分布式共识(Consensus)
分布式共识问题,简单说,就是在一个或多个进程提议了一个值应当是什么后,使系统中所有进程对这个值达成一致意见。
这样的协定问题在分布式系统中很常用,比如说选主(Leader election)问题中所有进程对Leader达成一致;
互斥(Mutual exclusion)问题中对于哪个进程进入临界区达成一致;
原子组播(Atomic broadcast)中进程对消息传递(delivery)顺序达成一致。
对于这些问题有一些特定的算法,但是,分布式共识问题试图探讨这些问题的一个更一般的形式,如果能够解决分布式共识问题,则以上的问题都可以得以解决。
分布式共识问题的定义如下图所示:
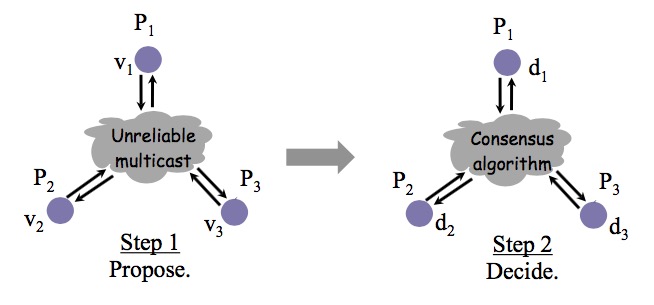
为了达到共识,每个进程都提出自己的提议(propose),最终通过共识算法,所有正确运行的进程决定(decide)相同的值。
共识算法的正确性要求是在运行中满足以下条件:
-
终止性(Liveness):所有正确进程最后都能完成决定。
-
协定性(Safety):所有正确进程决定相同的值。
-
完整性(Integrity):如果正确的进程都提议同一个值,那么所有正确进程最终决定该值。
系统模型
接下来让我们结合系统模型来思考共识问题。
如果在一个不出现故障的系统中,很容易可以构造出一个符合要求的共识算法:每个进程都将自己的提议通过可靠组播(Reliable broadcast)(见书15.4.2节)发送给其他进程,当进程收到所有成员的提议后,取所有提议中出现最多的值作为最终决定即可。
如果在存在故障的同步系统中,书中15.5.2节给出了一种解法,不是本文重点,因此不做过多讨论。
而如果是在存在故障的异步系统中,共识问题是否有可用的解法呢?
著名的FLP不可能性证明4告诉我们:没有任何算法可以在存在任何故障的异步系统中确保达到共识,FLP的证明过于庞大,本文不做展开,但其意义是非常重要的,正如之前说的,大部分实际的分布式系统都是异步的,FLP不可能性证明阻止了无数分布式系统设计者把时间浪费在寻找一个完美的异步系统共识算法上,而更应该去使用一个不那么完美却有实际意义的解法。
正如FLP不可能性证明所述,不存在算法可以“确保”达到共识,但我们可以设计出有较大概率可以达到共识的算法。
绕过不可能性结论的办法是考虑部分同步系统,利用故障屏蔽、故障检测器或随机化手段避开异步系统模型(详见书15.5.4节),构造出可接受的共识算法,在后文中会重点关注几个异步系统中共识问题的著名工作,并解释它们是如何做到的。
共识与多副本状态机(Replicated state machines)
分布式系统中对共识问题的直接应用常常是在多副本状态机(不太确定这个翻译对不对)的场景中出现的。
多副本状态机是指多台机器具有完全相同的状态,并且运行有完全相同的确定性状态机。
通过使用这样的状态机,可以解决很多分布式系统中的容错问题,因为多副本状态机通常可以容忍⌊N2⌋进程故障,且所有正常运行的副本都完全一致,所以,可以使用多副本状态机来实现需要避免单点故障的组件,如集中式的选主或是互斥算法中的协调者(coordinator),如图所示:

集中式的选主或互斥算法逻辑简单,但最大的问题是协调者的单点故障问题,通过采用多副本状态机来实现协调者实现了高可用的“单点”,回避了单点故障。
Google的Chubby服务5和类似的开源服务Zookeeper就是这样的例子。
虽然有很多不同的多副本状态机实现,但其基本实现模式是类似的:状态机的每个副本上都保存有完全相同的操作日志,保证所有副本状态机按照相同的顺序执行操作,这样由于状态机是确定性的,则一定会得到相同的状态,如下图:
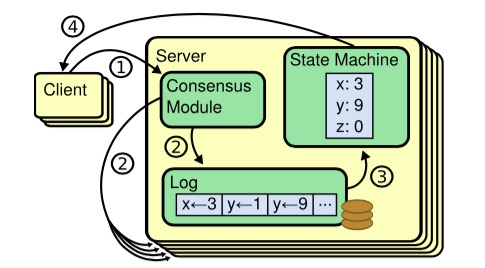
共识算法的作用就是在这样的场景中保证所有副本状态机上的操作日志具有完全相同的顺序,具体来讲:如果状态机的任何一个副本在本地状态机上执行了一个操作,则绝对不会有别的副本在操作序列相同位置执行一个不同的操作。
接下来,我将对三个我认为非常有代表性的分布式共识算法的工作进行简要介绍,分别是Viewstamped Replication、Raft和大名鼎鼎的Paxos算法,前两个工作本身就是基于多副本状态机的场景完成的,而Paxos算法是作为独立的分布式共识算法提出,并给出了使用该算法实现多副本状态机的范例。
参考资料
分布式共识(Consensus):Viewstamped Replication、Raft以及Paxos
https://nan01ab.github.io/2017/08/Viewstamped-Replication.html
https://github.com/coilhq/viewstamped-replication-made-famous
