目的
本文档描述如何配置和管理Hadoop的公平调用队列。
先决条件
确保Hadoop已经安装、配置并正确设置。有关更多信息,请参阅:
- 首次用户的单节点设置。
- 大型分布式集群的集群设置。
概览
Hadoop服务器组件,特别是HDFS NameNode,经历来自客户端的非常大的RPC负载。
默认情况下,所有客户端请求都通过先进先出队列进行路由,并按照到达的顺序提供服务。
这意味着单个用户提交大量请求可能会轻松地压倒服务,导致所有其他用户的服务降级。公平调用队列及相关组件旨在缓解此影响。
设计详细信息
IPC堆栈中有一些组件,它们之间有复杂的相互作用,每个组件都有自己的调整参数。
下面的图像呈现了它们的相互作用的图表概述,将在下面解释。
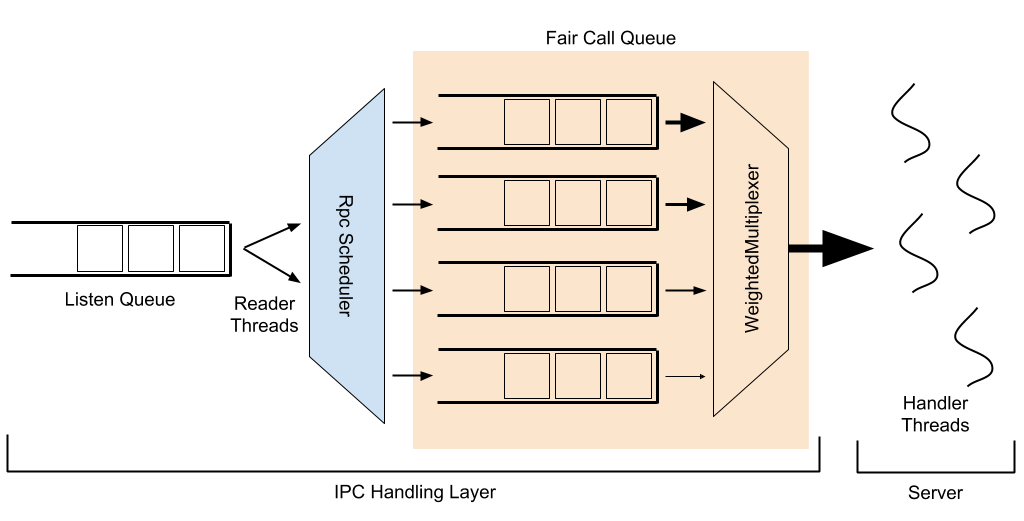
在下面的解释中,加粗的单词是指命名实体或可配置项。
当客户端向IPC服务器发出请求时,此请求首先进入侦听队列。读取器线程从此队列中移除请求,并将它们传递给可配置的RpcScheduler,以分配优先级并将它们放入调用队列;这就是FairCallQueue作为可插拔实现的位置(另一个现有的实现是FIFO队列)。处理器线程从调用队列中接受请求,处理它们,并回应客户端。
默认情况下,与FairCallQueue一起使用的RpcScheduler的实现是DecayRpcScheduler,它保持对每个用户接收到的请求的计数。此计数会随时间衰减;每个扫描周期(默认为5秒),每个用户的请求数都会乘以衰减因子(默认为0.5)。这维护了每个用户请求计数的加权/滚动平均值。每次执行扫描时,所有已知用户的调用计数都会从高到低排名。根据来自该用户的调用所占比例,为每个用户分配优先级(默认为0-3,其中0为最高优先级)。默认优先级阈值为(0.125、0.25、0.5),这意味着调用占总数的50%以上的用户(最多只能有一个这样的用户)被放入最低优先级,调用占总数的25%到50%之间的用户在第二低优先级,调用占总数的12.5%到25%之间的用户在第二高优先级,而所有其他用户都放在最高优先级。在扫描结束时,每个已知用户都有一个缓存的优先级,将在下一次扫描之前使用;在扫描之间出现的新用户将动态计算其优先级。
在FairCallQueue内部,有多个优先级队列,每个队列都被指定一个权重。当请求到达调用队列时,请求将根据调用的当前优先级(由RpcScheduler分配)放入这些优先级队列之一。当处理器线程尝试从调用队列中获取项目时,它从哪个队列中拉取由RpcMultiplexer决定;目前,这是硬编码为WeightedRoundRobinMultiplexer。WRRM根据它们的权重为队列服务请求;默认4个优先级级别的默认权重为(8、4、2、1)。因此,WRRM将为最高优先级队列提供8个请求,为第二高优先级队列提供4个请求,为第三高优先级队列提供2个请求,为最低优先级队列提供1个请求,然后再为最高优先级队列提供8个请求,依此类推。
除了上面讨论的优先级加权机制之外,还有一个可配置的退避机制,其中服务器将向客户端抛出异常而不是处理它;预计客户端将在再次尝试之前等待一段时间(即通过指数回退)。通常,当尝试将请求放入FCQ的优先级队列时(当该队列已满时),将触发退避。这有助于推迟对有影响的客户端的进一步推动,减少负载,并且可能带来实质性的好处。还有一项功能,根据响应时间退避,如果高优先级级别的请求的服务速度太慢,则会导致较低优先级级别的请求退避。例如,如果将优先级1的响应时间阈值设置为10秒,但该队列的平均响应时间为12秒,则较低优先级级别的传入请求将收到回退异常,而优先级级别为0和1的请求将正常进行。其目的是在整体系统负载足够重以导致高优先级客户端受到影响时,迫使较重的客户端退避。
上述讨论在讨论如何对请求进行分组以进行限制时引用了请求的用户。这是通过身份提供程序进行配置的,默认为UserIdentityProvider。用户身份提供程序简单地使用提交请求的客户端的用户名。
但是,可以使用自定义身份提供程序来使用其他分组进行限制,或使用外部身份提供程序。
基于成本的公平调用队列 Cost-based Fair Call Queue
尽管公平调用队列本身在减轻提交大量请求的用户带来的影响方面表现良好,但它并未考虑每个请求处理的成本。
因此,在考虑HDFS NameNode时,提交1000个“getFileInfo”请求的用户将与在某个非常大的目录上提交1000个“listStatus”请求的用户或提交1000个“mkdir”请求的用户具有相同的优先级,而这些请求的成本更高,因为它们需要对namesystem进行独占锁。为了在考虑用户请求的优先级时考虑操作的成本,公平调用队列引入了一种“基于成本”的扩展,该扩展使用用户操作的总处理时间来确定用户应该如何优先考虑。
默认情况下,不考虑排队时间(等待处理的时间)和锁等待时间(等待获取锁的时间)的成本,没有锁的情况下处理的时间被中性地加权(1x),使用共享锁处理的时间被加权高10倍,而使用独占锁处理的时间被加权高100倍。这试图根据用户实际对服务器的负载产生的负载来设置优先级。
要启用此功能,请将costprovder.impl配置设置为org.apache.hadoop.ipc.WeightedTimeCostProvider,如下所述。
配置
本节介绍如何配置公平调用队列。
配置前缀
所有与调用队列相关的配置仅与单个IPC服务器相关。这允许使用单个配置文件配置不同的组件,甚至是组件内的不同IPC服务器,以具有唯一配置的调用队列。
每个配置都以 ipc.<port_number> 为前缀,其中 <port_number> 是IPC服务器用于配置的端口。
例如,ipc.8020.callqueue.impl将调整运行在端口8020的IPC服务器的调用队列实现。
在本节的其余部分,将省略此前缀。
完整的配置列表
| 配置键 | 适用组件 | 描述 | 默认值 |
|---|---|---|---|
backoff.enable |
General | 是否启用当队列已满时客户端退避。 | false |
callqueue.impl |
General | 用作调用队列实现的类的完全限定名称。使用 org.apache.hadoop.ipc.FairCallQueue 作为公平调用队列的实现。 |
java.util.concurrent.LinkedBlockingQueue (FIFO队列) |
scheduler.impl |
General | 用作调度程序实现的类的完全限定名称。与公平调用队列一起使用时,使用 org.apache.hadoop.ipc.DecayRpcScheduler。 |
org.apache.hadoop.ipc.DefaultRpcScheduler (无操作调度程序) 如果使用 FairCallQueue,则默认为 org.apache.hadoop.ipc.DecayRpcScheduler。 |
scheduler.priority.levels |
RpcScheduler, CallQueue | 调度程序和调用队列中使用的优先级级别数量。 | 4 |
faircallqueue.multiplexer.weights |
WeightedRoundRobinMultiplexer | 每个优先级队列分配多少权重。这应该是一个逗号分隔的列表,长度与优先级级别数量相同。权重按2的因子递减(例如,对于4级:8,4,2,1)。 | |
identity-provider.impl |
DecayRpcScheduler | 将用户请求映射到其身份的身份提供者。 | org.apache.hadoop.ipc.UserIdentityProvider |
cost-provider.impl |
DecayRpcScheduler | 将用户请求映射到其成本的成本提供者。要根据处理时间确定成本,请使用 org.apache.hadoop.ipc.WeightedTimeCostProvider。 |
org.apache.hadoop.ipc.DefaultCostProvider |
decay-scheduler.period-ms |
DecayRpcScheduler | 以毫秒为单位的衰减因子应用于用户操作计数的频率。较高的值具有较小的开销,但对客户端行为的更改反应较慢。 | 5000 |
decay-scheduler.decay-factor |
DecayRpcScheduler | 在衰减用户操作计数时,应用的乘法衰减因子。较高的值将更强烈地加权旧操作,实际上为调度程序提供了更长的内存,并且在更长的时间内对重型客户端进行处罚。 | 0.5 |
decay-scheduler.thresholds |
DecayRpcScheduler | 每个优先级队列的客户端负载阈值,作为整数百分比。产生的负载少于在位置i处指定的总操作百分比的客户端将获得优先级i。这应该是一个逗号分隔的列表,长度等于优先级级别数减1(最后一个隐含为100)。阈值按2的因子上升(例如,对于4级:13,25,50)。 | |
decay-scheduler.backoff.responsetime.enable |
DecayRpcScheduler | 是否启用响应时间退避功能。 | false |
decay-scheduler.backoff.responsetime.thresholds |
DecayRpcScheduler | 每个优先级队列的响应时间阈值,作为时间持续时间。如果队列的平均响应时间高于此阈值,则在较低优先级队列中将发生退避。这应该是一个逗号分隔的列表,长度等于优先级级别数。阈值每级增加10秒(例如,对于4级:10秒,20秒,30秒,40秒)。 | |
decay-scheduler.metrics.top.user.count |
DecayRpcScheduler | 发出关于前N(即最重的)用户的度量信息的数量。 | 10 |
weighted-cost.lockshared |
WeightedTimeCostProvider | 在处理阶段中花费时间持有共享(读)锁时应用的权重乘数。 | 10 |
weighted-cost.lockexclusive |
WeightedTimeCostProvider | 在处理阶段中花费时间持有独占(写)锁时应用的权重乘数。 | 100 |
weighted-cost.{handler,lockfree,response} |
WeightedTimeCostProvider | 在不涉及持有锁的处理阶段中花费时间时应用的权重乘数。有关每个阶段的更多详细信息,请参见 org.apache.hadoop.ipc.ProcessingDetails.Timing。 |
1 |
示例配置
以下是将端口8020的IPC服务器配置为使用FairCallQueue,具有DecayRpcScheduler和仅2个优先级级别。
最重的10%用户受到严重处罚,仅处理总请求的1%。
<property>
<name>ipc.8020.callqueue.impl</name>
<value>org.apache.hadoop.ipc.FairCallQueue</value>
</property>
<property>
<name>ipc.8020.scheduler.impl</name>
<value>org.apache.hadoop.ipc.DecayRpcScheduler</value>
</property>
<property>
<name>ipc.8020.scheduler.priority.levels</name>
<value>2</value>
</property>
<property>
<name>ipc.8020.faircallqueue.multiplexer.weights</name>
<value>99,1</value>
</property>
<property>
<name>ipc.8020.decay-scheduler.thresholds</name>
<value>90</value>
</property>
参考资料
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/FairCallQueue.html
