SQL Join
也许你写了几年的 sql join,但是比如我,就没有认真的看过,join 时到底发生了什么。
概念
SQL连接是一种结构化查询语言(SQL)指令,用于组合来自两组数据(即两个表)的数据。
在深入了解SQL连接的细节之前,让我们简要讨论一下SQL是什么,以及为什么有人要执行SQL连接。
SQL是一种特殊用途的编程语言,用于管理关系数据库管理系统(RDBMS)中的信息。
关系(relational)这个词是关键;它指定数据库管理系统的组织方式,以便在不同的数据集之间定义清楚的关系。
通常,在您能够使用SQL管理数据之前,您需要将数据提取、转换和加载到RDBMS中,您可以使用像Stitch这样的工具来完成。
基础的 join 类型
SQL连接有四种基本类型:内部连接、左连接、右连接和全连接。
解释这四种类型之间差异的最简单和最直观的方法是使用维恩图,它显示了数据集之间所有可能的逻辑关系。
场景引入
假设我们的关系数据库中有两组数据:表A和表B,其中一些关系由主键和外键指定。将这些表连接在一起的结果可以用下图直观地表示:

重叠的程度,如果有的话,是由多少个表匹配记录在表中记录b取决于子集的数据我们想选择两个表,可以可视化通过强调四种加入相应的维恩图的部分:
inner join
从满足连接条件的表A和表B中选择所有记录。

left join
从表A中选择所有记录,以及表B中满足连接条件的记录(如果有的话)。
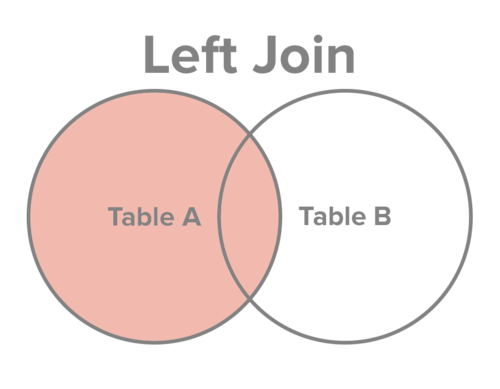
right join
从表B中选择所有记录,以及表A中满足连接条件的记录(如果有的话)。
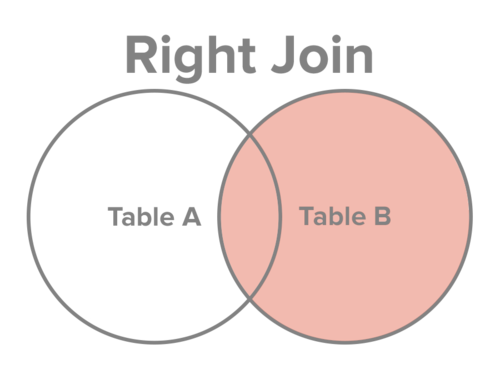
full join
从表A和表B中选择所有记录,不管是否满足连接条件。
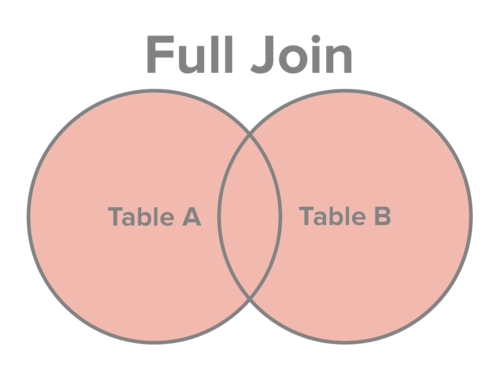
mysql join 原理
算法
join 的实现是采用 Nested Loop Join 算法
就是通过驱动表的结果集作为循环基础数据,然后一条一条的通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。
如果有多个join,则将前面的结果集作为循环数据,再一次作为循环条件到后一个表中查询数据。
例子
- 三表 join
select m.subject msg_subject, c.content msg_content
from user_group g,group_message m,group_message_content c
where g.user_id = 1
and m.group_id = g.group_id
and c.group_msg_id = m.id
- 查看执行计划
使用 explain 看看执行计划:
explain select m.subject msg_subject, c.content msg_content from user_group g,group_message m,
group_message_content c where g.user_id = 1 and m.group_id = g.group_id and c.group_msg_id = m.id\G;
explain选择user_group作为驱动表, 首先通过索引user_group_uid_ind来进行const条件的索引ref查找, 然后用user_group表中过滤出来的结果集group_id字段作为查询条件, 对group_message循环查询,然后再用过滤出来的结果集中的group_message的id作为条件与group_message_content的group_msg_id进行循环比较查询,获得最终的结果。
- 代码实现
for each record g_rec in table user_group that g_rec.user_id=1{
for each record m_rec in group_message that m_rec.group_id=g_rec.group_id{
for each record c_rec in group_message_content that c_rec.group_msg_id=m_rec.id
pass the (g_rec.user_id, m_rec.subject, c_rec.content) row
combination to output;
}
}
优化
-
用小结果集驱动大结果集,尽量减少join语句中的Nested Loop的循环总次数;
-
优先优化Nested Loop的内层循环,因为内层循环是循环中执行次数最多的,每次循环提升很小的性能都能在整个循环中提升很大的性能;
-
对被驱动表的join字段上建立索引;
-
当被驱动表的join字段上无法建立索引的时候,设置足够的Join Buffer Size。
join buffer
join_buffer_size
SELECT @@join_buffer_size;
当我们的join是ALL,index,rang或者Index_merge的时候使用的buffer。
实际上这种join被称为FULL JOIN。
实际上参与join的每一个表都需要一个join buffer。
所以在join出现的时候,至少是2个。
join buffer的这只在mysql5.1.23版本之前最大为4G,但是从5.1.23版本开始,再出了windows之外的64为平台上可以超出4GB的限制。
系统默认是128KB。
优化建议
如果应用中,很少出现join语句,则可以不用太在乎join_buffer_size参数的设置大小。
如果join语句不是很少的话,个人建议可以适当增大join_buffer_size到1MB左右,如果内存充足可以设置为2MB。
最后需要注意的是,每一个线程都会创建自己独立的buffer而不是整个系统共享,所以设置的值过大会造成系统内存不足。
准备数据
虽然在特定数据源中执行连接可能很有帮助,但是连接来自多个数据源的数据是高级分析的第一步。例如,将Adwords的营销数据与Square的交易数据结合起来,可以发现可操作的见解,从而让公司开始行动。
然而,跨数据源执行连接是困难的;首先需要将数据源整合到一个地方,最好是像Amazon Redshift这样的数据仓库。您可以手动从每个源提取数据,或者使用ETL服务(如Stitch)来连接您的数据源,并在几分钟内开始将信息传输到红移。
一旦您的数据在数据仓库中,您就可以跨任何您想要的数据源进行连接。Redshift特别支持快速查询和与商业智能工具(如查找器、模式和车辆)的无缝连接,这些工具允许您查询数据并使用图表和报告将其可视化。
整个系统是这样的:
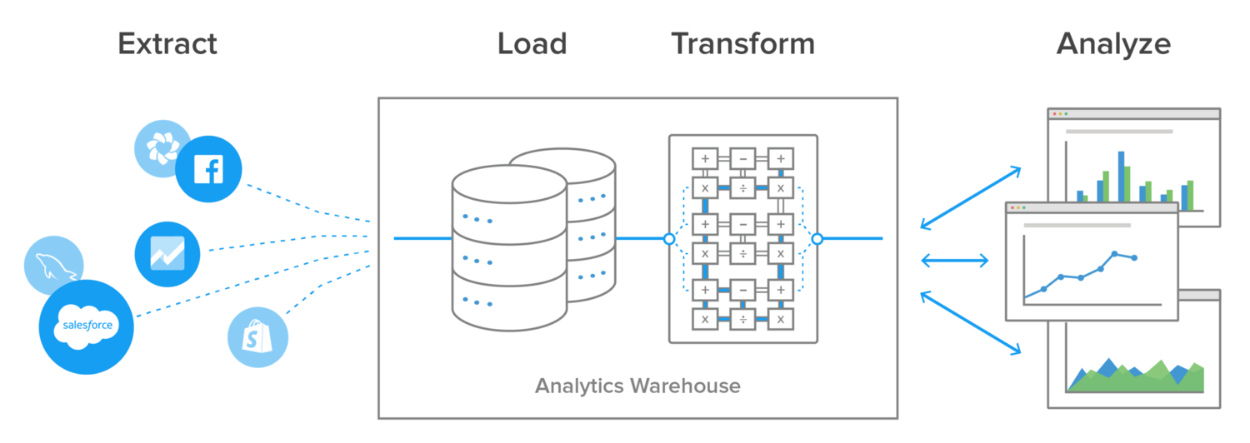
这里的要点是,在没有数据仓库的情况下,不可能使用SQL连接数据,而连接多个数据源的最简单方法是通过ETL工具。Stitch连接到你的业务已经在使用的数据源,比如MySQL、PostreSQL、MongoDB、Salesforce、Zendesk、谷歌Analytics等等,然后将所有数据流到Amazon Redshift。
在数据仓库中拥有数据之后,您可以使用下一页上的链接来理解每个数据源如何构造它们的数据,这样您就可以尽快开始执行连接。
参考资料
https://www.dofactory.com/sql/join
https://www.geeksforgeeks.org/sql-join-set-1-inner-left-right-and-full-joins/
- 原理
https://blog.csdn.net/tonyXf121/article/details/7796657
https://zhuanlan.zhihu.com/p/28877447
- buffer
https://blog.csdn.net/qq_21064841/article/details/53395899
- 分布式
https://www.zhihu.com/question/38038257/answer/75885958
