Apache Druid简介
Apache Druid是一个实时分析数据库,专为快速切片分析(”OLAP”查询)大型数据集而设计。
在大多数情况下,Druid被用于需要实时摄取、快速查询性能和高可用性的应用场景。
Druid通常用作分析应用程序的数据库后端,或者用于需要快速聚合的高并发API。Druid最适合事件导向的数据。
Druid常见的应用领域包括:
- 点击流分析,包括网络和移动应用分析
- 网络遥测分析,包括网络性能监测
- 服务器指标存储
- 供应链分析,包括制造指标
- 应用性能指标
- 数字营销/广告分析
- 商业智能/OLAP
如果您正在尝试新的Druid用例,或者对Druid的功能和特性有疑问,请加入Apache Druid Slack频道。
在那里,您可以与Druid专家联系,提问,并获得实时帮助。
Druid的关键特性
Druid的核心架构结合了数据仓库、时间序列数据库和日志搜索系统的思想。
一些Druid的关键特性包括:
-
列式存储格式。Druid使用列式存储。这意味着它仅加载特定查询所需的确切列。这极大地提高了仅检索少数列的查询速度。此外,为了支持快速扫描和聚合,Druid根据每个列的数据类型对列存储进行优化。
-
可扩展的分布式系统。典型的Druid部署跨越从数十到数百个服务器的集群。Druid可以每秒摄取数百万条记录,并保留数万亿条记录,同时保持查询延迟从亚秒到几秒钟的范围内。
-
大规模并行处理。Druid可以在整个集群中并行处理每个查询。
-
实时或批量摄取。Druid可以实时或批量摄取数据。摄取的数据立即可供查询使用。
-
自我修复、自动平衡、易操作。作为操作员,您可以添加服务器以进行扩展,或删除服务器以进行缩减。Druid集群会在后台自动重新平衡,无需任何停机时间。如果Druid服务器失败,系统会自动绕过故障路由数据,直到服务器可以替换。Druid被设计为持续运行,无论何种原因都不需要计划停机。这对于配置更改和软件更新都是如此。
-
云原生、容错架构,不会丢失数据。在摄取后,Druid会将数据安全地存储在深度存储中。深度存储通常是云存储、HDFS或共享文件系统。即使所有Druid服务器都失败,您也可以从深度存储中恢复数据。对于仅影响少数Druid服务器的有限故障,复制确保在系统恢复期间仍然可以进行查询。
-
快速过滤的索引。Druid使用Roaring或CONCISE压缩位图索引创建索引,以实现快速过滤和搜索多个列。
-
基于时间的分区。Druid首先按时间对数据进行分区。您还可以选择基于其他字段实现额外的分区。基于时间的查询仅访问与查询时间范围匹配的分区,这导致了显著的性能改进。
-
近似算法。Druid包括用于近似计数唯一、近似排名以及近似直方图和分位数计算的算法。这些算法具有有限的内存使用,并且通常比精确计算快得多。对于精度比速度更重要的情况,Druid还提供了精确计数唯一和精确排名。
-
摄取时自动摘要。Druid在摄取时可选支持数据摘要。这种摘要部分预聚合您的数据,可能导致显著的成本节省和性能提升。
何时使用Druid
许多不同规模的公司都在许多不同的用例中使用Druid。
要了解更多信息,请参阅由Apache Druid提供支持。
如果您的用例符合以下几点,则Druid可能是一个很好的选择:
- 插入速率非常高,但更新较少。
- 大多数查询都是聚合和报告查询。例如,“group by”查询。您可能还有搜索和扫描查询。
- 您的查询延迟目标是100毫秒到几秒钟。
- 您的数据具有时间组件。Druid包含专门与时间相关的优化和设计选择。
- 您可能有多个表,但每个查询仅命中一个大型分布式表。查询可能会命中多个较小的“查找”表。
- 您具有高基数的数据列,例如URL、用户ID,并且需要对它们进行快速计数和排名。
- 您希望从Kafka、HDFS、扁平文件或对象存储(如Amazon S3)加载数据。
可能不适合使用Druid的情况包括:
- 您需要使用主键对现有记录进行低延迟更新。Druid支持流式插入,但不支持流式更新。您可以使用后台批处理作业执行更新。
- 您正在构建一个离线报告系统,查询延迟并不是非常重要。
- 您想要进行“大”联接,即将一个大事实表与另一个大事实表进行联接,且您可以接受这些查询需要很长时间才能完成。
本地快速开始
这个快速入门指南将帮助您安装Apache Druid,并介绍Druid的摄取和查询功能。
对于本教程,您需要一台至少有6 GiB内存的机器。
在本快速入门中,您将会:
- 安装Druid
- 启动Druid服务
- 使用SQL进行数据摄取和查询
Druid支持多种摄取选项。完成本教程后,请参考摄取页面,以确定哪种摄取方法适合您。
先决条件
您可以在一台相对普通的机器上执行这些步骤,比如一台带有6 GiB内存的工作站或虚拟服务器。
安装机器的软件要求为:
- Linux、Mac OS X或其他类Unix的操作系统(不支持Windows)。
- Java 8u92+、11或17。
- Python 3(首选)或Python 2。
- Perl 5。
Java必须可用。它要么在您的路径上,要么设置了JAVA_HOME或DRUID_JAVA_HOME环境变量之一。
您可以运行apache-druid-28.0.1/bin/verify-java来验证您的环境是否满足Java要求。
在安装生产Druid实例之前,请确保查阅安全概述。一般来说,避免以root用户身份运行Druid。
考虑创建一个专用的用户帐户来运行Druid。
PS: 这里不支持 windows,我们直接本地使用 wsl 测试。
下载
https://dlcdn.apache.org/druid/28.0.1/apache-druid-28.0.1-bin.tar.gz
解压
tar -xzf apache-druid-28.0.1-bin.tar.gz
cd apache-druid-28.0.1
运行
启动Druid服务
使用自动单机配置启动Druid服务。此配置包括适用于本教程的默认设置,例如默认加载druid-multi-stage-query扩展,以便您可以使用MSQ任务引擎。
您可以在conf/druid/auto目录中查看默认设置的配置文件。
从apache-druid-28.0.1软件包的根目录中运行以下命令:
./bin/start-druid
这将启动ZooKeeper和Druid服务的实例。
Druid可能会使用总可用系统内存的80%。要显式设置Druid可用的总内存,请传递一个memory参数的值。例如,./bin/start-druid -m 16g。
Druid将所有持久状态数据,如集群元数据存储和数据段,存储在apache-druid-28.0.1/var目录中。每个服务都会在apache-druid-28.0.1/log目录下写入日志文件。
您可以随时通过删除整个var目录将Druid恢复到其原始的安装后状态。例如,在Druid教程之间或进行实验后,您可能希望这样做,以便从一个全新的实例开始。
要随时停止Druid,请在终端中使用CTRL+C。这会退出bin/start-druid脚本并终止所有Druid进程。
打开Web控制台
在启动Druid服务后,打开Web控制台,网址为http://localhost:8888。
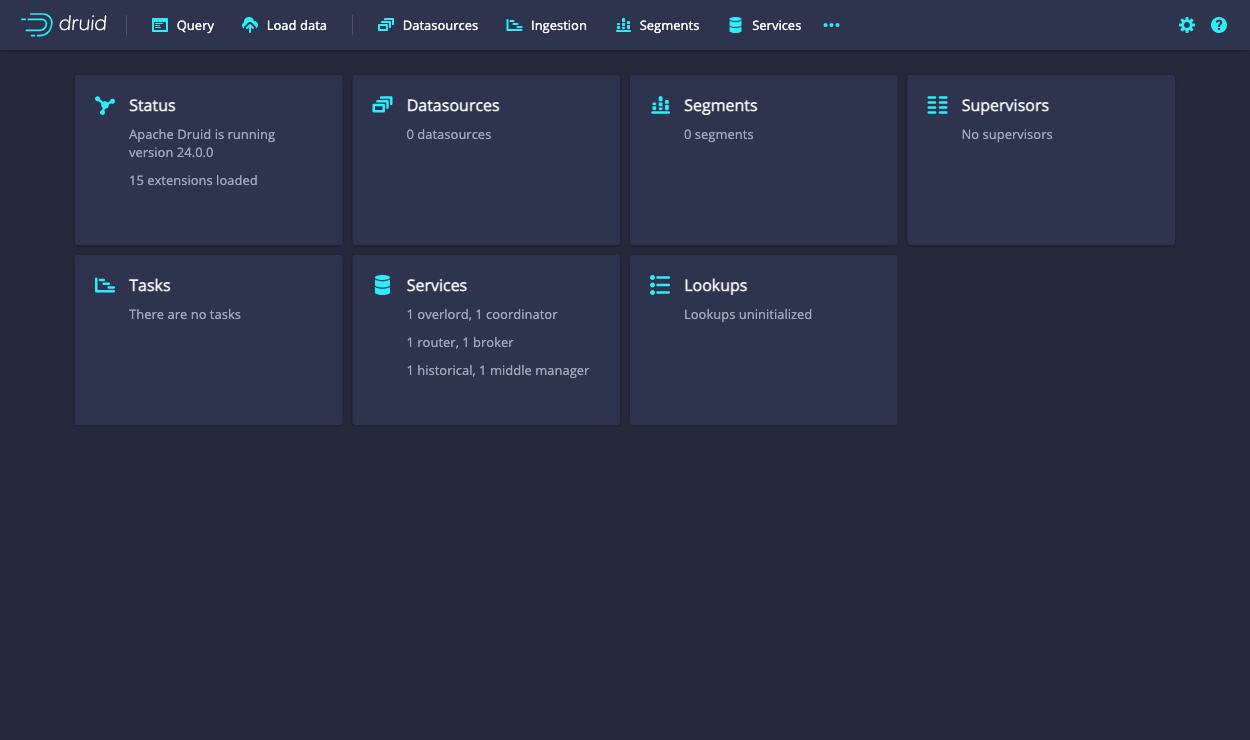
启动所有Druid服务完成可能需要几秒钟时间,包括提供控制台的Druid路由器。如果您在启动完成之前尝试打开Web控制台,则可能在浏览器中看到错误。请稍等片刻,然后再试一次。
在这个快速入门中,您将使用Web控制台执行数据摄取。MSQ任务引擎专门使用查询视图来编辑和运行SQL查询。有关与多阶段查询架构和MSQ任务引擎相关的查询视图的完整演示,请参阅UI演示。
chat
Q: alibaba 的连接池 druid 和这个是不是没啥关系?
虽然两者都涉及到“Druid”这个名字,但是阿里巴巴的连接池Druid和Apache Druid这两个项目之间实际上没有直接的关系。
阿里巴巴的连接池Druid是一个用于Java应用程序的高性能数据库连接池。它提供了强大的监控和扩展功能,是许多Java应用程序中常用的数据库连接池之一。
Druid连接池有助于管理数据库连接的创建、维护和释放,以确保Java应用程序与数据库之间的高效通信。
而Apache Druid是一个用于实时分析大规模数据的开源数据存储和分析引擎,它是一种用于处理和查询大数据集的技术解决方案。
Apache Druid主要用于实时数据分析、OLAP查询和可视化等场景,与数据库连接池Druid在功能和使用场景上有很大的差异。
因此,虽然它们的名字相似,但阿里巴巴的Druid连接池和Apache Druid两者之间没有直接的关联或依赖关系。
Q: 详细介绍一下 apache druid
Apache Druid(以前称为Apache Imply或简称为Druid)是一个用于实时分析大规模数据的开源数据存储和分析引擎。
它最初由MetaMarkets(现为斯利亚姆)开发,并于2012年开源,于2015年加入Apache孵化器,成为Apache顶级项目。
Druid被设计为支持快速数据摄取、实时查询和交互式分析,尤其适用于大数据集的即席查询和可视化分析。
下面是Apache Druid的一些关键特性和组成部分:
-
实时数据摄取:Druid能够高效地摄取和处理大规模实时数据流。它支持多种数据源,包括Kafka、Amazon Kinesis、HDFS等,可以快速地处理高速数据流。
-
列式存储:Druid使用列式存储来优化查询性能。这意味着它将数据按列而不是按行存储,这样可以更快地扫描和检索数据,尤其适用于OLAP(联机分析处理)场景。
-
多维数据模型:Druid支持多维数据模型,可以轻松地对数据进行分组、过滤和聚合。它允许用户定义维度和指标,以便进行灵活的分析和查询。
-
实时查询:Druid提供了实时查询功能,使用户能够在数据摄取后立即进行查询和分析。这对于需要及时了解数据趋势和模式的应用程序非常有用。
-
可伸缩性:Druid被设计为具有高度可伸缩性,可以处理PB级别的数据规模。它支持水平扩展,可以在需要时添加更多的节点来增加存储容量和查询吞吐量。
-
容错和高可用性:Druid具有容错和高可用性的特性。它能够在节点故障时自动恢复,并且支持数据复制和备份,以确保数据的可靠性和可用性。
-
支持多种查询接口:Druid支持多种查询接口,包括SQL、REST API和原生的Java查询接口。这使得与各种应用程序和工具集成变得更加容易。
-
生态系统和扩展性:Druid生态系统丰富,提供了许多与其集成的工具和库。它还支持自定义插件和扩展,可以根据需要定制功能。
总的来说,Apache Druid是一个强大的实时数据存储和分析引擎,适用于需要快速查询和分析大规模数据集的应用场景,如实时监控、业务智能和日志分析等。
参考资料
https://github.com/apache/druid
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
