inner join 优化小表驱动大表介绍
在数据库查询中
SELECT * FROM 小表 INNER JOIN 大表 ON 小表.id=大表.id
效率高于
SELECT * FROM 大表 INNER JOIN 小表 ON 小表.id=大表.id
前者时间更短!
inner join 原理 AND 小表驱动大表的原因
其实其他join也是这个原理,只是MySQL只对inner join 自动的进行小表驱动大表的有优化。
join的原理是,查询出每一条前表的数据,然后放入join_buffer(可理解为一个内存区域即可)中,直到join_buffer中装不下数据,然后将后表加载进内存,和这些数据进行匹配,找出连接的数据,然后后表存内存中踢出;
如果前表中还有数据,就再一条一条的查找出来,一条一条的放入join_buffer中,直到join_buffer中装不下数据,然后将后表加载进内存,和这些数据进行匹配,找出连接的数据,然后后表存内存中踢出;最后合并查询出所有的数据!
join_buffer的默认大小为256KB,可以使用命令 show VARIABLES LIKE '%join_buffer%',查看自己 mysql 的join_buffer的大小:
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| join_buffer_size | 262144 |
+------------------+--------+
1 row in set, 1 warning (0.00 sec)
以上 join 原理核心点有两个:
-
前表查询出数据需要一条一条的加入到join_buffer中,这需要IO操作,比较耗时,因此如果前表比较小,那么效率就高,这是小表驱动大表的一个主要原因
-
将join_buffer中的数据和后表中的数据进行匹配,如果连接得字段可以使用索引,那么效率就更高了,但是如果没有索引,抛开核心点1得IO操作时间,那么小表驱动大表和大表驱动小表效率其实是差不多得,因为都需要双循环,MN 和NM是差不多的。
总结
前表查询出数据需要一条一条的加入到join_buffer中,这需要IO操作,比较耗时,因此如果前表比较小,那么效率就高,这是小表驱动大表的一个主要原因;
将join_buffer中的数据和后表中的数据进行匹配,如果连接得字段可以使用索引,那么效率就更高了
MySQL表连接及其优化
本文基于MySQL 5.7版本进行探究,由于MySQL 8中引入了新的连接方式hash join,本文可能不适用MySQL8版本
MySQL的七种连接方式介绍
在MySQL中,常见的表连接方式有4类,共计7种方式:
INNER JOIN:inner join是根据表连接条件,求取2个表的数据交集; LEFT JOIN:left join是根据表连接条件,求取2个表的数据交集再加上左表剩下的数据;此外,还可以使用where过滤条件求左表独有的数据。 RIGHT JOIN:right join是根据表连接条件,求取2个表的数据交集再加上右表剩下的数据;此外,还可以使用where过滤条件求右表独有的数据。 FULL JOIN:full join是左连接与右连接的并集,MySQL并未提供full join语法,如果要实现full join,需要left join与right join进行求并集,此外还可以使用where查看2个表各自独有的数据。
通过图形来表现,各种连接形式的求取集合部分如下,蓝色部分代表满足join条件的数据:
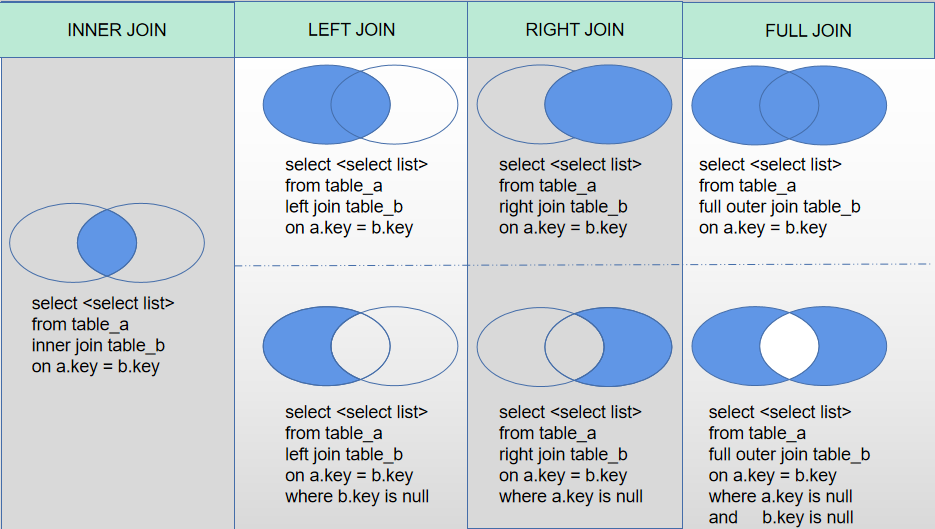
MySQL Join算法
在MySQL 5.7中,MySQL仅支持Nested-Loop Join算法及其改进型Block-Nested-Loop Join算法,在8.0版本中,又新增了Hash Join算法,这里只讨论5.7版本的表连接方式。
Nested-Loop Join算法
嵌套循环连接算法(NLJ)从第一个循环的表中读取1行数据,并将该行传递到下一个表进行连接运算,如果符合条件,则继续与下一个表的行数据进行连接,知道连接完所有的表,然后重复上面的过程。
简单来讲Nested-Loop Join就是编程中的多层for循环。
假设存在3个表进行连接,连接方式如下:
table join type
------ -------------
t1 range
t2 ref
t3 ALL
如果使用 NLJ 算法进行连接,伪代码如下:
for each row in t1 matching range {
for each row in t2 matching reference key {
for each row in t3 {
if row satisfies join conditions, send to client
}
}
}
Block Nested-Loop Join算法
块嵌套循环(BLN)连接算法使用外部表的行缓冲来减少对内部表的读次数。
例如,将外部表的10行数据读入缓冲区并将缓冲区传递到下一个内部循环,则可以将内部循环中的每一行与缓冲区的10行数据进行比较,此时,内部表读取的次数将减少为1/10。
如果使用BNL算法,上述连接的伪代码可以写为:
for each row in t1 matching range {
for each row in t2 matching reference key {
store used columns from t1, t2 in join buffer
if buffer is full {
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions, send to client
}
}
empty join buffer
}
}
}
if buffer is not empty {
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions, send to client
}
}
}
MySQL Join Buffer有如下特点:
-
join buffer可以被使用在表连接类型为ALL,index,range。换句话说,只有索引不可能被使用,或者索引全扫描,索引范围扫描等代价较大的查询才会使用Block Nested-Loop Join算法;
-
仅仅用于连接的列数据才会被存在连接缓存中,而不是整行数据
-
join_buffer_size系统变量用来决定每一个join buffer的大小
-
MySQL为每一个可以被缓存的join语句分配一个join buffer,以便每一个查询都可以使用join buffer。
-
在执行连接之前分配连接缓冲区,并在查询完成后释放连接缓冲区。
表连接顺序
在关系型数据库中,对于多表连接,位于嵌套循环外部的表我们称为驱动表,位于嵌套循环内部的表我们称为被驱动表,驱动表与被驱动表的顺序对于Join性能影响非常大,接下来我们探索一下MySQL中表连接的顺序。
因为RIGHT JOIN和FULL JOIN在MySQL中最终都会转换为LEFT JOIN,所以我们只需讨论INNER JOIN和LEFT JOIN即可。
其ER图如下:
ON和WHERE的思考
在表连接中,我们可以在2个地方写过滤条件,一个是在ON后面,另一个就是WHERE后面了。
那么,这两个地方写谓词过滤条件有什么区别呢?
我们还是通过INNER JOIN和LEFT JOIN分别看一下。
INNER JOIN
使用INNER JOIN,不管谓词条件写在ON部分还是WHERE部分,其结果都是相同的。
实际上,通过trace报告可以看到,在inner join中,不管谓词条件写在ON部分还是WHERE部分,MySQL都会将SQL语句的谓词条件等价改写到where后面。
LEFT JOIN
可以看到,在LEFT JOIN中,过滤条件放在ON和WHERE之后结果是不同的:
-
如果过滤条件在ON后面,那么将使用左表与右表每行数据进行连接,然后根据过滤条件判断,如果满足判断条件,则左表与右表数据进行连接,如果不满足判断条件,则返回左表数据,右表数据用NULL值代替;
-
如果过滤条件在WHERE后面,那么将使用左表与右表每行数据进行连接,然后将连接的结果集进行条件判断,满足条件的行信息保留。
JOIN优化
JOIN语句相对而言比较复杂,我们根据SQL语句的结构考虑优化方法,JOIN相关的主要SQL结构如下:
-
inner join
-
inner join + 排序(group by 或者 order by)
-
left join
inner join优化
常规inner join的SQL语法如下:
SELECT <select_list>
FROM <left_table> inner join <right_table> ON <join_condition>
WHERE <where_condition>
优化方法:
1.对于inner join,通常是采用小表驱动大表的方式,即小标作为驱动表,大表作为被驱动表(相当于小表位于for循环的外层,大表位于for循环的内层)。这个过程MySQL数据局优化器以帮助我们完成,通常无需手动处理(特殊情况,表的统计信息不准确)。注意,这里的“小表”指的是结果集小的表。
2.对于inner join,需要对被驱动表的连接条件创建索引
3.对于inner join,考虑对连接条件和过滤条件(ON、WHERE)创建复合索引
inner join + 排序(group by 或者 order by)优化
常规inner join+排序的SQL语法如下:
SELECT <select_list>
FROM <left_table>
inner join <right_table>
ON <join_condition>
WHERE <where_condition>
GROUP BY <group_by_list>
ORDER BY <order_by_list>
优化方法:
1.与inner join一样,在被驱动表的连接条件上创建索引
2.inner join + 排序往往会在执行计划里面伴随着Using temporary Using filesort关键字出现,如果临时表或者排序的数据量很大,那么将会导致查询非常慢,需要特别重视;反之,临时表或者排序的数据量较小,例如只有几百条,那么即使执行计划有Using temporary Using filesort关键字,对查询速度影响也不大。如果说排序操作消耗了大部分的时间,那么可以考虑使用索引的有序性来消除排序,接下来对该优化方法进行讨论。
group by和order by都会对相关列进行排序,根据SQL是否存在GROUP BY或者ORDER BY关键字,分3种情况讨论:
| - | SQL语句存在group by | SQL语句存在 order by | 优化操作考虑的排序列 | 解释 |
|---|---|---|---|---|
| 情况1 | 是 | 否 | 只需考虑group by相关列排序问题即可 | 如果SQL语句中只含有group by,则只需考虑group by后面的列排序问题即可 |
| 情况2 | 否 | 是 | 只需考虑order by相关列排序问题即可 | 如果SQL语句中只含有order by,则只需考虑order by后面的列排序问题即可 |
| 情况3 | 是 | 是 | 只需考虑group by相关列排序问题即可 | 如果SQL语句中同时含有group by和order by,只需考虑group by后面的排序即可。因为MySQL先执行group by,后执行order by,通常group by之后 数据量已经较少了,后续的order by直接在磁盘上排序即可 |
参考资料
https://www.cnblogs.com/lijiaman/p/14381027.html
https://blog.csdn.net/weixin_44663675/article/details/112190762
