节点存在时更新,不存在时创建
MERGE (p:merge_role { id: 1 }) SET p.id = 1, p.rolename = 'r1';
通过 id 指定唯一约束的字段,然后通过后续的信息 SET 实现 merge。
执行 1 次
╒════════════════════════════════════╕
│n │
╞════════════════════════════════════╡
│(:merge_role {rolename: "r1",id: 1})│
└────────────────────────────────────┘
执行 2 次
╒════════════════════════════════════╕
│n │
╞════════════════════════════════════╡
│(:merge_role {rolename: "r1",id: 1})│
└────────────────────────────────────┘
属于幂等操作。
边 merge 创建,如果节点不存在,则首先创建。
MERGE (from:merge_role_extra { role_id: 1 }) MERGE (to:merge_role { id: 1 }) MERGE (from)-[:role_extra_role_id_to_role_id]->(to)
执行 1 次
╒════════════════════════════════════╕
│n │
╞════════════════════════════════════╡
│(:merge_role {rolename: "r1",id: 1})│
├────────────────────────────────────┤
│(:merge_role_extra {role_id: 1}) │
└────────────────────────────────────┘
此时有一个 merge_role_extra->merge_role 的关系存在。
执行 2 次
不会变化。
和上面一样,属于幂等操作。
merge
MERGE用于保证元素一定存在,作为查询节点和边,若查不到就创建该节点和边。
简单的用法
这个关键字基本上是把create和match合并到一起
merge (robert:Person {name: 'Robert'}) return robert, labels(robert)
本身是不存在这个节点的,所以会直接创建;
如果存在这个节点,发现此时上述命令的作用只是相当于match命令。
创建和获取值
当然也可以比如:
# 查找人物和城市,再查找他们之间“亲人”的关系,若找不到该关系,则创建该关系,并返回它们,
MATCH (n:Person {name:'Robert'}), (m:Person {name:"hanscal"})
MERGE (n)-[r:FAMILY]->(m)
RETURN n.name,type(r),m.name
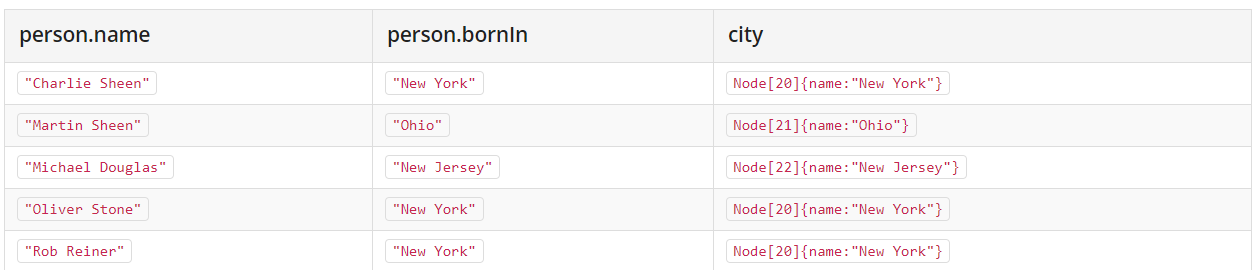
# 从已经存在的节点中,匹配到节点属性值,然后进行批量复制,下面把person节点的bornIn属性,赋值给City这个类型的节点
MATCH (person:Person)
MERGE (city:City { name: person.bornIn })
RETURN person.name, person.bornIn, city
这个操作可以是批量的,比如此处的结果是:
on create
这个实际上是一个限定条件,表达的是当创建的时候(匹配不到时)才执行,不创建就不执行:
# 如果不存在Hanscal这个人名,那么就创建这个人名,并且创建或更新一个create属性
merge (c:Person{name:'Hanscal'})
on create set c.create = timestamp()
return c.name, c.create
如果数据库中已经存在了一个Hanscal,那么就不会set值,
如果不存在,那么就会执行set后面的部分。
on match
这个命令和上述表达差不多,不同的是它是匹配上了就进行set
# 如果匹配上Hanscal这个人名,则对这个人添加属性或者修改属性found=true
MERGE (person:Person{name:"Hanscal"})
ON MATCH SET person.found = TRUE RETURN person.name, person.found
可以同时设置多个属性值:
MERGE (person:Person)
ON MATCH SET person.found = TRUE , person.lastAccessed = timestamp()
RETURN person.name, person.found, person.lastAccessed
on create 和on match 合并
MERGE (keanu:Person { name: 'Keanu Reeves' })
ON CREATE SET keanu.created = timestamp()
ON MATCH SET keanu.lastSeen = timestamp()
RETURN keanu.name, keanu.created, keanu.lastSeen
现在数据库中是没有这个节点的,也就是说会进行创建,但是MATCH后面的不会执行:

Merge关系
MERGE 同样也能被用来match或者create关系。
比如已经存在两个节点,想给他们MERGE一下关系:
# 首先在match到的情况下,如果没有LIVE_IN的关系,那么就创建关系
MATCH (mike:Person { name: 'Mike' }),(Loc:Location { city: 'Boston' })
MERGE (mike)-[r:LIVE_IN]->(Loc)
RETURN mike.name, type(r), Loc.city
结果是:

也可以一下处理多个关系,比如:
MATCH (j:Person { name: 'John' }),(h:Person { name: 'hanscal' })
MERGE (j)-[:LIVE_IN]->(loc:Location {city:"San Francisco"})<-[:BORN_IN]-(h)
RETURN loc
最后结果是,如果有多个节点,那么就会创建多个三元组关系:
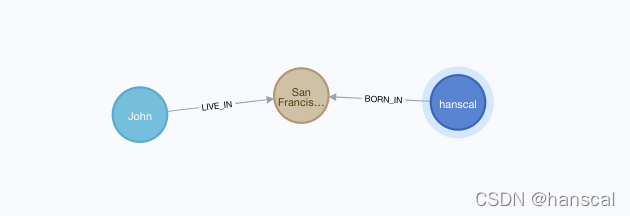
还可以创建一个无向的连接:
MATCH (j:Person { name: 'John' }),(h:Person { name: 'Hanscal' })
MERGE (j)-[r:KNOWS]-(h)
RETURN type(r)
批量操作
批量操作能够快速创建大量节点和关系,比如:
# 将所有Person中出生地和实际的城市直接挂钩!
MATCH (person:Person)
MERGE (city:City { name: person.bornIn })
MERGE (person)-[r:BORN_IN]->(city)
RETURN person.name, person.bornIn, city
# 上面命令还可以改写成如下
MATCH (person:Person)
MERGE (person)-[r:BORN_IN]->(city:City { name: person.bornIn })
RETURN person.name, person.bornIn, city
最后结果是:
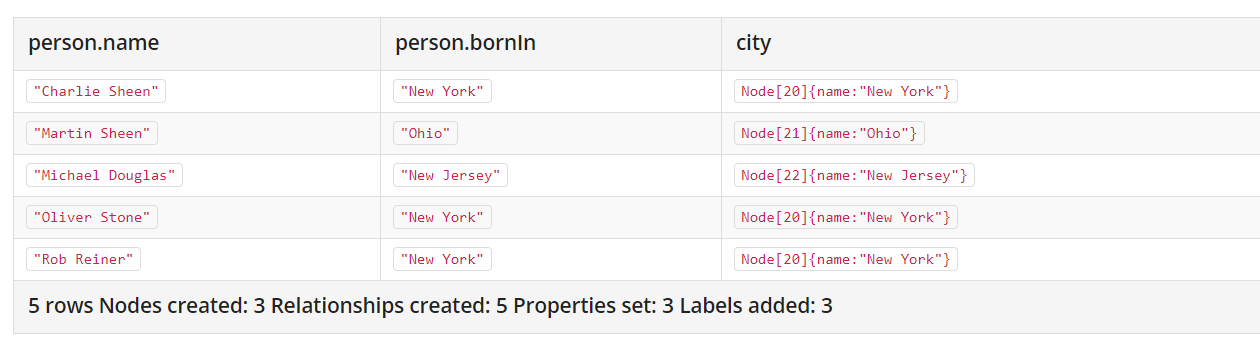
小结
merge 可以考虑和 unwind 批量操作,这样会方便很多。
