Hash
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出就是散列值。根据散列值作为地址存放数据,这种转换是一种压缩映射,简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。查找关键字数据(如K)的时候,若结构中存在和关键字相等的记录,则必定在f(K)的存储位置上。由此,不需比较便可直接取得所查记录。我们称这个对应关系f为散列函数(Hash function),按这个事件建立的表为散列表。
综上所述,根据散列函数f(key)和处理冲突的方法将一组关键字映象到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“象” 作为记录在表中的存储位置,这种表便称为散列表,这一映象过程称为散列造表或散列,所得的存储位置称散列地址。
Hash冲突
对不同的关键字可能得到同一散列地址,即key1≠key2,而f(key1)=f(key2),这种现象称hash冲突。
即:key1通过f(key1)得到散列地址去存储key1,同理,key2发现自己对应的散列地址已经被key1占据了。
解决办法(总共有四种):
-
开放地址
-
再哈希
-
链地址
-
建立公共溢出区
其中开放地址又分为:
-
线性探测再散列
-
二次探测再散列
-
伪随机探测再散列
开放寻址法
所谓的开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入 。
开放寻址法:Hi=(H(key) + di) MOD m,i=1,2,…,k(k<=m-1),其中H(key)为散列函数,m为散列表长,di为增量序列,可有下列三种取法:
1). di=1,2,3,…,m-1,称线性探测再散列;
2). di=1^2,(-1)^2,2^2,(-2)^2,(3)^2,…,±(k)^2,(k<=m/2)称二次探测再散列;
3). di=伪随机数序列,称伪随机探测再散列。
用开放定址法解决冲突的做法是:当冲突发生时,使用某种探测技术(线性探测法、二次探测法(解决线性探测的堆积问题)、随机探测法(和二次探测原理一致,不一样的是:二次探测以定值跳跃,而随机探测的散列地址跳跃长度是不定值))在散列表中形成一个探测序列。
沿此序列逐个单元地查找,直到找到给定的关键字,或者碰到一个开放的地址(即该地址单元为空)为止插入即可。
例子
比如说,我们的关键字集合为{12,67,56,16,25,37,22,29,15,47,48,34},表长为12。
我们用散列函数f(key) = key mod l2
当计算前S个数{12,67,56,16,25}时,都是没有冲突的散列地址,直接存入:

计算key = 37时,发现f(37) = 1,此时就与25所在的位置冲突。
于是我们应用上面的公式f(37) = (f(37)+1) mod 12 = 2。
于是将37存入下标为2的位置:

再哈希
再哈希法又叫双哈希法,有多个不同的Hash函数,当发生冲突时,使用第二个,第三个,….,等哈希函数去计算地址,直到无冲突。
虽然不易发生聚集,但是增加了计算时间。
链地址法(Java hashmap就是这么做的)
链地址法的基本思想是:每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,将所有关键字为同义词的结点链接在同一个单链表中,
例子
如:
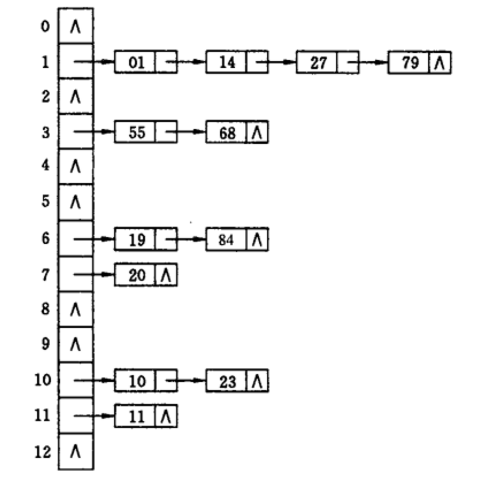
设有 m = 5 , H(K) = K mod 5 ,关键字值序例 5 , 21 , 17 , 9 , 15 , 36 , 41 , 24 ,按外链地址法所建立的哈希表如下图所示:
建立公共溢出区
建立公共溢出区的基本思想是:假设哈希函数的值域是 [1,m-1],则设向量 HashTable[0...m-1] 为基本表,
每个分量存放一个记录,另外设向量 OverTable[0...v] 为溢出表,所有关键字和基本表中关键字为同义词的记录,不管它们由哈希函数得到的哈希地址是什么,一旦发生冲突,都填入溢出表。
拓展阅读
参考资料
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
