03 DevOps 场景下落地 K8s 的困难分析 Kubernetes 是用于自动部署,扩展和管理容器化应用程序的开源系统,一般被 DevOps 团队用来解决在 CI/CD(也就是持续集成、持续发布)场景下遇到的工具链没法统一,构建过程没法标准化等痛点。DevOps 团队在落地 Kubernetes 的过程中发现,在安装、发布、网络、存储、业务滚动升级等多个环节都会遇到一些不可预期的问题,并且官方的参考资料并没有确定性的方案来解决。很多 DevOps 因为需要快速迭代,都不得不采用现有的经验临时解决遇到的问题,因为场景限制,各家的问题又各有各的诉求,让很多经验无法真正的传承和共享。本文旨在直面当前的 DevOps 痛点,从源头梳理出核心问题点,并结合业界最佳的实践整理出一些可行的方法论,让 DevOps 团队在日后落地可以做到从容应对,再也不用被 Kubernetes 落地难而困扰了。
Kubernetes 知识体系的碎片化问题
很多 DevOps 团队在落地 Kubernetes 系统时会时常借助互联网上分享的业界经验作为参考,并期望自己少点趟坑。但是当真落地到具体问题的时候,因为环境的不一致,场景需求的不一致等诸多因素,很难在现有的方案中找到特别合适的方案。
另外还是更加糟糕的情况是,网上大量的资料都是过期的资料,给团队的知识体系建设带来了很多障碍。虽然团队可以借助外部专家的指导、专业书籍的学习等多种方法,循序渐进地解决知识的盲点。我们应该避免 Kubernetes 爆炸式的知识轰炸,通过建立知识图谱有效地找到适合自己团队的学习路径,让 Kubernetes 能支撑起你的业务发展。以下就是笔者为你提供的一份知识图谱的参考图例:
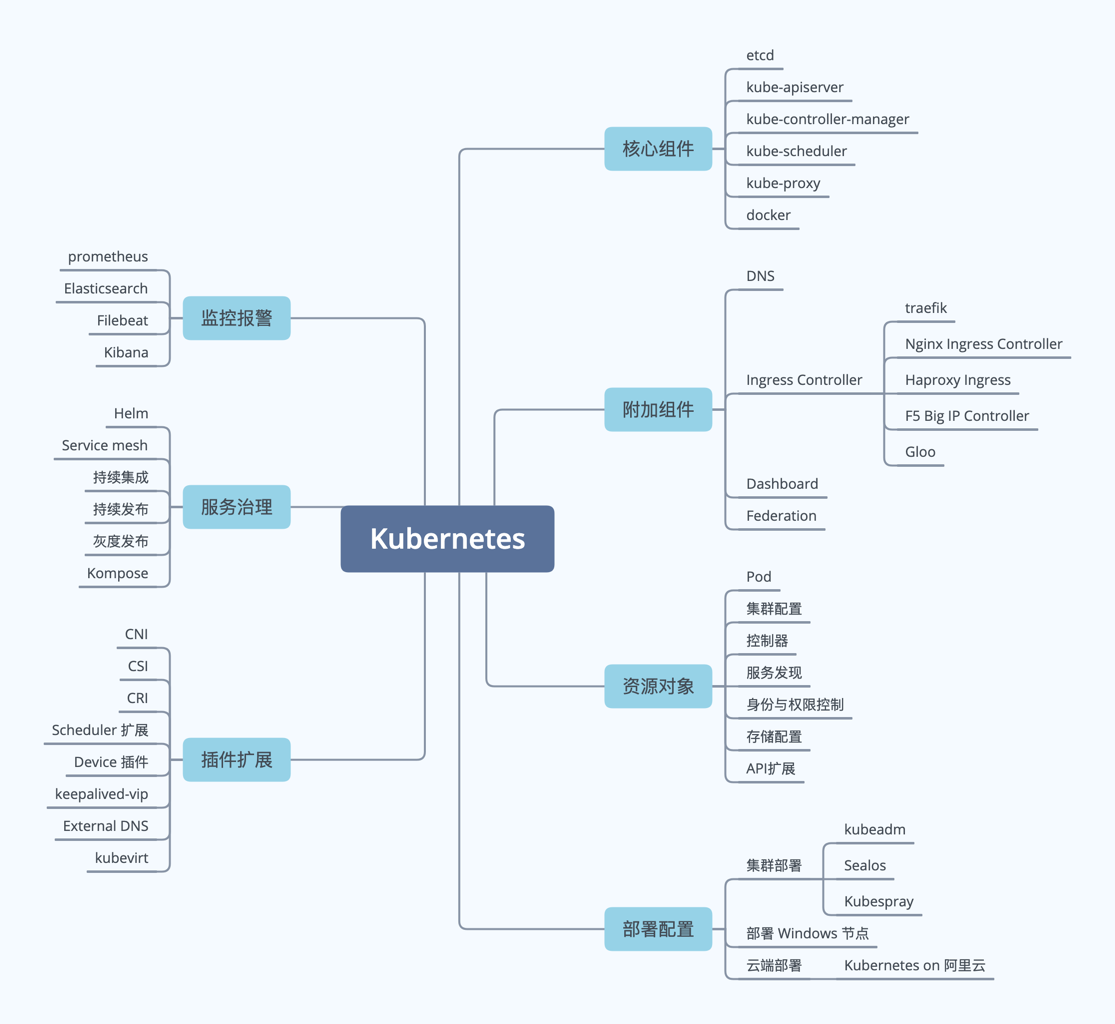
有了图谱,你就有了一张知识导航图,帮助你在需要的时候全局了解团队的 Kubernetes 能力。
容器网络的选择问题
容器网络的选择难题一直是 DevOps 团队的痛点。Kubernetes 集群设计了 2 层网络,第一层是服务层网络,第二层是 Pod 网络。Pod 网络可以简单地理解为东西向容器网络,和常见的 Docker 容器网络是一致的设计。服务层网络是 Kubernetes 对外暴露服务的网络,简单地可以理解为南北向容器网络。Kubernetes 官方部署的常见网络是 Flannel,它是最简化的 Overlay 网络,因为性能不高只能在开发测试环境中使用。为了解决网络问题,社区提供了如 Calico、Contiv、Cilium、Kube-OVN 等诸多优秀的网络插件,让用户在选择时产生困惑。
首先企业在引入 Kubernetes 网络时,仅仅把它作为一套系统网络加入企业网络。企业网络一般设计为大二层网络,对于每一套系统的网络规划都是固定的。这样的规划显然无法满足 Kubernetes 网络的发展。为了很好地理解和解决这样的难题,我们可以先把大部分用户的诉求整理如下:
- 第一 ,由于容器实例的绝对数量剧增,如果按照实例规划 IP 数量,显然不合理。
- 第二、我们需要像虚拟机实例一样,给每一个容器实例配置固定的 IP 地址。
- 第三、容器网络性能不应该有损耗,最少应该和物理网络持平。
在这样的需求下,网络性能是比较关键的指标。查阅网上推荐的实践,可以看到一些结论:Calico 的虚拟网络性能是接近物理网络的,它配置简化并且还支持 NetworkPolicy,它是最通用的方案。在物理网络中,可以采用 MacVlan 来获得原生网络的性能,并且能打通和系统外部网络的通信问题。
这样的信息虽然是网上分享的最佳实践,我们仍然会不太放心,还是需要在本地网络环境中通过测试来验证的。 这种网络验证是必须的,只是在选择网络选型时,我们大可不必把每一项网络方案都去测试一遍。我们可以遵循一些合理的分类来明确方向。
其实,我们应该回到 Kubernetes 的设计初衷,它是一套数据中心级别的容器集群系统,我们可以给它独立的网络分层。按照这个方向选择,它的网络应该采用虚拟网络,这样我们就会看到可以选择的方案是 Flannel、Calico、Cilium。
还有另外一个方向,就是希望 Kubernetes 网络是你整个企业网络的延展,这样的设计目标之下,等于你给 Kubernetes 网络落地原有的网络。Kubernetes 上的对象系统全部压缩到只使用 Pod 网络这一层。笔者人为在很多传统遗留的系统中,如果想落地 Kubernetes 方案就会遇到这样的问题。在这样的场景下,应该采用 Contiv、Kube-Ovn 直接对接原生网络。这样的设计会平滑的让很多遗留系统平滑的迁入到云原生的网络之中。这是非常好的实践。
存储方案的引入问题
容器 Pod 是可以挂载盘的,对于外挂盘有本地存储、网络存储,对象存储这样的三类。在早期 Kubernetes 发展阶段,容器存储驱动是百花齐放,很多驱动的 Bug 导致容器运行出现各种各样的问题。现在 Kubernetes 社区终于制定了 CSI 容器存储标准方案,并且已经达到生产可用阶段。所以,我们在选择存储驱动的时候一定需要选择 CSI 的存储驱动来调用存储。
本地存储原来都是直接挂载目录,现在采用 CSI 方式之后,本地的资源也期望采用 PV、PVC 的方式来申请,不要在直接 Mount 目录了。
对于网络存储,一般我们特别指定 NFS。NFS 比较特别的地方是它是共享挂载方式,也就是一个目录可以被多台主机挂载。但是 PV、PVC 的挂载方式仍然期望目标存储是唯一的,这个时候,一定要注意规划好 NFS 的目录结构。还有需要注意的是存储的大小在 NFS 中是没法限制的,完全有底层 NFS 来规划。为了有效管理存储空间大小,DevOps 团队可以手动创建 PV 并限制好空间大小,然后让用户采用 PVC 来挂载这个手动创建的 PV。
对于对象存储,因为抽象能力的增强,可以实现 PV 的动态创建和 PVC 的自动挂载,并且申请的大小可以动态满足。这个是最理想的存储方案,但是因为后端存储系统如 Ceph 类需要专人维护,才能保证系统的问题性。在投入资源时需要多加考虑。
容器引擎的选择问题
很多人好奇这有什么好选择的,直接安装 Docker 不就完事了。因为容器技术的发展,目前 Kubernetes 官方引擎已经默认安装为 Cri-O 开源引擎。原来,Kubernetes 社区给容器引擎定义了一套标准,所以容器引擎开始出现多元化。为了更清楚地理解容器引擎的位置,我们可以通过一张图来详细理解容器引擎的位置:
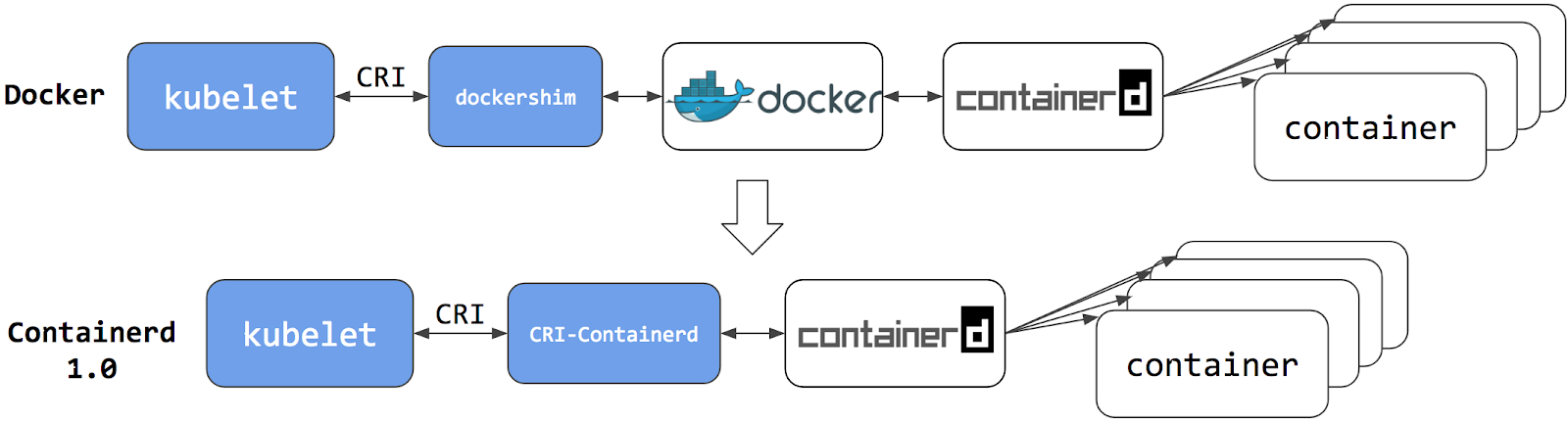
显而易见,Cotnainerd 已经取代 Docker 的位置,由于 Containerd 源自 Docker 源码,它的可靠性是经过多年的历练的,目前是最可靠的容器引擎。
除此之外,当业务发展需要实现多租户时,对于主机环境不在信任,这个时候的容器引擎需要更进一步的隔离。目前可以选择的方案有 KataContainer、firecracker、gVisor。这种技术一般被称为富容器技术,通过采用裁剪虚拟化组件来彻底隔离容器环境,是真正轻量级虚拟机。打个比方,你就会明白。因为服务器的规格越来越高级,CPU 一般都达到 32 核,内存高达 256G 的规格都很常见,在这么大容量的主机上,如果只跑一个用户群体的容器,显然会浪费。原来我们实现资源划分都是采用虚拟机隔离一层之后在分配给业务,业务 DevOps 团队在规划 Kubernetes 集群资源。当我们把虚拟化这一层例如 Openstack 和 Kubernetes 合并之后,势必需要把虚拟化技术真正引入到 Kubernetes 中,所以,这就是富容器的意义所在。当然这块的实践配置仍然还无法做到傻瓜方式,仍然需要专业的开发人员进行调优,所以我们还需要谨慎试用。
集群规模的规划问题
对于企业来说,一套系统应该只希望部署一套,减少管理运维成本。但是毕竟 Kubernetes 是一套开源系统,在很多场景下它并没有办法解决跨网的管理,我们不得不为了业务划分部署多套集群。多套集群等于就是多套基础设施,让很多 DevOps 团队开始感到一些运维压力。这里我们可以对比一下:
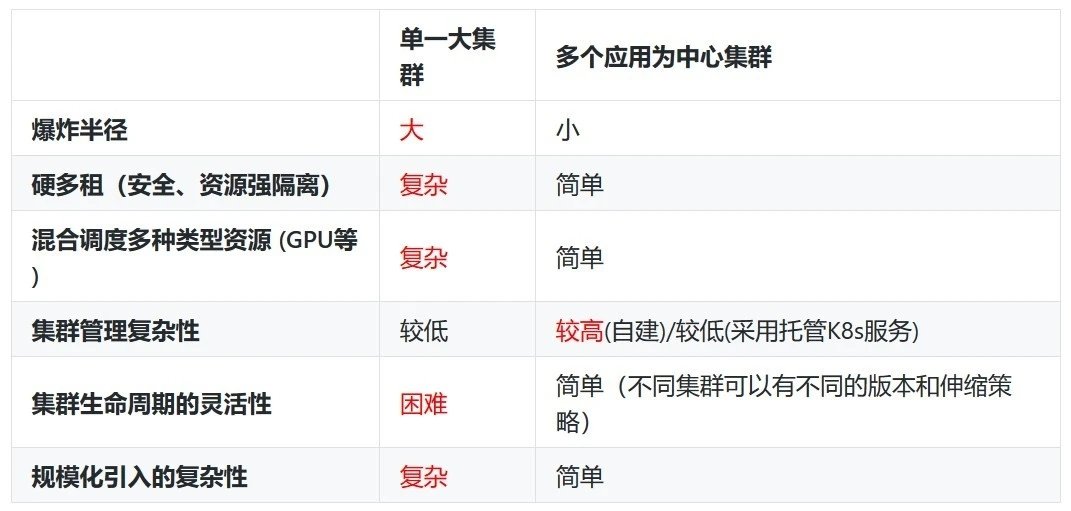
这里我认为应该参考谷歌内部集群运维的经验,按照数据中心的规模,每个数据中心只规划一套集群。那么国内企业比较头疼的现状是内部网络采用防火墙隔离成若干隔离区域,每个网络区域直接通过白名单方式开放有限的端口,甚至生产网络只允许通过跳板机执行运维操作。如果是一套 Kubernetes 集群部署到这样的复杂网络中,势必需要规划梳理很多参数和规则,比分开部署集群需要投入更多的精力。
为了有效地解决这个难题,我们可以通过迭代的办法,先期采用多套集群的模式,然后通过主机标签和 Namespace 空间方式,不断把多个集群的主机归并到单一集群中。当然,谷歌的安全级别只有一种,不管是开发测试还是集成生产都是一个安全策略,这非常适合一套集群的规划。但是很多企业的安全级别是分开管理的,服务质量 SLA 也是不一样的。在这样的情况下,我们可以把集群分为开发测试集群和生产集群,也是很合理的规划。毕竟,安全是企业的生命线,然后才是集群运营成本的规划。
安全审计的引入问题
Kubernetes 系统是一套复杂的系统,它的安全问题也是企业非常重视的环节。首先,对于集群调用的认证和授权,原生有一套 RBAC(角色的权限访问控制)模型。这种 RBAC 在角色权限不是很多的情况下,它是可以支撑的。但是对于更细力度的控制就无法轻易满足了。比如:允许用户访问用户的 Namespace,但是不允许访问 kube-system 系统级的命名空间这样细粒度的虚拟。社区提供了 Open Policy Agent 工具就是来解决这个问题的。
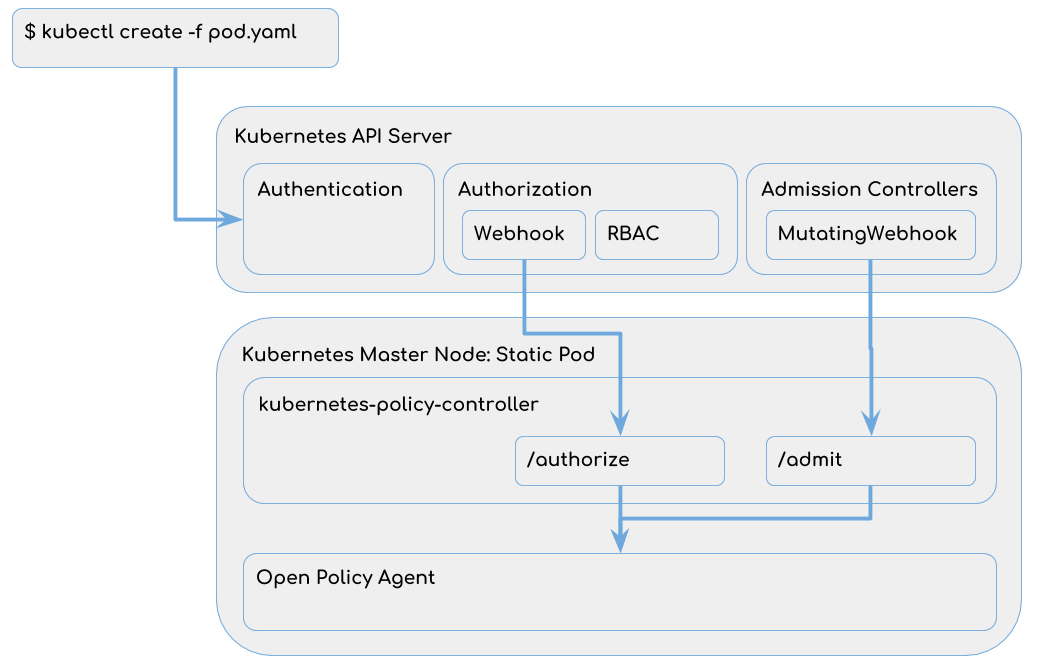
简单地说,RBAC 是白名单做法,用户规则多的情况下,策略变更需要涉及多个角色的定义更新,维护成本高。采用 OPA 是黑名单的做法,只需要一个规则就可以搞定变更。
另外,企业 Kubernetes 的安全情况需要借助一些工具来定期审查。比较出名的工具是 CIS Kubernetes Benchmark,你可以参考应用。
业务保障团队的建设问题
很多 DevOps 团队在接手 Kubernetes 之后,明显发现这套系统的运维难度是之前其它系统的数倍。对于业务稳定性的要求给 DevOps 团队带来很多不确定的压力。很明显的原因是,Kubernetes 对人员的能力要求提高了。
参考谷歌的 SRE 团队的建设历程,我发现这是国内企业比较缺失的一个岗位。SRE 在国内传统企业并不多见,它类似资深运维架构师,但处理问题的视角以业务为中心来保障企业的正常运营。随着阿里系在引入业务保障体系之后的成功,国内领先的大厂已经渐渐接受了这种新的角色,并且还在不断升华这个岗位的能力范围。
对于传统企业来说,现有 DevOps 人员如何有效的升级知识结构,并能转变思路以业务保障为中心全局的来思考问题成为新的课题。从资源上来讲,很多企业的技术能力是由合作伙伴的整合来完成的,并不是一定需要传统企业打破原有企业的岗位规划,完全采用互联网的做法也是有很多风险在里面。因为传统企业的第一要素是安全,然后才是可靠性。因为传统企业的数据可靠性早就比互联网企业要成熟很多,通过大量的冗余系统足够保证数据的完整性。在这样的情况之下,原厂的 DevOps 团队应该充分理解 Kubernetes 的能力缺陷,多借助合作伙伴的技术合作共赢的方式,让 Kubernetes 系统的落地更加稳健。
集群安装的问题
大家别小看 Kubernetes 的安装工具的问题,目前业界有很多种 Kubernetes 集群安装部署方式,这让企业的 DevOps 团队感到困惑。
首先,Kubernetes 的核心组件发布的都是二进制版本,也就是在主机层面可以使用 systemd 的方式来安装部署。有一些部署版本采用静态 Pod 的方式来部署都是比较特别的部署方式,不建议传统企业采用。还有一些发行版本完全采用容器的部署方式来数据,虽然早期使用过程中感觉很方便,但是在日后运维中,因为容器的隔离导致组件的状态无法第一时间获取,可能会给业务故障的排查带来一定的障碍。所以笔者推荐的方式还是采用二进制组件的方式来部署最佳。当前 Kubernetes 官方主推的是 kubeadm 来安装集群,但是 kubeadm 竟然也是采用镜像来部署核心组件,虽然在便捷性上给用户节省了很多事情,但是也给未来的故障运维带来很多坑,请小心使用。
其次,因为企业对集群有高可用的需求,所以 Master 节点一般配置为 3 台。其中,最重要的组件就是 etcd 键值集群的维护。其中让企业很容易混淆的地方是,Master 节点只要有 3 台以上,我们的系统就是高可用的,其实不然。如果 3 台 Master 节点放在一个网络区域,当这个网络区域出现抖动的时候,服务仍然还是会出问题。解决办法就是把 Master 放在 3 个不同的网络区域才能实现容错和高可用。
另外,还有很大一部分企业的情况是服务器的规模有限,比如 5~6 台左右,也想使用 Kubernetes 集群。如果划出 3 台作为 Master 节点不跑业务会觉得很浪费。这个时候,我认为应该采用更轻量级的 Kubernetes 集群系统来支持。这里我推荐 K3s 集群系统,它巧妙的把所有核心组件都编译到一个二进制程序里,只需要 40M 大小就可以部署。虽然这个集群是单机版本的集群,但是 Kubernetes 集群的 Node 节点上承载的业务并不会因为 Master 节点宕机就不可以访问。我们只需要在业务上做到多节点部署,就可以完美切合这样的单节点集群。企业可以根据需要灵活采用这种方案。
综上所述,我认为企业落地 Kubernetes 是有一定的技术挑战的,DevOps 需要迎面接受挑战并结合落地情况选择一些合理的方案。
参考资料
https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/Kubernetes%20%e5%ae%9e%e8%b7%b5%e5%85%a5%e9%97%a8%e6%8c%87%e5%8d%97/03%20DevOps%20%e5%9c%ba%e6%99%af%e4%b8%8b%e8%90%bd%e5%9c%b0%20K8s%20%e7%9a%84%e5%9b%b0%e9%9a%be%e5%88%86%e6%9e%90.md
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
