前言
大家好,我是老马。
上一篇文章我们简单学习了事务的隔离级别,
另外的一些概念,比如原子性和持久性谈的人不多。
本文就简单聊一下 mysql 中的 redo-log。
REDO-LOG
是什么?
redo log叫做重做日志,是保证事务持久性的重要机制。
当mysql服务器意外崩溃或者宕机后,保证已经提交的事务,确定持久化到磁盘中的一种措施。
为什么需要?
innodb 是以页为单位来管理存储空间的,任何的增删改差操作最终都会操作完整的一个页,会将整个页加载到buffer pool中,然后对需要修改的记录进行修改,修改完毕不会立即刷新到磁盘,因为此时的刷新是一个随机io,而且仅仅修改了一条记录,刷新一个完整的数据页的话过于浪费了。
但是如果不立即刷新的话,数据此时还在内存中,如果此时发生系统崩溃最终数据会丢失的,因此权衡利弊,引入了redo log,也就是说,修改完后,不立即刷新,而是记录一条日志,日志内容就是记录哪个页面,多少偏移量,什么数据发生了什么变更。
这样即使系统崩溃,再恢复后,也可以根据redo日志进行数据恢复。
另外,redo log 是循环写入固定的文件,是顺序写入磁盘的。
主要作用
redo log 的作用主要是
-
崩溃恢复,数据库实例在重启的时候,总会重新加载redo log里面的日志信息(last checkpoint之后的)
-
更加快的commit,数据库写redo log 是追加写,写完就可以commit,后续数据页持久化到ibd文件是后台线程在刷,即刷脏页。
redo 日志格式
type | space ID | page number | data
type:该条redo日志的类型,redo日志设计大约有53种不同的类型日志。
space ID:表空间ID。
page number:页号。
data:该条redo日志的具体内容。(比如:某个事务将系统表空间中的第100号页面中偏移量为1000处的那个字节的值1改成2)
redo log block和日志缓冲区
InnoDB为了更好的进行系统崩溃恢复,把redo日志都放在了大小为512字节的块(block)中。
为了解决磁盘速度过慢的问题而引入了Buffer Pool。
同理,写入redo日志时也不能直接直接写到磁盘上,实际上在服务器启动时就向操作系统申请了一大片称之为redo log buffer的连续内存空间,翻译成中文就是redo日志缓冲区,我们也可以简称为log buffer。
这片内存空间被划分成若干个连续的redo log block,我们可以通过启动参数innodb_log_buffer_size来指定log buffer的大小,该启动参数的默认值为16MB。
向log buffer中写入redo日志的过程是顺序的,也就是先往前边的block中写,当该block的空闲空间用完之后再往下一个block中写。
以组的方式写入
在一个事务中,可能会发生多次的数据修改,对应的就是多个数据页多个偏移量位置的字段变更,也就是说会产生多条redo log,而且因为在同一个事物中,这些redo log,也是不可再分的,也就是说,一个组的redo log在持久化的时候,不能部分成功,部分失败,否则的话,就会破坏事务的原子性。
另外为了提升性能redo log是按照块组织在一起,然后写入到磁盘中的,类似于数据的页,而且引入了redo log buffer,默认的大小为16MB。
buffer中分了很多的block,每个block的大小为512kb,每一个事务产生的所有redo log称为一个group。
配置
可以指定配置:
innodb_log_files_in_group =16
innodb_log_file_size =256M
innodb_log_buffer_size =64M
redo log的刷盘时机
redo log听着挺厉害的,但是刚开始也是在内存中的一个东西,万一,还没有持久化到磁盘就发生了系统崩溃怎么处理。
状态
show engine innodb status
可以看的如下信息
Log sequence number 2830566 日志序列号值
Log flushed up to 2830566 redo 刷新到磁盘的值
Pages flushed up to 2830566 下次做checkpoint 的值
Last checkpoint at 2830557 checkpoint的值,这个值之前的代表已经刷新到ibd文件,不需要检查,这个值之后的才需要进行崩溃恢复
0 pending log flushes, 0 pending chkp writes
97 log i/o's done, 0.00 log i/o's/second
这个便于redo log的刷盘时机有关:通过一个参数控制:innodb_flush_log_at_trx_commit
1、commit 的时候进行刷盘:这也是最保险的,因为如果这个时候崩溃了代表没有commit成功,因此,也不用恢复什么数据。
2、commit 的时候,只是刷新近os的内核缓冲区,具体的刷盘时机不确定。
0、后台线程,每s刷新一次到磁盘中。
为了保证事务的持久性,推荐使用1。
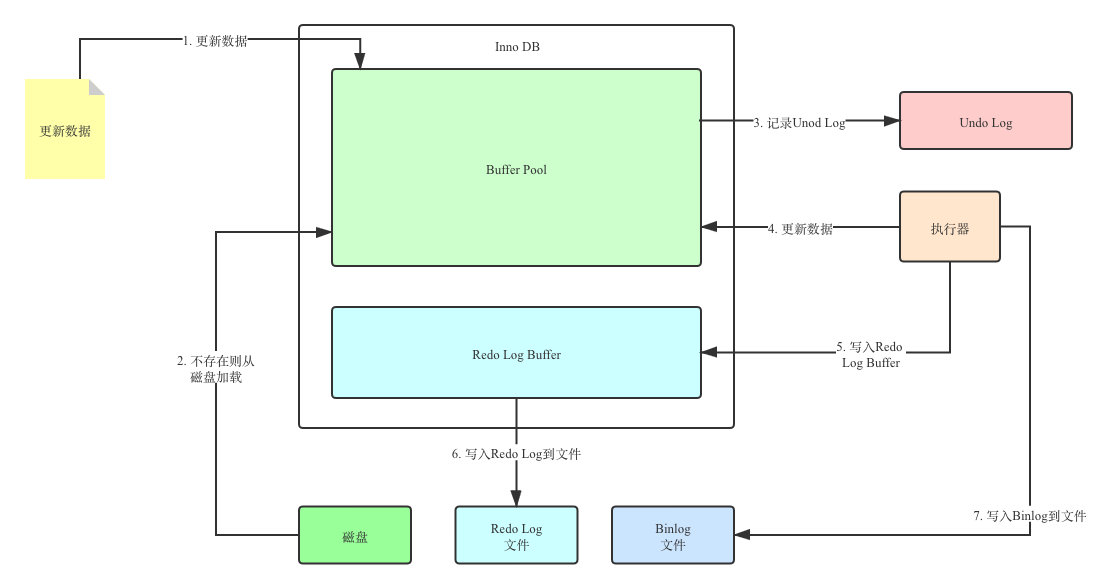
一条更新语句的执行步骤
update table set id = 10 where id = 1;
-
连接数据库 …
-
判断id=1的这条记录在不在buffer pool中,在的话之间更新,否则从磁盘中加载到buffer pool中,然后进行更新
-
将这个更新操作记录到redo log中,记录的是一个物理日志。此时redo log是一个prepare状态
-
记录该操作的binlog,并且将binlog刷盘
-
提交事务,对redo log进行提交。
Mysql的两阶段提交
对于Mysql Innodb存储引擎而言,每次修改后,不仅需要记录Redo log还需要记录Binlog,而且这两个操作必须保证同时成功或者同时失败,否则就会造成数据不一致。
为此Mysql引入两阶段提交。
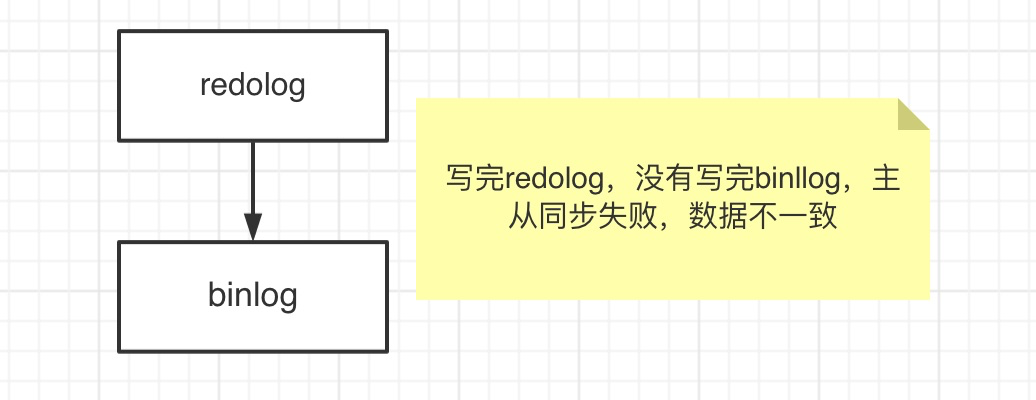
1、如果先写redolog再写binlog
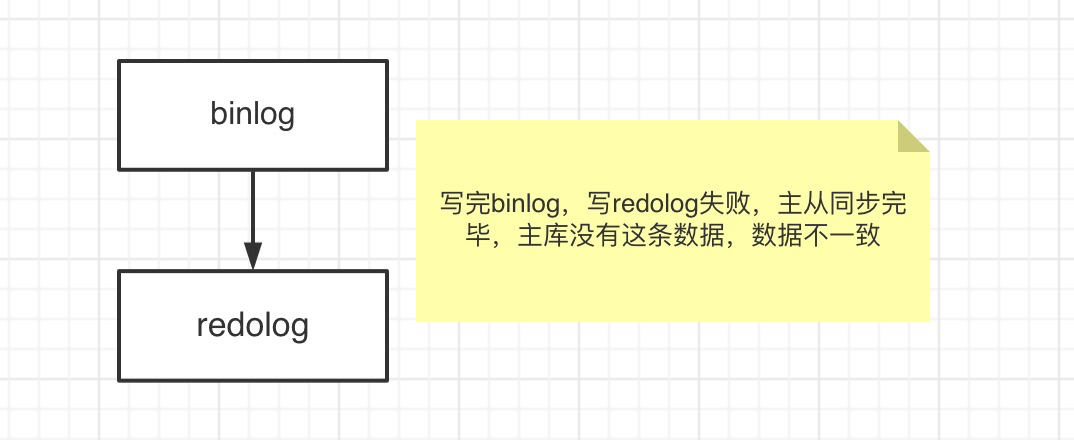
2、先写binlog再写redolog
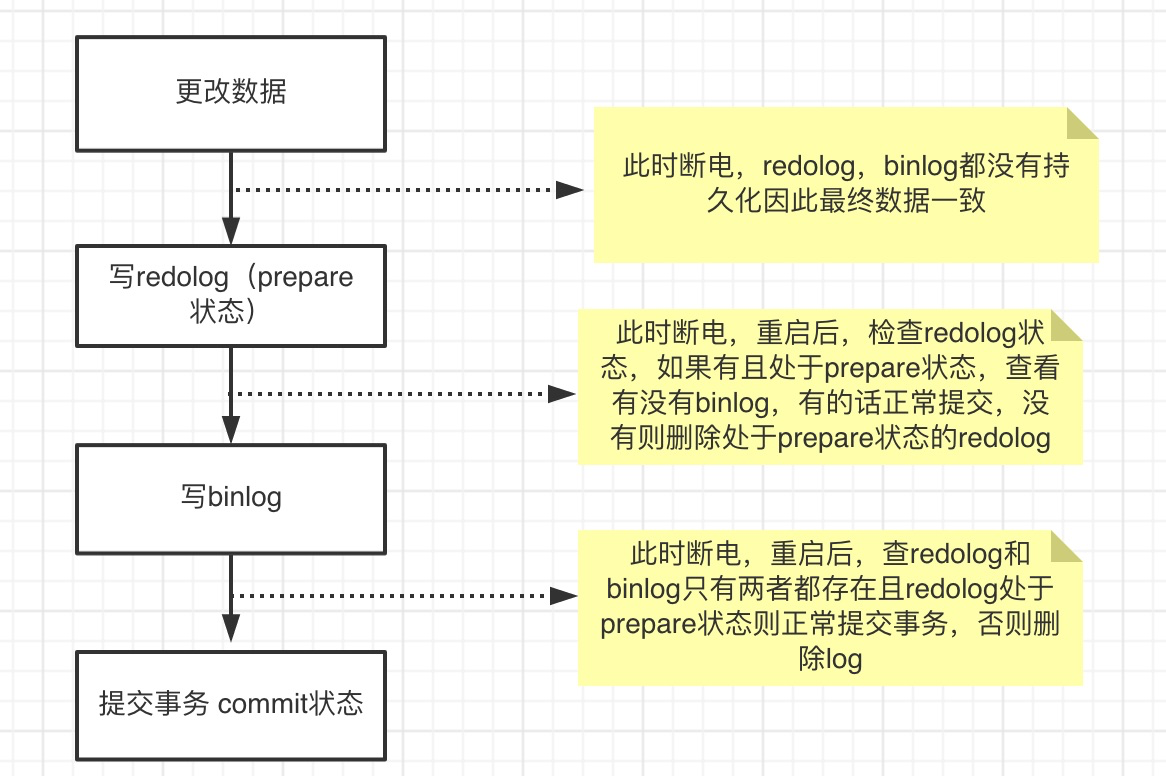
3、两阶段提交
总结

小结
Redo-log 保证了数据库 crash 之后,数据可以正常恢复。
当然,如果每一步都刷盘也可以,但是这样性能会很差。
内存+顺序写+定时异步提交,提升程序性能。
两段式提交解决数据不一致的问题,这个思想基本是通用的。
希望本文对你有所帮助,如果喜欢,欢迎点赞收藏转发一波。
我是老马,期待与你的下次重逢。
参考资料
https://blog.csdn.net/weixin_43213517/article/details/117457184
https://blog.csdn.net/mizepeng/article/details/124028904
https://zhuanlan.zhihu.com/p/375936941
https://www.jb51.net/article/243172.htm
https://www.jianshu.com/p/90b147488eba
