What is Apache Cassandra?
Cassandra是一种分布式的NoSQL数据库。按设计,NoSQL数据库具有轻量级、开源、非关系型和广泛分布的特点。
它们的优势之一包括横向可扩展性、分布式架构以及对模式定义的灵活性。
NoSQL数据库使得对极高容量、不同数据类型的数据进行快速的即兴组织和分析成为可能。这在最近几年变得更加重要,随着大数据的出现以及在云中迅速扩展数据库的需求。Cassandra是一种已经解决了先前的数据管理技术(如SQL数据库)的限制的NoSQL数据库之一。
分布提供了强大性能和弹性
NoSQL分布式数据库Cassandra的一个重要特性是其数据库是分布式的。这既带来了技术上的优势,也带来了业务上的优势。当应用程序承受高压力时,Cassandra数据库可以轻松扩展,而分布还能防止由于任何给定数据中心的硬件故障而导致的数据丢失。分布式架构还带来了技术上的强大之处;例如,开发人员可以独立调整读取查询或写入查询的吞吐量。
“分布式”意味着Cassandra可以在多台机器上运行,同时对用户而言表现为一个统一的整体。将Cassandra作为单个节点运行并不多见,尽管在学习其工作原理时这样做非常有帮助。但要充分发挥Cassandra的最大优势,您应该在多台机器上运行它。
由于它是一个分布式数据库,Cassandra可以(通常也会)具有多个节点。一个节点表示Cassandra的一个单独实例。这些节点通过称为gossip的协议相互通信,这是一种计算机对等通信的过程。Cassandra还具有无主架构 – 数据库中的任何节点都可以提供与任何其他节点完全相同的功能 – 这有助于Cassandra的强大性能和弹性。多个节点可以被逻辑地组织成一个集群,或称为“环”。您还可以拥有多个数据中心。
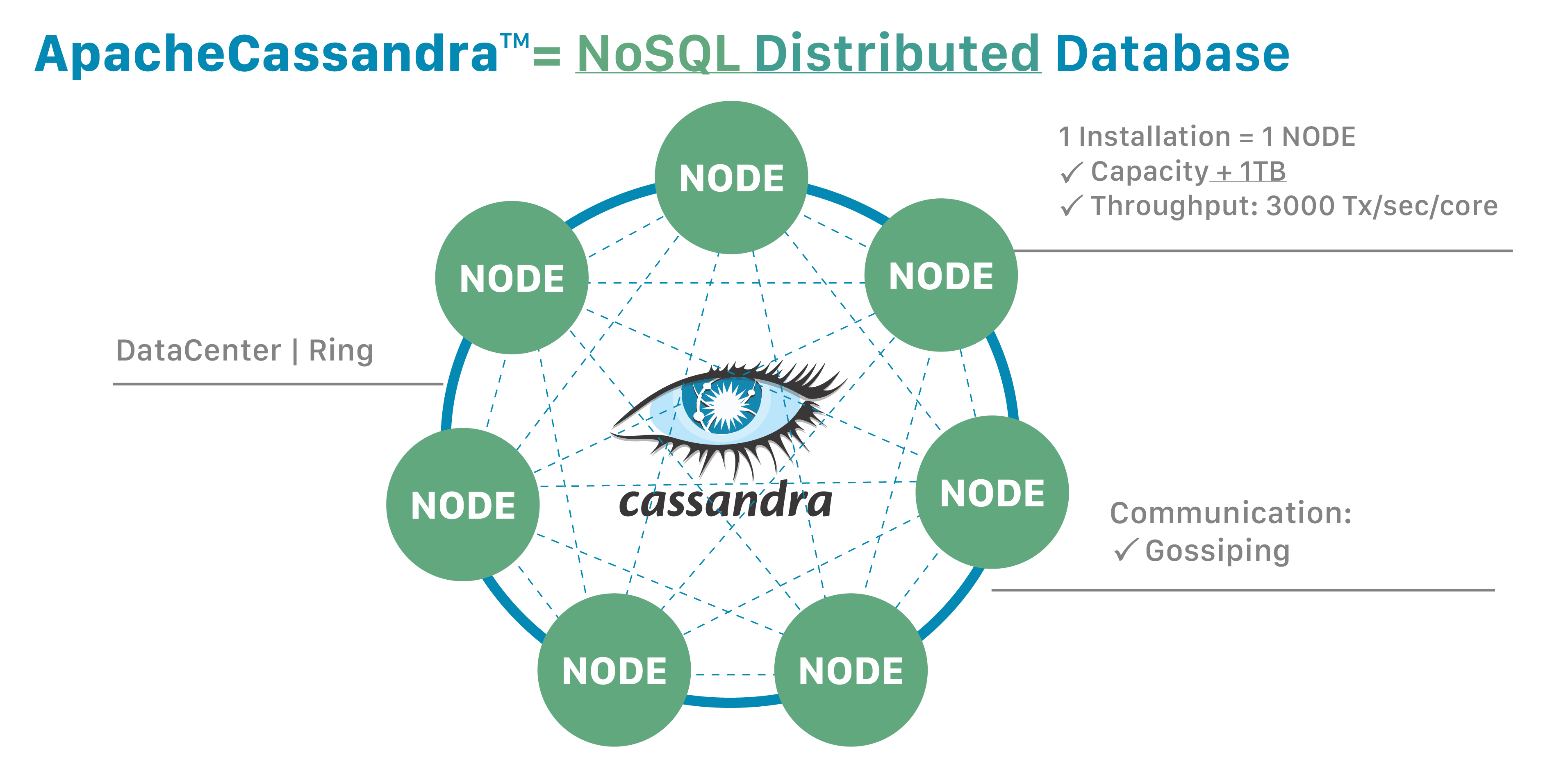
想要更强大的性能?增加更多节点
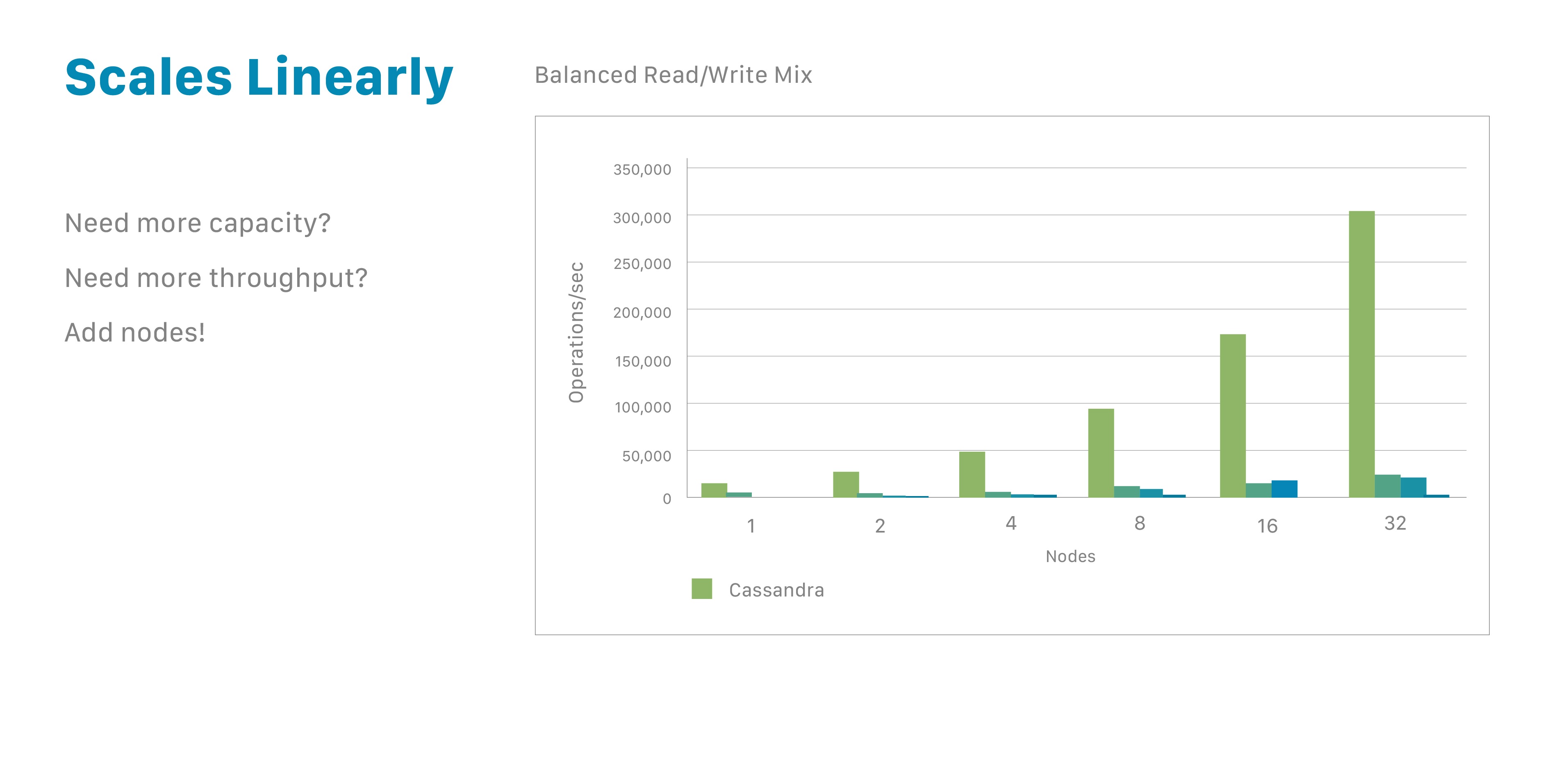
动态扩展其数据库一个让Cassandra备受欢迎的原因是它使开发人员能够使用现成的硬件,在没有停机的情况下动态扩展其数据库。您可以根据需要进行扩展,也可以根据应用程序的需求进行缩减。
也许您习惯于使用Oracle或MySQL数据库。如果是这样,您就知道要支持更多用户或存储容量,需要增加更多的CPU功率、内存或更快的磁盘。每一项都需要显著的成本。然而:最终,您仍然会遇到一些限制和约束。
相比之下,Cassandra使增加其管理数据量变得非常简单。由于它基于节点,Cassandra采用水平扩展(也称为横向扩展),使用较低成本的通用硬件。要使容量翻倍或吞吐量翻倍,只需将节点数量翻倍。就是这么简单。需要更多性能?增加更多节点 – 无论是8个还是8,000个 – 而不会导致停机。您还可以根据需要进行灵活的缩减。
这种线性可扩展性基本上可以无限期地应用。这一能力已经成为Cassandra的关键优势之一。
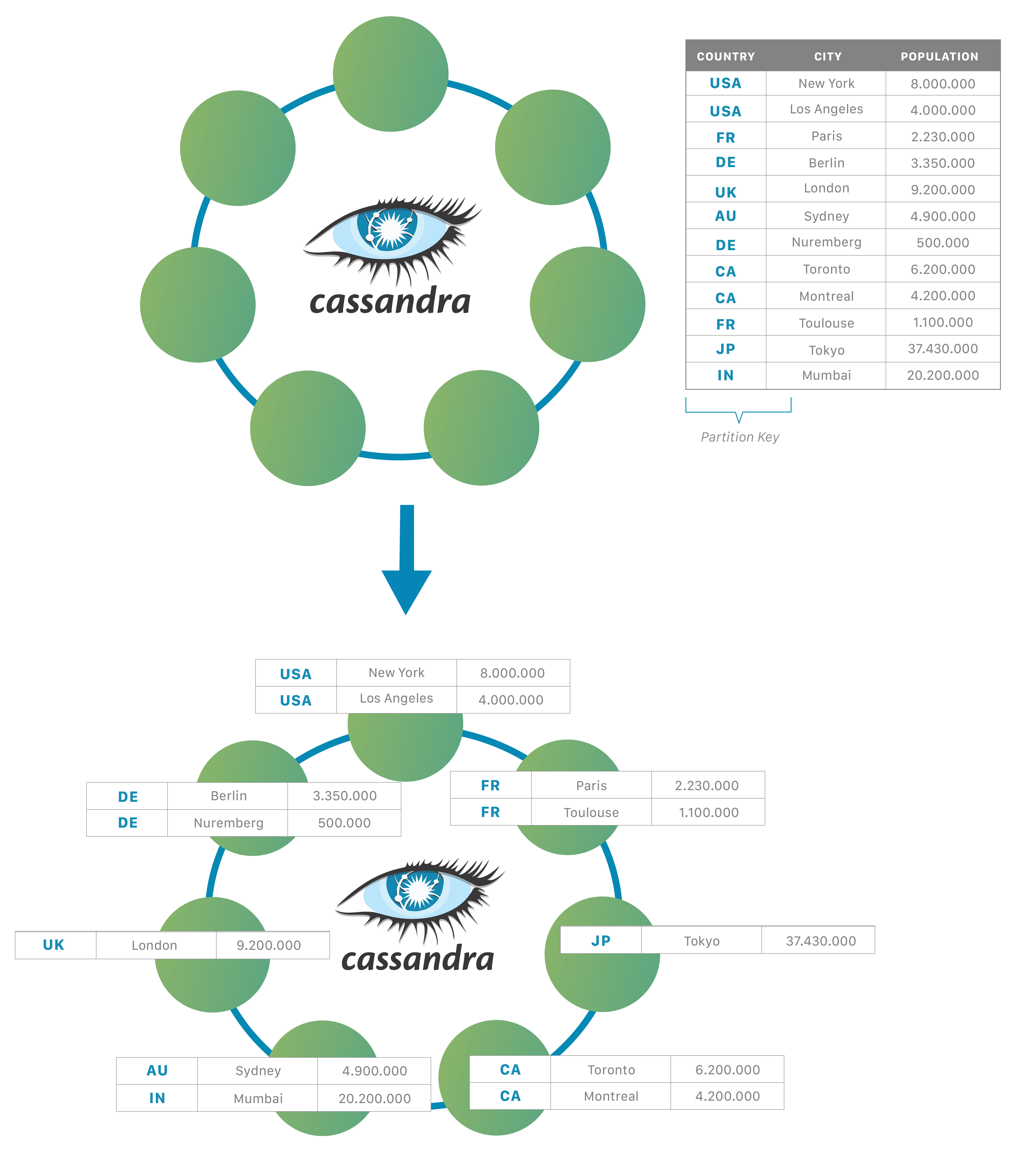
介绍分区
线性扩展在Cassandra中,数据本身是自动分布的,这带来了(积极的)性能影响。它通过使用分区来实现这一点。每个节点拥有特定的标记集,Cassandra根据这些标记在整个集群中的范围分布数据。分区键负责在节点之间分布数据,并且对于确定数据位置很重要。当数据插入到集群中时,第一步是对分区键应用哈希函数。输出用于确定哪个节点(基于标记范围)将获得数据。
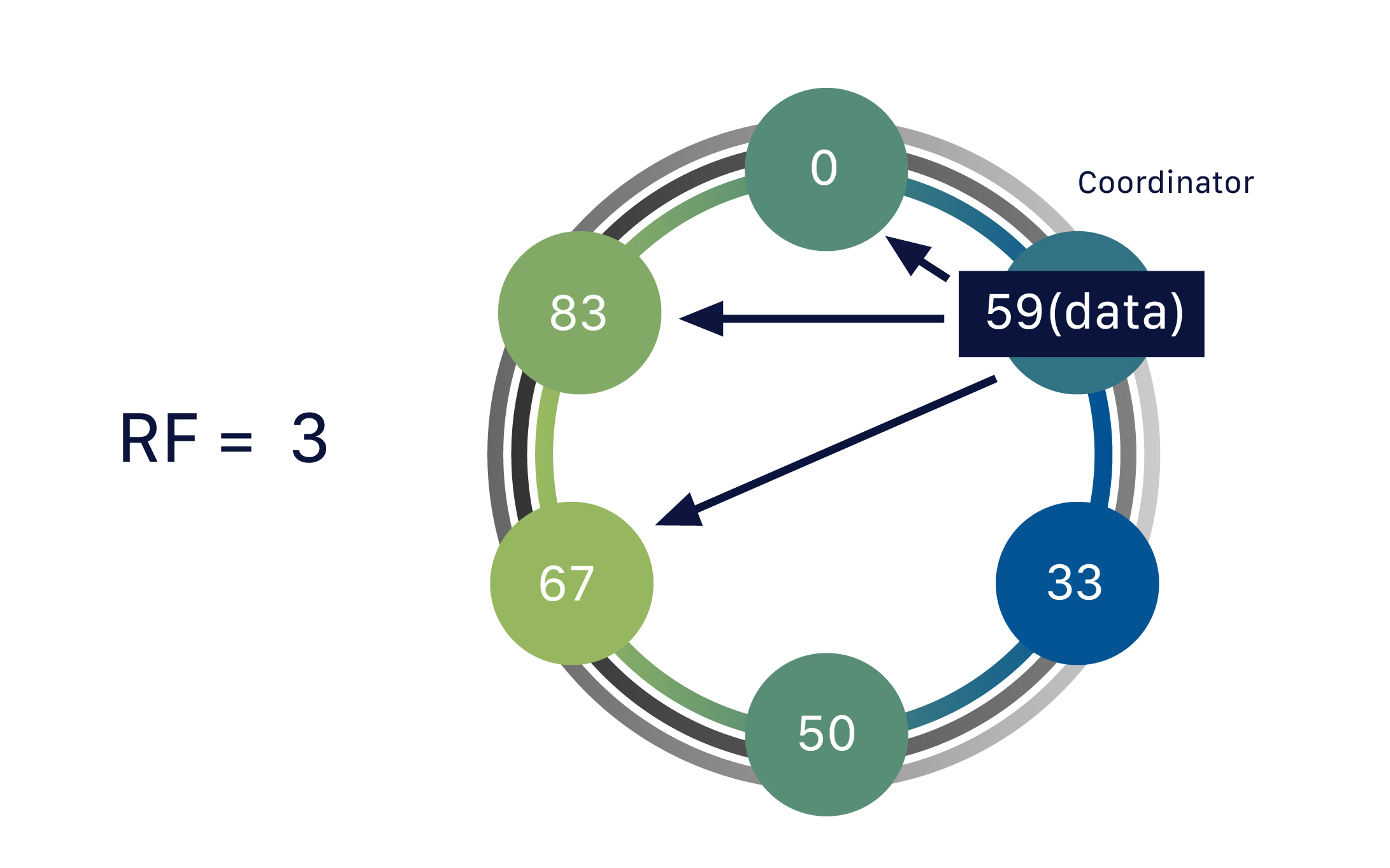
复制确保可靠性和容错性当数据进入时,数据库的协调器负责分配给定的分区 – 我们称之为分区59。请记住,集群中的任何节点都可以担任协调器的角色。正如我们之前提到的,节点之间进行通信,彼此交流关于哪个节点负责什么范围的信息。因此,在我们的例子中,协调器进行查找:哪个节点有标记59?当找到正确的节点时,它将数据转发到该节点。拥有该范围数据的节点称为副本节点。一份数据可以被复制到多个(副本)节点,确保可靠性和容错性。到目前为止,我们的数据只被复制到一个副本。这表示复制因子为一,即RF = 1。
协调器节点不是单一位置;如果是这样,系统将变得脆弱。它只是在特定时刻收到请求的节点。任何节点都可以充当协调器。
复制确保可靠性和容错性
多个(副本)节点一份数据可以被复制到多个(副本)节点,确保了可靠性和容错性。Cassandra支持复制因子(RF)的概念,描述了在数据库中应存在多少份数据副本。到目前为止,我们的数据只被复制到一个副本(RF = 1)。如果我们将复制因子提高到两个(RF = 2),数据需要存储在第二个副本上 – 因此每个节点除了其主要范围外,还负责一个次要范围的标记。复制因子为三确保了在该特定标记范围内有三个节点(副本),数据存储在另一个节点上。
Cassandra的分布式特性Cassandra的分布式特性使其更具弹性和性能。当我们为相同的数据拥有多个副本时,这真正发挥了作用。这有助于系统在出现问题时自我修复,例如如果一个节点宕机,硬盘故障或AWS重置实例。复制确保数据不会丢失。如果对数据发出请求,即使我们的一个副本宕机,其他两个仍然可用来满足请求。协调器还为该数据存储了一个“提示”,当宕机的副本恢复时,它将找出自己错过了什么,并迎头赶上其他两个副本的速度。不需要手动操作,这完全是自动完成的。
使用多个副本还具有性能优势。因为我们不限于单个实例,我们有三个节点(副本)可以访问,为我们的操作提供数据,我们可以在它们之间进行负载均衡以实现最佳性能。
Cassandra会自动在不同的数据中心之间复制数据。您的应用程序可以将数据写入美国西海岸的Cassandra节点,该数据将自动在亚洲和欧洲的节点中的数据中心中可用。这带有积极的性能优势 – 尤其是如果您支持全球用户基础。在一个依赖云计算和快速数据访问的世界中,由于距离而导致的延迟对用户没有不适。
调整一致性级别
可用的分区容忍数据库我们一直在谈论分布式系统和可用性。如果您熟悉CAP定理,Cassandra默认是一个AP(可用的分区容忍)数据库,因此它“始终在线”。但您确实可以在每个查询的基础上配置一致性。在这个背景下,一致性级别表示在操作被视为成功之前,协调器必须获得的Cassandra节点的最小数量,以确认读取或写入操作。通常,您将根据复制因子选择一致性级别(CL)。可用的分区容忍数据库在下面的例子中,我们的数据被复制到三个节点。我们设置了CL=QUORUM(Quorum指的是大多数,在这种情况下是2个副本或RF/2 +1),因此协调器需要从两个副本中获得确认,以便将查询视为成功。
与其他计算任务一样,学习如何调整此功能以获得理想的性能、可用性和数据完整性可能需要一些技巧,但您可以以非常细致的方式控制它,这意味着您可以详细控制部署。
Cassandra是部署不可知的最终,Cassandra是部署不可知的。它不关心您把它放在哪里 – 在本地、云提供商、多个云提供商。您可以在单个数据库中使用这些的组合。这为软件开发人员提供了最大的灵活性。
快速开始
感兴趣开始使用Cassandra吗?按照以下步骤进行操作:
步骤1:使用Docker获取Cassandra 您需要在计算机上安装Docker Desktop for Mac、Docker Desktop for Windows或类似的软件。
Apache Cassandra也可以作为tarball或软件包下载。
docker pull cassandra:latest
步骤2:启动Cassandra Docker网络允许我们访问容器的端口而不在主机上暴露它们。
docker network create cassandra
docker run --rm -d --name cassandra --hostname cassandra --network cassandra cassandra
步骤3:创建文件 Cassandra查询语言(CQL)与SQL非常相似,但适用于Cassandra的无JOIN结构。
创建一个名为data.cql的文件,并将以下CQL脚本粘贴到其中。此脚本将创建一个键空间(keyspace),即Cassandra复制其数据的层次,创建一个用于存储数据的表,并将一些数据插入该表:
-- 创建键空间
CREATE KEYSPACE IF NOT EXISTS store WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : '1' };
-- 创建表
CREATE TABLE IF NOT EXISTS store.shopping_cart (
userid text PRIMARY KEY,
item_count int,
last_update_timestamp timestamp
);
-- 插入一些数据
INSERT INTO store.shopping_cart
(userid, item_count, last_update_timestamp)
VALUES ('9876', 2, toTimeStamp(now()));
INSERT INTO store.shopping_cart
(userid, item_count, last_update_timestamp)
VALUES ('1234', 5, toTimeStamp(now()));
步骤4:使用CQLSH加载数据 CQL shell,或称为cqlsh,是与数据库交互的一种工具。我们将使用它使用刚刚保存的脚本将一些数据加载到数据库中。
docker run --rm --network cassandra -v "$(pwd)/data.cql:/scripts/data.cql" -e CQLSH_HOST=cassandra -e CQLSH_PORT=9042 -e CQLVERSION=3.4.6 nuvo/docker-cqlsh
注意:Cassandra服务器本身(您运行的第一个docker run命令)需要几秒钟来启动。如果服务器尚未完成初始化序列,上述命令将引发错误,请给它一些时间来启动。
步骤5:交互式CQLSH 与SQL shell类似,您当然也可以使用CQLSH交互式地运行CQL命令。
docker run --rm -it --network cassandra nuvo/docker-cqlsh cqlsh cassandra 9042 --cqlversion='3.4.5'
这应该会给您一个类似于以下的提示:
Connected to Test Cluster at cassandra:9042.
[cqlsh 5.0.1 | Cassandra 4.0.4 | CQL spec 3.4.5 | Native protocol v5]
Use HELP for help.
cqlsh>
步骤6:读取一些数据
SELECT * FROM store.shopping_cart;
步骤7:写入更多数据
INSERT INTO store.shopping_cart (userid, item_count) VALUES ('4567', 20);
步骤8:清理
docker kill cassandra
docker network rm cassandra
恭喜!
嘿,这不是那么难,是吧?
要了解更多信息,建议执行以下下一步:
- 阅读Cassandra Basics,了解主要概念以及Cassandra在高层次上的工作原理。
- 要更详细地了解Cassandra,请查看文档。
- 浏览案例研究,了解我们全球社区中其他用户如何从Cassandra中获取价值。
chat
Cassandra 介绍
Cassandra(Apache Cassandra)是一个高度可伸缩、分布式、开源的NoSQL数据库系统。
它最初由Facebook开发,并在2008年成为Apache软件基金会的顶级项目。
Cassandra被设计用于处理大规模的数据,具有强大的横向扩展能力,适用于分布式、分区式的数据存储和检索。
以下是一些 Cassandra 的关键特性和概念:
-
分布式架构: Cassandra采用分布式架构,数据可以存储在多个节点上。这使得它能够容易地扩展以适应大规模的数据和负载。
-
分区和副本: Cassandra将数据分为多个分区,每个分区可以分布在集群中的不同节点上。每个分区都有多个副本,分布在集群中的不同节点上,以提高数据的可用性和容错性。
-
无单点故障: Cassandra没有单点故障,因为每个节点都可以独立运行,并且数据在多个节点上复制。如果一个节点失效,系统仍然可以从其他节点获取数据。
-
支持CAP定理: Cassandra采用AP(可用性和分区容忍性)模型,这意味着它在分布式环境下更注重可用性和分区容忍性,而不是强一致性。
-
灵活的数据模型: Cassandra是一个面向列的数据库系统,支持动态添加和删除列。这使得它能够灵活地适应不同类型和变化频繁的数据模型。
-
CQL(Cassandra Query Language): Cassandra引入了CQL,这是一种类似于SQL的查询语言,使得开发人员更容易从关系型数据库迁移到Cassandra。
-
Tuneable Consistency: Cassandra允许用户在一致性和性能之间进行权衡。用户可以根据应用程序的需求调整读写操作的一致性级别。
-
支持多数据中心: Cassandra支持多数据中心部署,使得数据在全球范围内的分布变得更加容易。
总体而言,Cassandra 是一个适用于大规模、高可用性需求的分布式数据库系统,尤其在需要处理海量数据、具备横向扩展能力的场景中表现出色。
类似 Cassandra 的开源 nosql 有哪些?
有许多类似于Cassandra的开源NoSQL数据库,它们都在不同的场景中展现出自己的优势。以下是一些常见的类似Cassandra的开源NoSQL数据库:
-
Apache HBase: HBase是一个基于Hadoop的分布式、面向列的NoSQL数据库。它设计用于处理大规模的数据,并且提供了高度可扩展性和高吞吐量。
-
MongoDB: MongoDB是一个面向文档的NoSQL数据库,它以BSON(Binary JSON)格式存储数据。MongoDB非常灵活,支持动态模式,适用于各种应用场景。
-
Couchbase: Couchbase是一个分布式的、多模型的NoSQL数据库,支持键值对、文档和图形数据。它注重性能和可伸缩性,并提供了内置的缓存功能。
-
Amazon DynamoDB: DynamoDB是AWS提供的托管式NoSQL数据库服务,具有高可用性、横向扩展和灵活的数据模型。它适用于云原生应用和需要无服务器架构的场景。
-
Apache CouchDB: CouchDB是一个分布式的面向文档的数据库,支持多主复制和离线数据同步。它的设计目标是提供可靠的、高性能的数据存储。
-
Riak: Riak是一个分布式的键值对数据库,具有高可用性和容错性。它支持水平扩展,适用于需要强大的分布式能力的应用。
-
Redis: Redis是一个基于内存的键值对存储系统,也可以用作缓存和消息代理。它具有出色的性能和灵活的数据结构支持。
-
Neo4j: Neo4j是一个图形数据库,专注于处理图形结构数据。它适用于需要深度关系分析的应用,如社交网络和推荐系统。
这只是一小部分NoSQL数据库的例子,市场上还有许多其他NoSQL数据库,每个都有其独特的特点和适用场景。选择适合特定需求的NoSQL数据库通常取决于应用程序的数据模型、性能需求和可扩展性要求。
Cassandra 的独特特点和应用场景?为什么选择 Cassandra 呢?
Cassandra具有一些独特的特点,这些特点使其在特定的应用场景中成为一个合适的选择:
-
分布式和横向扩展: Cassandra的设计目标之一是支持横向扩展,能够轻松地在集群中添加新的节点,以应对数据量的增长。这使得Cassandra非常适合处理大规模数据和高负载。
-
无单点故障: Cassandra的分布式架构和数据复制机制使得系统具有高可用性。即使某个节点失效,数据仍然可以从其他节点访问,不会导致整个系统的故障。
-
灵活的数据模型: Cassandra是一个面向列的数据库,支持动态添加和删除列,适应于多变的数据模型。这种灵活性使其能够存储不同类型和结构的数据。
-
CAP模型的支持: Cassandra采用AP(可用性和分区容忍性)模型,这意味着在网络分区的情况下,系统会保持可用性而不是强一致性。这使得Cassandra适合那些对系统的可用性要求更高的应用场景。
-
高性能读写: Cassandra的设计优化了读写性能,支持快速的数据插入和查询操作。这使得它适用于需要低延迟读写的应用,如实时分析和日志存储。
-
支持多数据中心部署: Cassandra允许在多个数据中心之间进行数据复制,这使得它在全球范围内的分布式部署中表现出色。
-
可伸缩性: Cassandra在硬件水平上可伸缩,能够轻松处理大量的数据和请求。这使得它非常适合需要高度可伸缩性的应用,如云服务和大规模Web应用。
应用场景:
-
大规模数据存储和查询: Cassandra适用于需要处理大量数据和高并发查询的场景,如分布式日志存储、事件追踪和时间序列数据。
-
实时分析: 由于其高性能读写和横向扩展的特点,Cassandra可以用于实时分析和报表生成,支持快速的数据查询操作。
-
时序数据处理: Cassandra的分布式架构和面向列的特性使其成为处理时序数据(如传感器数据、日志数据)的理想选择。
-
用户个性化推荐: 适用于需要存储和查询用户行为数据,以提供个性化推荐的应用场景。
总的来说,选择 Cassandra 的原因包括其强大的横向扩展能力、高可用性、灵活的数据模型以及适用于大规模分布式环境的特点。然而,具体的选择仍应该根据应用程序的需求和特定的使用情境来进行评估。
给出 Cassandra 的深入学习资料,包含网址
以下是一些深入学习 Cassandra 的资源,包括在线文档、教程和书籍。
请注意,链接可能会发生变化,建议在查找时确保获取最新版本的文档和资源。
- 官方文档:
- 在线教程:
- DataStax Academy:DataStax是一个与Cassandra密切相关的公司,其学院提供了丰富的Cassandra培训资源,包括免费的在线课程。
- 书籍:
- “Cassandra: The Definitive Guide” by Eben Hewitt:这本书是关于Cassandra的权威指南,涵盖了从基础到高级概念的全面内容。
- “Learning Apache Cassandra - Manage Fault Tolerant and Scalable Real-Time Data” by Mat Brown:这是一本介绍Cassandra的实用指南,适合初学者。
- 社区资源:
- Cassandra 官方邮件列表:通过邮件列表可以获取到社区的最新动态和与其他Cassandra用户交流经验。
- Stack Overflow 的 Cassandra 标签:在Stack Overflow上,你可以找到许多关于Cassandra的问题和答案。
- GitHub 资源:
- Cassandra GitHub Repository:Cassandra的源代码仓库,你可以在这里查看最新的代码和提交。
- 视频教程:
- DataStax YouTube Channel: DataStax在YouTube上有一系列关于Cassandra的视频教程,包括基础概念和高级主题。
请确保检查官方文档的版本,以确保你查看的是与你使用的Cassandra版本相对应的文档。
学习Cassandra时,最好深入了解其基本概念、架构、CQL查询语言以及性能调优和数据建模等方面的知识。
参考资料
更多学习
更多实时资讯,前沿技术,生活趣事。尽在【老马啸西风】
交流社群:[交流群信息](https://mp.weixin.qq.com/s/rkSvXxiiLGjl3S-ZOZCr0Q)
