SQL Index
概念
数据库索引是一种数据结构,它以额外的写入和存储空间来维护索引数据结构为代价,提高了数据库表上数据检索操作的速度。
作用
索引用于快速定位数据,而无需在每次访问数据库表时搜索数据库表中的每一行。可以使用数据库表的一个或多个列创建索引,为快速随机查找和有效访问有序记录提供基础。
索引是从表中选择的数据列的副本,可以非常有效地搜索,还包括一个低级磁盘块地址或到复制的完整数据行的直接链接。有些数据库允许开发人员在函数或表达式上创建索引,从而扩展了索引的功能。
MySQL 索引的使用
索引用于快速查找具有特定列值的行。没有索引,MySQL必须从第一行开始,然后通读整个表以找到相关的行。
table 越大,花费就越多。如果表中有相关列的索引,MySQL可以快速确定要在数据文件中间查找的位置,而无需查看所有数据。这比按顺序读每一行要快得多。
个人经验
- 唯一主键约束
用来保证数据的唯一性
- 唯一联合主键约束
和上面功能类似。
- 提升查询速度
在 WHERE 经常 hit 到的字段,添加索引。
使用场景
-
以快速找到匹配WHERE子句的行。
-
从考虑中消除行。如果要在多个索引之间进行选择,MySQL通常使用查找最小行数的索引(最具选择性的索引)。
-
如果表具有多列索引,那么优化器可以使用索引的任何最左边的前缀来查找行。
例如,如果您对(col1、col2、col3)有三列索引,那么您就对(col1)、(col1、col2)和(col1、col2、col3)有索引搜索功能。
- 在执行连接时从其他表检索行。
MySQL可以更有效地使用列上的索引,如果它们声明为相同的类型和大小。
在此上下文中,如果将VARCHAR和CHAR声明为相同大小,则认为它们是相同的。例如,VARCHAR(10)和CHAR(10)大小相同,但VARCHAR(10)和CHAR(15)大小不同。
- 对于非二进制字符串列之间的比较,两列都应该使用相同的字符集。
如果不进行转换就不能直接比较值,那么比较不同的列(例如,将字符串列与时态或数字列进行比较)可能会阻止使用索引。对于数值列中的1这样的给定值,它可能等于字符串列中的任意数量的值,例如“1”、“1”、“00001”或“01.e1”。这就排除了字符串列的任何索引的使用。
- 查找特定索引列key_col的MIN()或MAX()值。
这是由一个预处理器优化的,它检查您是否使用 WHERE key_part_N = constant 来处理索引中 key_col 之前的所有关键部分。
在本例中,MySQL为每个MIN()或MAX()表达式执行一个键查找,并用常量替换它。如果将所有表达式替换为常量,则查询立即返回。
例如:
SELECT MIN(key_part2),MAX(key_part2)
FROM tbl_name WHERE key_part1=10;
- 如果对一个可用索引的最左边的前缀进行排序或分组,则对表进行排序或分组(例如,按key_part1、key_part2排序)。
如果所有关键部件后面都跟着DESC,则按相反顺序读取关键部件。(或者,如果索引是降序索引,则按前进顺序读取键。)
SELECT key_part3 FROM tbl_name
WHERE key_part1=1
设计思考
为什么设计成树
hash 从速度上来说,不应该是最快的吗?
加速查找速度的数据结构,常见的有两类:
(1)哈希,例如HashMap,查询/插入/修改/删除的平均时间复杂度都是O(1);
(2)树,例如平衡二叉搜索树,查询/插入/修改/删除的平均时间复杂度都是O(lg(n));
不管是读请求,还是写请求,哈希类型的索引,都要比树型的索引更快一些,那为什么,索引结构要设计成树型呢?
- 单行访问
select * from t where name="ryo";
确实是哈希索引更快,因为每次都只查询一条记录。
- 排序查询
分组:group by
排序:order by
比较:<、>
哈希型的索引,时间复杂度会退化为O(n),而树型的“有序”特性,依然能够保持O(log(n)) 的高效率。
为什么是 B+ 树
二叉搜索树
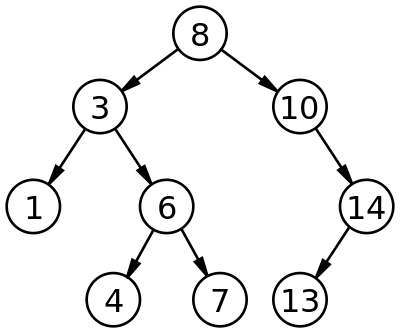
(1)当数据量大的时候,树的高度会比较高,数据量大的时候,查询会比较慢;
(2)每个节点只存储一个记录,可能导致一次查询有很多次磁盘IO;
B 树
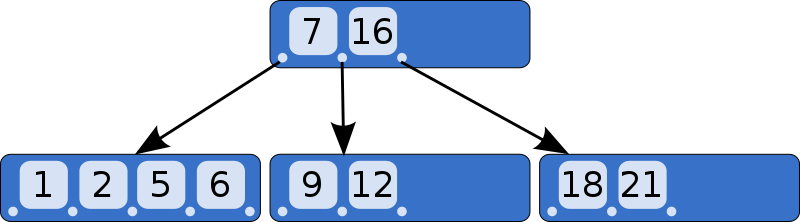
它的特点是:
(1)不再是二叉搜索,而是m叉搜索;
(2)叶子节点,非叶子节点,都存储数据;
(3)中序遍历,可以获得所有节点;
B树被作为实现索引的数据结构被创造出来,是因为它能够完美的利用局部性原理。
- 为何适合做索引
(1)由于是m分叉的,高度能够大大降低;
(2)每个节点可以存储j个记录,如果将节点大小设置为页大小,例如4K,能够充分的利用预读的特性,极大减少磁盘IO;
B+ 树

B+树,如上图,仍是m叉搜索树,在B树的基础上,做了一些改进:
(1)非叶子节点不再存储数据,数据只存储在同一层的叶子节点上;
画外音:B+树中根到每一个节点的路径长度一样,而B树不是这样。
(2)叶子之间,增加了链表,获取所有节点,不再需要中序遍历;
- 优势
这些改进让B+树比B树有更优的特性:
(1)范围查找,定位min与max之后,中间叶子节点,就是结果集,不用中序回溯;
画外音:范围查询在SQL中用得很多,这是B+树比B树最大的优势。
(2)叶子节点存储实际记录行,记录行相对比较紧密的存储,适合大数据量磁盘存储;非叶子节点存储记录的PK,用于查询加速,适合内存存储;
(3)非叶子节点,不存储实际记录,而只存储记录的KEY的话,那么在相同内存的情况下,B+树能够存储更多索引;
量化对比
最后,量化说下,为什么m叉的B+树比二叉搜索树的高度大大大大降低?
大概计算一下:
(1)局部性原理,将一个节点的大小设为一页,一页4K,假设一个KEY有8字节,一个节点可以存储500个KEY,即j=500
(2)m叉树,大概m/2<= j <=m,即可以差不多是1000叉树
(3)那么:
一层树:1个节点,1*500个KEY,大小4K
二层树:1000个节点,1000500=50W个KEY,大小10004K=4M
三层树:10001000个节点,10001000500=5亿个KEY,大小10001000*4K=4G
画外音:额,帮忙看下有没有算错。
可以看到,存储大量的数据(5亿),并不需要太高树的深度(高度3),索引也不是太占内存(4G)。
B-Tree Index Characteristics
在使用=、>、>=、<、<=或操作符之间的表达式中,可以使用b树索引进行列比较。
如果LIKE的参数是一个不以通配符开头的常量字符串,则索引还可以用于LIKE比较。
例如,下面的SELECT语句使用索引:
SELECT * FROM tbl_name WHERE key_col LIKE 'Patrick%';
SELECT * FROM tbl_name WHERE key_col LIKE 'Pat%_ck%';
在第一个语句中,只考虑 'Patrick' <= key_col < 'Patricl' 的行。在第二个语句中,只考虑带有 'Pat' <= key_col < 'Pau' 的行。
Hash Index Characteristics
哈希索引有一些不同于刚才讨论的特性:
它们仅用于使用 = 或 <=> 运算符的相等比较(但速度非常快)。
它们不用于查找值范围的比较运算符(如 <)。
依赖这种单值查找的系统称为“键值存储”;若要对此类应用程序使用MySQL,请尽可能使用哈希索引。
优化器不能使用哈希索引来加快操作顺序。(这种类型的索引不能用于按顺序搜索下一个条目。)
MySQL不能确定两个值之间大约有多少行(范围优化器使用这个来决定使用哪个索引)。如果将MyISAM或InnoDB表更改为哈希索引的内存表,这可能会影响某些查询。
只能使用整键来搜索一行。(对于b树索引,任何键最左边的前缀都可以用来查找行。)
MyISAM 与 InnoDB Index
数据库的索引分为主键索引(Primary Inkex)与普通索引(Secondary Index)。
InnoDB和MyISAM是怎么利用B+树来实现这两类索引,其又有什么差异呢?这是今天要聊的内容。
MyISAM 索引
MyISAM 的索引与行记录是分开存储的,叫做非聚集索引(UnClustered Index)。
其主键索引与普通索引没有本质差异:
-
有连续聚集的区域单独存储行记录
-
主键索引的叶子节点,存储主键,与对应行记录的指针
-
普通索引的叶子结点,存储索引列,与对应行记录的指针
画外音:MyISAM的表可以没有主键。
主键索引与普通索引是两棵独立的索引B+树,通过索引列查找时,先定位到B+树的叶子节点,再通过指针定位到行记录。
例子
举个例子,MyISAM:
t(id PK, name KEY, sex, flag);
表中有四条记录:
1, shenjian, m, A 3, zhangsan, m, A 5, lisi, m, A 9, wangwu, f, B

20180901-mysql-index-un-clustered.png 20180901-mysql-index-clustered.png
其 B+ 树索引构造如上图:
-
行记录单独存储
-
id为PK,有一棵id的索引树,叶子指向行记录
-
name为KEY,有一棵name的索引树,叶子也指向行记录
InnoDB 索引
InnoDB的主键索引与行记录是存储在一起的,故叫做聚集索引(Clustered Index):
-
没有单独区域存储行记录
-
主键索引的叶子节点,存储主键,与对应行记录(而不是指针)
画外音:因此,InnoDB的PK查询是非常快的。
因为这个特性,InnoDB的表必须要有聚集索引:
(1)如果表定义了PK,则PK就是聚集索引;
(2)如果表没有定义PK,则第一个非空unique列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
聚集索引,也只能够有一个,因为数据行在物理磁盘上只能有一份聚集存储。
普通索引
InnoDB的普通索引可以有多个,它与聚集索引是不同的:
- 普通索引的叶子节点,存储主键(也不是指针)
最佳实践
(1)不建议使用较长的列做主键,例如char(64),因为所有的普通索引都会存储主键,会导致普通索引过于庞大;
(2)建议使用趋势递增的key做主键,由于数据行与索引一体,这样不至于插入记录时,有大量索引分裂,行记录移动;
例子
仍是上面的例子,只是存储引擎换成InnoDB:
t(id PK, name KEY, sex, flag);

其B+树索引构造如上图:
-
id为PK,行记录和id索引树存储在一起
-
name为KEY,有一棵name的索引树,叶子存储id
当:
select * from t where name = 'lisi';
会先通过name辅助索引定位到B+树的叶子节点得到id=5,再通过聚集索引定位到行记录。
画外音:所以,其实扫了2遍索引树。
MyISAM FULLTEXT-INDEX
概念
全文索引(也称全文检索)是目前搜索引擎使用的一种关键技术。
它能够利用「分词技术「等多种算法智能分析出文本文字中关键字词的频率及重要性,然后按照一定的算法规则智能地筛选出我们想要的搜索结果。
在这里,我们就不追根究底其底层实现原理了,现在我们来看看在MySQL中如何创建并使用全文索引。
实例
- 创建表
在MySQL中,创建全文索引相对比较简单。
例如,我们有一个文章表(article),其中有主键ID(id)、文章标题(title)、文章内容(content)三个字段。
现在我们希望能够在title和content两个列上创建全文索引,article表及全文索引的创建SQL语句如下:
CREATE TABLE article (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
content TEXT,
FULLTEXT (title, content) --在title和content列上创建全文索引
);
- 指定列
此外,如果我们想要给已经存在的表的指定字段创建全文索引,同样以article表为例,我们可以使用如下SQL语句进行创建:
--给现有的article表的title和content字段创建全文索引
--索引名称为fulltext_article
ALTER TABLE article
ADD FULLTEXT INDEX fulltext_article (title, content)
- 使用
在MySQL中创建全文索引之后,现在就该了解如何使用了。
众所周知,在数据库中进行模糊查询是使用LIKE关键字进行查询,例如:
SELECT * FROM article WHERE content LIKE '%查询字符串%'
那么,我们使用全文索引也是这样用的吗?
当然不是,我们必须使用特有的语法才能使用全文索引进行查询。
例如,我们想要在article表的title和content列中全文检索指定的查询字符串,可以如下编写SQL语句:
SELECT * FROM article WHERE MATCH(title, content) AGAINST('查询字符串')
注意
目前,使用MySQL自带的全文索引时,如果查询字符串的长度过短将无法得到期望的搜索结果。 MySQL全文索引所能找到的词的默认最小长度为4个字符。另外,如果查询的字符串包含停止词, 那么该停止词将会被忽略。
如果可能,请尽量先创建表并插入所有数据后再创建全文索引,而不要在创建表时就直接创建全文索引,因为前者比后者的全文索引效率要高。
从MySQL 5.7开始,MySQL内置了 ngram 全文检索插件, 用来支持中文分词,并且对MyISAM和InnoDB引擎有效。
执行计划
概念
根据表、列、索引和WHERE子句中的条件的详细信息,MySQL优化器考虑了许多技术来有效执行SQL查询中涉及的查找。
在一个巨大的表上执行查询可以不读取所有的行;可以在不比较每个行组合的情况下执行涉及多个表的联接。
优化器选择执行最高效查询的操作集称为“查询执行计划”,也称为解释计划。
您的目标是识别表明查询优化良好的EXPLAIN计划的各个方面,并学习SQL语法和索引技术,以便在看到一些低效操作时改进计划。
例子
mysql> explain select * from subject where iid <= 100;
+----+-------------+---------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | subject | range | PRIMARY | PRIMARY | 8 | NULL | 100 | Using where |
+----+-------------+---------+-------+---------------+---------+---------+------+------+-------------+
1 row in set (0.01 sec)
属性说明
id
id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询。
select_type
A:simple:表示不需要union操作或者不包含子查询的简单select查询。有连接查询时,外层的查询为simple,且只有一个
B:primary:一个需要union操作或者含有子查询的select,位于最外层的单位查询的select_type即为primary。且只有一个
C:union:union连接的两个select查询,第一个查询是dervied派生表,除了第一个表外,第二个以后的表select_type都是union
D:dependent union:与union一样,出现在union 或union all语句中,但是这个查询要受到外部查询的影响
E:union result:包含union的结果集,在union和union all语句中,因为它不需要参与查询,所以id字段为null
F:subquery:除了from字句中包含的子查询外,其他地方出现的子查询都可能是subquery
G:dependent subquery:与dependent union类似,表示这个subquery的查询要受到外部表查询的影响
H:derived:from字句中出现的子查询,也叫做派生表,其他数据库中可能叫做内联视图或嵌套select
table
显示的查询表名,如果查询使用了别名,那么这里显示的是别名,如果不涉及对数据表的操作,那么这显示为null,
如果显示为尖括号括起来的 <derived N> 就表示这个是临时表,后边的N就是执行计划中的id,表示结果来自于这个查询产生。
如果是尖括号括起来的 <union M,N>,与 <derived N> 类似,也是一个临时表,表示这个结果来自于union查询的id为M,N的结果集。
type
依次从好到差:system,const,eq_ref,ref,fulltext,ref_or_null,unique_subquery,index_subquery,range,index_merge,index,ALL, 除了all之外,其他的type都可以使用到索引,除了index_merge之外,其他的type只可以用到一个索引
A:system:表中只有一行数据或者是空表,且只能用于myisam和memory表。如果是Innodb引擎表,type列在这个情况通常都是all或者index
B:const:使用唯一索引或者主键,返回记录一定是1行记录的等值where条件时,通常type是const。其他数据库也叫做唯一索引扫描
C:eq_ref:出现在要连接过个表的查询计划中,驱动表只返回一行数据,且这行数据是第二个表的主键或者唯一索引,且必须为not null,唯一索引和主键是多列时,只有所有的列都用作比 较时才会出现eq_ref
D:ref:不像eq_ref那样要求连接顺序,也没有主键和唯一索引的要求,只要使用相等条件检索时就可能出现,常见与辅助索引的等值查找。或者多列主键、唯一索引中,使用第一个列之外的 列作为等值查找也会出现,总之,返回数据不唯一的等值查找就可能出现。
E:fulltext:全文索引检索,要注意,全文索引的优先级很高,若全文索引和普通索引同时存在时,mysql不管代价,优先选择使用全文索引
F:ref_or_null:与ref方法类似,只是增加了null值的比较。实际用的不多。
G:unique_subquery:用于where中的in形式子查询,子查询返回不重复值唯一值
H:index_subquery:用于in形式子查询使用到了辅助索引或者in常数列表,子查询可能返回重复值,可以使用索引将子查询去重。
I:range:索引范围扫描,常见于使用>,<,is null,between ,in ,like等运算符的查询中。
J:index_merge:表示查询使用了两个以上的索引,最后取交集或者并集,常见and ,or的条件使用了不同的索引,官方排序这个在ref_or_null之后,但是实际上由于要读取所个索引,性 能可能大部分时间都不如range
K:index:索引全表扫描,把索引从头到尾扫一遍,常见于使用索引列就可以处理不需要读取数据文件的查询、可以使用索引排序或者分组的查询。
L:all:这个就是全表扫描数据文件,然后再在server层进行过滤返回符合要求的记录。
possible_keys
查询可能使用到的索引都会在这里列出来
key
查询真正使用到的索引,select_type为index_merge时,这里可能出现两个以上的索引,其他的select_type这里只会出现一个。
key_len
用于处理查询的索引长度,如果是单列索引,那就整个索引长度算进去,如果是多列索引,那么查询不一定都能使用到所有的列,具体使用到了多少个列的索引,这里就会计算进去,没有使用到的列,这里不会计算进去。留意下这个列的值,算一下你的多列索引总长度就知道有没有使用到所有的列了。要注意,mysql的ICP特性使用到的索引不会计入其中。另外,key_len只计算where条件用到的索引长度,而排序和分组就算用到了索引,也不会计算到key_len中。
ref
如果是使用的常数等值查询,这里会显示const,如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段,如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为func
rows
这里是执行计划中估算的扫描行数,不是精确值
extra
这个列可以显示的信息非常多,有几十种,常用的有
A:distinct:在select部分使用了 distinct 关键字
B:no tables used:不带from字句的查询或者From dual查询
C:使用not in()形式子查询或not exists运算符的连接查询,这种叫做反连接。即,一般连接查询是先查询内表,再查询外表,反连接就是先查询外表,再查询内表。
D:using filesort:排序时无法使用到索引时,就会出现这个。常见于order by和group by语句中
E:using index:查询时不需要回表查询,直接通过索引就可以获取查询的数据。
F:using join buffer(block nested loop),using join buffer(batched key accss):5.6.x之后的版本优化关联查询的BNL,BKA特性。主要是减少内表的循环数量以及 比较顺序地扫描查询。
G:using sort_union,using_union,using intersect,using sort_intersection:
using intersect:表示使用and的各个索引的条件时,该信息表示是从处理结果获取交集
using union:表示使用or连接各个使用索引的条件时,该信息表示从处理结果获取并集
using sort_union和using sort_intersection:与前面两个对应的类似,只是他们是出现在用and和or查询信息量大时,先查询主键,然后进行排序合并后,才能读取记录并返回。
H:using temporary:表示使用了临时表存储中间结果。临时表可以是内存临时表和磁盘临时表,执行计划中看不出来,需要查看status变量,used_tmp_table, used_tmp_disk_table才能看出来。
I:using where:表示存储引擎返回的记录并不是所有的都满足查询条件,需要在server层进行过滤。查询条件中分为限制条件和检查条件,5.6之前,存储引擎只能根据限制条件扫描数据 并返回,然后server层根据检查条件进行过滤再返回真正符合查询的数据。5.6.x之后支持ICP特性,可以把检查条件也下推到存储引擎层,不符合检查条件和限制条件的数据,直接不读取,这 样就大大减少了存储引擎扫描的记录数量。extra列显示using index condition
J:firstmatch(tb_name):5.6.x开始引入的优化子查询的新特性之一,常见于where字句含有in()类型的子查询。如果内表的数据量比较大,就可能出现这个
K:loosescan(m..n):5.6.x之后引入的优化子查询的新特性之一,在in()类型的子查询中,子查询返回的可能有重复记录时,就可能出现这个
除了这些之外,还有很多查询数据字典库,执行计划过程中就发现不可能存在结果的一些提示信息
filtered
使用explain extended时会出现这个列,5.7之后的版本默认就有这个字段,不需要使用explain extended了。这个字段表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数。
索引小课堂
索引越多越好吗
提高SELECT操作性能的最佳方法是在查询中测试的一个或多个列上创建索引。
索引条目的作用类似于指向表行的指针,允许查询快速确定哪些行与WHERE子句中的条件匹配,并检索这些行的其他列值。所有MySQL数据类型都可以建立索引。
尽管为查询中可能使用的每个列创建索引很有吸引力,但不必要的索引浪费了MySQL的空间和时间,无法确定使用哪些索引。
索引还会增加插入、更新和删除的成本,因为每个索引都必须更新。您必须找到正确的平衡,以便使用最优的索引集实现快速查询。
最多多少索引?
mysql中提到,一个表最多 16 个索引,最大索引长度 256 字节.
索引不生效的场景
!= 或者 <>
负向条件查询不能使用索引
- 实例
select * from order where status!=0 and stauts!=1
not in/not exists都不是好习惯
建议优化为:
select * from order where status in(2,3)
在属性上进行计算不能命中索引
select * from order where YEAR(date) < = '2017'
即使date上建立了索引,也会全表扫描,可优化为值计算:
select * from order where date < = CURDATE()
或者:
select * from order where date < = '2017-01-01'
使用聚合函数
表关联的时候。只有当主键和外键具有相同的类型才会生效。
LIKE, REGEX 只有当第一个不是通配符才会生效。
like '%abc' ×
like 'abc%' √
ORDER BY
只有当条件不是表达式时会生效。多表的时候效果不好。
相同的字段太多
比如全是 0/1
- 实例
select * from user where sex=1
性别大部分只有男女,索引效果不佳。
经验上,能过滤80%数据时就可以使用索引。对于订单状态,如果状态值很少,不宜使用索引,如果状态值很多,能够过滤大量数据,则应该建立索引。
拓展知识
局部性原理
局部性原理的逻辑是这样的:
(1)内存读写块,磁盘读写慢,而且慢很多;
(2)磁盘预读:磁盘读写并不是按需读取,而是按页预读,一次会读一页的数据,每次加载更多的数据,如果未来要读取的数据就在这一页中,可以避免未来的磁盘IO,提高效率;
画外音:通常,一页数据是4K。
(3)局部性原理:软件设计要尽量遵循“数据读取集中”与“使用到一个数据,大概率会使用其附近的数据”,这样磁盘预读能充分提高磁盘IO;
非聚集索引
但是如果你没有带着你书上的DDS#来图书馆,那么你需要第二个索引来帮助你。
在过去的日子里,你会在图书馆的前面发现一个奇妙的抽屉柜,被称为“卡片目录”。
里面有成千上万张3x5的卡片——每本书一张,按字母顺序排列(也许是按书名)。这对应于“非聚集索引”。这些卡片目录被组织成一个层次结构,这样每个抽屉都会贴上它所包含的卡片的范围(例如Ka - Kl;即。“中间节点”)。
再一次,你会钻到你找到你的书,但在这种情况下,一旦你找到了它(我。e,“叶节点”),您没有书本身,但只有一张带有索引号(DDS#)的卡片,您可以用它在聚集索引中找到实际的书。
当然,没有什么能阻止图书管理员复印所有的卡片,并在单独的卡片目录中按照不同的顺序进行分类。(通常至少有两个这样的目录:一个按作者姓名排序,另一个按标题排序。)原则上,您可以拥有任意数量的“非集群”索引。
聚集索引
如果你走进公共图书馆,你会发现所有的书都按照特定的顺序排列(很可能是杜威十进制系统,或DDS)。
这对应于书籍的“聚集索引”。如果您想要的书的DDS#是005.7565 F736s,那么您可以从定位一排标着001-099之类的书架开始。 (堆栈末尾的endcap符号对应于索引中的“中间节点”。)最后,您将深入到标签为005.7450 - 005.7600的特定书架,然后扫描,直到找到指定的DDS#的书,这时您已经找到了您的书。
InnoDB 聚集索引
InnoDB的索引有两类索引,聚集索引(Clustered Index)与普通索引(Secondary Index)。
InnoDB的每一个表都会有聚集索引:
(1) 如果表定义了PK,则PK就是聚集索引;
(2) 如果表没有定义PK,则第一个非空unique列是聚集索引;
(3) 否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
InnoDB 索引和记录是存储在一起的,而 MyISAM 的索引和记录是分开存储的。
普通索引
叶子节点存储了PK的值;
画外音:
所以,InnoDB的普通索引,实际上会扫描两遍:
第一遍,由普通索引找到PK;
第二遍,由PK找到行记录;
索引结构,InnoDB/MyISAM 的索引结构,如果大家感兴趣,未来撰文详述。
感触
对于东西,首先要知道其存在和作用。
然后要思考为什么这么设计?
底层原理是什么?
不要觉得自己会写个 index 就是会索引了,那不叫会,那叫菜。
参考资料
- 底层数据结构
https://www.cnblogs.com/zlcxbb/p/5757245.html
https://www.cnblogs.com/weizhixiang/p/5914120.html
- index
https://en.wikipedia.org/wiki/Database_index
https://dev.mysql.com/doc/refman/8.0/en/optimization-indexes.html
https://www.tutorialspoint.com/mysql/mysql-indexes.htm
https://www.guru99.com/indexes.html
- 对比
https://dev.mysql.com/doc/refman/8.0/en/index-statistics.html
https://dev.mysql.com/doc/refman/8.0/en/index-btree-hash.html
https://www.cnblogs.com/aspnethot/articles/1504082.html
- 原理
http://blog.codinglabs.org/articles/theory-of-mysql-index.html
http://blog.codinglabs.org/articles/index-condition-pushdown.html?utm_source=rss&utm_medium=rss&utm_campaign=rss
- fulltext index
https://dev.mysql.com/doc/refman/5.6/en/innodb-fulltext-index.html
http://www.mysqltutorial.org/activating-full-text-searching.aspx
https://hackernoon.com/dont-waste-your-time-with-mysql-full-text-search-61f644a54dfa
http://xiaorui.cc/2016/02/03/%E6%B5%85%E8%B0%88mysql-fulltext%E5%85%A8%E6%96%87%E7%B4%A2%E5%BC%95%E7%9A%84%E4%BC%98%E7%BC%BA%E7%82%B9/
- explain
https://dev.mysql.com/doc/refman/8.0/en/execution-plan-information.html
http://www.cnblogs.com/xiaoboluo768/p/5400990.html
- optimize
http://www.cnblogs.com/hongfei/archive/2012/10/19/2731342.html
- 数据结构
本期跳过,数据结构专栏学习
https://en.wikipedia.org/wiki/Binary_search_tree
https://en.wikipedia.org/wiki/B-tree
https://www.bysocket.com/?p=1209
