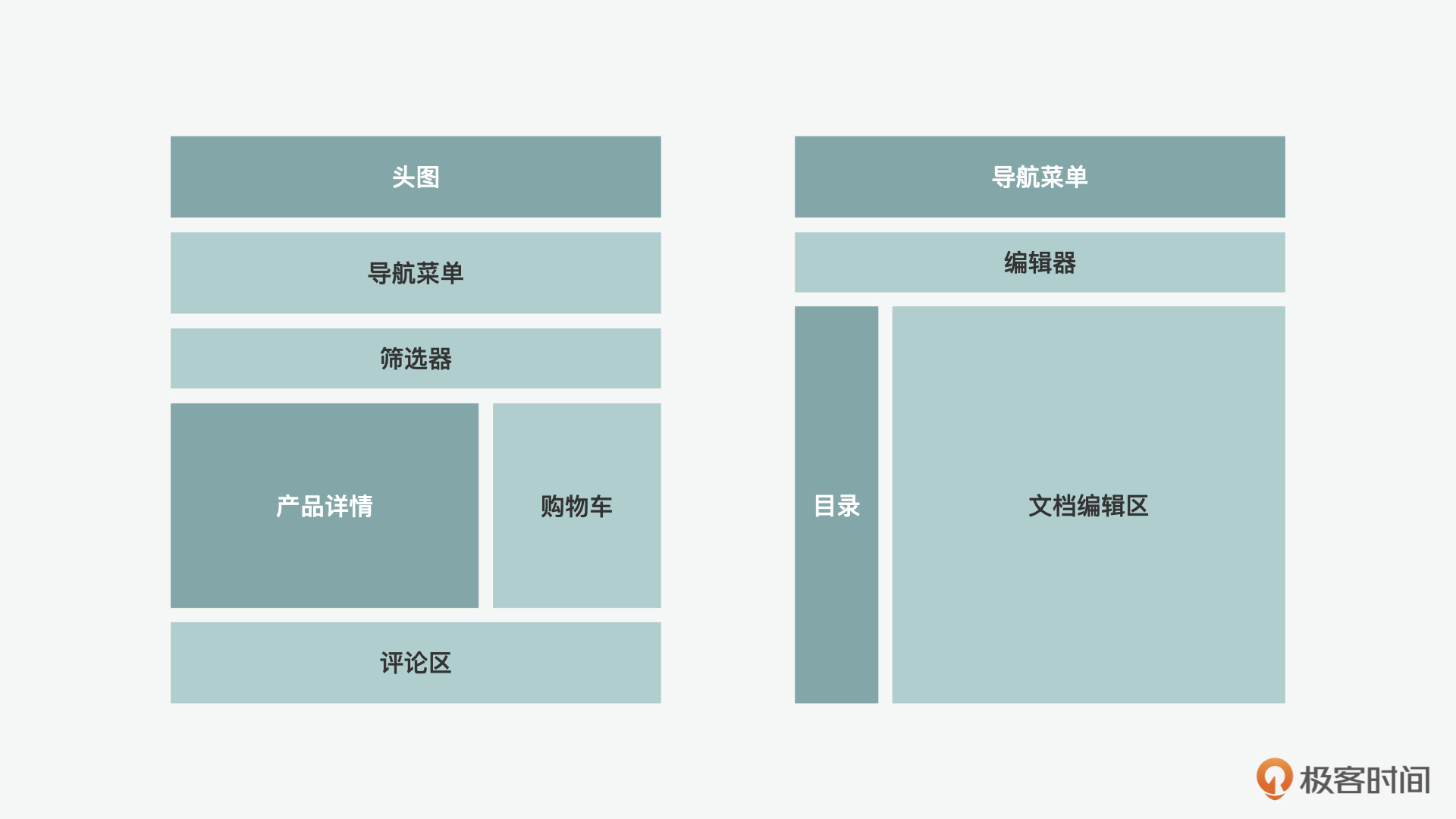
接下来我们就来讲讲几种在React中会用到的组件化的模式。这里我们首先需要注意的是,在React中的组件化和我们通常了解的Web Component是有区别的。我们在说到Web Component的时候,更多关注的是组件的封装和重用,也就是经典的面向对象的设计模式思想。而React Component更多关注的是,通过声明式的方式更好地让DOM和状态数据之间同步。为了更好地实现组件化,React推出了一些不同的模式,这里比较重要的就包含了上下文提供者、渲染属性、高阶组件和后来出现的Hooks。
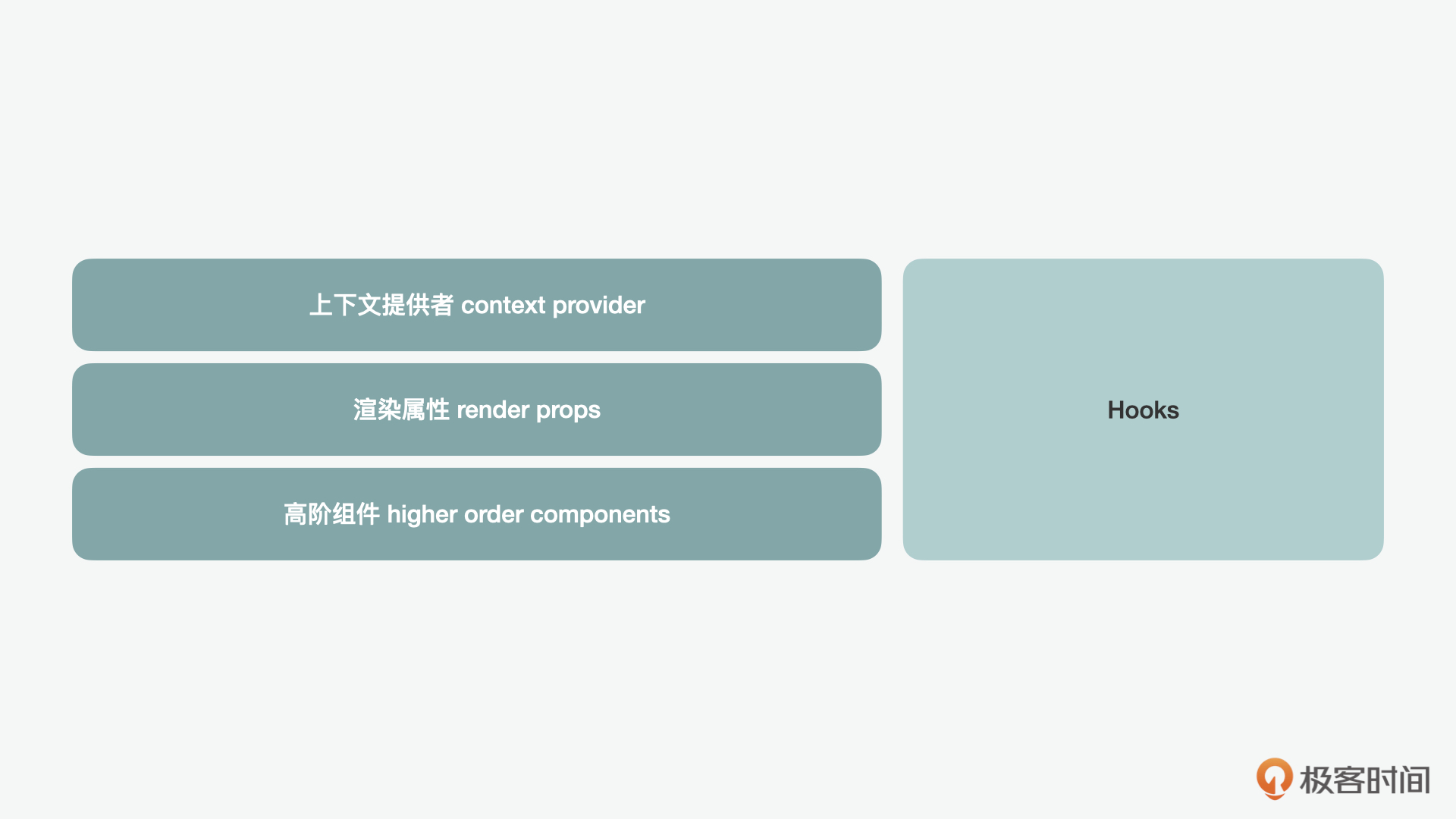
这里,我们可以大体将这些组件化的模式分为两类,一类是在Hooks出现之前的上下文提供者、渲染属性、高阶组件模式,一类是Hooks出现后带来的新模式。下面,就让我们从经典模式依次来看下。
经典模式
首先我们先来看上下文提供者模式(Context Provider Pattern),这是一种通过创建上下文将数据传给多个组件的组件化方式。它的作用是可以避免prop-drilling,也就是避免将数据从父组件逐层下传到子组件的繁琐过程。
那么这种模式有什么实际的应用呢?那就是当我们想根据应用的界面目前所处的上下文来做展示的时候,这种模式就派上用场了。比如我们需要对于登录和未登录态的用户展现不同的内容,或者是当春节或国庆等特殊节日的主题皮肤发放时,又或是根据用户所在的国家或地区做展示调整的时候,都可以用到提供者模式。
举个例子,假如我们有一个菜单,里面包含了一个列表和列表元素。通过以下代码,我们看到如果将数据一层层传递,就会变得非常繁琐。 function App() { const data = { … } return (<Menu data={data} />); } var Menu = ({ data }) => <List data={data} /> var List = ({ data }) => <ListItem data={data} /> var ListItem = ({ data }) => {data.listItem}
而通过React.createContext,我们创建一个主题。之后通过ThemeContext.Provider,我们可以创建一个相关的上下文。这样我们无需将数据一一传递给每个菜单里的元素,便可以让上下文中的元素都可以获取相关的数据。
var ThemeContext = React.createContext(); function App() { var data = {}; return ( <ThemeContext.Provider value = {data}> <Menu /> </ThemeContext.Provider> ) }
通过React.useContext,可以获取元素上下文中的数据来进行读写。
function useThemeContext() { var theme = useContext(ThemeContext); return theme; } function ListItem() { var theme = useThemeContext(); return <li style={theme.theme}>…</li>; }
说完了上下文提供者,下面我们再来看看渲染属性模式(Render Props Pattern)。先思考一个问题,我们为什么需要渲染属性模式呢?
下面我们可以看看,在没有渲染模式的情况下,可能会出现的问题。比如在下面的价格计算器的例子中,我们想让程序根据输入的产品购买数量计算出价格。但是,在没有渲染属性的情况下,我们虽然想通过value /* 188计算根据输入的购买的数量展示计算的价格,但是价格计算拿不到输入的购买数量的value值,所以实际上计算不出价格。
export default function App() { return ( <div className="App"> <h1>价格计算器</h1>
为了解决这个问题,我们就可以用到render props,把amount作为input的子元素,在其中传入value参数。也就是说通过渲染属性,我们可以在不同的组件之间通过属性来共享某些数据或逻辑。
export default function App() { return ( <div className="App"> … {value => ( <> <Amount value={value} /> </> )} </Input> </div> ); } function Input() { … return ( <> <input … /> {props.children(value)} </> ); } function Amount({ value = 0 }) { … }
说完了渲染属性,下面我们再来看看高阶组件模式(HOC,Higher Order Components Pattern),这种叫法听上去像是我们在说到函数式编程时提到的高阶函数。当时我们说过,当我们把一个函数作为参数传入,并且返回一个函数作为结果的函数,叫做高阶函数。那么在高阶组件中,它的概念类似,就是我们可以把一个组件作为参数传入,并且返回一个组件。
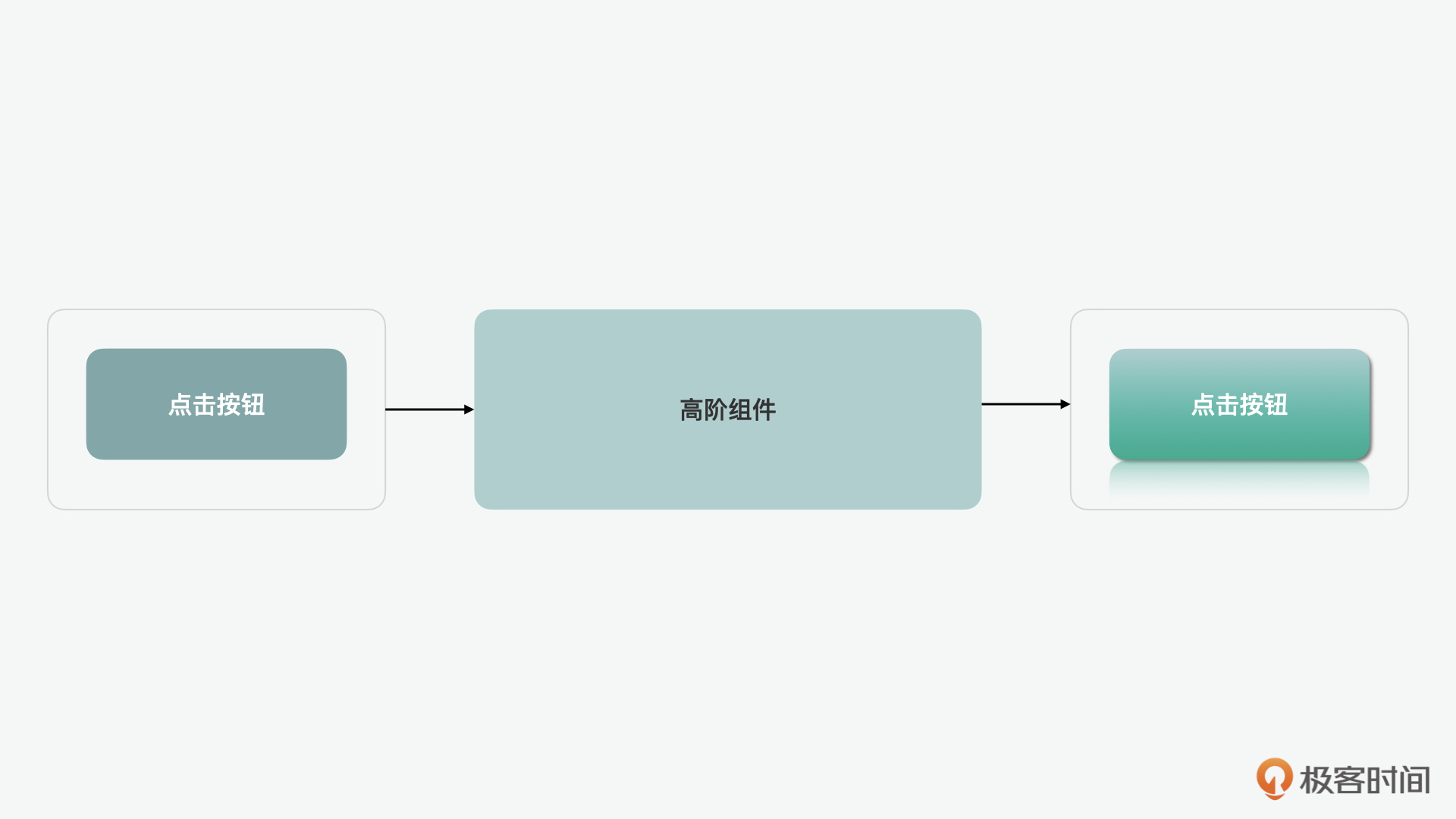
那么它有什么应用呢?假设在没有高阶组件的情况下,我们想给一些按钮或文字组件增加一个圆边,可能要修改组件内的代码,而通过高阶函数,我们可以在原始的直角的文字框和按钮组件的基础上面包装一些方法来得到圆边的效果。在实际的应用中,它可以起到类似于“装饰器”的作用。它不仅让我们不需要对组件本身做修改,而且还可以让我们重复使用抽象出来的功能,避免代码冗余。 // 高阶函数 var enhancedFunction = higherOrderFunction(originalFunction); // 高阶组件 var enhancedComponent = higherOrderComponent(originalComponent); // 高阶组件作为装饰器 var RoundedText = withRoundCorners(Text); var RoundedButton = withRoundCorners(Button);
Hooks模式
前面,我们看完了几种经典的可以帮助我们实现和优化组件化的方式,下面,我们再来看看从React 16.8开始新增的Hooks。
Hooks最直接的作用是可以用函数来代替ES6引入的新的class创建组件。如我们之前在讲到JavaScript中面向对象时所提到的,关于this的绑定理解,对于从其他语言转来的开发者来说还是比较绕脑的。而通过Hooks,可以通过函数表达更直观地创建组件。
我们先来看一个计数器的例子。如果用传统class的方式来创建的话,需要用到
this.state,this.setState 和
this.state.count 来初始化,设置和读取计数状态。 class App extends React.Component { constructor(props) { super(props); this.state = { count: 0 }; } render() { return ( <button onClick={() => this.setState({ count: this.state.count + 1 })}> 点击了{this.state.count}次。 </button> ); } }
而如果用Hooks的话,我们可以通过
useState(0) 来代替
this.state 创建一个初始化设置为0的计数状态。同时,再点击计数按钮的时候,我们可以用
count 和
setCount 分别来代替
this.state.count 和
this.setState 做计数状态的读写。
import React, { useState } from ‘react’; function APP() { var [count, setCount] = useState(0); return ( <div> <button onClick={() => setCount(count + 1)}>点击了{count}次。 </button> </div> ); }
在这个例子中,你可以看到,我们刚才是通过用解构(destructure)的方式,创建了两个计数状态的变量,一个是
count ,另外一个是
setCount 。这样当我们将这两个值赋值给
userState(0) 的时候,它们会分别被赋值为获取计数和更新计数。
// 数组解构 var [count, setCount] = useState(0); // 上等同于 var countStateVariable = useState(0); var count = countStateVariable[0]; var setCount = countStateVariable[1];
除了用函数代替类以外,Hooks另外的一个作用是可以让组件按功能解耦、再按相关性组合的功能。比如在没有Hooks的情况下,我们可能需要通过组件的生命周期来组合功能,我们的一个应用组件会有两个不同的功能,一个是显示购物车商品数量,一个是显示现有的客服状态。如果我们用的是同一个组件的生命周期
componentDidMount 管理,那就会将不相干的功能聚合在了一起,而通过useEffect这样的一个Hook,就可以把不相干的功能拆开,再根据相关性聚合在一起。
class App extends React.Component { constructor(props) { this.state = { count: 0, isAvailable: null }; this.handleChange = this.handleChange.bind(this); } componentDidMount() { document.title = 目前购物车中有${this.state.count}件商品; UserSupport.subscribeToChange(this.props.staff.id, this.handleChange); } } function App(props) { var [count, setCount] = useState(0); useEffect(() => { document.title = 目前购物车中有${count}件商品; }); var [isOnline, setIsOnline] = useState(null); useEffect(() => { function handleChange(status) {setIsOnline(status.isAvailable);} UserSupport.subscribeToChange(props.staff.id, handleChange); }); }
除了上述的两个好处以外,Hooks还可以让逻辑在组件之间更容易共享。我们在上面的例子中看到过,之前如果我们想要让一些行为重用在不同的组件上,可能要通过渲染属性和高阶组件来完成,但这样做的成本是要以改变了组件原有的结构作为代价的,组件外被包裹了大量的提供者、渲染属性和高阶函数等,这种过度的抽象化就造成了包装地狱(wrapper hell)。而有了Hooks之后,它可以通过更原生的方式替代类似的工作。
加载渲染模式
之前我们在讲到响应式设计的时候,有讲过前端渲染(CSR)、后端渲染(SSR)和水合(hydration)的概念。今天,就让我们更系统地了解下加载渲染模式吧。首先,我们先从渲染模式说起。
渲染模式
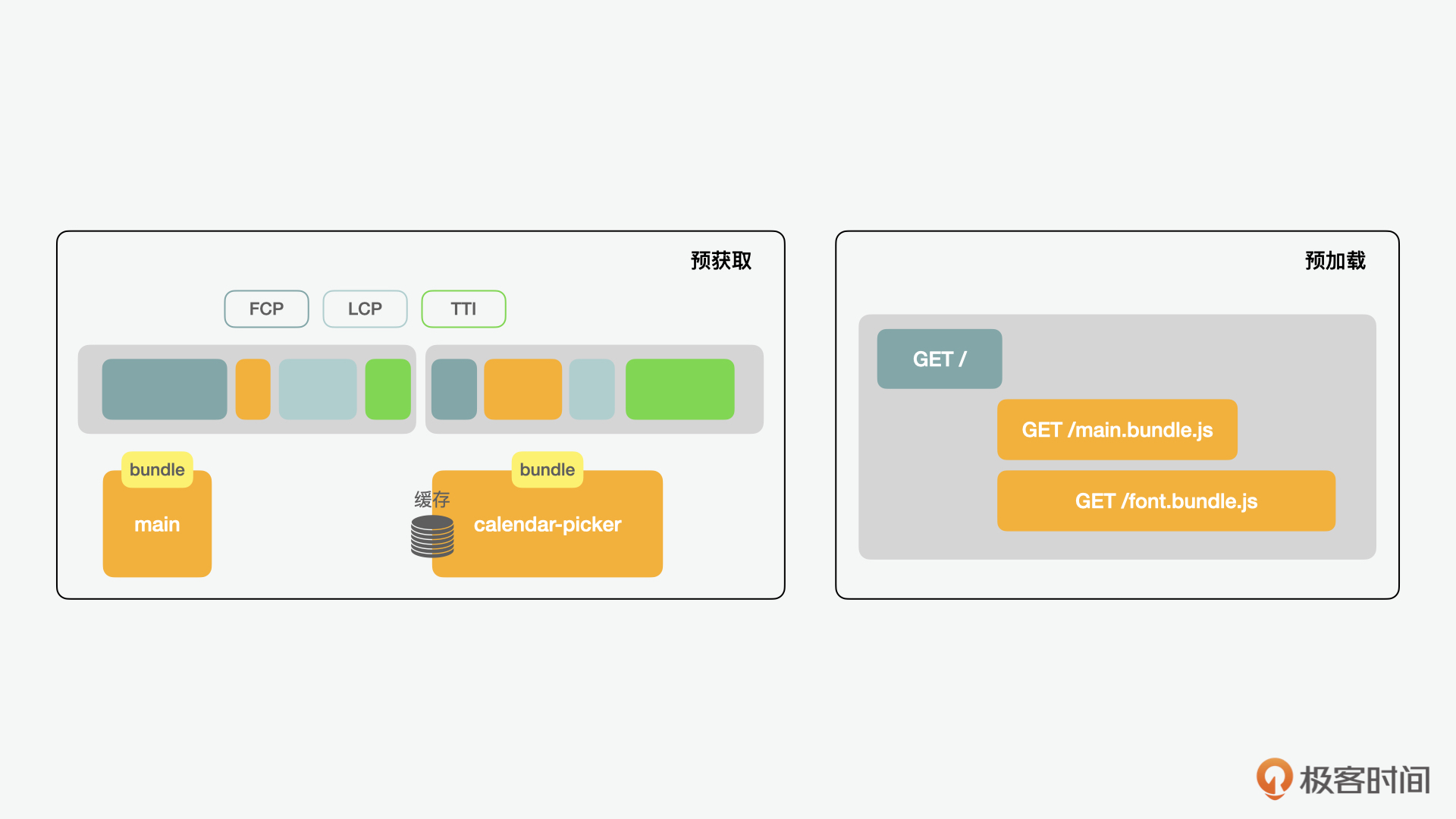
在Web应用刚刚流行的时候,很多的单页应用(SPA)都是通过前端渲染开发的,这样的模式不需要浏览器的刷新就可以让用户在不同的页面间进行切换。这样在带来了方便的同时,也会造成性能上问题,比如它的FCP(First Contentful Paint,首次内容绘制时间)、 LCP(Largest Contentful Paint,最大内容绘制时间)、TTI(Time to Interactive,首次可交互时间) 会比较长,遇到这种情况,通过初始最小化代码、预加载、懒加载、代码切割和缓存等手段,性能上的问题可以得到一些解决。
但是相比后端渲染,前端渲染除了性能上的问题,还会造成SEO的问题。通常为了解决SEO的问题,一些网站会在SPA的基础上再专门生成一套供搜索引擎检索的后端页面。但是作为搜索的入口页面,后端渲染的页面也会被访问到,它最大的问题就是到第一字节的时间(TTFB)会比较长。
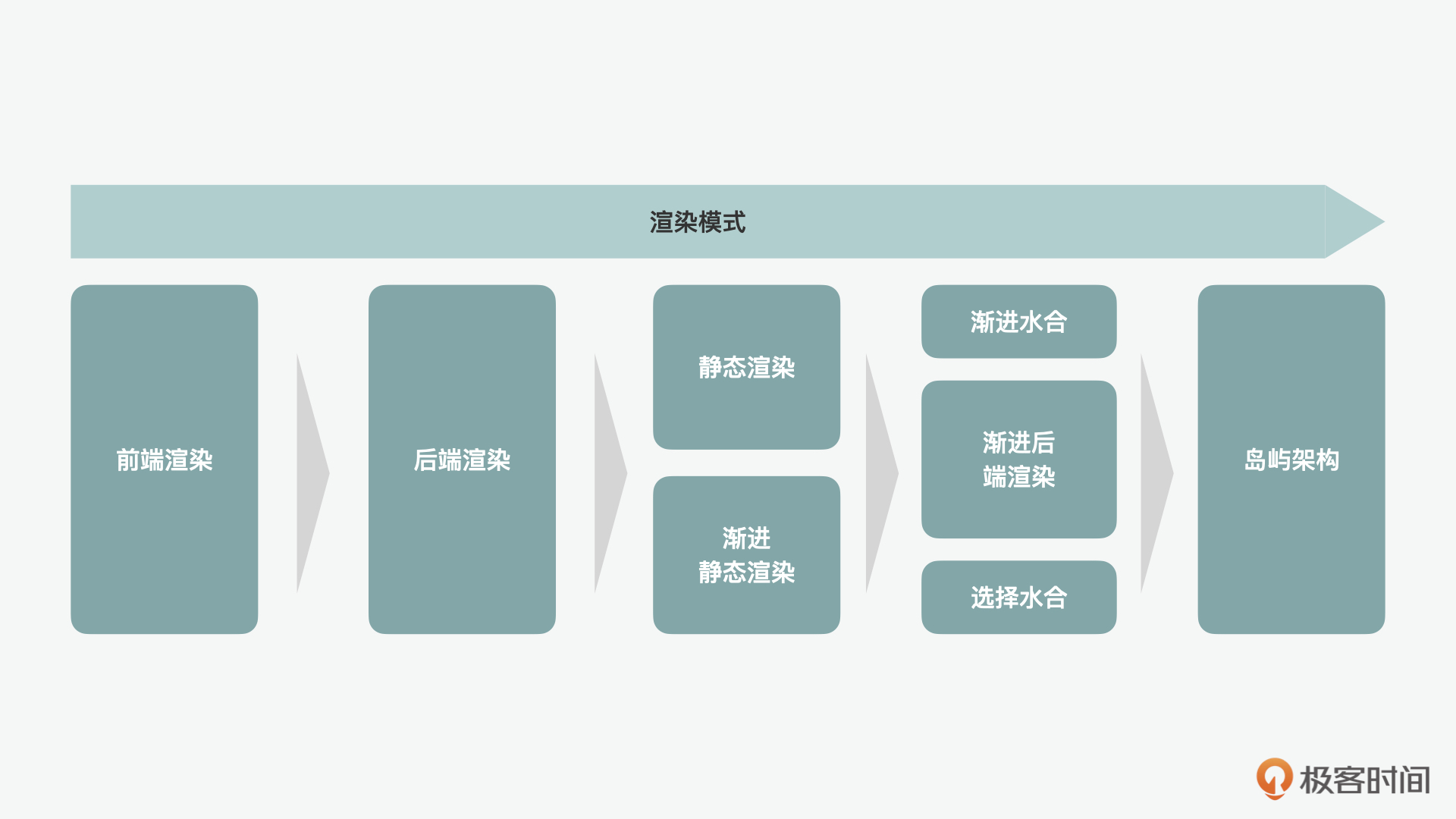
为了解决前端和后端渲染的问题,静态渲染(static rendering)的概念便出现了。静态渲染使用的是一种预渲染(pre-render)的方式。也是说在服务器端预先渲染出可以在CDN上缓存的HTML页面,当前端发起请求的时候,直接将渲染好了的文件发送给后端,通过这种方式,就降低了TTFB。相比静态的页面内容而言,JS的文件通常较小,所以在静态渲染的情况下页面的FCP和TTI也不会太高。
静态渲染一般被称之为静态生成(SSG,static generation),而由此,又引出了静态渐进生成(iSSG,incremental static generation)的概念。我们看到静态生成在处理静态内容,比如“关于我们”的介绍页时是可以的,但是如果内容是动态更新的比如“博客文章”呢?换句话说,就是我们要在面对新页面增加的同时也要支持旧页面的更新,这时渐进静态生成就派上用场了。iSSG可以在SSG的基础上做到对增量页面的生成和存量部分的再生成。
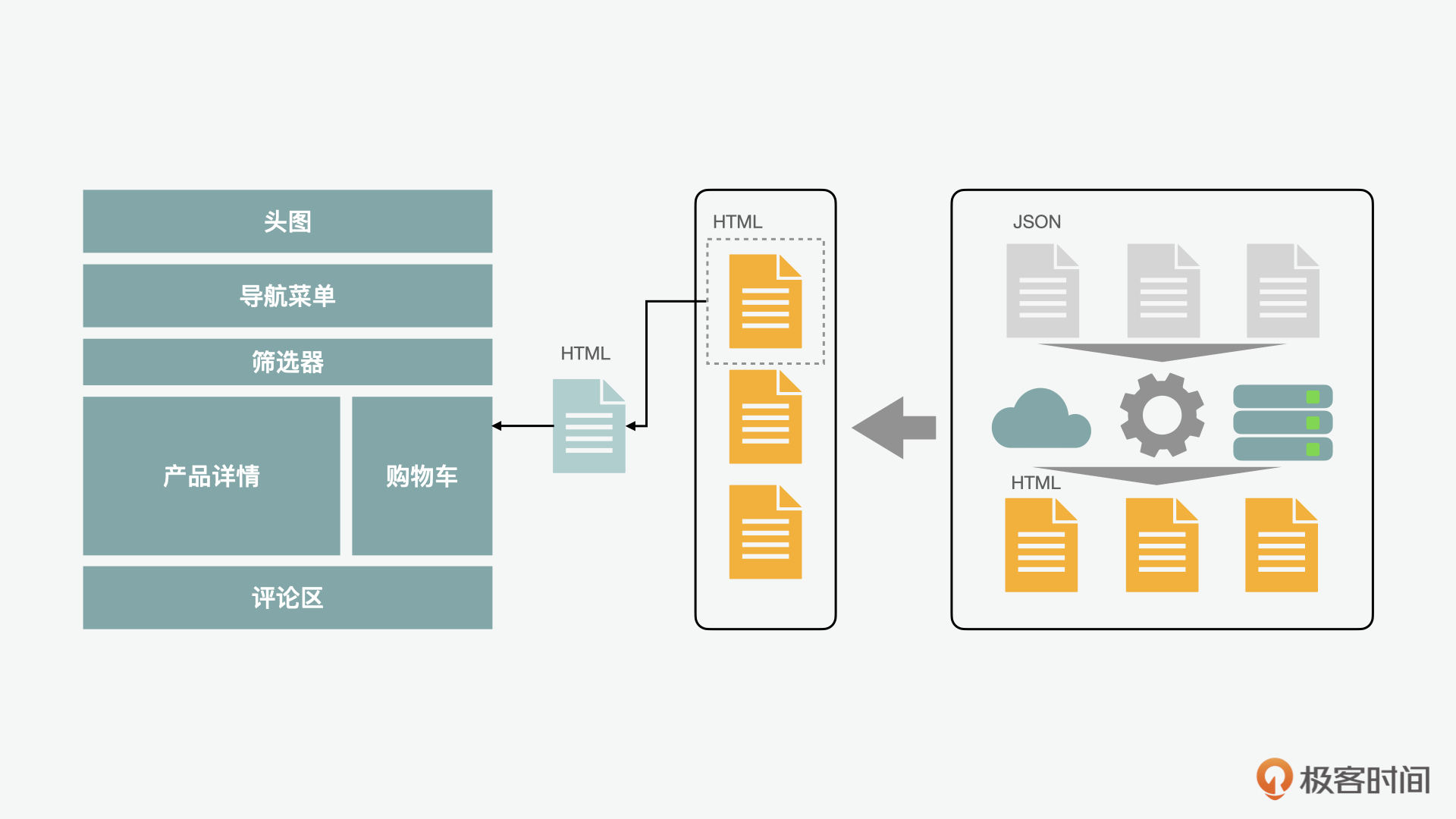
无论是“关于我们”还是“博客文章”之类的页面,它们虽然从内容的角度看,有静态和动态之分,但总体上都是不需要频繁互动的。但是如果静态渲染的内容需要有相关的行为代码支持互动的情况下,SSG就只能保证FCP,但是很难保证TTI了。这种情况就是我们之前讲到的水合(hydration)可以起到作用的时候了,它可以给静态加载的元素赋予动态的行为。而在用户发起交互的时候,再水合的动作就是渐进式水合(progressive hydration)。
同时,除了静态渲染和水合可以渐进外,后端渲染也可以通过node中的流(stream)做到后端渐进渲染(progressive SSR)。通过流,页面的内容可以分段传到前端,前端可以先加载先传入的部分。除了渐进式水合外,选择性水合可以利用node stream暂缓部分的组件传输,而将先传输到前端的部分进行水合,这种方式就叫做选择性水合(selective hydration)。
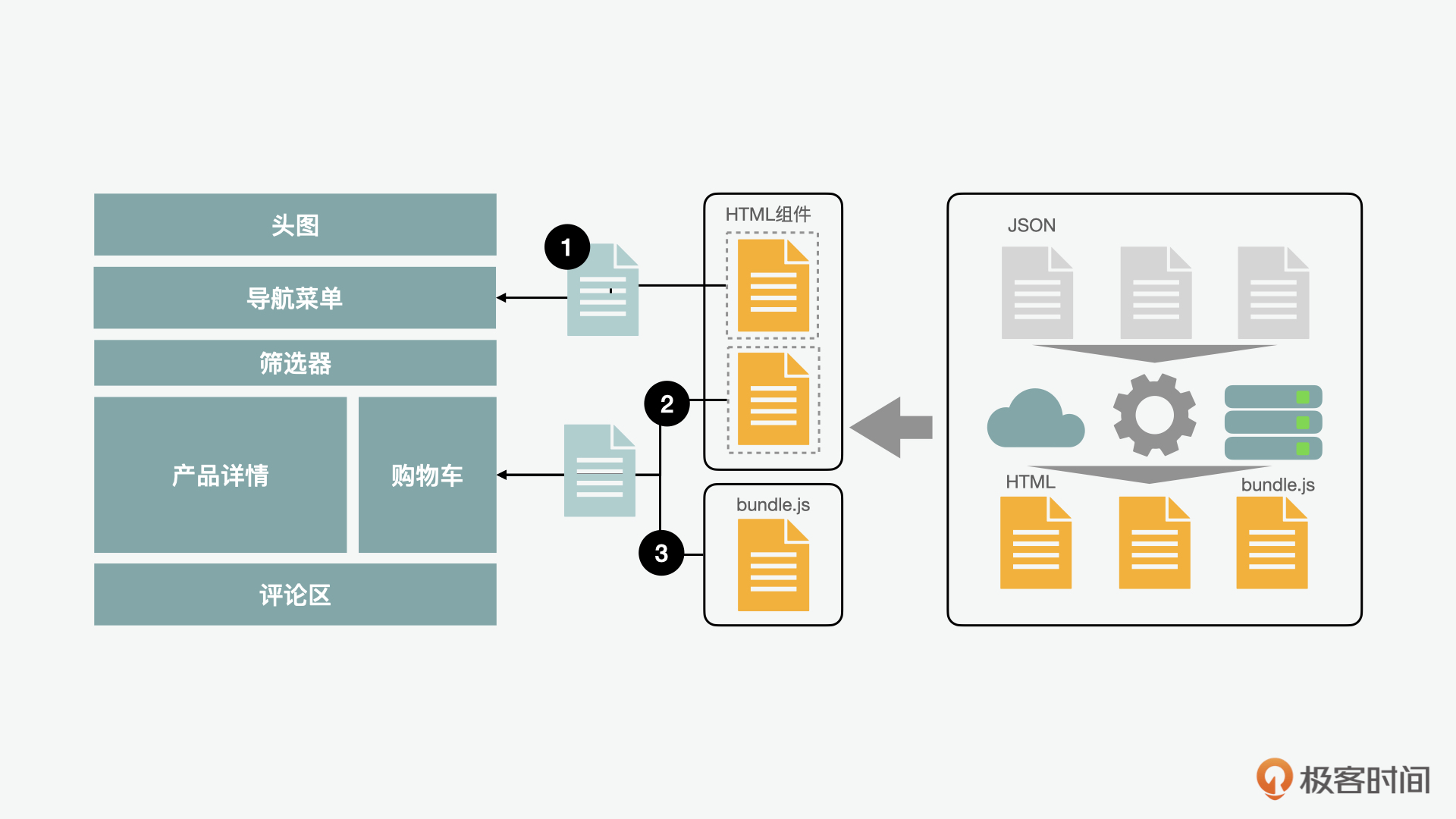
除了上述的这些模式外,还有一种集大成的模式叫做岛屿架构(islands architecture)。就好像我们在地理课学到的,所有的大陆都可以看作是漂流在海洋上的“岛屿”一样,这种模式把页面上所有的组件都看成是“岛屿”。把静态的组件视为静态页面“岛屿”,使用静态渲染;而对于动态的组件则被视为一个个的微件“岛屿”,使用后端加水合的方式渲染。
加载模式
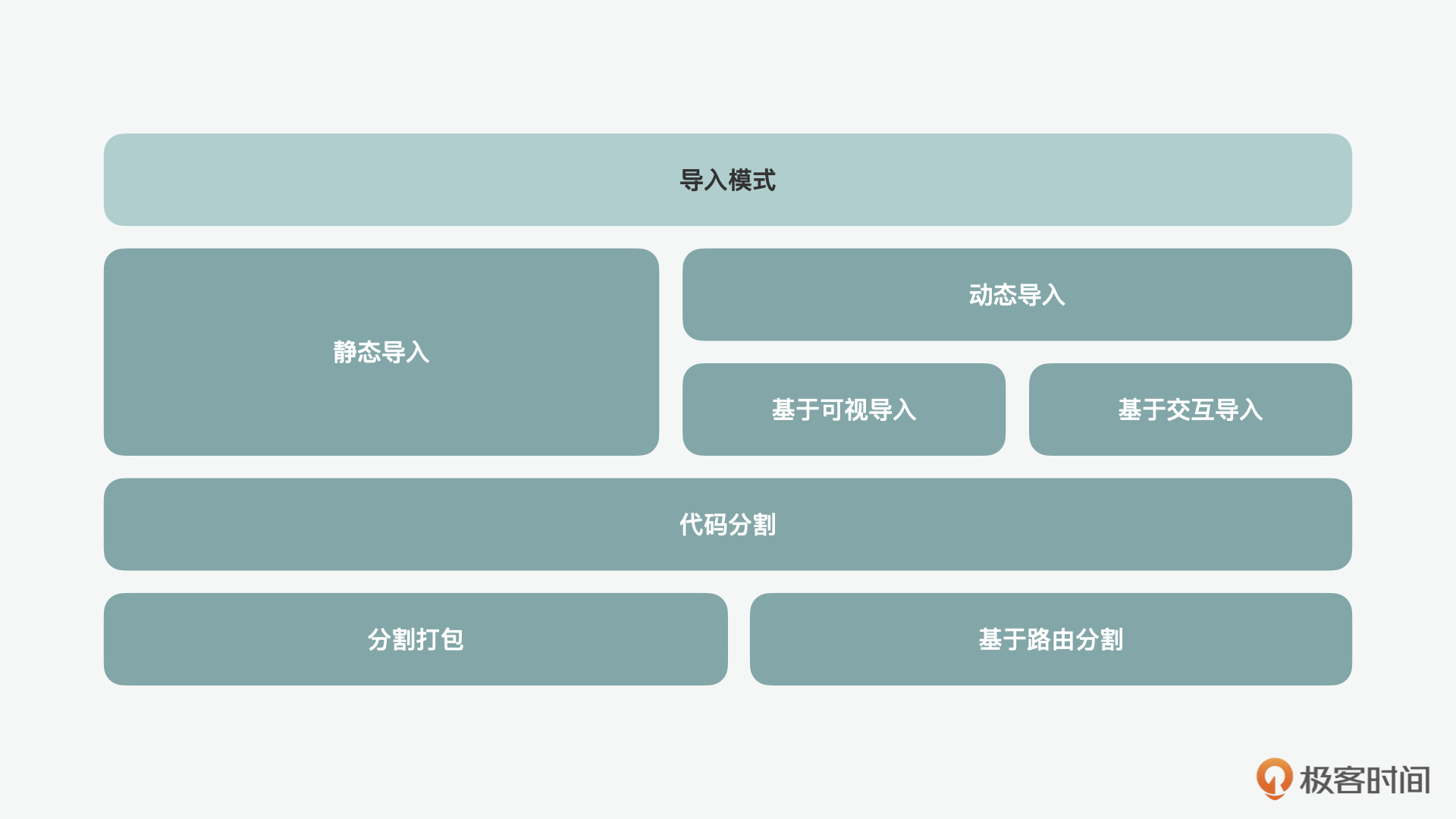
为了配合上述的渲染模式,自然需要一系列的加载模式。对于静态内容,就通过静态倒入;动态的内容则通过动态倒入。基于渐进的思想,我们也可以在部分内容活动到特定区域或者交互后,将需要展示的内容渐进地导入。被导入的内容可以通过分割打包(bundle splitting),根据路径(route based splitting)来做相关组件或资源的加载。
除此之外,另外一个值得了解的模式是PRPL(Push Render, Pre-Cache, Lazy-load)。PRPL模式的核心思想是在初始化的时候,先推送渲染最小的初始化内容。之后在背后通过service worker缓存其它经常访问的路由相关的内容,之后当用户想要访问相关内容时,就不需要再请求,而直接从缓存中懒加载相关内容。
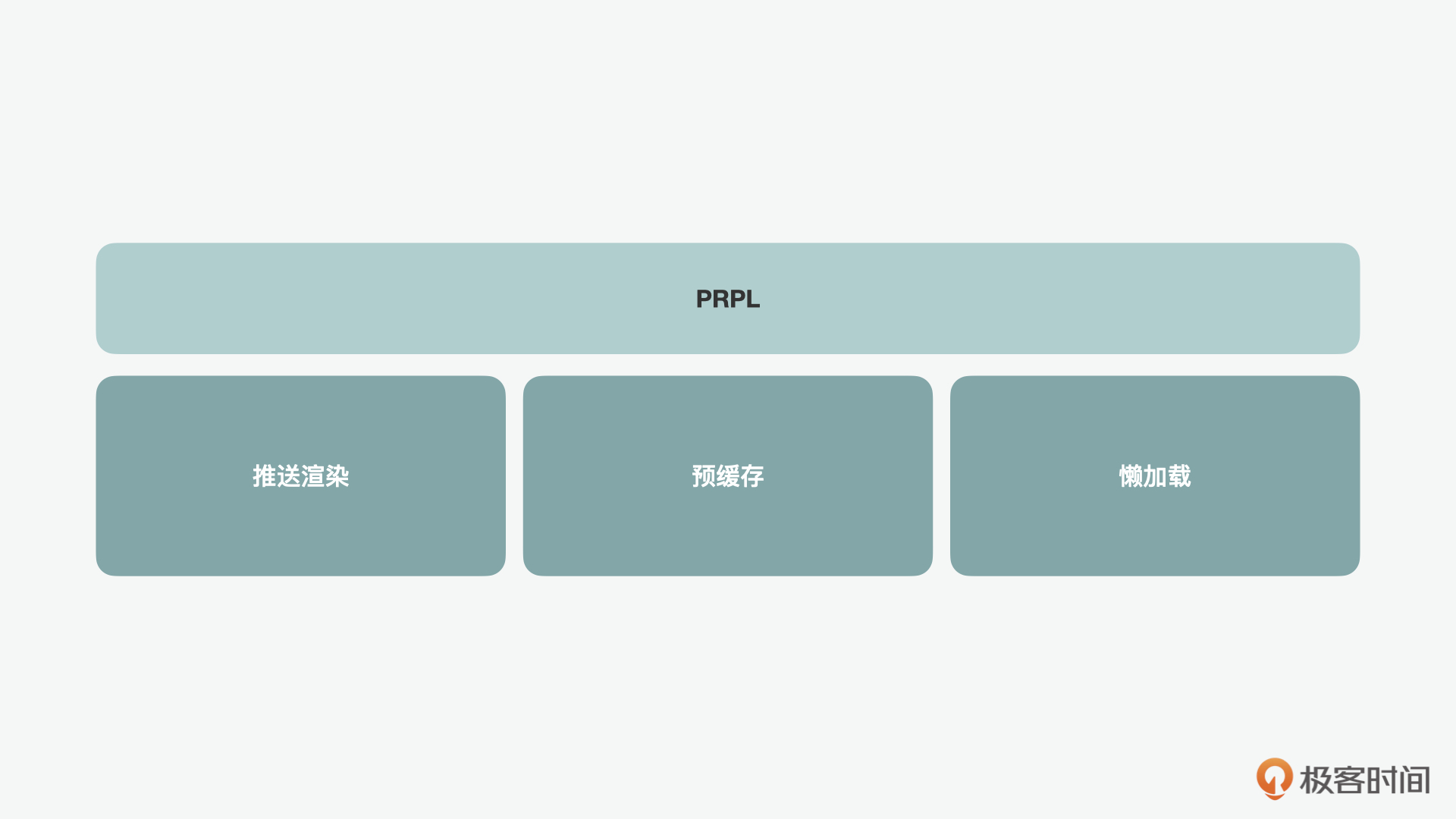
PRPL的思想是如何实现的呢?这里就要说到HTTP2的特点了。相比HTTP1.1,HTTP2中提供的服务器推送可以一次把初始化所需要的资源以外的额外素材都一并推送给客户端,PRPL就是利用到了HTTP2的这个特点。可是光有这个功能还不够,因为虽然这些素材会保存在浏览器的缓存中,但是不在HTTP缓存中,所以用户下次访问的时候,还是需要再次发起请求。
为了解决这个问题,PRPL就用到了service worker来做到将服务器推送过来的内容做预缓存。同时它也用到了代码分割(code splitting),根据不同页面的路由需求将不同的组件和资源分割打包,来按需加载不同的内容。
在说到加载的时候,还有一个我们需要注意的概念就是,pre-fetch不等于pre-load。pre-fetch更多指的是预先从服务器端获取,目的是缓存后,便于之后需要的时候能快速加载。而预加载则相反,是加载特别需要在初始化时使用的素材的一种方式,比如一些特殊字体,我们希望预先加载,等有内容加载时能顺滑地展示正确样式的字体。
性能优化模式
前面我们看了JS中特有的一些组件化和加载渲染模式。在加载渲染的模式中,我们已经可以看到提高性能的影子,最后我们再来看一个类别,就是进一步做到前端性能优化的模式,这里值得一提的,包括摇树优化(tree shaking)和虚拟列表优化(list virtualization)。
摇树优化
其中,摇树优化的作用是移除 JavaScript上下文中未引用的代码(dead-code)。那为什么我们需要移除这些代码呢?因为这些未被使用的代码如果存在于最后加载的内容中,会占用带宽和内存,而如果它们并不会在程序执行中用到,那就可以被优化掉了。
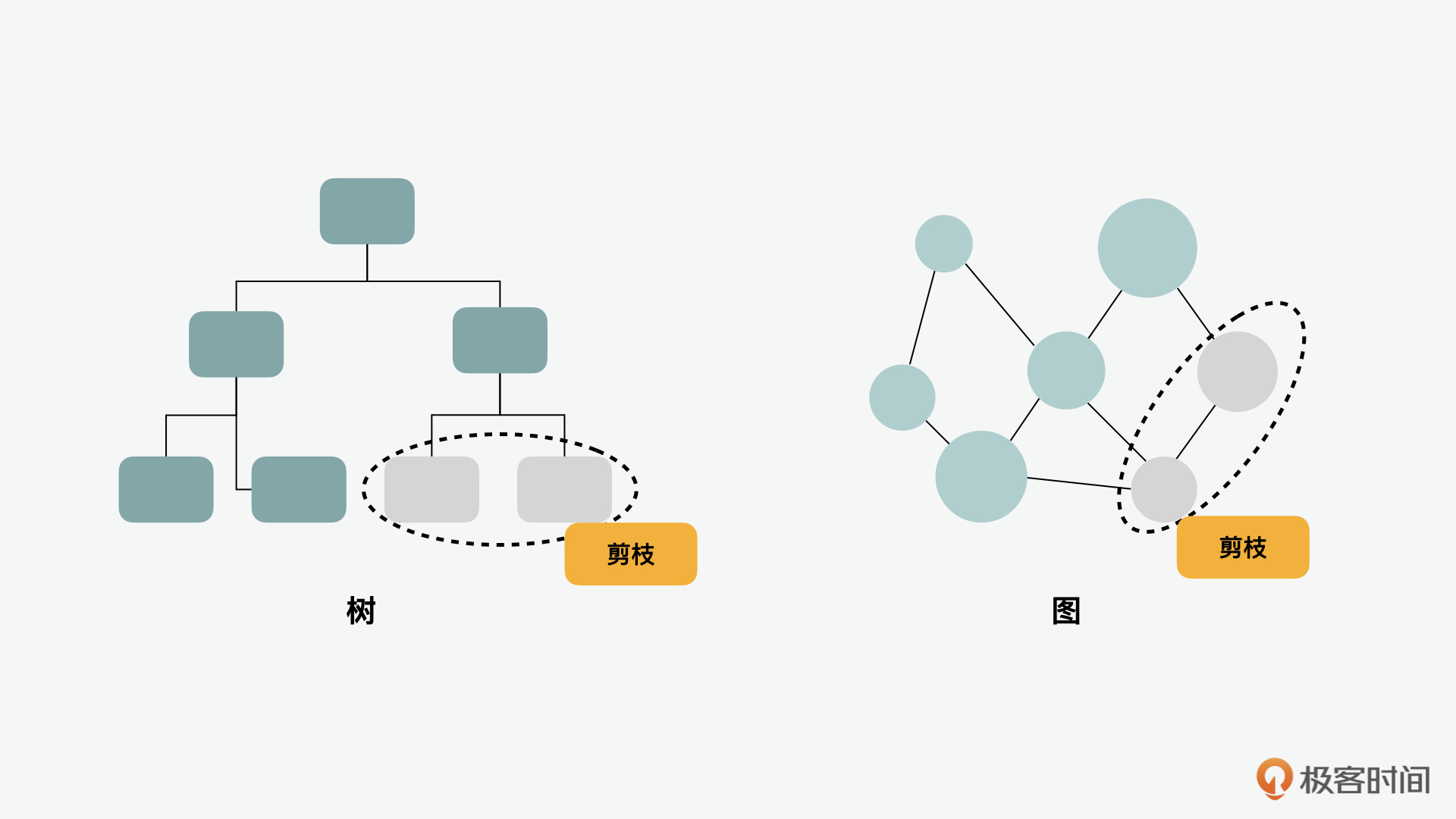
摇树优化中为什么会有“树”这个字呢?实际上它是一种图结构,但是你可以把它想象成一个类似于AST语法树的结构。摇树算法会遍历整代码中的执行关系,而没有被遍历到的元素则被认为是不需要的,会做相关的“剪枝”。它依赖于ES6中的import和export语句,检测代码模块是否被导出、导入,且被 JavaScript 文件使用。在JavaScript程序中,我们用到的模块打包工具例如webpack或Rollup,准备预备发布代码时,就会用到摇树算法。这些工具在把多个JavaScript文件打包为一个文件时,可以自动删除未引用的代码,使打包后的生成文件更简洁、轻便。
虚拟列表优化
说完摇树优化,我们再来看看列表虚拟化,它名字中的“虚拟化”一词从何而来呢?这就有点像我们在量子力学里面提到的“薛定谔的猫”思想,就是我们眼前的事物只有在观测的一瞬间才会被渲染出来,在这里我们的世界就好像是“虚拟”的沙箱。而在虚拟列表中,我们同样也只关注于渲染窗口移动到的位置。这样就可以节省算力和相关的耗时。
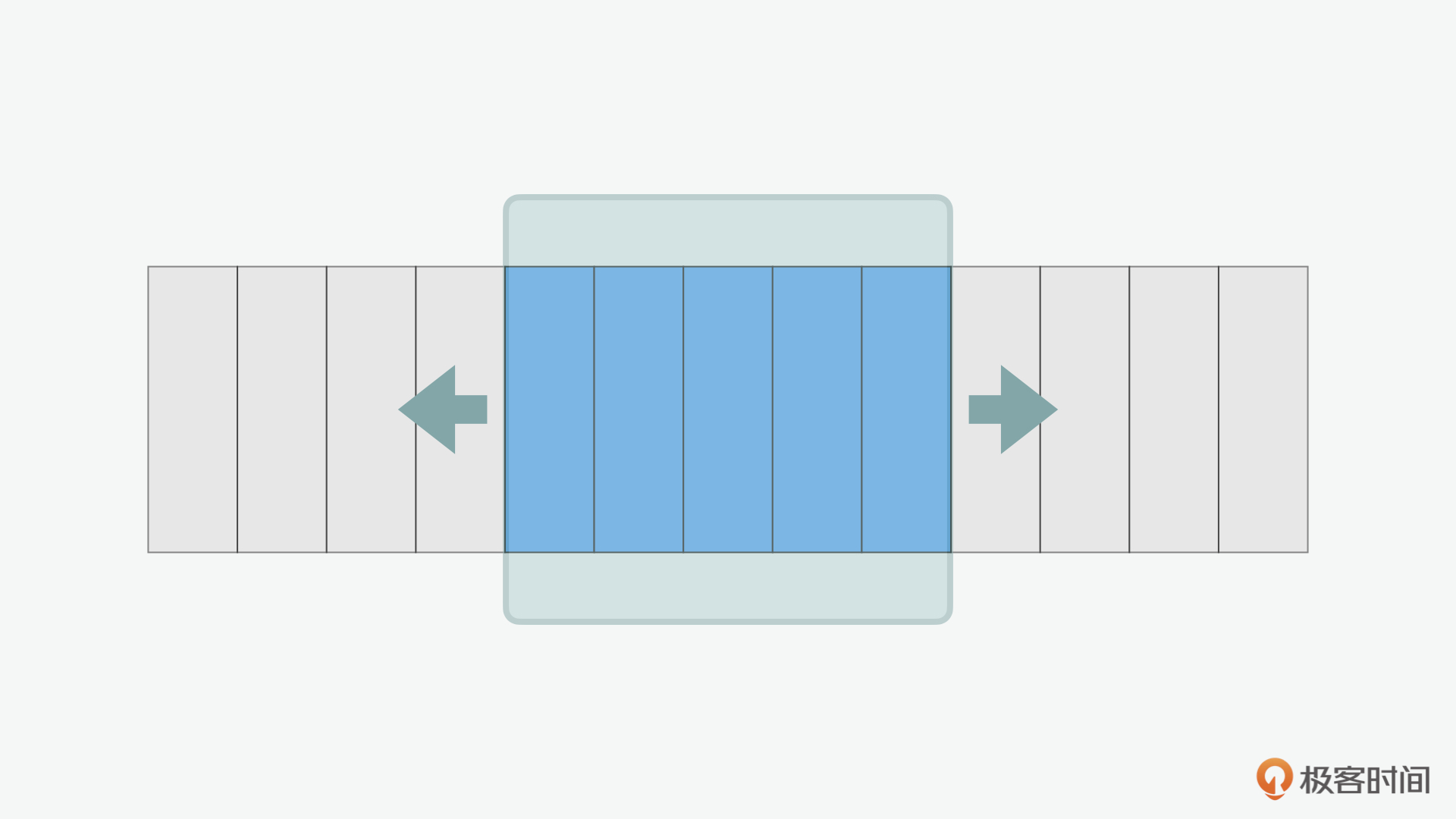
在基于React的三方工具中,有支持虚拟列表优化的react-window 和react-virtualized。它们两个的作者是同一个人。相比react-virtualized,react-window结合了上面讲到的摇树优化,同时它也比react-virtualized更加轻量化。感兴趣的同学可以在Github上了解更多。
总结
通过今天的学习,我们更系统化地了解了在前端强交互的场景下,响应式编程中的几种设计模式。我们学到了可以通过Hooks来减少组件间嵌套关系,更高效地建立数据、状态和行为上的联系。在加载和渲染的模式我们看到了,为了提高展示和交互的速度,降低资源的消耗,如何渐进式地提供内容和交互。最后在性能优化模式中,我们可以看到更多通过优化资源及节省算力的方式来提高性能的模式。
思考题
我们前面说到了通过Hooks可以减少嵌套,那么你觉得这种方式可以直接取代上下文提供者(context provider)、渲染属性(render props)、高阶组件(HOC)的这些模式吗?
欢迎在留言区分享你的答案、交流学习心得或者提出问题,如果觉得有收获,也欢迎你把今天的内容分享给更多的朋友。我们下节课再见!
参考资料
https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/JavaScript%20%e8%bf%9b%e9%98%b6%e5%ae%9e%e6%88%98%e8%af%be/26%20%e7%89%b9%e6%ae%8a%e5%9e%8b%ef%bc%9a%e5%89%8d%e7%ab%af%e6%9c%89%e5%93%aa%e4%ba%9b%e5%a4%84%e7%90%86%e5%8a%a0%e8%bd%bd%e5%92%8c%e6%b8%b2%e6%9f%93%e7%9a%84%e7%89%b9%e6%ae%8a%e2%80%9c%e6%a8%a1%e5%bc%8f%e2%80%9d%ef%bc%9f.md
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
