Confluo
Confluo is a system for real-time monitoring and analysis of data, that supports:
-
high-throughput concurrent writes of millions of data points from multiple data streams;
-
online queries at millisecond timescale; and
-
ad-hoc queries using minimal CPU resources.
像卡夫卡和 kinesis 这样的 publish-subscribe 系统在分区日志上公开了一个发布-订阅界面。
我们描述了使用动用的 pub-sub 系统的实现, 该系统通过无锁定并发实现了消息的高发布和订阅吞吐量。
实现
我们的分布式邮件系统实现采用卡夫卡的接口和数据模型-消息发布到或订阅到
Topic
它们是逻辑上的消息流。系统维护主题集合, 其中每个主题的消息存储在用户指定数量的 flufluo 分片中。
在我们的实现中, 每个分片都公开了一个基本的读和写接口。
发布者将消息分批写入特定主题的分片, 而订阅者则从这些分片异步提取批处理的消息。
与卡夫卡设计类似, 每个订阅者跟踪其在分片中的最后一个读取消息的对象 id, 随着它消耗更多消息而递增。
使用动用浮罗存储消息的主要好处包括:
-
从读写争用的自由, 以及写写争用的无锁定解析。
-
与卡夫卡不同的是, 普力弗罗提供了一个有效的方法来获得整个主题的快照。
-
支持丰富的在线
系统与实验设置的比较
我们将我们的 pub-sub 的性能与 apache kafka 进行比较。
由于这两个系统在通过多个分区扩展读取和写入性能方面是相同的, 因此我们在一个 r3.8 x大实例上进行了实验, 对这两个系统使用了一个主题和一个日志分区。
对64字节消息执行了读取和写入, 两个系统中的并发订阅者属于不同的订阅者组, 即在分区上执行独立的、不协调的读取。
我们将卡夫卡的存储安装在一个足够大的 ram 磁盘上, 确保这两个系统在内存中完全运行。
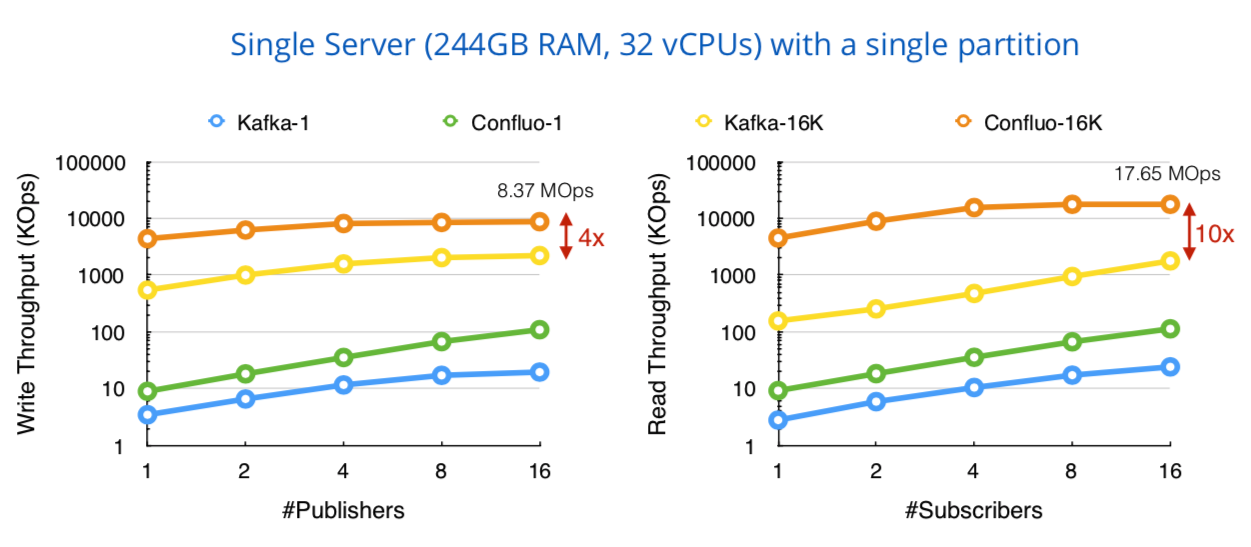
由于卡夫卡使用锁同步并发追加, 因此由于写写争用 (图 (左)), 发布者写入吞吐量受到影响。
动用洛对这些冲突采用了无锁定分辨率, 以实现较高的写入吞吐量。
较大的批次 (16k 消息) 在一定程度上缓解了卡夫卡的锁定开销, 而收款 fluo 在16k 消息批次时接近网络饱和度, 有4个以上的发布商。
由于读取在两个系统中都没有争用, 因此读取吞吐量会与多个订阅者线性扩展 (图 (右))。
差速音实现了更高的绝对读取吞吐量, 这可能是由于卡夫卡的系统开销, 而不是由于基本的设计差异。
与以前一样, 由于网络饱和, 在4个订阅者和16k 消息批次中读取受理绒毛的吞吐量。
