08 运行时(下):不同语言形态下的函数在容器中是如何执行的? 你好,我是静远。这节课,我们继续来看运行时的原理和实践。
在上一节课里,我跟你分享了运行时的基本理念以及不同语言下运行时的区别,并且通过GoLang的例子让你对运行时有了一个具象化的理解。
今天我将重点介绍后半部分:解释型语言的实现和异同。通过今天的课程,相信你会对运行时有一个从1到N的认知,并从中抽象出一套构建思路,用于自己的实战中。
Python运行时
通过GoLang Runtime运行时的学习,相信你已经了解运行时需要完成的工作以及整个处理流程了。
在前面我也提到了,编译型语言的业务逻辑与依赖通常都存在着强绑定的关系,需要将运行时和用户编写的函数代码统一编译成一个二进制文件或者Jar包、War包后再被执行,但解释型语言不需要。这也从一定程度上说明了很多函数计算平台只对编译型语言运行时进行开源的原因。
接下来,我以Python语言为例来介绍一下解释型语言的运行机制,带你进一步加深对函数计算运行时的理解。
如果你使用Python或者Node.js开发过函数计算的代码,你会发现,其实上传的文件完全不需要任何依赖,甚至两行代码就可以定义好你的函数入口,比如下面这个Python的案例: def handler(event, context): return ‘hello world’
在这种情况下,其实是不利于我们对运行时做分析的,但有的云厂商提供了登录函数实例的能力。我们就继续以阿里云函数计算FC来说明,它提供的实例登录功能,可以让我们直接到实例中查看运行时的执行过程。
路径
登录函数实例后,我们首先要找到运行时被挂载在哪个路径下。想一想,我们有可能在哪里找到它呢?
运行时作为一个容器的进程,不断等待请求的到来,它的生命周期和函数容器实例是保持一致的,因此,我们可以直接在当前路径下使用“ps” 命令,查看当前实例内进程的运行状态。 root@s-62c8e50b-80f87072536d411b8914:/code/# ps -ef UID PID PPID C STIME TTY TIME CMD user100+ 1 0 0 02:16 pts/0 00:00:00 /var/fc/runtime/rloader user100+ 4 1 0 02:31 pts/0 00:00:00 /var/fc/lang/python3/bin/python3 -W ignore /var/fc/runtime/python3/bootstrap.py root 6 0 0 02:31 ? 00:00:00 /bin/sh -c cd /code > /dev/null 2>&1 && COLUMNS=167; export COLUMNS; LINES=27; export LINES; TERM=xterm-256color; expor root 7 6 0 02:31 ? 00:00:00 /bin/sh -c cd /code > /dev/null 2>&1 && COLUMNS=167; export COLUMNS; LINES=27; export LINES; TERM=xterm-256color; expor root 8 7 0 02:31 ? 00:00:00 /usr/bin/script -q -c /bin/bash /dev/null root 9 8 0 02:31 pts/0 00:00:00 sh -c /bin/bash root 10 9 0 02:31 pts/0 00:00:00 /bin/bash
1号进程为实例启动的初始进程,4号进程是通过1号进程fork出来的,它其实就是Python运行时了,而bootstrap.py是整个运行时的入口,看进程的启动参数就可以知道Python运行时的路径其实就在/var/fc/runtime/python3/ 下。
核心流程
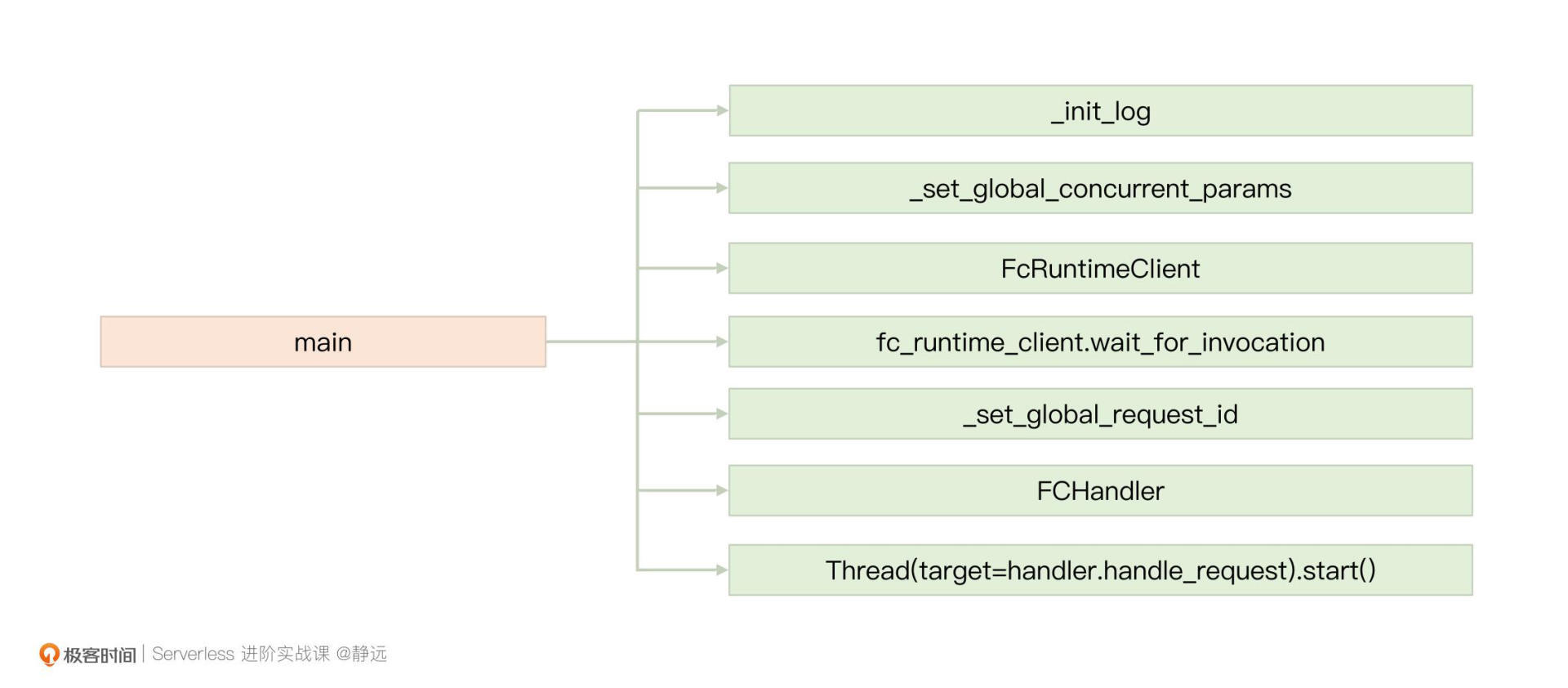
针对Python运行时这一部分,我将只截取main函数的部分代码来跟你介绍它的主要流程,你也可以顺便体会一下Python和GoLang运行时在处理请求中有哪些异同。完整的代码,你可以进入到/var/fc/runtime/python3/中看到。 def main(): …… try: _init_log() /# 日志初始化 … _set_global_concurrent_params() /# 设置全局并发参数 fc_api_addr = os.environ[‘FC_RUNTIME_API’] fc_runtime_client = FcRuntimeClient(fc_api_addr) /# 创建runtime client _sanitize_envs() except Exception as e: … return /# 等待请求 …. while True: try: if global_concurrent_limit == 1: request = fc_runtime_client.wait_for_invocation() else: request = fc_runtime_client.wait_for_invocation_unblock() … handler = FCHandler(request, fc_runtime_client) /# 获取函数入口函数 if global_concurrent_limit == 1: handler.handle_request() /# 执行业务逻辑 else: /# 如果是多并发执行,则通过线程启动执行任务 from threading import Thread Thread(target=handler.handle_request).start() except Exception as e: …
从代码结构看,整个运行时的核心处理流程和GoLang运行时中的逻辑基本类似,包括了以下三个方面。
- 服务初始化: 包括日志初始化、设置并发模式下的全局参数。同时,还是通过FC_RUNTIME_API这个环境变量所提供的服务地址,构造之后获取请求的客户端;
- 获取请求:使得客户端不断获取请求信息;
- 根据请求信息执行用户代码:这里和Golang唯一的区别就是,在多并发情况下,Python指派的是线程来完成任务的处理,而不是协程。
这里我再简单提一下关联用户handler的方法,以及调用用户handler方法处理请求的过程,也就是FCHandler的handle_request方法: def handle_request(self): … event, ctx, handler = self.get_handler() /# load user handler valid_handler, request_handler = _concurrent_get_handler(handler) /# execute handler if self.function_type == Constant.HANDLE_FUNCTION and self.request.http_params: /# http function succeed, resp = wsgi_wrapper(self.request_id, request_handler, event, ctx, self.request.http_params) if succeed: self.print_end_log(True) self.fc_runtime_client.return_http_result(self.request_id, resp[0], resp[1], Constant.CONTENT_TYPE) return else: succeed, resp = execute_request_handler(self.function_type, request_handler, event, ctx) if succeed: self.print_end_log(True) self.fc_runtime_client.return_invocation_result(self.request_id, resp, Constant.CONTENT_TYPE) return …
程序首先会调用get_handler,获取请求中的userHandler信息。这个信息其实就是你在云函数元信息中配置的类似index.handler这种形式的入口函数。后续的过程和GoLang的处理思路基本上是一样的,也是通过反射机制获取到具体的userHandler,然后对其进行调用。
我们可以用一个示意图来梳理一下上面的主流程,便于你之后回溯执行过程:
分析运行时的小技巧
像GoLang、Java这一类运行时,一般都有开源的代码可以查看,而像Python这一类解释型语言的运行时,代码通常都不能直接获取到,并且很多函数计算平台也不会像阿里云函数计算FC一样,为用户提供函数实例的登录入口。这个时候,如果你想要分析运行时,其实是不太方便的。
这里教给你一个小技巧。一般来说,用户都是有函数容器实例内文件的可读权限的,你可以通过在代码中注入命令的方式查看。
我继续以Python运行时为例,简单演示一下。通过在函数代码内执行一些shell命令,就可以将想看的运行时代码打印出来,如通过ps 、ls、cat等常用命令,就可以完成我们需要的任务: import logging import os def handler(event, context): print(os.system(“ps -ef”)) print(os.system(“ls -l /var/fc/runtime”)) print(os.system(‘cat /var/fc/runtime/python3/bootstrap.py’)) return ‘hello world’
这里需要说明一点,不同的云厂商可能实现方式不一样,有的厂商对运行时代码路径做了屏蔽处理,你只能看到一层入口而已。
运行时构建思路
学习了两种不同类型运行时的实现原理之后,相信你对运行时的整个工作流程已经有了一个比较清晰的认知。接下来,我们就可以利用上面学到的知识,构建一个自己的运行时了。
来回想一下,请求从到达函数实例再到被执行经过了哪些关键步骤?
- 需要有一个初始化进程,将运行时加载到内存中运行起来;
- 运行时需要获取到请求的详细信息。在GoLang、Python中,都是通过客户端请求约定的接口获取的,如RUTIME_API。这里也可以通过其他方式来获取,比如管道;
- 调用用户代码执行请求,并在处理后,请求返回结果。
我们在自己构建函数平台的时候,就可以参考这种方式,但如果你是一个函数业务开发人员,也完全可以基于云厂商的工具和平台来定义一个自己的运行时。
实战体验
接下来我会带你利用阿里云函数计算FC提供的开发工具Serverless Devs手动搭建一个自定义运行时,帮助你加深对整个运行时概念的理解。
我们首先选择python37作为自定义运行时,创建一个初始项目。 s init fc-custom-python37-event
在初始化项目时候,会提示你进行一些配置,按照提示一一输入即可,这里我给新的项目叫做GeekBang。
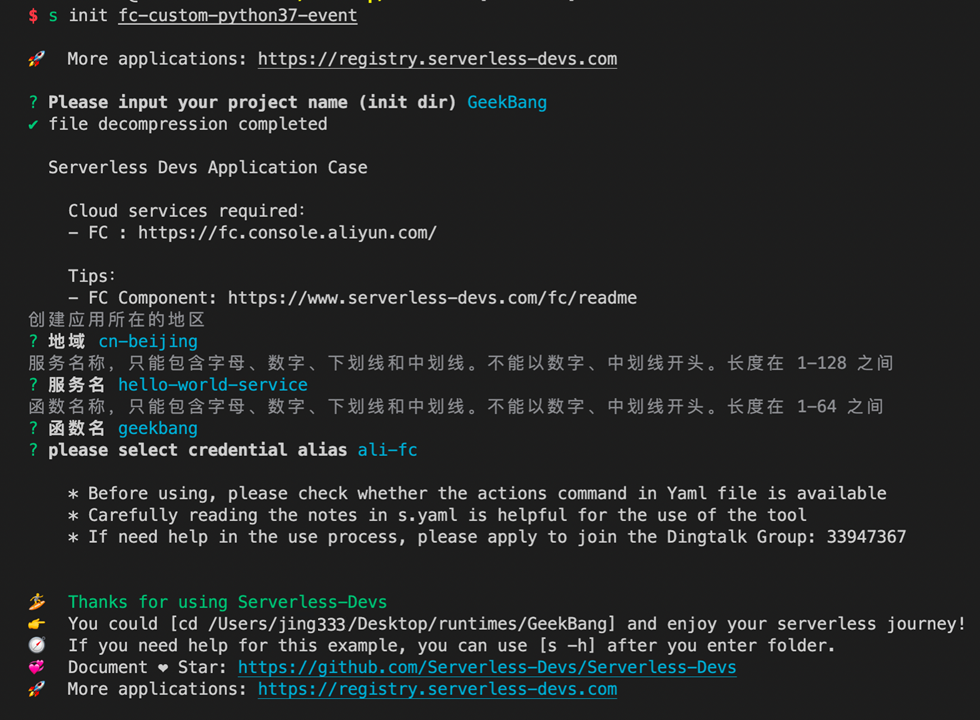
进入到项目路径下,我们可以看到都创建了哪些东西: $ tree . . ├── code │ ├── gunicorn_conf.py │ ├── requirements.txt │ └── server.py ├── readme.md ├── s.yaml └── s_en.yaml
可以看到,它包括了一些yaml格式的配置文件,以及一个code 文件夹。这两个yaml文件其实一样,只不过s_en.yaml里是英文注释,我们点开s.yaml进行查看,就会发现里面除了配置超时时间、内存限制等常见参数外,还有一个自定义运行时的启动参数。
customRuntimeConfig: command: - gunicorn args: - ‘-c’ - ‘gunicorn_conf.py’ - ‘server:app’
这其中,gunicorn 是一个Python的http服务器,在函数实例第一次被初始化时会执行如下的命令,并且这条命令最终会将代码路径下的server.py文件启动起来。
gunicorn -c gunicorn_conf.py server:app
我们再看server.py的代码,会发现其实他本质上就是一个http服务。
@app.route(‘/invoke’, methods=[‘POST’]) def event_invoke(): rid = request.headers.get(REQUEST_ID_HEADER) print(“FC Invoke Start RequestId: “ + rid) data = request.stream.read() print(data) try: /# do your things, for example: evt = json.loads(data) print(evt) except Exception as e: exc_info = sys.exc_info() trace = traceback.format_tb(exc_info[2]) errRet = { “message”: str(e), “stack”: trace } print(errRet) print(“FC Invoke End RequestId: “ + rid + “, Error: Unhandled function error”) return errRet, 404, [(“x-fc-status”, “404”)] print(“FC Invoke End RequestId: “ + rid) return data
当你在控制台或者开发工具执行调用时,最终就会调用/invoke这个接口,来实现你的业务逻辑。在try结构下,你可以直接调用一个定义好的函数,我这里只是简单地将event事件进行了打印而已。
然后,我们依次按照通过build、deploy等代码部署到云端,最后,可以通过invoke命令调用。下面,是我们体验的结果: $ s invoke -e ‘{“key”:”value”}’ ========= FC invoke Logs begin ========= FC Invoke Start RequestId: 5c44f71b-eadb-4bbf-8969-396ecf4e25a4 b’{“key”:”value”}’ {‘key’: ‘value’} FC Invoke End RequestId: 5c44f71b-eadb-4bbf-8969-396ecf4e25a4 21.0.0.1 - - [27/Jun/2022:07:17:14 +0000] “POST /invoke HTTP/1.1” 200 15 “-“ “Go-http-client/1.1” Duration: 2.60 ms, Billed Duration: 3 ms, Memory Size: 1536 MB, Max Memory Used: 80.95 MB ========= FC invoke Logs end =========
你会发现,调用结果和常规的运行时执行基本没有区别。
当然,我们还是登录云端的控制台来看一下进程状态,可以发现最终是由gunicorn启动的server在提供http 服务。 root@c-62ca6e0c-3721605419294647aac9:/code/# ps -ef UID PID PPID C STIME TTY TIME CMD root 1 0 4 06:13 pts/0 00:00:00 /usr/local/bin/python /code/.s/python/bin/gunicorn -c gunicorn_conf.py server:app root 4 1 3 06:13 pts/0 00:00:00 /usr/local/bin/python /code/.s/python/bin/gunicorn -c gunicorn_conf.py server:app root 5 1 3 06:13 pts/0 00:00:00 /usr/local/bin/python /code/.s/python/bin/gunicorn -c gunicorn_conf.py server:app root 11 0 0 06:13 ? 00:00:00 /bin/sh -c cd /code > /dev/null 2>&1 && COLUMNS=167; export COLUMNS; LINES=27; export LINES; TERM=xterm-256color; expor root 12 11 0 06:13 ? 00:00:00 /bin/sh -c cd /code > /dev/null 2>&1 && COLUMNS=167; export COLUMNS; LINES=27; export LINES; TERM=xterm-256color; expor root 13 12 0 06:13 ? 00:00:00 /usr/bin/script -q -c /bin/bash /dev/null root 14 13 0 06:13 pts/0 00:00:00 sh -c /bin/bash root 15 14 0 06:13 pts/0 00:00:00 /bin/bash root 17 15 0 06:13 pts/0 00:00:00 ps -ef
通过这种方式,你应该已经明白,运行时的实现机制和执行流程其实是一样的,只是基于不同的语言类型和本身的特性,编码的方式不一样而已。
小结
今天我以不同的方式带你了解了Python运行时的运行流程,在这期间,也跟你分享了一个查看函数计算实例中运行情况的方法——在代码中注入命令。
通过这两节课程的介绍,我们可以总结出来,运行时主要做的是这三件事:
- 获取请求信息;
- 关联用户代码;
- 调用用户代码处理请求。
这里我们要注意的是,在获取请求信息时,通常都是从单机侧的约定接口或管道获取,在获取请求后,可以通过反射机制获取到用户代码的入口信息,最后再调用。
如果只考虑最简单的运行流程,运行时中甚至不需要做一些复杂的类型转换工作(如反射机制等),只需要像自定义运行时中的例子一样,定义好函数实例启动的执行命令,并提供一个简单的http服务即可。
希望你通过这节课程,对函数计算形态下的语言运行时有一定的了解,不仅会用,更知道它是如何实现的。在后续遇到问题和开发更复杂的功能时,能够做到心中有数。
思考题
好了,这节课到这里也就结束了,最后我给你留了一个思考题。
你的场景用自定义运行时的时候多么?有遇到过哪些问题吗?又是如何解决的呢?
欢迎在留言区写下你的思考和答案,我们一起交流讨论。感谢你的阅读,也欢迎你把这节课分享给更多的朋友一起交流学习。
参考资料
https://learn.lianglianglee.com/%e4%b8%93%e6%a0%8f/Serverless%e8%bf%9b%e9%98%b6%e5%ae%9e%e6%88%98%e8%af%be/08%20%e8%bf%90%e8%a1%8c%e6%97%b6%ef%bc%88%e4%b8%8b%ef%bc%89%ef%bc%9a%e4%b8%8d%e5%90%8c%e8%af%ad%e8%a8%80%e5%bd%a2%e6%80%81%e4%b8%8b%e7%9a%84%e5%87%bd%e6%95%b0%e5%9c%a8%e5%ae%b9%e5%99%a8%e4%b8%ad%e6%98%af%e5%a6%82%e4%bd%95%e6%89%a7%e8%a1%8c%e7%9a%84%ef%bc%9f.md
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
