Viewstamped Replication
Viewstamp Replication(以下简称VR)最初被提出是作为数据库中的一部分工作,2012年作为单独的分布式共识算法再次发表。
系统模型
VR算法适用于允许故障-停止的异步系统中,并且VR不要求可靠的消息传递,即VR可以容忍消息丢失、延迟、乱序以及重复。
容错
在一个总共有2f+1个进程的VR服务中,VR可以容忍最多不超过f个进程同时发生故障。
原理介绍
从整体上来看,正常运行中的VR副本中一个作为primary,其余副本都作为backup,正如上文所说的,Replicated state machine最关键的问题在于让所有副本状态机按照相同的顺序执行命令,VR中primary副本决定命令的顺序,所有其他的backup副本仅仅接受primary所决定好的顺序。当primary出现故障时,VR执行一个称为view change的过程,在VR中每个view中都有且仅有一个固定的primary,通过执行view change,可以使系统进入下一个view,并选出新的primary取代故障的旧primary副本。
当primary没有发生故障时,VR在一个稳定的view中运行,副本之间通过消息通信,每个消息中都包含了自己当前所处的view-number,仅当收到的消息包含和自己所知吻合的view-number时副本才会处理该消息,如果收到来自旧view的消息,副本简单丢弃该消息,而如果收到更新的view的消息,则副本知道自己落后了,这时需要执行一套特殊的state transfer过程来赶上系统的最新状态。在正常运行中,VR按以下过程执行用户请求:
client向primary发出请求⟨REQUEST op,c,s⟩,其中op代表需要运行的操作,c代表client-id,s代表对于每个client单调递增的request-number。
primary接收到请求后,会对比收到的request-number和本地记录中该client最近的一次请求,如果新请求不比之前本地记录的请求更新,则拒绝执行该请求,并将之前请求的应答再次返回给client。(每个client同时只能发出一个请求)
否则,primary为接收到的请求确定op-number(在view中递增),将该请求添加到本地log中,并用它来更新本地记录中该client的最新请求。然后,primary向所有backup副本发送消息⟨PREPARE v,m,n,k⟩,v是当前的view-number,m是client发出的请求消息,n是op-number,k是commit-number,代表最近的已提交op-number。
backup收到PREPARE消息后,严格按照顺序处理所有PREPARE消息(和第2步中primary定序结合,相当于构造了全序组播),当该请求的所有前置请求都处理过后,backup副本与primary一样,递增本地op-number、将请求添加到本地log、更新本地对该client的请求记录,最后向primary回复⟨PREPAREOK v,n,i⟩来确认准备完成。
primary在收到超过f个来自不同backup的PREPAREOK消息后,对该消息(及之前的所有消息,如果有)执行提交操作:执行client提交的操作,并递增commit-number,最后向client返回应答⟨REPLY v,s,x⟩,x是操作的执行结果,同时primary会将该结果保存在本地,用于防止client故障产生的重复请求(见2)
primary可以通过PREPARE消息或⟨COMMIT v,k⟩消息通知backup已确认提交的请求。
当backup副本收到提交确认消息后,如果该消息已经在本地log中(有可能有落后的副本),则它执行操作、递增commit-number,然后更新本地client请求结果。
这个处理过程如下图所示:
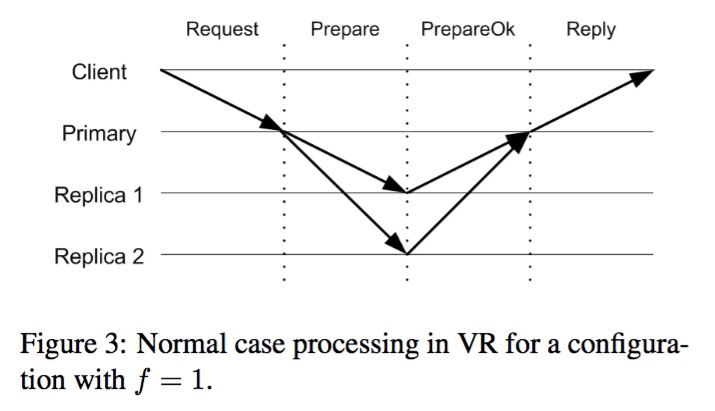
另外,在整个过程中,在没有收到回复时发送方会重复发送消息,以此来对抗可能出现的消息丢失。在VR中只有primary副本可以响应client请求,backup对client请求仅仅是简单的丢弃,如果primary发生了变化,当请求超时后client会向所有副本发送请求以找到新的primary。
如果primary故障,backup就无法收到来自primary的PREPARE和COMMIT(当没有请求是被周期发送,相当于心跳的作用)消息,当触发一个超时后,backup认为primary发生了故障,此时进入了view change阶段,如下:
对于副本i,当它发现primary发生了故障(超时)或着收到了来自其他副本的STARTVIEWCHANGE或DOVIEWCHANGE消息,进入view-change状态,它将递增view-number,并且向其他副本发出⟨STARTVIEWCHANGE v,i⟩消息。
当副本i收到来自超过f个不同副本的吻合它view-number的STARTVIEWCHANGE消息后,它向新的primary副本(VR中选主过程非常简单,所有进程根据IP地址排序获得编号,在每次view change过程中按顺序轮流当primary)发送⟨DOVIEWCHANGE v,l,v′,n,k,i⟩,l是它的日志,v′是它转为view change状态之前的view-number。
当新的primary副本收到超过f+1个来自不同副本的DOVIEWCHANGE消息后,它将自己的view-number修改为消息中携带的值,并选择具有最大的v′的消息中的l作为新的log,如果多条消息具有同样的v′,则选择具有最大n的那个。同时,它将op-number设置为log中尾部请求的序号,将commit-number设置为收到所有消息中最大的。然后将自身状态修改回normal,并向其他副本发送⟨STARTVIEW v,l,n,k⟩以通知他们view change完成。
新的primary开始正常响应client的请求,并且同时执行任何之前没有执行完的命令(根据新获得的log)。
其他副本在收到STARTVIEW消息后,根据消息的内容修改本地状态和log,执行本地没有提交的操作(由于该副本有落后),并将自身状态修改回normal,另外,如果log中包含未提交的操作(当旧primary还没来得及向其他副本确认提交成功就故障了),则向新primary发送⟨PREPAREOK v,n,i⟩消息。
到这里已经完成了VR算法核心流程的叙述:包括正常状态下的执行和primary副本故障后的view change过程,VR算法还包括了故障进程恢复协议以及动态修改副本配置的Reconfiguration协议,限于篇幅和精力,就不再展开叙述了。
正确性
那么VR算法是正确的么?前文中描述过了共识算法正确性的标准,那么对于VR来说,其共识算法需要保证所有状态机副本以相同的顺序执行操作。
我们分两部分来讨论VR算法的正确性。
首先,在正常运行过程中(无primary故障)VR算法显然是正确的,primary决定了统一的操作顺序并将其传播到backup副本上,因此在primary发生故障时的view change协议必须可以保障整体VR算法的正确性。
从Safety的角度来讲,view change必须保证每一个在先前view中已经提交的操作必须能够传递到新的view中,并且处于操作序列中完全相同的位置。
理解这个正确性的关键在于注意到VR算法中的两个细节:primary只有在超过f+1个副本已经收到某操作的前提下才会提交该操作,而在view change过程中,新的primary必须收到来自超过f+1个副本的log才能开始工作。由于VR最多只容忍f个副本同时故障,则必然有至少一个了解该操作的副本向新的primary提交了自己的log。
另一个对Safety非常非常关键的点在于:副本一旦进入view-change状态,就不会再响应任何来自旧view的PREPARE消息。这是因为VR算法应用于异步系统,当primary出现超时并不代表primary真正故障了,有可能它只是运行缓慢或者网络延迟严重,随后有可能会出现延时到达的PREPARE消息,这样的消息是非常致命的,为了保证DOVIEWCHANGE消息中包含了所有的已提交操作,必须保证屏蔽掉旧view中的primary。这种方式实际上相当于使用故障检测器屏蔽超时进程,将异步系统改造成为了半同步系统,绕过了FLP不可能性结论。
至于Liveness,论文证明了view change满足liveness,这也是我的一个疑问,不是说异步系统不能确保达到共识么(后文中的两个算法在Liveness上都有些缺陷)…
参考资料
分布式共识(Consensus):Viewstamped Replication、Raft以及Paxos
https://nan01ab.github.io/2017/08/Viewstamped-Replication.html
https://github.com/coilhq/viewstamped-replication-made-famous
