Bytecode 字节码指令
本文分为三部分,每一部分都分成几个小节。
每个小节都可以单独阅读,不过由于一些概念是逐步建立起来的,如果你依次阅读完所有章节会更简单一些。
每一节都会覆盖到Java代码中的不同结构,并详细介绍了它们是如何编译并执行的。
变量
局部变量
JVM是一个基于栈的架构。方法执行的时候(包括main方法),在栈上会分配一个新的帧,这个栈帧包含一组局部变量。
这组局部变量包含了方法运行过程中用到的所有变量,包括this引用,所有的方法参数,以及其它局部定义的变量。
对于类方法(也就是static方法)来说,方法参数是从第0个位置开始的,而对于实例方法来说,第0个位置上的变量是this指针。
局部变量可以是以下这些类型:
-
char
-
long
-
short
-
int
-
float
-
double
-
引用
-
返回地址
除了long和double类型外,每个变量都只占局部变量区中的一个变量槽(slot),而long及double会占用两个连续的变量槽,因为这些类型是64位的。
当一个新的变量创建的时候,操作数栈(operand stack)会用来存储这个新变量的值。然后这个变量会存储到局部变量区中对应的位置上。如果这个变量不是基础类型的话,本地变量槽上存的就只是一个引用。这个引用指向堆的里一个对象。
比如:
int i = 5;
编译后就成了
0: bipush 5
2: istore_0
- bipush
用来将一个字节作为整型数字压入操作数栈中,在这里5就会被压入操作数栈上。
- istore_0
这是istore_这组指令集(译注:严格来说,这个应该叫做操作码,opcode ,指令是指操作码加上对应的操作数,oprand。
不过操作码一般作为指令的助记符,这里统称为指令)中的一条,这组指令是将一个整型数字存储到本地变量中。
n代表的是局部变量区中的位置,并且只能是0,1,2,3。再多的话只能用另一条指令istore了,这条指令会接受一个操作数,对应的是局部变量区中的位置信息。
指令执行时的内存布局
这条指令执行的时候,内存布局是这样的:
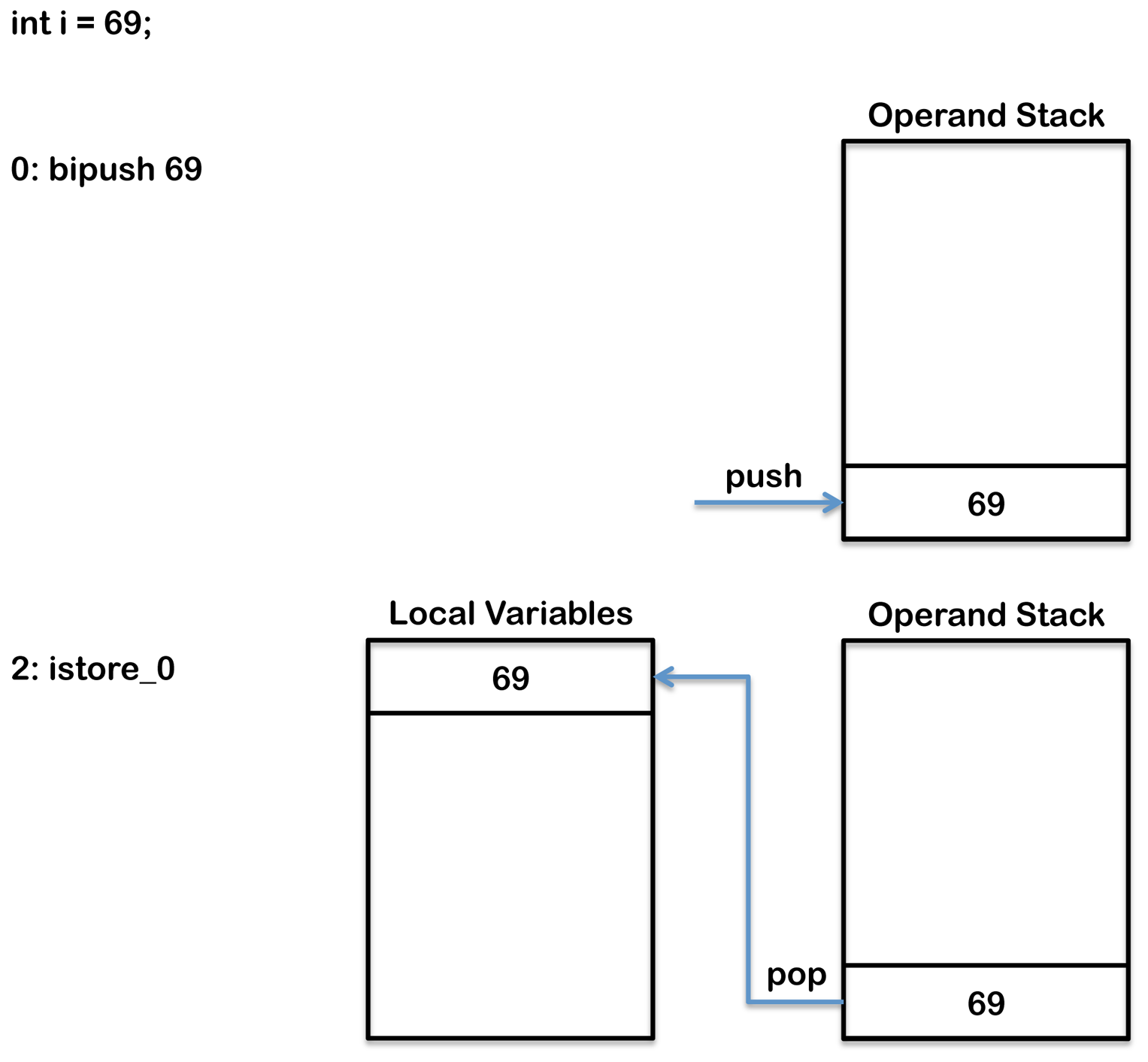
class文件中的每一个方法都会包含一个局部变量表,如果这段代码在一个方法里面的话,你会在类文件的局部变量表中发现如下的一条记录。
LocalVariableTable:
Start Length Slot Name Signature
0 1 1 i I
字段
Java类里面的字段是作为类对象实例的一部分,存储在堆里面的(类变量对应存储在类对象里面)。
关于字段的信息会添加到类文件里的field_info数组里,像下面这样:
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info contant_pool[constant_pool_count – 1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
另外,如果变量被初始化了,那么初始化的字节码会加到构造方法里。
下面这段代码编译了之后:
public class SimpleClass {
public int simpleField = 100;
}
如果你用javap进行反编译,这个被添加到了field_info数组里的字段会多出一段描述信息。
public int simpleField;
Signature: I
flags: ACC_PUBLIC
初始化变量的字节码会被加到构造方法里,像下面这样:
public SimpleClass();
Signature: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: aload_0
5: bipush 100
7: putfield #2 // Field simpleField:I
10: return
参数详解
- aload_0
从局部变量数组中加载一个对象引用到操作数栈的栈顶。尽管这段代码看起来没有构造方法,
但是在编译器生成的默认的构造方法里,就会包含这段初始化的代码。第一个局部变量正好是this引用,
于是aload_0把this引用压到操作数栈中。aload_0是aload_指令集中的一条,这组指令会将引用加载到操作数栈中。
n对应的是局部变量数组中的位置,并且也只能是0,1,2,3。还有类似的加载指令,它们加载的并不是对象引用,
比如iload_,lload_,fload_,和dload_, 这里i代表int,l代表long,f代表float,d代表double。
局部变量的在数组中的位置大于3的,得通过iload,lload,fload,dload,和aload进行加载,
这些指令都接受一个操作数,它代表的是要加载的局部变量的在数组中的位置。
- invokespecial
这条指令可以用来调用对象实例的构造方法,私有方法和父类中的方法。
它是方法调用指令集中的一条,其它的还有invokedynamic, invokeinterface, invokespecial, invokestatic, invokevirtual.
这里的invokespecial指令调用的是父类也就是java.lang.Object的构造方法。
- bipush
它是用来把一个字节作为整型压到操作数栈中的,在这里100会被压到操作数栈里。
- putfield
它接受一个操作数,这个操作数引用的是运行时常量池里的一个字段,在这里这个字段是simpleField。
赋给这个字段的值,以及包含这个字段的对象引用,在执行这条指令的时候,都 会从操作数栈顶上pop出来。
前面的aload_0指令已经把包含这个字段的对象压到操作数栈上了,而后面的bipush又把100压到栈里。
最后putfield指令会将这两个值从栈顶弹出。执行完的结果就是这个对象的simpleField这个字段的值更新成了100。
内存执行过程
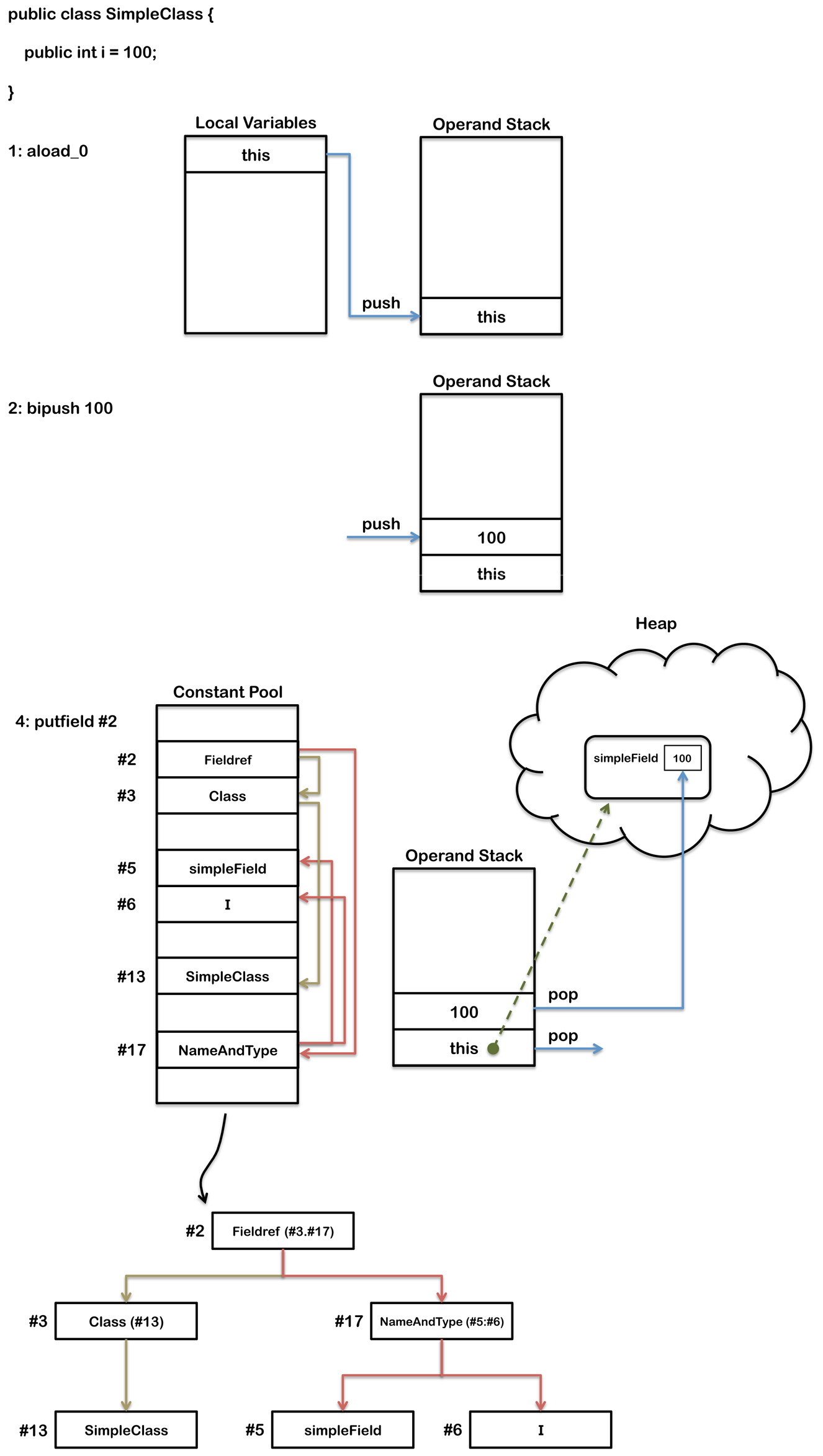
这里的putfield指令的操作数引用的是常量池里的第二个位置。JVM会为每个类型维护一个常量池,
运行时的数据结构有点类似一个符号表,尽管它包含的信息更多。Java中的字节码操作需要对应的数据,
但通常这些数据都太大了,存储在字节码里不适合,它们会被存储在常量池里面,
而字节码包含一个常量池里的引用 。当类文件生成的时候,其中的一块就是常量池:
Constant pool:
#1 = Methodref #4.#16 // java/lang/Object."<init>":()V
#2 = Fieldref #3.#17 // SimpleClass.simpleField:I
#3 = Class #13 // SimpleClass
#4 = Class #19 // java/lang/Object
#5 = Utf8 simpleField
#6 = Utf8 I
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 LocalVariableTable
#12 = Utf8 this
#13 = Utf8 SimpleClass
#14 = Utf8 SourceFile
#15 = Utf8 SimpleClass.java
#16 = NameAndType #7:#8 // "<init>":()V
#17 = NameAndType #5:#6 // simpleField:I
#18 = Utf8 LSimpleClass;
#19 = Utf8 java/lang/Object
常量字段(类常量)
带有final标记的常量字段在class文件里会被标记成ACC_FINAL.
public class SimpleClass {
public final int simpleField = 100;
}
字段的描述信息会标记成ACC_FINAL:
public static final int simpleField = 100;
Signature: I
flags: ACC_PUBLIC, ACC_FINAL
ConstantValue: int 100
对应的初始化代码并不变
静态变量
带有static修饰符的静态变量则会被标记成ACC_STATIC:
public static int simpleField;
Signature: I
flags: ACC_PUBLIC, ACC_STATIC
不过在实例的构造方法中却再也找不到对应的初始化代码了。
因为static变量会在类的构造方法中进行初始化,并且它用的是putstatic指令而不是putfiled。
static {};
Signature: ()V
flags: ACC_STATIC
Code:
stack=1, locals=0, args_size=0
0: bipush 100
2: putstatic #2 // Field simpleField:I
5: return
条件语句
像if-else, switch这样的流程控制的条件语句,是通过用一条指令来进行两个值的比较,然后根据结果跳转到另一条字节码来实现的。
循环语句包括for循环,while循环,它们的实现方式也很类似,但有一点不同,它们通常都会包含一条goto指令,以便字节码实现循环执行。
do-while循环不需要goto指令,因为它的条件分支是在字节码的末尾。更多细节请参考循环语句一节。
有一些指令可以用来比较两个整型或者两个引用,然后执行某个分支,这些操作都能在单条指令里面完成。
而像double,float,long这些值需要两条指令。首先得去比较两个值,然后根据结果,会把1,0或者-1压到栈里。最后根据栈顶的值是大于,等于或者小于0来判断应该跳转到哪个分支。
我们先来介绍下if-else语句,然后再详细介绍下分支跳转用到的几种不同的指令。
if-else
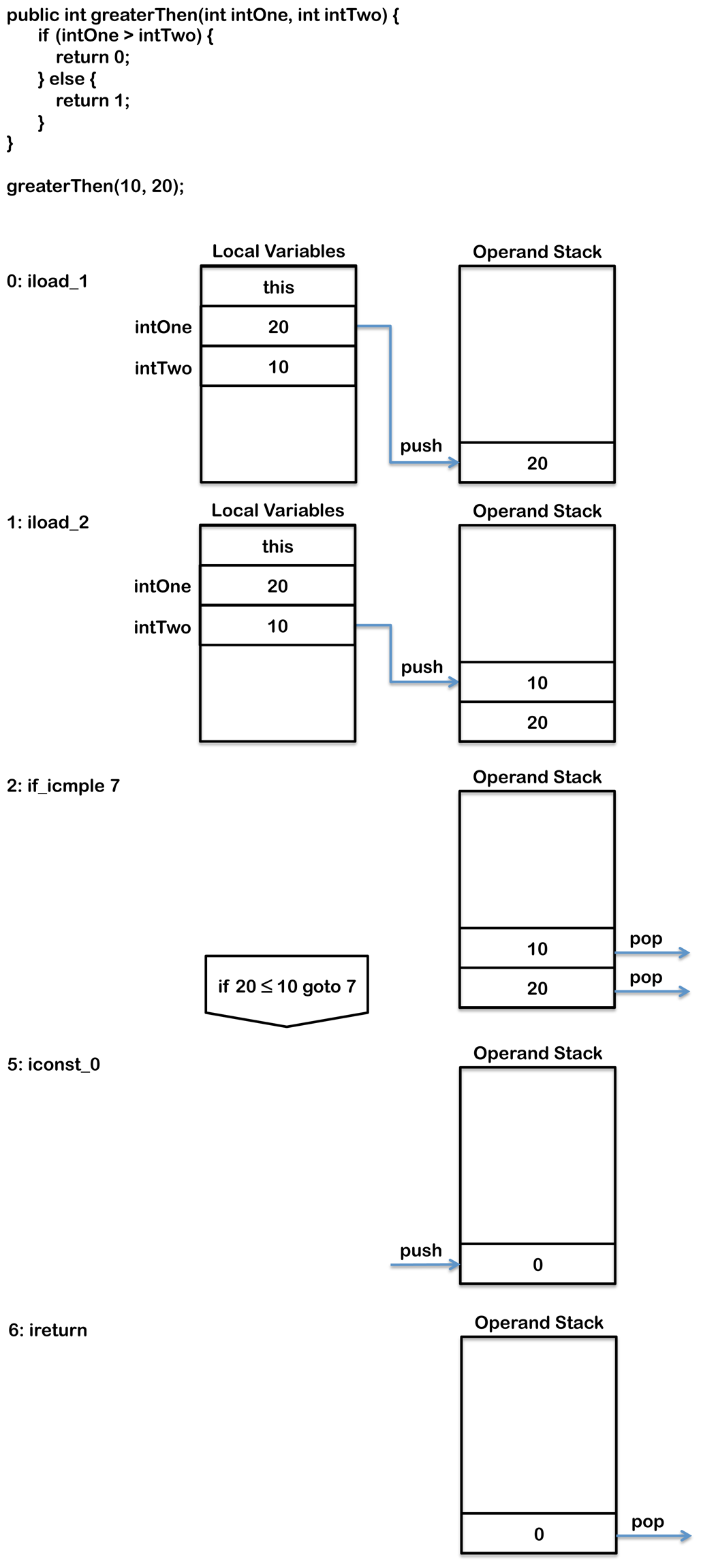
下面的这个简单的例子是用来比较两个整数的:
public int greaterThen(int intOne, int intTwo) {
if (intOne > intTwo) {
return 0;
} else {
return 1;
}
}
方法最后会编译成如下的字节码:
0: iload_1
1: iload_2
2: if_icmple 7
5: iconst_0
6: ireturn
7: iconst_1
8: ireturn
首先,通过iload_1, iload_2两条指令将两个入参压入操作数栈中。if_icmple会比较栈顶的两个值的大小。
如果intOne小于或者等于intTwo的话,会跳转到第7行处的字节码来执行。
可以看到这里和Java代码里的if语句的条件判断正好相反,这是因为在字节码里面,判断条件为真的话会跑到else分支里面去执行,而在Java代码里,判断为真会进入if块里面执行。
换言之,if_icmple判断的是如果if条件不为真,然后跳过if块。if代码块里对应的代码是5,6处的字节码,而else块对应的是7,8处的。
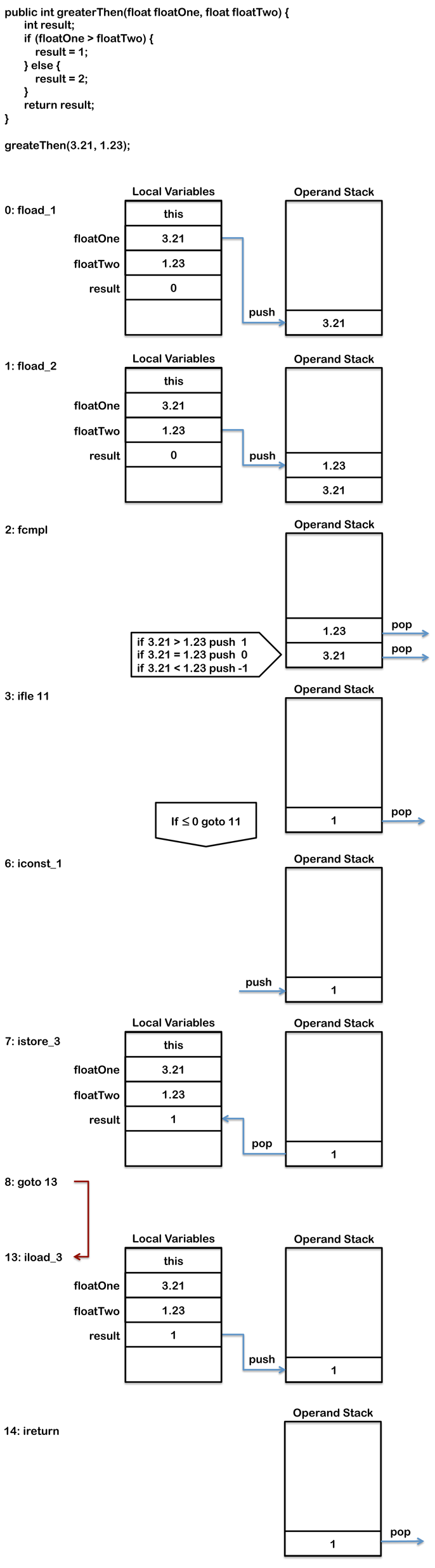
多次比较
下面的代码则稍微复杂了一点,它需要进行两次比较。
public int greaterThen(float floatOne, float floatTwo) {
int result;
if (floatOne > floatTwo) {
result = 1;
} else {
result = 2;
}
return result;
}
编译后会是这样:
0: fload_1
1: fload_2
2: fcmpl
3: ifle 11
6: iconst_1
7: istore_3
8: goto 13
11: iconst_2
12: istore_3
13: iload_3
14: ireturn
在这个例子中,首先两个参数会被fload_1和fload_2指令压入栈中。
和上面那个例子不同的是,这里需要比较两回。
fcmple先用来比较栈顶的floatOne和floatTwo,然后把比较的结果压入操作数栈中。
* floatOne > floatTwo –> 1
* floatOne = floatTwo –> 0
* floatOne < floatTwo –> -1
* floatOne or floatTwo = NaN –> 1
然后通过ifle进行判断,如果前面fcmpl的结果是< =0的话,则跳转到11行处的字节码去继续执行。
这个例子还有一个地方和前面不同的是,它只在方法末有一个return语句,因此在if代码块的最后,会有一个goto语句来跳过else块。
goto语句会跳转到第13条字节码处,然后通过iload_3将存储在局部变量区第三个位置的结果压入栈中,然后就可以通过return指令将结果返回了。
除了比较数值的指令外,还有比较引用是否相等的(==),以及引用是否等于null的(== null或者!=null),以及比较对象的类型的(instanceof)。
常见参数
if_icmp<cond>
这组指令用来比较操作数栈顶的两个整数,然后跳转到新的位置去执行。
<cond> 可以是:eq-等于,ne-不等于,lt-小于,le-小于等于,gt-大于, ge-大于等于。
if_acmp<cond>
这两个指令用来比较对象是否相等,然后根据操作数指定的位置进行跳转。
ifnonnull ifnull
这两个指令用来判断对象是否为null,然后根据操作数指定的位置进行跳转。
lcmp
这个指令用来比较栈顶的两个长整型,然后将结果值压入栈中: 如果value1>value2,压入1,如果value1==value2,压入0,如果 value1<value2 压入-1.
fcmp<cond> l g dcomp<cond>
这组指令用来比较两个float或者double类型的值,然后然后将结果值压入栈中:如果value1>value2,压入1,如果value1==value2,压入0,
如果value1<value2压入-1. 指令可以以l或者g结尾,不同之处在于它们是如何处理NaN的。
fcmpg和dcmpg指令把整数1压入操作数栈,而fcmpl和dcmpl把-1压入操作数栈。
这确保了比较两个值的时候,如果其中一个不是数字(Not A Number, NaN),比较的结果不会相等。
比如判断if x > y(x和y都是浮点数),就会用的fcmpl,如果其中一个值是NaN的话,-1会被压入栈顶,下一条指令则是ifle,如果分支小于0则跳转。
因此如果有一个是NaN的话,ifle会跳过if块,不让它执行。
- instanceof
如果栈顶对象的类型是指定的类的话,则将1压入栈中。这个指令的操作数指定的是某个类型在常量池的序号。如果对象为空或者不是对应的类型,则将0压入操作数栈中。
if<cond>
将栈顶值和0进行比较,如果条件为真,则跳转到指定的分支继续执行。这些指令通常用于较复杂的条件判断中,在一些单条指令无法完成的情况。比如验证方法调用的返回值。
switch语句
Java switch表达式的类型只能是char,byte,short,int,Character, Byte, Short,Integer,String或者enum。
JVM为了支持switch语句,用了两个特殊的指令,叫做tableSwitch和lookupswitch,它们都只能操作整型数值。
只能使用整型并不影响,因为char,byte,short和enum都可以提升成int类型。
Java7开始支持String类型,下面我们会介绍到。
tableswitch操作会比较快一些,不过它消耗的内存会更多。tableswitch会列出case分支里面最大值和最小值之间的所有值,如果判断的值不在这个范围内则直接跳转到default块执行,case中没有的值也会被列出,不过它们同样指向的是default块。
拿下面的这个switch语句作为例子:
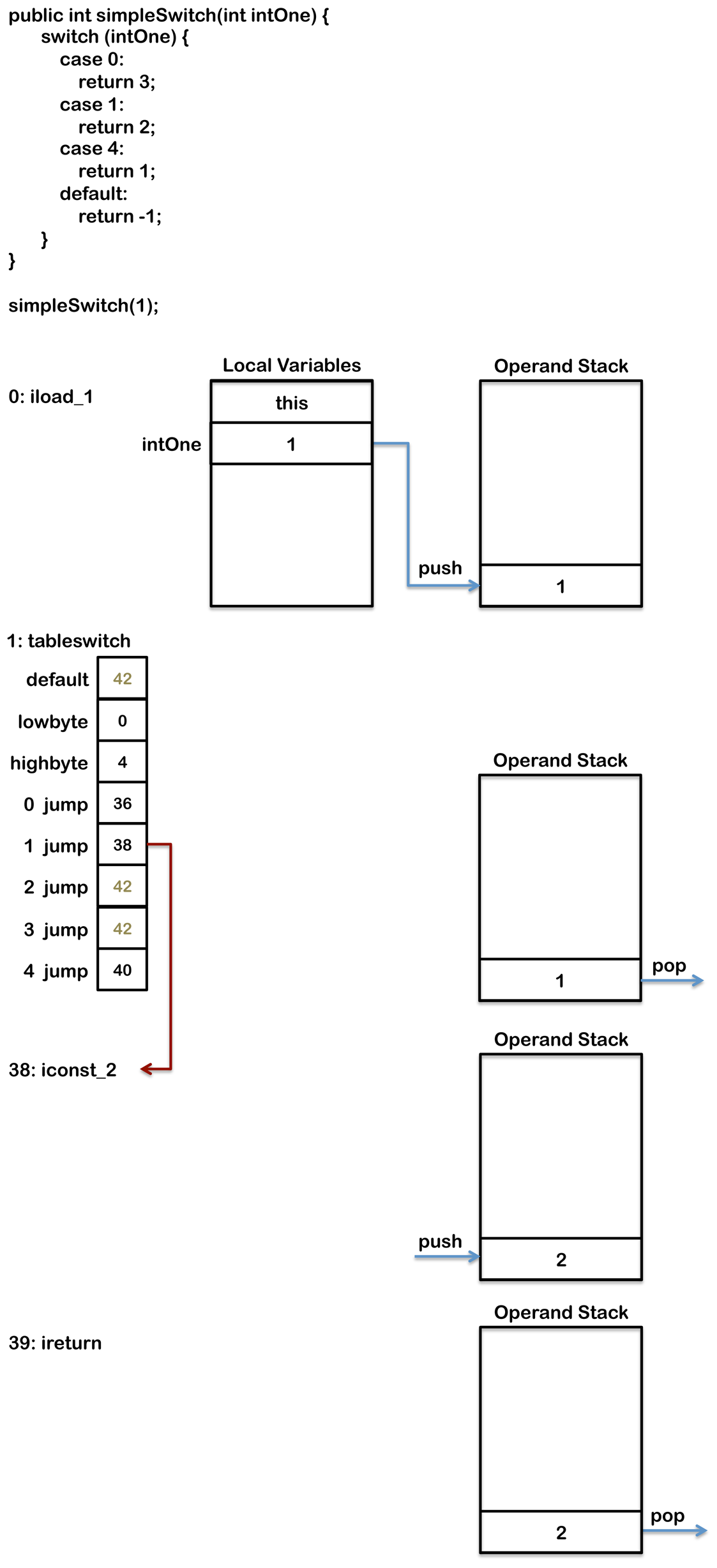
public int simpleSwitch(int intOne) {
switch (intOne) {
case 0:
return 3;
case 1:
return 2;
case 4:
return 1;
default:
return -1;
}
}
编译后会生成如下的字节码
0: iload_1
1: tableswitch {
default: 42
min: 0
max: 4
0: 36
1: 38
2: 42
3: 42
4: 40
}
36: iconst_3
37: ireturn
38: iconst_2
39: ireturn
40: iconst_1
41: ireturn
42: iconst_m1
43: ireturn
tableswitch指令里0,1,4的值和代码里的case语句一一对应,它们指向的是对应代码块的字节码。
tableswitch指令同样有2,3的值,但代码中并没有对应的case语句,它们指向的是default代码块。
当这条指令执行的时候,会判断操作数栈顶的值是否在最大值和最小值之间。
如果不在的话,直接跳去default分支,也就是上面的42行处的字节码。为了确保能找到default分支,它都是出现在tableswitch指令的第一个字节(如果需要内存对齐的话,则在补齐了之后的第一个字节)。
如果栈顶的值在最大最小值的范围内,则用它作为tableswtich内部的索引,定位到应该跳转的分支。比如1的话,就会跳转至38行处继续执行。
执行过程
下图会演示这条指令是如何执行的:
lookupswitch
如果case语句里面的值取值范围太广了(也就是太分散了)这个方法就不太好了,因为它占用的内存太多了。
因此当switch的case条件里面的值比较分散的时候,就会使用lookupswitch指令。
这个指令会列出case语句里的所有跳转的分支,但它没有列出所有可能的值。
当执行这条指令的时候,栈顶的值会和lookupswitch里的每个值进行比较,来确定要跳转的分支。
执行lookupswitch指令的时候,JVM会在列表中查找匹配的元素,这和tableswitch比起来要慢一些,因为tableswitch直接用索引就定位到正确的位置了。
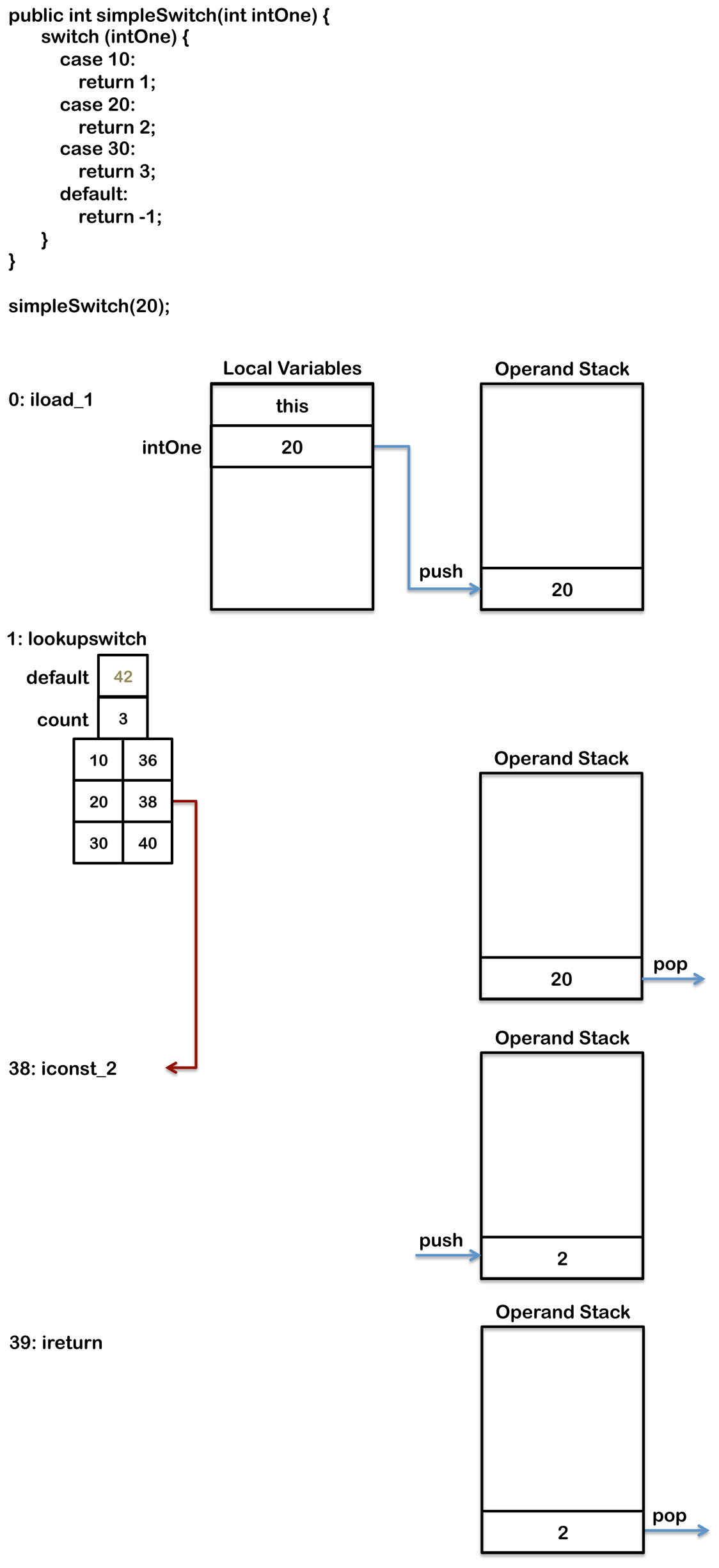
当switch语句编译的时候,编译器必须去权衡内存的使用和性能的影响,来决定到底该使用哪条指令。下面的代码,编译器会生成lookupswitch语句
public int simpleSwitch(int intOne) {
switch (intOne) {
case 10:
return 1;
case 20:
return 2;
case 30:
return 3;
default:
return -1;
}
}
生成后的字节码如下:
0: iload_1
1: lookupswitch {
default: 42
count: 3
10: 36
20: 38
30: 40
}
36: iconst_1
37: ireturn
38: iconst_2
39: ireturn
40: iconst_3
41: ireturn
42: iconst_m1
43: ireturn
为了确保搜索算法的高效(得比线性查找要快),这里会提供列表的长度,同时匹配的元素也是排好序的。
下图演示了lookupswitch指令是如何执行的。
执行过程
参考资料
《深入理解 jvm》
- 字节码
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
