业务背景
访问 mongodb 有时候会出现不稳定的情况。
以前使用 v3.4.6 主从复制存在 BUG,所以一直没有使用读写分离。
现在升级到 v4.0,决定使用读写分离并且使用相对稳定的机器环境。
双管齐下,保证系统的稳定性。
mongo的集群方式有三种:
Replica Set(副本集)
其实简单来说就是集群当中包含了多份数据,保证主节点挂掉了,备节点能继续提供数据服务,提供的前提就是数据需要和主节点一致
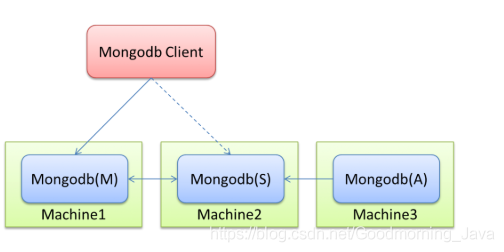
Master-Slaver(主从)
也就是主备,官方已经不推荐使用。
Sharding(分片集群)
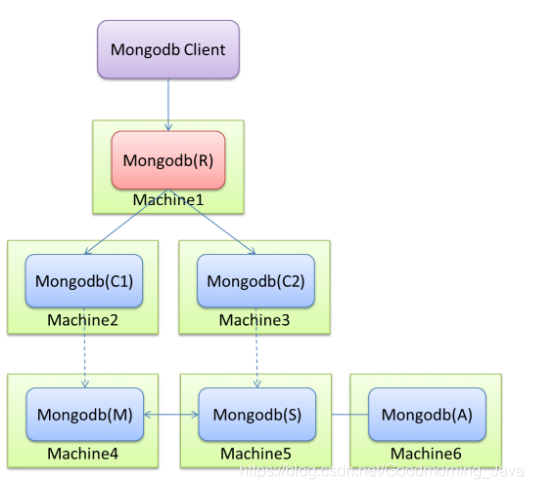
MongoDB 复制集
复制集(Replica Sets)是额外的数据副本,是跨多个服务器同步数据的过程,复制集提供了冗余备份并提高了数据的可用性,通过复制集可以对硬件故障和中断的服务进行恢复。
MongoDB 复制集工作原理
mongodb的复制集至少需要两个节点。
其中一个是主节点(Primary),负责处理客户端请求,其余的都是从节点(Secondary),负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从、一主多从。
主节点记录其上的所有操作到 oplog 中,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
客户端在主节点写入数据,在从节点读取数据,主节点与从节点进行数据交互保障数据的一致性。
如果其中一个节点出现故障,其他节点马上会将业务接过来而无需停机操作。
MongoDB 复制集的特点及优势
复制集的特点
-
N个节点的群集
-
任何节点都可作为主节点
-
所有写入操作都在主节点上
-
自动故障转移
-
自动恢复
复制集的优势:
-
让数据更安全
-
高数据可用性(24x7)
-
灾难恢复
-
无停机维护(如备份、索引重建、故障转移)
-
读缩放(额外的副本读取)
-
副本集对应用程序是透明的
有必要读写分离吗
收益与付出
看过网上有的商城对MongoDB运营的经验,对读写分离的分析是:
是不是可以使用Secondary或者SecondaryPreference实现读写分离来提高系统的承载能力?
1、Secondary节点的写压力跟Primary基本是相同的,所以,读操作在从库上并不会提高查询速度。
2、由于是异步复制数据,所以读Secondary的数据可能是过时的。
3、在分片架构中使用读写分离的时候有可能会丢失数据或者读到重复数据。
数据延迟问题
其实读写分离还是有意义的,关键是要解决同步数据延时问题。
ps:感觉这里的意义,主要是高可用,而不是高性能。
mongodb其实提供了相关的解决方案:
写操作的相关设置:
通过writeConcern指定REPLICA_ACKNOWLEDGED(4,2000),也就是说4台节点全部写确认成功后才返回,设置了2秒的等待超时,可以根据复制集群数来指定节点数和等待超时时间。
我们自己的场景
我们的读写比例基本是 1:1,实际上读写分离并不能带来什么太大的性能提升。
不过如果读写全部放在主库,会导致主库的压力较大。
Mongodb 配置连接
java端配置读写分离
这里,mongo采用的是副本集(Replica Set)的部署方式这里采用的事xml配置文件形式:
read-preference=“SECONDARY_PREFERRED”,这个配置
1
2
3
4
5
6
7
8
9
10
11
12<mongo:mongo-client id="mongo" replica-set="${mongo.replicationSet}">
<mongo:client-options
write-concern="NORMAL"
connections-per-host="${mongo.connectionsPerHost}"
threads-allowed-to-block-for-connection-multiplier="${mongo.threadsAllowedToBlockForConnectionMultiplier}"
connect-timeout="${mongo.connectTimeout}"
read-preference="SECONDARY_PREFERRED"
max-wait-time="${mongo.maxWaitTime}"
socket-keep-alive="${mongo.socketKeepAlive}"
socket-timeout="${mongo.socketTimeout}"
/>
</mongo:mongo-client>
读写分离配置说明
mongodb 复制集对读写分离的支持是通过 Read Preferences 特性进行支持的,这个特性非常复杂和灵活。
应用程序驱动通过read reference来设定如何对复制集进行读写操作,默认客户端驱动所有的读操作都是直接访问primary节点的,从而保证了数据的严格一致性。
支持五种 read preference 模式:
-
primary:主节点,默认模式,读操作只在主节点,如果主节点不可用,报错或者抛出异常。
-
primaryPreferred:首选主节点,大多情况下读操作在主节点,如果主节点不可用,如故障转移,读操作在从节点。
-
secondary:从节点,读操作只在从节点,如果从节点不可用,报错或者抛出异常。
-
secondaryPreferred:首选从节点,大多情况下读操作在从节点,特殊情况(如单主节点架构)读操作在主节点。
-
nearest:最邻近节点,读操作在最邻近的成员,可能是主节点或者从节点。
使用复制集时你需要知道的
主节点不固定
MongoDB复制集里Primary节点是不固定的,当遇到复制集轮转升级、Primary宕机、网络分区等场景时,复制集可能会选举出一个新的Primary,而原来的Primary则会降级为Secondary,即发生主备切换。
总而言之,MongoDB复制集里Primary节点是不固定的,不固定的,不固定的,重要的事情说3遍。
当连接复制集时,如果直接指定Primary的地址来连接,当时可能可以正确读写数据的,但一旦复制集发生主备切换,你连接的Primary会降级为Secondary,你将无法继续执行写操作,这将严重影响到你的线上服务。
所以生产环境千万不要直连Primary,千万不要直连Primary,千万不要直连Primary。
说了这么多,到底该如何连接复制集?
如何正确连接
要正确连接复制集,需要先了解下MongoDB的Connection String URI,所有官方的driver都支持以Connection String的方式来连接MongoDB。
下面就是Connection String包含的主要内容
1mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]]
参数说明
mongodb:// 前缀,代表这是一个Connection String
username:password@ 如果启用了鉴权,需要指定用户密码
hostX:portX 复制集成员的ip:port信息,多个成员以逗号分割
/database 鉴权时,用户帐号所属的数据库
?options 指定额外的连接选项
通过正确的Connection String来连接MongoDB复制集时,客户端会自动检测复制集的主备关系,当主备关系发生变化时,自动将写切换到新的主上,以保证服务的高可用。
常用连接参数
如何实现读写分离?
`
在options里添加 readPreference=secondaryPreferred 即可实现,读请求优先到Secondary节点,从而实现读写分离的功能,更多读选项参考Read preferences
如何限制连接数?
在options里添加 maxPoolSize=xx 即可将客户端连接池限制在xx以内。
如何保证数据写入到大多数节点后才返回?
在options里添加 w=majority 即可保证写请求成功写入大多数节点才向客户端确认,更多写选项参考Write Concern
