背景
基于ClickHouse的Billions2.0日志方案上线后(B站基于Clickhouse的下一代日志体系建设实践),虽然能够降低60%的存储成本,但仍然存在几个比较明显的问题,需要进一步的优化和解决。
一、存储成本的优化
对于大规模的日志数据,存储成本一直是困扰企业的一个问题。我们采用了基于ClickHouse的解决方案,该方案实现了高效的数据编码和压缩率,有效降低了存储成本。
然而,当前ClickHouse日志表数据依赖于双副本方案,存储成本仍有优化空间。
二、提升日志排障能力
日志做为可观测性(logs/metrics/tracing/event)的一环, 一个核心要求是提升排障能力,我们的目标是提升日志排障能力,以支持DevOps中的问题定位和版本比对。
我们致力于提升定位异常日志的速度,并帮助快速发现和定位问题。这样,我们能够满足对快速解决研发需求的追求。
三、存算一体方案的挑战
原生ClickHouse采用的是Share Nothing架构,这种存算一体的方案在不增加计算节点的情况下无法容纳海量的日志数据。
同时对于机型的选择也会更加困难,向B站这边每年的机型都是相对固定,对于日志系统这块一个是很难有相关机型满足(日志存储量远大于需要的计算量),如果用通用机型意味着会存在不必要的资源浪费。
如果使用专用机型,往往会出现类似”过拟合”的效果,如果出现资源不足或者因为优化资源节省,很难做全公司层面资源腾挪,对资源混布也会更加困难。
另外如果简单的走存算一体方案随着资源规模的变大,在追求降本增效的前提下必然会出现存储计算比越来越大的情况,这意味当出现单个节点故障或扩容搬迁等需要副本修复或转移的代价也越来越高。
四、满足业务对于数据复杂处理的诉求
随着用户对日志数据分析需求的增多,复杂的ETL操作变得必要。
现阶段,需要将ClickHouse日志数据导出到分布式文件系统(如HDFS)进行处理,然后再重新导入ClickHouse,导致导入导出的成本较高。
我们的目标是整合离线和在线的数据处理和交互流程,打通公司的整个大数据体系,实现零转换操作。
用户可以直接使用日志平台完成日志的一般查询,对于特别复杂或严重影响日志平台性能的场景可以直接使用大数据套件进行数据查询或二次处理,避免不必要的导入导出成本,同时满足查询性能需求。
五、提高资源利用率
一方面,使用ClickHouse整机的成本比较高,日志场景又是越久远的越没人查询,所以我们希望我们的成本转成固定成本+按使用灵活变化的成本。
另一方面,虽然各大公司都有做资源混布,但一个机器的资源是否可以完全被利用起来除了和调度算法和策略相关,也和业务模型相关。
在实际中一台机器上往往会有那么1核两核的边角料不好用掉。因此我们希望把这些资源作为补充一方面可以卸载一部分日志平台的计算资源,一方面提升整体的资源利用率。
业界调研
为了解决上述问题,我们从日志平台本身的问题出发,进行了一系列的方案调研和讨论,核心围绕如何满足解决上述问题,以及在解决上诉问题的前提下如何有效的确保ROI,我们目的是解决问题找到合适当前状态并对未来发展呈现开放状态(不会出现规模体量或业界有变化不得不大幅度掉头) , 目的不是要做一个什么东西去发论文。
另外B站日志团队并不像一些公司动辄十几号人,有充足的人力去做各种自研,实际的研发就3个人。
同时当前问题又是紧迫的摆在团队面前我们必须要能够实现阶段性产出比如半年就能拿到初步的收益,在后续在迭代中又可以逐步完善达到更高目标,逐步做深做强。
我们的调研主要包括OpenSearch/Clickhouse/Loki/SLS以及一些公司的内部方案。
大的层面主要分为2个派系:
存算一体。
通过依托于各大云厂商提供的弹性块存储或NAS等方式或公司内有一个非常强大的块/文件存储团队,配合不同存储和ecs套餐做资源生命周期流转。
这种方式再一定层度上可以降低一些成本,解决存储计算的错配,但对于其他方面并不能解决问题,这显然对于B站来说并不合适,这个下面就不展开了。
存算分离。
下面我们简单展开说一下这一块的调研情况。
OpenSearch/Clickhouse/SLS
这里提到的OpenSearch(AWS推的elasticsearch项目)主要是指其remote storage方案, 或者是一些公司基于内部分布式存储重构的ElasticSearch存算分离方案。
Clickhouse是指一些公司基于clickhouse构建存算分离方案。
这些方案不管是开源或者闭源,都是针对原本产品定位和体系做了相关设计,对性能和自控力上做了很高的“强调”。
这些项目虽然在定位以及侧重点上都有所不同,但在一个比较大的层面的思路基本是比较相似的,最底层支持多种存储系统,提供filesystem的抽象,比如支持hdfs也支持对象存储。
在这个之上构建存储引擎层,存储引擎可能是独立的进程也可能是在计算引擎中的一个模块,但这几个基本定义了自己的数据组织方式,即table format。
一般的还会配有metaservice做元数据管理。indexservice做索引加速,local cache做访问加速或结果加速等。
如果这边采用这样子的方案前提下,会有两个选择,
基于一个产品自研。就像阿里云的卖的ElasticSearch存算分离方案一样。这样子做对于当前的团队面对的上诉提到的背景来说非常不切实际。
就直接用这些开源的解决方案。
比如我们是不是可以直接用opensearch?
且不论这个方案是不是久经考验,假设就是经历过这样子考验,比如字节前段时间开源的ByConity内部有一定的使用规模,但我们是不是可以在较短时间内掌握这样子的东西,社区是不是真的活跃。
更为关键的是这些方案基本都是数据封闭的,并不能满足我们对开放的要求。
同时也不能满足我们对于和整个大数据体系结合的目标,我们希望非必要不需要做数据转换流转,应该进行原地查询。
Loki
前面提到的OpenSearch/Clickhouse本身功能都非常强大,定位是olap产品非日志系统,做日志系统需要配套构建包括数据采集,数据管道,数据分发,日志查询等能力构建。
而Loki设计之初就是定位轻量级低成本日志系统,提供了完整的日志系统能力。
因为B站在当前的日志平台2.0上已经具有了相关的基础完整能力(即使采用最多也要和当前的看怎么结合),所以我们下面主要简单说一下Loki的存储引擎相关的设计。基本思路还是类似上面的分成index store和chunk store。
index store存储索引,也就是一行日志的标签,chunk store存储实际的数据。
通过标签(key+value)计算出唯一ID关联到一个series(所以使用loki一般推荐标签少一些,标签基数低一些,不然会出现大量series),一个series由若干chunk组成, 每个chunk在chunk store里面对应一个实际的文件。
写入通过追加写的方式写入到chunk。一个典型的查询为根据标签查询到对应的series,通过seriesID查到关联的chunkID,然后暴力读取每个chunk并根据其他条件grep数据,然后聚合返回。
整个设计简单直接,在思路上提供了一个不错的想法:“暴力或许有时候也能解决问题”。
当然就他这样子的索引设计方式在实际场景中往往会导致小文件过多进而导致性能不达预期,使用场景会比较受限。
一个是类似上面opensearch等的原因,二个是并不能支撑内部数据规模体量,所以很快我们放弃了loki的想法。
Billions 3.0 架构
结合上诉的调研我们发现,我们需要几个东西:
-
支持海量数据存储的低成本存储系统
-
业界通用的table format可以支持各种查询引擎查询
-
一个或多个高效的查询引擎,可以实现较为灵活的扩缩容
-
一个查询网关屏蔽底层的查询引擎的差异。
熟悉大数据的同学不难看出,这就是一个典型的湖仓一体想法。
整体架构
billions 3.0日志平台,涵盖了日志采集、数据网关、数据管道、加工投递、日志引擎、查询网关以及统一接入等,实现了整个端到端的一体,同时在架构上始终保持着放开状态。
下面简单介绍各个层负责的主要工作以及能力。
日志采集:日志采集这块我们实现了日志采集器log-agent,支持otel协议以及常见的十几种日志格式采集,支持基础的日志处理下推,包括但不限于: 日志格式解析,数据过滤,数据采样等。主要以物理机daemon方式部署负责采集物理机以及容器产生的日志,基本覆盖了B站的全日志场景。
数据网关:log-gateway当前最新版本代号kafka-proxy,主要负责日志采集器上报数据的聚合投递到数据管道,主要实现日志数据的路由投递到对应的数据管道集群,同时实现透明的数据管道降级切换。数据网关以通用大集群+高优集群+专用集群的方式部署。
数据管道:这块目的是为了实现整个日志流量的削峰填谷,同时实现采集和处理的解耦。这块我们主要使用的kafka集群实现。kafka作为老牌的消息中间件,各种计算引擎等实现了相关connector。当前以通用大机群+高优集群+专用集群的方式部署。
加工投递:这块以自研的log-consumer为主,flink job为辅。log-consumer专注简单场景的日志加工投递提供高性能和高灵活性,flink job负责复杂场景的日志加工投递解决业务的特殊需求。业务在使用上根据不同的配置会最终生成对应的log-consumer或者flink job任务。这块我们除了本身的数据入日志引擎外,为一些业务对于秒级可见性实时日志消费的需求,我们还支持kafka/databus(在线场景消息队列)消费。
日志引擎:当前采用clickhouse + iceberg + hdfs + trino的实现方式。给日志平台提供核心的存储以及计算能力的同时也支持外部计算引擎(flink/spark/presto等)基于iceberg进行直接查询消费。
查询网关:主要目的为屏蔽底层查询引擎差异,实现统一的查询语义,当前支持DSL以及类SQL语法。比如在grafana上配置日志指标监控可以不需要知道底层是什么。
统一接入:主要是我们的用户交互平台以及openapi服务。日志平台支持采集接入、租户管理、查询分析以及监控告警等能力。
针对上述问题,我们设计了billions3.0日志服务体系,主要实现了iceberg + clickhouse的混合存储,实现了自研的可视化分析平台,并统一了日志的上报协议。
日志引擎
B站日志平台2.0日志引擎完全基于clickhouse构建,基于一个基本假设天内数据查询频率远大于超过一天数据。
热数据(一天内)采用nvme盘存储以提供最快的查询速度,冷数据(超过一天)采用HDD盘存储。
采用clickhouse自带的基于TTL的数据生命周期管理方式进行数据流转淘汰。
3.0日志引擎基本思路是:访问加速层 + table format + 查询引擎。
当前数据访问加速层采用的clickhouse,table format采用的iceberg,查询引擎默认使用的trino。
基本思路为log-consumer双写clickhouse和iceberg,查询由log-query作为统一查询屏蔽clickhouse和trino。
对于大数据套件来说所有的数据已经在数据湖中,可以通过各种查询引擎对数据进行直接查询或者二次处理。
访问加速层
3.0日志引擎的查询加速层采用的是clickhouse,主要是以下几个原因:
0是2.0的延续,我们2.0时在日志场景做了不少优化,也沉淀了不少技术积累,同时在热数据上clickhouse并没有成为”问题”
一圈调研之后确实没有比clickhouse更适合当前的背景的访问加速层引擎(低成本、高性能)
公司有专业的clickhouse团队,日志团队和clickhouse团队构建了良好的合作基础,能够共同进退
与2.0不同的是clickhouse不再被认为是数据生命周期流转的必要的阶段,而是做为一个访问加速作用。
在实际的场景中,有业务日志类似于审计日志等并不需要很快的查询速度,也不存在明显的查询冷热分层的情况,我们当前会选择关闭clickhouse的写入以减少不必要的资源浪费。
因为clickhouse在3.0中只是作为访问加速层存在,以现在架构下要进行加速层引擎的插拔并不是一件很难的事情,哪天出现更加合适的引擎我们也会考虑进行必要的替换,或者在一些场景下使用clickhouse,在一些场景下使用另外的引擎。
核心访问层
这块我们需要考虑的是几个问题:我们应该选择哪种table format?
我们应该选择哪种底层存储系统?
我们应该选择哪种查询引擎?
先来说问题1,业界现在主流的table format主要有: iceberg、hudi、delta lake等。几个table format随着过几年的发展能力上也越发趋于类似。从日志平台的角度看:
我们是希望使用被业界主流认可的table format以方便后续架构的迭代演进,这三个其实都满足。
最好B站有相关团队在维护并进行二次开发,因为介于日志团队人员情况,当前并不适合自己去维护一套format并进行二次开发。
对于日志场景来说,其实需要的主要是一个可以持续追加写入并且可以动态改变schema的表格存储(schema less)。对更新、time travel等并不感冒。
我们希望一款定位简单清晰的format,能够比较容易进行二次开发,比如元数据优化,索引优化等,我们并不需要大而全且复杂的东西,毕竟我们的场景是日志平台,并不是要做一个大数据计算平台。
综上我们最后选择了iceberg作为我们的table format。
再来说问题2,其实在B站(自建机房)并没有太多的选择,主要有对象存储和hdfs(我们并不打算去自研底层存储这个并不适合我们团队)。
两个产品都提供了数据做EC以实现低成本存储,也就是在低成本上两边并没有特别的差异。最后我们选择hdfs主要考虑了几个点:
对于存算分离架构来说,计算池化/存储池化是一个必然要考虑的问题,而拥有一个足够大的存储池,更加有利于对数据放置的调度,更加有利于闲散io的利用,后续做相关的优化也更加不容易掣肘。
而在B站当前情况下hdfs的存储规模远大于对象存储。
hdfs长期做为整个大数据存储底座天然和整个大数据有更好的配合,也就各种大数据引擎都考虑对hdfs的优化。而我们3.0的一个目标是和大数据体系打通
所以我们最终选择了hdfs作为底层存储系统,默认EC采用6+3配比,仅需 1.5 倍存储成本用来保存日志数据就能提供比之前 Clickhouse 2副本更高的数据持久性。
最后说问题3,因为整个架构是开放的,其实B站内部所有的大数据查询引擎都是可以直接查询iceberg的。日志平台本身采用的查询引擎默认是trino,采用trino的几个核心原因主要是:
trino和iceberg是一个团队在进行研发,相关团队在两者结合上做了不少优化,比如索引优化、小文件优化等
trino当前在日志场景提供了不错的查询性能,是可以满足绝大部分场景的(在实际业务场景中可以实现1400亿行数据点查20秒返回)。
B站trino采用容器化部署,当资源不足时可以较为方便的进行扩容
所以我们最终选择了trino作为默认的查询引擎。
当然我们对一些其他查询引擎也保持观望,比如: presto + velox,spark + gluten,StarRocks数据湖方案等等
日志表的设计
Iceberg日志数据按照业务存储在不同的日志表中,日志表按照天作为分区,部分日志表可能按照业务字段构建二级分区,日志表中的字段主要按照以下方式规划:
公共字段,公共字段包含抽象出来的所有日志都会有的独立字段,例如timestamp, app_id等等。
log_msg字段,log_msg字段是日志的文本字段,用户可基于该字段进行文本检索。
私有字段,私有字段在各业务日志中并不相同,且可能会随着业务日志埋点的不同动态变化,不同于log_msg文本字段,私有字段是日志的维度数据,主要用于在日志查询时点查或范围过滤。
日志数据的异步优化
哔哩哔哩基于Iceberg的湖仓一体平台提供了对于Iceberg数据进行管理优化的能力,通过采集Iceberg表的Commit信息(类似于Mysql的Binlog)结合表本身的元信息(表的排序字段,索引等),按照一定规则和策略拉起Spark任务对已经写入Iceberg表的数据异步进行重新的组织和优化,具体的能力包括:
小文件合并。实时写入的日志数据可能会产生大量的小文件,对HDFS NameNode产生较大压力,且小文件会影响查询性能,Iceberg数据优化任务会尽量将小文件合并成期望大小的文件。
数据排序和组织。数据的排序组织方式会影响索引的效果,以及压缩的效率,Iceberg数据优化任务会按照表的元数据定义对日志数据进行重新的排序组织,我们支持对于Iceberg表定义文件间和文件内不同的排序方式,以及Order/Z-Order/Hibert-Curve-Order等多种排序方式,数据的排序组织可能和小文件合并在同一个任务中完成。
索引生成。除了Iceberg本身的MinMax Metrics,以及Parquet/Orc文件内部的MinMax,BloomFilter等Segment Metrics,我们的湖仓一体平台还支持更多扩展的文件级别的索引,Iceberg数据优化服务根据用户自定义的Iceberg表的索引类型,在1,2两步完成后拉起Spark任务生成对应的索引数据。
Iceberg Metadata优化。频繁的数据写入会产生大量的snapshot,影响访问Iceberg表元数据的性能,Iceberg数据优化服务也会自动拉起对应任务清理过期snapshot。
通过湖仓一体平台提供的能力,我们可以结合日志场景数据和查询的具体情况,对于日志数据进行合理的配置和管理优化,使得大规模日志数据的低成本交互式分析成为可能。
正向索引的使用
日志数据的查询普遍会限制在一定的时间范围内,如何根据用户查询的时间范围尽量减少需要扫描的数据量是加速查询性能的关键之一,日志表的时间分区(一般是天分区)能够进行分区级别的Data Skipping,只扫描满足时间过滤条件的分区数据,但是对于时间范围更小的查询,比如2023-05-20:10:05:00 ~ 2023-05-20:10:15:00,则需要通过正向索引和数据排序组织进行进一步的Data Skipping。
在实践中,我们可以将_timestamp字段设置为文件间和文件内排序字段,使得优化后的Iceberg数据在分区内按照_timestamp充分聚集,在Iceberg文件级别,通过Iceberg的MinMax Metrics在Trino查询的Coordinator getSplits阶段将不需要的文件直接Skip掉,对于没有过滤掉的文件,在Trino Worker处理Split,读取Orc数据时,还可以继续用Orc Segment级别的MinMax Metric进行文件内Segment级别的Data Skipping。
对于其他常见的过滤字段,则可以通过二级索引进行Data Skipping,比如对于常见的点查过滤,可以考虑在该字段上配置BloomFilter索引,对于范围过滤,可以在该字段上配置BloomRangeFilter索引等。
基于Iceberg原生和我们扩展的正向索引,通过合理的索引配置,我们可以根据用户查询中基于公共字段的过滤条件把需要扫描的数据限制在相对较小的范围内了,为交互式查询打下一个良好的基础。
针对高基数字段的点查:
select * from test where arg_trid = '1007997177f95bd44536bb570fd193830ab1' and (log_date = '20230512' or log_date = '20230513') order by _timestamp desc limit 200;

反向索引的使用
除了时间范围和基于公共字段的过滤条件,常在用户查询中出现的过滤条件还包括基于log_msg字段的文本检索条件,特别是在日志排障场景中,如何根据文本检索条件进一步缩小需要扫描的数据是支持交互式日志分析的关键。
如何快速地进行文本检索是工业界和学术界已经探索了很多年的方向,技术已经非常成熟,其中最主要的手段就是通过反向索引进行查询加速。
TokenBloomFilter索引
我们首先扩展Iceberg实现了一个轻量级的TokenBloomFilter索引,支持在Iceberg文件级别对索引字段先分词,分词后生成BloomFilter索引。BloomFilter数据结构占用空间小,非常适合针对低频词的文件检索。
但是Bloomfitler是一种Approximate数据结构,有出现False Positive Probability的可能,所以只能用于membership的判断,无法准确定位到符合检索条件的数据行,对于部分场景,BloomFilter索引过滤文件的效果不是很好,比如日志检索中经常出现的Phrase查询,TokenBloomFilter索引只能根据Phrase短语中分词后的term是否全部出现在文档中判断是否可以跳过扫描文件,而无法充分利用检索条件表达的”Phrase短语中分词后的term全部出现在文档中的某一行且满足出现顺序”的约束条件。基于此,我们进一步实现了TokenBitMap索引。
TokenBitMap索引
TokenBitMap索引主要是基于著名开源文本检索框架Lucene的一些基础能力实现,并没有直接使用Lucene索引,这主要基于如下考虑:
日志排障是典型的精确文本检索场景,日志平台需要精确返回所有满足用户检索条件的数据,不需要打分,排序,同义词等能力,Lucene作为比较全能的文本检索框架,对于精确文本检索场景冗余的能力会带来额外的代价。
Iceberg日志数据在文本检索场景下主要用于历史日志数据的排障,访问相对低频,我们更关注在低存储成本下加速查询性能,Lucene索引的存储成本过高,有时甚至索引文件大小超过数据文件本身。
Lucene索引是为本地文件系统所设计,每个Lucene索引会产生数十个索引文件,Iceberg存储在HDFS上,大量小文件对于HDFS不友好。
所以我们使用Lucene的基础能力实现了一个相比Lucene索引更加轻量级的索引类型:TokenBitMap索引。
Token BitMap 索引结构十分简单,索引文件包括 Token 字典和 BitMap 索引两部分,Token 字典使用 Lucene的FST存储,FST 会记录 Token 对应的 BitMap 在 BitMap 索引文件中的偏移量,在匹配 Token 时,会优先读取 FST进行存在性判断,如果存在,通过 FST 获取 Token 在 BitMap 索引中的偏移量,并返回相应的 BitMap。
由于BitMap包含了Token在数据文件中出现的RowId信息,可以根据过滤条件表达式进行交并差计算,返回确定的行级的DataSkipping信息。此外,我们还支持将TokenBitMap索引匹配出的BitMap透传到Trino的TableScan节点中,在访问Parquet/Orc文件时,使用BitMap信息进行精确的文件内Segment Skipping,尽可能减少需要扫描的数据量。
相比于TokenBloomFilter索引,TokenBitMap索引可以更加充分地利用文本检索条件过滤扫描数据,不过TokenBitMap索引的缺点就是占用存储空间过大,在实现TokenBitMap索引时,我们也针对这方面进行的重点的优化设计。首先是分词器,分词器决定了索引字段分词后Token的数量,从而决定FST的大小和BitMap的数量,我们实现了一个自定义的 LogAnalyzer,在 EnglishAnalyzer 的默认停用词基础上新增了日志文本中通用的关键词,比如 timestamp、app_id 等,同时限制了 token 的最大长度,默认最大长度为 40,并对数字类型 token 进行了裁剪,这些优化后,生成的 Token 索引整体接近 50% 存储空间的减少。
其次,对于BitMap的存储,分为三种情况,低频词,中频词,高频词,对于低频词,相比于使用BitMap存储其行号信息,使用压缩数组存储空间反而更小,对于高频词,其BitMap存储所需空间较大,但是因为其广泛存在文件的大部分数据行中,对于Data Skipping作用甚小,ROI小,我们不存储这种类型的BitMap,低频词/中频词/高频词的划分通过参数控制,可以根据实际日志数据情况灵活调整。
反向索引的性能测试
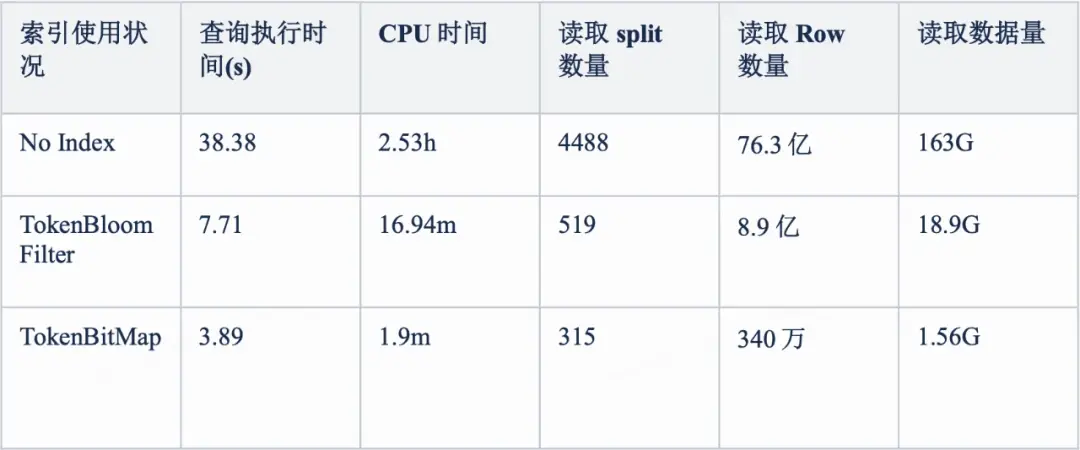
我们使用实际日志数据进行了测试对比,330GB ORC格式的日志数据,生成TokenBloomFilter索引2.1GB,生成TokenBitMap索引76.6GB,使用了低频词/中频词/高频词(出现的次数分别是25/2813/127204438次)检索的性能如下:
低词频查询:
select count(*) from test01 where has_token(log_msg, '1666505943110300001');
中词频查询:
select count(*) from test01 where has_token(log_msg, '1978979513');
高词频查询:
select count(*) from test01 where has_token(log_msg, '1664553600');
可以看到,在中低词频的检索中,对比于TokenBloomFilter,TokenBitMap索引的查询性能更好,在需要扫描的数据量和查询消耗的CPU时间方面优势更加明显。
不过在实际的日志排障使用场景中,考虑到最近的日志数据在ClickHouse有存储加速,Iceberg日志数据主要满足历史以及跨天日志数据排障,查询频次较低,我们更关注存储成本的代价,所以对于大部分日志数据,只创建TokenBloomFilter索引,只对少部分查询频次较高,性能要求较高的日志数据构建TokenBitMap索引。
进一步的探索
日志数据除了如timestamp/app_id等公共字段及log_msg文本字段,通常还会在数据入湖过程中抽取出不同业务各自的私有字段用于日志查询时更方便的检索过滤,这些私有字段各业务皆不相同且可能动态变化,所以通常使用Map或者Json类型字段存储,对于此类字段,如何更好地利用过滤条件进行Data Skipping,是我们进一步探索的方向,我们在这方面的工作如下:
支持基于map_keys(col)/map_values(col)表达式创建索引,此索引可以用于常见Map类型过滤条件element_at的Data Skipping,例如对于过滤条件element_at(col, ‘key1’) = ‘v1’, 可以首先使用基于map_keys(col)生成的索引判断‘key1‘是否在文件中存在,然后使用基于map_values(col)的索引判断‘v1’是否在文件中存在。
如果用户日志查询只会经常使用某一个key值做过滤,则可以直接基于element_at(col, ‘key1’)表达式创建索引,只从Map中抽取‘key1’对应的value构建索引,从而减少索引大小,提升索引过滤效果。
支持基于json_scalar_extract($json_path)表达式创建索引,用户可以使用此方式从json字段中抽取常见内部字段构建索引,在查询时,如果使用对应json路径抽取的字段作为过滤条件,则可以通过索引判断是否可以跳过扫描文件。
计算下推
当前log-agent主要以物理机部署为主,即B站几乎所有机器上都部署了log-agent服务。当前log-agent支持多种input/processor/output等。
为了减少后端资源的使用,我们可以在log-agent上执行一部分简单的计算,把后端的计算卸载到相关节点上,把物理机上的闲散资源利用起来。
其中比较典型的玩法是支持下推非结构化/半结构化日志解析为结构化日志,我们通过不同的参数配置可以让相关转换是在消费端进行还是采集端进行。
现在只有小部分因为相关机器资源使用要求,我们计算还是在消费端专门的消费服务进行解析,大部分日志的结构化转换我们都已经在log-agent完成。
消费调度
数据分流
考虑到容灾和可用性要求,我们在3.0中的基本思路是按高优集群+专用集群+通用大集群的方式进行数据分流。
log-agent可以根据AppID+StreamID路由规则进行调度到不同的log-gateway集群。
默认情况下,高优日志进入kafka-proxy-high集群,没有特殊要求的日志进入到日志大集群(绝大部分日志都在这个集群), 另外有特殊场景要求的,比如极高优要求完全不想被其他人影响的,值得专门部署一套链路的,我们也支持专用集群,但原则上我们尽量会避免,因为这在资源利用率上并不会有很好的效果。
对于出现任意集群出现不稳定时,我们优先会考虑对集群快速弹性的扩容(log-gateway是无状态的), 当扩容不能解决问题时,我们可以快速将该集群的流量一部分或所有切到其他集群中。
log-gateway可以根据AppID+StreamID维度路由规则进行调度到不同的kafka集群。
同样我们把kafka分成了高优/专用/通用大集群,绝大部分日志会进通用大集群。由于kafka是一个有状态服务,加之其相关设计实现弹性扩缩容能力并不太理想。在这个层面我们会优先把相关日志流调度到其他集群,同时配合下游log-consumer的扩容。
kafka topic层面我们同样采用大+小的方式,对于一些特别大,或优先级高的我们会拆分单独的topic(这里提一点在我们的架构下,把一个或多个流拆分到其他topic是很简单的事情);对于一般的日志流我们会根据资源使用相对均匀得拆到到N个topic里面。
采用大+小的主要是成本+容灾之间的tradeoff。
log-consumer同样是一个无状态服务,采用golang编写,容器化部署,整体资源使用率比同样场景的flink至少少50%。
可以实现方便的弹性伸缩,同时可以根据路由规则动态消费不同的topic以实现充分的资源均衡利用。
该方案上线之后效果显著,年初频繁因为业务突增流量导致整个日志链路整体不可用的情况得到很好的抑制, 半年来未发生因为这块出现相关故障。
打通大数据体系
得益于我们架构上采用了iceberg这种table format,打通B站大数据体系变得容易起来。
下面简单提一下批处理场景和流处理场景。
批处理场景分区提交
这个策略是基于Kafka消费延迟和写入延迟的双重指标来动态提交Hive分区。
监控写入程序的消费延迟:这是初始步骤,需要计算日志的上报时间和写入存储的时间差,这样就可以得到日志在实际被写入之前的延迟时间。这是一项关键的度量,因为它可以了解数据从接收到实际写入存储的耗时。
监控 Kafka 的消费 lag:观察到数据消费存在延迟时,对比消费延迟时间和消费端的吞吐量,可以预估出一个延迟数据被消费掉的时间。
结合写入延迟和Kafka的lag:在这个阶段,我们结合写入延迟和Kafka的lag,以及预定的提交延迟阈值,来决定是否提交Hive分区。可以设定一个规则,如果写入延迟和Kafka的lag都超过了预设的阈值,那么就提交该分区。
流处理场景分区提交
Flink侧是使用Flink作为观察者发送消息通知,观察者为Iceberg端,被观察者分区是否就绪是引擎端可以直接感知的事情。具体的感知方式会因不同的引擎而异。对于Flink,我们可以利用Watermark这个概念感知分区是否就绪。当分区就绪后,我们可以注册一个事件处理函数和对应的事件类型——在我们的例子中,是实现了Flink自带的PartitionCommitPolicy的CommitPolicy。在CommitPolicy中,我们实现具体的commit逻辑,即调用调度平台API以实现分区就绪的通知机制。
具体实现这一设计思路需要对Flink写入Iceberg的线程模型进行修改。我们可以在IcebergStreamWriter算子的prepareSnapshotPreBarrier阶段增加分区处理逻辑,并把分区信息发送到下游IcebergFilesCommitter算子。这些新的分区信息(我们称之为pendingPartition)被存储在一个Set中,等待提交。当这些pendingPartitions满足提交条件后,我们将其从Iterator中移除。
分区处理逻辑的实现借鉴了Hive connector的做法。在checkpoint完成时,我们将可提交的分区(committablePartition)发送到下游的IcebergFilesCommitter算子。IcebergFilesCommitter收到committablePartition后,会将这些committablePartition加到pendingPartitions里。
当分区就绪时,我们会调用Archer(B站DAG 任务调度平台)API完成消息通知。为了在批量计算过程中支持 Iceberg 表,我们需要设计一套在分区就绪后进行消息通知的策略,分区就绪的标志分为两部分,一部分是观察分区就绪的条件,另一部分是分区就绪后的消息通知设计。消息通知设计的时候,主要考虑在分区就绪的时候,在哪个层面通知 Archer 调度下游任务,其中包含两种设计思路:一种是将 Flink 作为观察者发送消息通知,另一种是将 Iceberg 作为观察者发送消息通知。
在 Flink 观察者模式下,分区就绪的标志是引擎测可以直接感知的,具体的感知方式会因不同的引擎而有所不同,对于 Flink,我们可以使用 watermark 这个概念来感知分区是否就绪。在分区就绪后,我们可以注册一个事件处理函数和对应的事件类型 ArcherCommitPolicy(实现了 Flink 自带的 PartitionCommitPolicy),并且在 ArcherCommitPolicy里实现具体的 commit 逻辑,即调用 Archer API 来实现分区就绪的通知机制。由于 Iceberg 是基于文件级别进行统计的,所以我们可以在文件级别获取到对应的分区信息。
日志聚类
我们加强了日志分析的能力,帮助用户进行更好的日志排障。在服务出现问题时候,通常ERROR的日志量会暴增,不利于问题的定位,使用我们的轻量级日志聚类功能,可以将相似度高的日志聚合,做到秒级返回日志聚类,迅速理解日志全景,提升问题定位效率。
日志聚类在DevOps中可以被应用于问题定位和版本比对,这对于快速发现异常日志和定位问题是非常有帮助的。主要的设计需求包括:
聚类过程需要尽可能快,而且结果应非常稳定。换言之,聚类的类别和结果不应有波动。
需要能够保证日志模式的一致性,以便在不同的时间段内,通过日志类别查看其波动和变化。
设计思路是结合阿里云和观测云的日志聚类功能。阿里云采用全量日志聚类,将所有日志数据通过聚类模型获取其模式。这需要消耗大量的计算资源,且模式和索引需要落盘,从而增加了约10%的日志存储。观测云则选择对部分日志进行聚类,它查询限定时间范围内的1w条日志数据进行聚类,因此其聚类结果可能不完全稳定,同时也无法进行日志对比。
因此,我们的目标是在需求更少的资源的同时,获得更丰富且更稳定的聚类结果。
我们可以用下面这张图来理解日志聚类所做的工作:

日志模式解析过程可以理解为是一个倒推日志打印代码的过程,也是一个对日志聚类的过程(相同pattern的日志认为是同一类日志)。
算法思路设计:
被同一条代码打印出来的日志肯定是相似的,所以我们可以得到第一种模式解析的思路,给出文本相似度公式或距离公式,通过聚类算法,将相同模式的日志聚到一起,
然后再获取日志模板,业界基于聚类的日志模式解析算法,如Drain3、Lenma、Logmine、SHISO等。但在实际聚类过程中会往往存在很多的问题,聚类速度慢,大量的pattern类别、全量计算消耗大量资源等问题,
我们设计了基于固定深度解析树的思路,多个子pattern进行层次融合的方式,结合代码行号等特征对聚类速度和精度进行加速聚类
整体算法步骤分为以下几个部分:
预处理的获取日志平台表达式查询后的全部日志数据,(对于超过10w条的日志进行采样)在对日志进行解析前,都会先进行分词,因为词是表达完整含义的最小单位,将一些特殊词,如IP地址、时间等给识别出来,
然后替换为特殊字符或去掉,这是由于这些特殊词明显是参数,如此处理可以有效提高相同模式日志的相似度。提取日志消息对应的 日志行号特征数据
聚类的简单过程如下,我们首先构建一个固定深度的解析树,对于日志进行聚类,
1,根据日志的长度分组和日志行号等以及根据日志的前几个单词分组,树深度决定了用前多少个单词进行分组。
2,解析树的上层节点以日志行号特征和日志消息的长度(token的数量)区分日志组,根据预处理后的日志消息前几个单词依次向下搜索,直到叶子节点。叶子节点下存储着该组别中的聚类簇,
搜索到叶子节点后再计算相似度,根据相似度计算结果更新子聚类中心或者创建新的聚类子簇
相似度计算逻辑如下, 在找到simSeq最大的日志组后,将其与自适应的相似度阈值st进行比较,如果simSeq≥st,那么就会返回该组作为最佳匹配。
3,更新解析树,将每个日志消息解析为字段,并按照固定深度树的结构进行插入。每个字段都对应树中的一个节点,如果节点已存在,则更新节点的统计信息;如果节点不存在,则创建新节点,对于匹配上的子pattern,
描日志消息和日志事件相同位置的token,如果两个token相同,则不修改该token位置上的token。否则,在日志事件中通过通配符*更新该token位置上的token。
4,层次融合,对于相似的pattern进行融合,结合LCS(最大公共子序列)的思路进行融合,将改善聚类效果,比如使同一行号下不同的pattern和不同行号特征下的子pattern聚类得到公共pattern。
5,模型保存与推理
聚类后的模型按appid进行保存,在后续实时日志聚类推理过程中,将直接日志消息与模型的解析流程进行匹配,未匹配上的日志将实时更新聚类的模型
整体收益
综上所述,通过我们对日志系统的持续演进, 进一步降低了存储成本(至少20%)并增强了日志系统的稳定性, 保证了日志的低延迟、低成本, 以支持全公司的各类日志数据, 以及满足他们的查询和进一步使用需求。我们还基于iceberg实现了离在线一体架构的演进的同时还保持了架构的开放性。
同时, 我们围绕日志作为核心, 构建了一整套针对MTTR的日志服务和功能, 包括日志一站式快速分析、基于最小代价的日志聚类、灵活配置打通可观测性平台的日志告警等, 帮助业务显著降低平均故障修复时间。
未来展望
在过去半年时间里我们完成了上诉相关的工作,基本解决了开头提到的几大问题。但当前系统仍然存在诸多不足以及功能补齐。
clickhouse多集群平滑拆分。解决clickhouse集群越来越大导致的不必要的稳定性问题。
日志数据insight能力,帮助业务进行日志管理,简化业务自主日志优化以及降本。
基于opentelemery和整个可观测性平台更强的联动,提供更强的根因分析以及排障能力。
实现快速海外云上部署。当前方案严重依赖B站大数据体系以及微服务体系,以至于海外云上部署困难重重。
统一可观测性平台几大组件底层技术支撑能力。让logs/tracing/metrics基于统一的架构上,实现更大层面的资源混合调度
探索为日志而生的iceberg meta service以及index service可行性,进一步提升对于海量日志查询下的性能。
探索更加弹性的数据管道以及消费端组件,提供更灵活的资源调度。
探索log-agent基于wasm的动态算子下推能力。
参考资料
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
