18 路由引擎:如何实现数据访问的分片路由和广播路由?
在上一课时中,我们看到起到承上启下作用的 ShardingRouter 会调用 RoutingEngine 获取路由结果,而在 ShardingSphere 中存在多种不同类型的 RoutingEngine,分别针对不同的应用场景。
我们可以按照是否携带分片键信息将这些路由方式分成两大类,即分片路由和广播路由,而这两类路由中又存在一些常见的 RoutingEngine 实现类型,如下图所示:
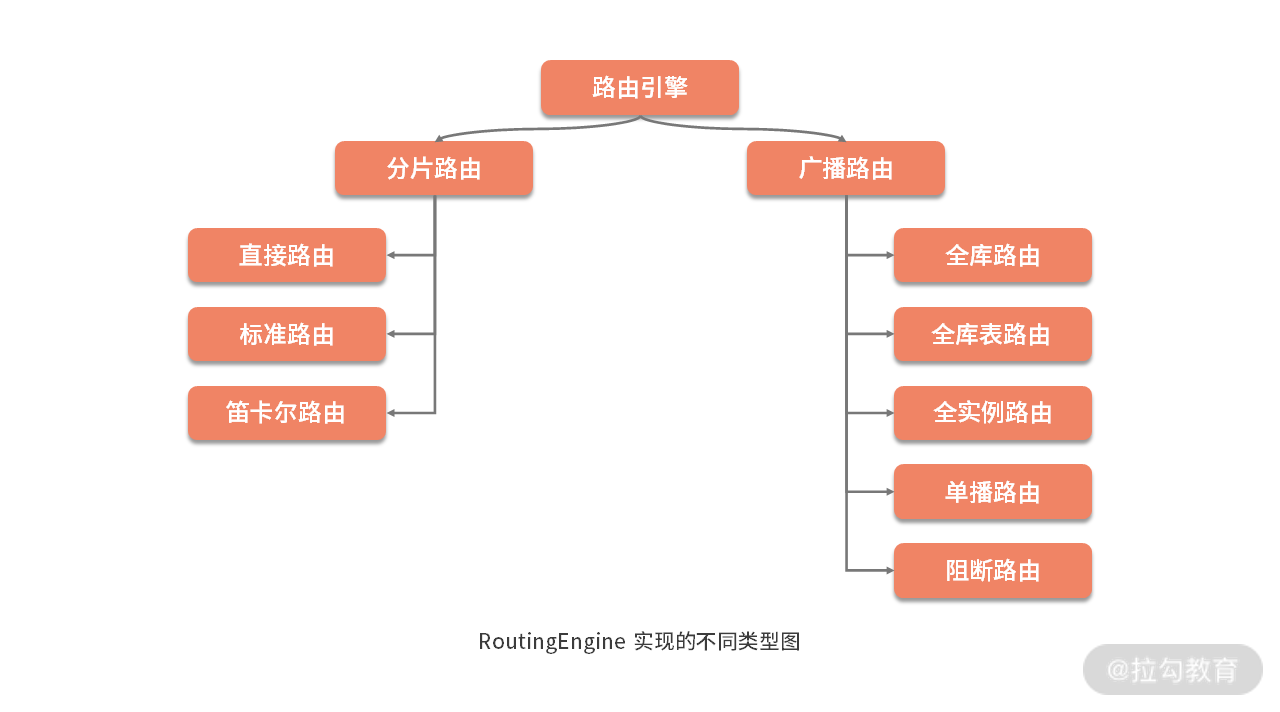
我们无意对所有这些 RoutingEngine 进行详细 的 展开,但在接下来的内容中,我们会分别对分片路由和广播路由中具有代表性的 RoutingEngine 进行讨论。
分片路由
对于分片路由而言,我们将重点介绍标准路由,标准路由是 ShardingSphere 推荐使用的分片方式。
在使用过程中,我们需要首先考虑标准路由的适用范围。标准路由适用范围有两大场景:一种面向不包含关联查询的 SQL;另一种则适用于仅包含绑定表关联查询的 SQL。前面一种场景比较好理解,而针对后者,我们就需要引入绑定表这个 ShardingSphere 中的重要概念。
| 关于绑定表,我们已经在 [《06 |
数据分片:如何实现分库、分表、分库+分表以及强制路由(上)?》]中进行了讨论,在明确了这些概念之后,我们来看标准路由的具体实现过程。 |
1.StandardRoutingEngine 的创建过程
明确了标准路由的基本含义之后,我们回顾一下上一课时中介绍的工厂类 RoutingEngineFactory。RoutingEngineFactory 类根据上下文中的路由信息构建对应的 RoutingEngine,但在其 newInstance 方法中,我们并没有发现直接创建StandardRoutingEngine 的代码。事实上,StandardRoutingEngine 的创建是在 newInstance 方法中的最后一个代码分支,即当所有前置的判断都不成立时会进入到最后的 getShardingRoutingEngine 代码分支中,如下所示:
private static RoutingEngine getShardingRoutingEngine(final ShardingRule shardingRule, final SQLStatementContext sqlStatementContext, final ShardingConditions shardingConditions, final Collection tableNames) { //根据分片规则获取分片表 Collection shardingTableNames = shardingRule.getShardingLogicTableNames(tableNames); //如果目标表只要一张,或者说目标表都是绑定表关系,则构建StandardRoutingEngine if (1 == shardingTableNames.size() || shardingRule.isAllBindingTables(shardingTableNames)) { return new StandardRoutingEngine(shardingRule, shardingTableNames.iterator().next(), sqlStatementContext, shardingConditions); } //否则构建ComplexRoutingEngine return new ComplexRoutingEngine(shardingRule, tableNames, sqlStatementContext, shardingConditions); }
这段代码首先根据解析出来的逻辑表获取分片表,以如下所示的 SQL 语句为例:
SELECT record.remark_name FROM health_record record JOIN health_task task ON record.record_id=task.record_id WHERE record.record_id = 1
那么 shardingTableNames 应该为 health_record 和 health_task。如果分片操作只涉及一张表,或者涉及多张表,但这些表是互为绑定表的关系时,则使用 StandardRoutingEngine 进行路由。
基于绑定表的概念,当多表互为绑定表关系时,每张表的路由结果是相同的,所以只要计算第一张表的分片即可;反之,如果不满足这一条件,则构建一个 ComplexRoutingEngine 进行路由。
这里我们来看一下代码中的 isAllBindingTables 方法如何对多表互为绑定表关系进行判定,该方法位于 ShardingRule 中,如下所示:
public boolean isAllBindingTables(final Collection logicTableNames) { if (logicTableNames.isEmpty()) { return false; } //通过传入的logicTableNames构建一个专门的BindingTableRule Optional bindingTableRule = findBindingTableRule(logicTableNames); if (!bindingTableRule.isPresent()) { return false; } Collection result = new TreeSet<>(String.CASE_INSENSITIVE_ORDER); //获取BindingTableRule中的LogicTable result.addAll(bindingTableRule.get().getAllLogicTables()); //判断获取的LogicTable是否与传入的logicTableNames一致 return !result.isEmpty() && result.containsAll(logicTableNames); }
这段代码会通过传入的 logicTableNames 构建一个专门的 BindingTableRule,然后看最终获取的 BindingTableRule 中的 LogicTable 是否与传入的 logicTableNames 一致。这里构建 BindingTableRule 的过程实际上是根据传入的 logicTableName 来从 ShardingRule 中自身保存的 Collection
获取对应的 BindingTableRule,如下所示:
public Optional findBindingTableRule(final String logicTableName) { for (BindingTableRule each : bindingTableRules) { if (each.hasLogicTable(logicTableName)) { return Optional.of(each); } } return Optional.absent(); }
上述代码的 bindingTableRules 就是 ShardingRule 中自身保存的 BindingTableRule 集合,我们在 ShardingRule 构造函数中发现了初始化 bindingTableRules 的代码,如下所示:
bindingTableRules = createBindingTableRules(shardingRuleConfig.getBindingTableGroups());
显然,这个构建过程与规则配置机制有关。如果基于 Yaml 配置文件,绑定表的配置一般会采用如下形式:
shardingRule: bindingTables: health_record,health_task
针对这种配置形式,ShardingRule 会对其进行解析并生成 BindingTableRule 对象,如下所示:
private BindingTableRule createBindingTableRule(final String bindingTableGroup) { List tableRules = new LinkedList<>(); for (String each : Splitter.on(",").trimResults().splitToList(bindingTableGroup)) { tableRules.add(getTableRule(each)); } return new BindingTableRule(tableRules); }
至此,我们终于把绑定表相关的概念以及实现方式做了介绍,也就是说完成了 RoutingEngineFactory 中进入到 StandardRoutingEngine 这条代码分支的介绍。
### 2.StandardRoutingEngine 的运行机制
现在,我们已经创建了 StandardRoutingEngine,接下来就看它的运行机制。作为一种具体的路由引擎实现方案,StandardRoutingEngine 实现了 RoutingEngine 接口,它的 route 方法如下所示:
@Override public RoutingResult route() { … return generateRoutingResult(getDataNodes(shardingRule.getTableRule(logicTableName))); }
这里的核心方法就是 generateRoutingResult,在此之前需要先通过 getDataNodes 方法来获取数据节点信息,该方法如下所示:
private Collection getDataNodes(final TableRule tableRule) { //如基于Hint进行路由 if (isRoutingByHint(tableRule)) { return routeByHint(tableRule); } //基于分片条件进行路由 if (isRoutingByShardingConditions(tableRule)) { return routeByShardingConditions(tableRule); } //执行混合路由 return routeByMixedConditions(tableRule); }
我们看到这个方法的入参是一个 TableRule 对象,而 TableRule 属于分片规则 ShardingRule 中的一部分。我们在上一课时中知道该对象主要保存着与分片相关的各种规则信息,其中就包括 ShardingStrategy。从命名上看,ShardingStrategy 属于一种分片策略,用于指定分片的具体 Column,以及执行分片并返回目标 DataSource 和 Table。
这部分内容我们会在下一课时中进行展开。这里,我们先梳理与 ShardingStrategy 相关的类结构,如下所示:
