MonetDB
MonetDB 的列存储技术已经深入到所有主要商业数据库供应商的产品中。
它的开创性作用得到了国际公认的ACM SIGMOD Edgar F. Codd创新奖和ACM SIGMOD系统奖。
通过这些技术赋予应用的市场为进一步创新提供了充足的空间,
例如, 正如我们正在进行的项目所示。
与此同时,重大创新的格局仍然敞开大门。
屡获殊荣的论文中提供了一个预览:“数据研究员指南:在几秒钟内查询科学数据库”。
列存储功能
当您的数据库扩展到分布在许多表中的数百万条记录并且商业智能/科学成为流行的应用程序域时,需要一个列存储数据库管理系统。
与传统的行存储(如MySQL和PostgreSQL)不同,列存储提供了一种现代且可扩展的解决方案,而无需大量的硬件投资。
自1993年以来,MonetDB开创了用于商业智能和电子科学的高性能数据仓库的列存储解决方案。
它通过在DBMS的所有层创新实现其目标,例如:基于垂直分段的存储模型,现代CPU调优查询执行架构,自动和自适应索引,运行时查询优化和模块化软件架构。
它基于SQL 2003标准,完全支持外键,连接,视图,触发器和存储过程。它完全符合ACID标准,支持丰富的编程接口(JDBC,ODBC,PHP,Python,RoR,C / C ++,Perl)。
MonetDB作为源tarball,安装包和各种平台上的二进制安装程序分发。
最新版本已经在Linux(Fedora,RedHat Enterprise Linux,Debian,Ubuntu),Gentoo,Mac OS,SUN Solaris,Open Solaris,Windows XP,Windows Sever 2003,Windows Vista上进行了测试。定期发布计划可确保最新的功能改进,以便快速到达社区。
MonetDB是数据库研究的重点,推动了许多领域的技术包络。
它的三级软件堆栈由SQL前端,战术优化器和柱状抽象机内核组成,提供了一个灵活的环境,可以通过多种不同的方式对其进行自定义。丰富的链接库集合为时态数据类型,数学例程,字符串和URL提供了功能。有关MonetDB设计和实施技术创新的深入信息,请参阅我们的科学图书馆。
最后,但并非最不重要的是,MonetDB系统是在自由开源许可下发布的。它允许您以您喜欢的任何方式修改和扩展它,然后在开源和关闭源产品中重新分发它。我们非常感谢MonetDB代码库的错误修复和功能增强。
特性
简而言之,MonetDB系统具有以下功能:
列存储数据库内核。
MonetDB建立在数据库关系的规范表示上,如列,a.k.a。数组。
它们是相当大的实体 - 几百兆字节 - 由操作系统交换到内存中,并在需要时压缩在磁盘上。
一个高性能的系统。
MonetDB 在应用程序方面表现优异,数据库热设置 - 实际触及的部分 - 可以主要保存在主内存中,或者广泛关系表的几列足以处理单个请求。
进一步利用缓存意识算法证明了这些设计决策的有效性。
多核动力引擎。
MonetDB 专为桌面上的多核并行执行而设计,可缩短复杂查询处理的响应时间。
探索了几种分布式处理技术,但正如许多人所发现的那样,没有灵丹妙药来改善并行处理性能。
对于简单的数据并行问题,map-reduce 方案就足够了,但是对于更复杂的情况,需要仔细考虑数据库设计和(部分)复制。
一个多功能的代数数据库内核。
MonetDB 旨在通过其专有的代数语言(称为MonetDB汇编语言(MAL))来适应不同的查询语言。
它为从查询编译器接收的声明性表达式到包括必要的分布式处理协议在内的路由铺平了道路,以引导各个数据库服务器的执行。
分发的主要前端是SQL到MAL编译器。
适合所有人的规模。
MonetDB支持的最大数据库大小取决于底层处理平台,例如32位或64位处理器,以及存储设备,例如文件系统和磁盘raid。
每个表的列数实际上是无限的。 每列都映射到一个文件,其限制由操作系统和硬件平台决定。
并发用户线程数是配置参数。
可扩展的平台。
MonetDB 受到科学实验的强烈影响,以理解算法和应用程序要求之间的相互作用。
它已将 MonetDB 转变为可扩展的数据库系统,在软件堆栈的所有级别都有挂钩。
这允许使用特定于域的规则扩展优化器管道线; 内核中针对特定领域算法的批量操作; 以及现有科学图书馆的传统操作封装。
应用范围广泛。
MonetDB通过连接外部提供的库来支持广泛的应用程序域,
例如: pcre,raptor,libxml和geos。
几种外部文件格式被封装到数据库中,这在一些科学领域中普遍存在的数据库处理和遗留文件处理之间创建了共生和自然桥梁。
一个开源解决方案。
MonetDB已经在CWI多年的研究中得到发展,其章程确保其他人可以轻松获得结果。
MonetDB论坛和邮件列表是开发团队的访问点。
通过MonetDB公司可以提供交钥匙扩展,高端技术咨询和合资项目。
前言
对于越来越多的分析型场景,例如数据仓库,科学计算等, 经典的数据库DBMS的检索性能颇显乏力。
相反的,最近出现了很多面向列存的数据库DBMS,像ClickHouse,Vertica, MonetDB等,因其充分利用了现代计算机的一些硬件优势,同时舍弃了一些DBMS特性,得到了非常好的检索性能。
本文就MonetDB, 整理一些资料和代码,简单介绍其核心设计。
通过简单Benchmark, 验证其检索性能。
飞速发展的硬件
CPU 计算模型
在过去的几十年中,CPU的架构设计经历了巨大的发展和变化,如今的CPU结构已经变动的非常复杂和精巧,其计算能力也得到了显著提升。
新硬件的发展驱使应用软件不断改进其架构设计,以至于更加贴合新硬件的优势,使应用软件表现出更好的性能。
下图展示了基础CPU模型和Pentium 4 CPU的结构(虽然Pentium也已经过时了),为了简化对CPU计算过程的认识,从基础CPU模型开始:
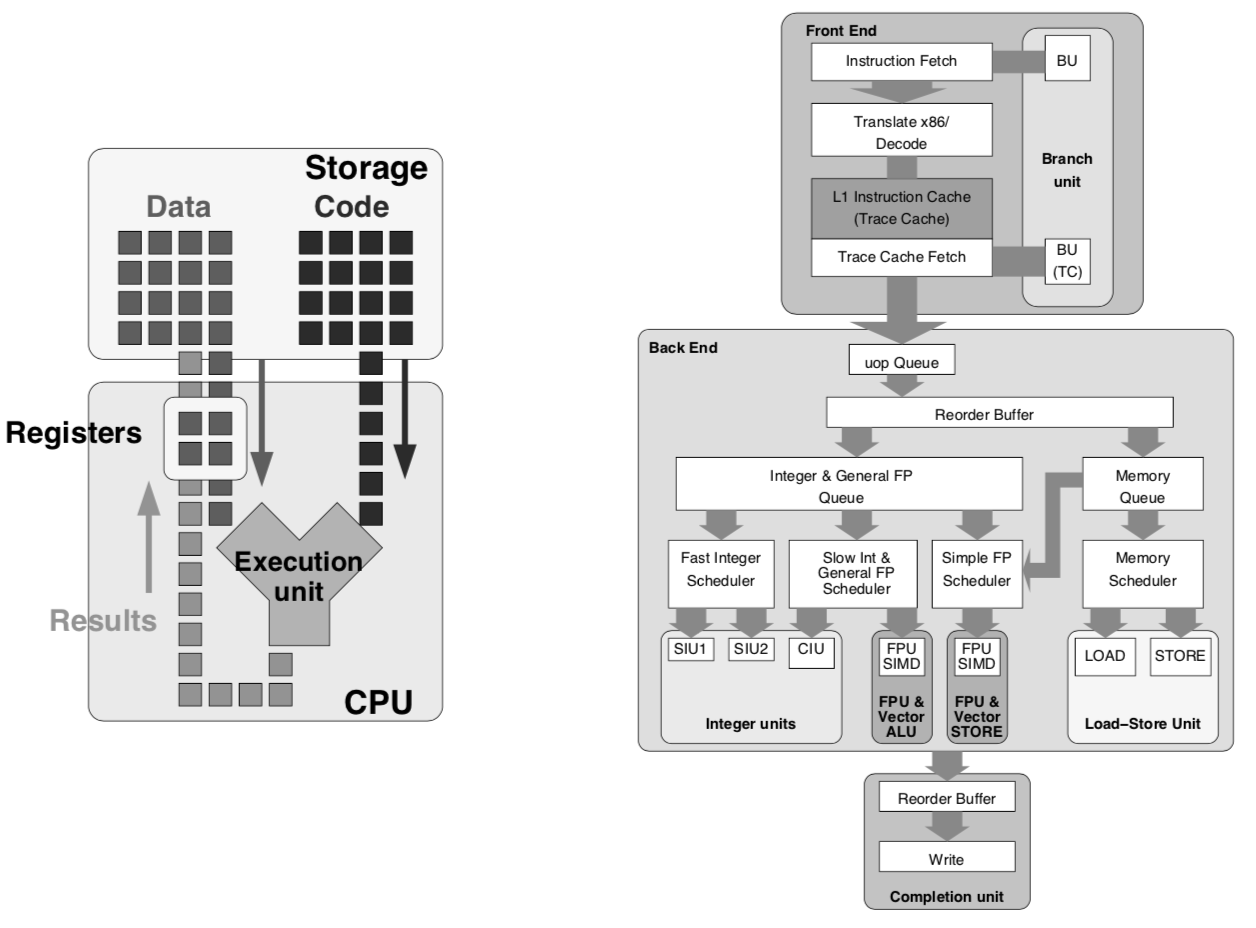
Data :
CPU 计算操作数,即每次计算的输入数据,例如一个整型值;
Code :
CPU 计算指令,命令CPU做何种计算;
Storage :
存储操作数和指令的容器,通常为主存RAM;
Registers:
寄存器,CPU内部存储单元,存储CPU当前执行的指令需要操作的数据。
Execution Unit :
计算执行单元,不断读取下一个待执行的指令,同时从寄存器读取该指令要操作的数据,执行指令描述的计算,并将结果写回寄存器。
以上这些抽象的逻辑单元都比较简单易理解。
该模型下CPU的每一次Cycle只执行一条指令。
通常情况下,每条指令的执行又可以分解为以下4个严格串行的逻辑Stage :
Instruction Fetch(IF) : 指令获取。获取待执行的指令。
Instruction Decode(ID) : 指令解码。根据系统指令集解码指令为microcodes。
Execute(EX) : 执行指令。执行解码后的microcodes, 不同类型的计算过程通常需要不同的物理计算单元来完成,例如代数计算单元,浮点数计算单元,操作数加载单元等。
Write-Back(WB) : 保存计算结果到寄存器。
不同的Stage通常由不同的CPU物理单元来完成,由于这几个Stage必须以严格串行的方式执行。
所以最简单的执行方式就是:每个CPU物理单元完成自己负责的Stage任务后将结果作为执行下一个Stage的CPU物理单元的输入,弊端就是,例如执行’EX’的CPU 物理单元必须等待执行’ID’的CPU物理单元完成,在此之前,它都是空闲的, 如下图”Sequential execution”所示。
为了提高效率,采用了 pipeline 的模式,如下图”Pipelined execution”所示:
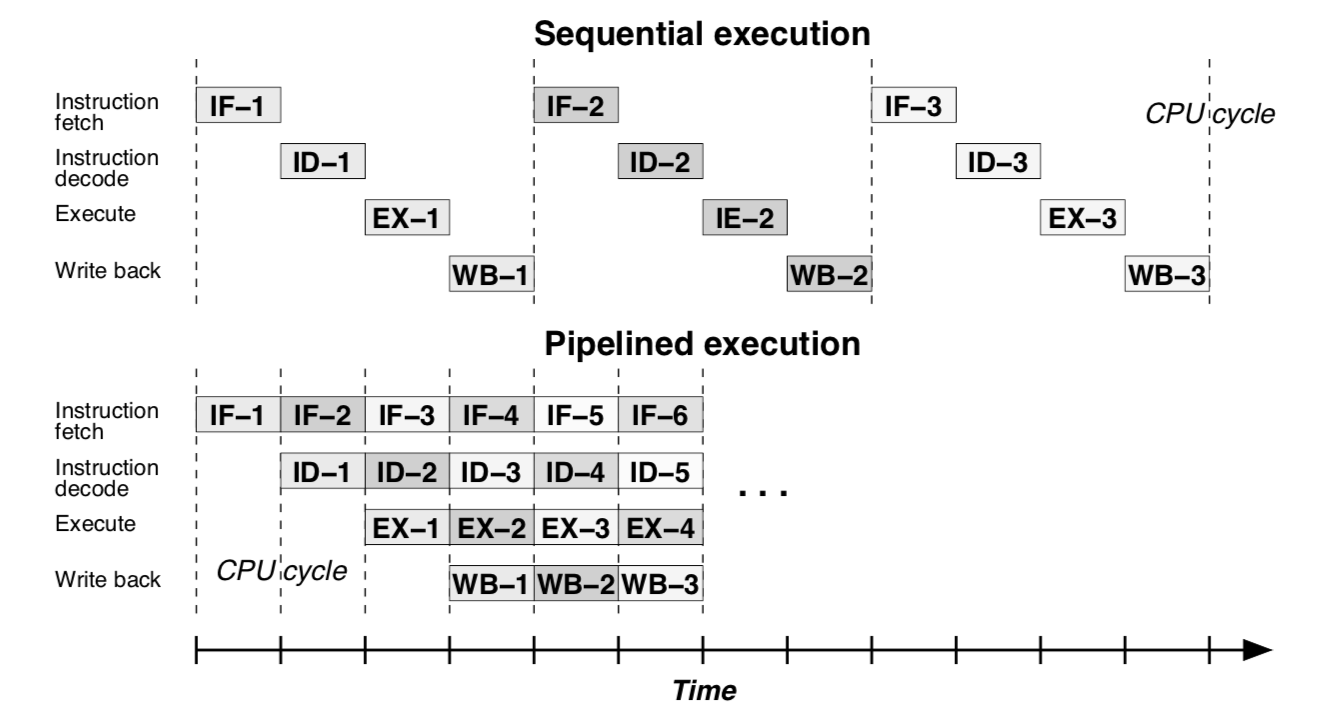
尽管Pipelined的执行方式并没有改变单条指令的执行时间,但整体指令流的执行吞吐明显提升了。
如上图所示,吞吐提升了4倍。当然,这仅是理想情况。
为了进一步提高CPU指令计算的吞吐,现代CPU进一步发展了Superscalar的执行方式,通过内置多个同类型的物理执行单元,来获取更”宽”的pipeline。
例如,在只有一个代数运算单元的CPU中,代数运算的pipeline宽度为1,即每个CPU Cycle只有一条代数运算指令被执行。
如果把代数运算单元double一倍,那么一个CPU Cycle内就可以有两条代数运算指令在不同的代数运算单元上同时执行,IF Stage也可以一次性获取两条指令作为pipeline的输入,此时Pipeline的宽度为2,CPU指令计算的吞吐又提升了一倍。
另外,除了通过扩展CPU单元的数量来提升CPU计算的吞吐,还可以通过提升单个CPU运算单元的能力来达到目的。
以前,一个代数运算单元一次(在一个CPU Cycle内)对一份操作数,执行一个代数运算指令,得到一份结果,这称为单指令单数据流(SISD)。
如现在的大多数CPU的代数运算单元,可以一次对多份操作数,执行同一个运算指令,得到多份结果,这称为单指令多数据流(SIMD)。假设在某些场景下,如果都是相同类型的计算,只改变计算的参数(例如图像领域,3D渲染等), 利用SIMD又可以成倍提升CPU计算吞吐。
Pipelined Execution, 其对CPU计算吞吐的提升都仅限于理想情况,其基本的假设是CPU正确的推测了马上会执行的指令并将其加入Pipeline。
但是很多情况下,下一个要执行的指令可能必须基于运行时的判断。
如果下一个指令恰好跳出了已经Pipelined的指令的范围,那CPU不仅要等待加载该指令,而且当前整条Pipeline需要被清空并重新加载,这被称之为Control Hazards, 另外,当跳转发生时,不仅指令需要被加载,指令相关的操作数也需要被重新获取,如果Cache-Miss导致主存Lookup,则至少要浪费上百个CPU Cycle, 这称之为Data Hazards。 这类因指令跳转造成吞吐下降的现象称为Pipeline-bubble。
现代CPU架构中,CPU-Cycle的Stage划分更加精细,加深了Pipeline的深度。更深的Pipeline有利于提高CPU计算的吞吐,但Pipeline-bubble的问题也被进一步放大。因此,对CPU-Friendly的代码,其性能更好,反之,性能反而有所下降。
抛开上面的逻辑模型,宏观上,现代CPU大都采用同步多线程技术(SMT), 多处理器架构(CMP)等,整体提升CPU的并行计算能力。
内存系统
相比于CPU计算能力的巨幅提升,Memory Access的时间并不显著。
因此,在现代主流计算机中,一个memory-access指令需要等很长的时间(几百个CPU-Cycle)才能把数据加载到寄存器中。
为了缓解此类问题,内存系统被设计为多层次内存体系。一些更快,但容量较小的静态存储媒介被加到内存体系中,作为主存RAM的缓存Cache Memory。Cache Memory分为D-Cache 和I-Cache, 分别用于存储数据和指令(代码);
在该体系中,按data access的时间从小到大,依次有Register, L1 Cache, L2 Cache, L3 Cache, 主存RAM等(相应的data access时间可以参考Jeff Dean’s Number)。
Cache Memory 通常被按固定大小分为很多个Cache lines, 每个Cache line缓存主存中的某一块相应大小数据。
Memory access 被设计为先访问Cache Memory,如果恰好访问地址在Cache lines中,称为cache-hit, 反之cache-miss。 cache-miss 引发主存lookup,并换入lookup到的数据块到cache line中。因为虚拟文件系统的关系,cache-miss时,lookup主存有可能引发page-fault, 延长数据获取时间。
更多关于Memory的知识可以阅读:What every programmer should know about memory.
数据库 Database: 行 or 列
经典关系数据库在逻辑上把数据保存成一系列行(row)的集合,每行对应关系数据的一个Tuple。
在物理存储上,也是如此。这种存储方式称之为NSM(N-ary storage model)。
与之相应的,是一种按列组织并存储数据的方式,称之为 DSM(Decomposed storage model), 如下图所示:
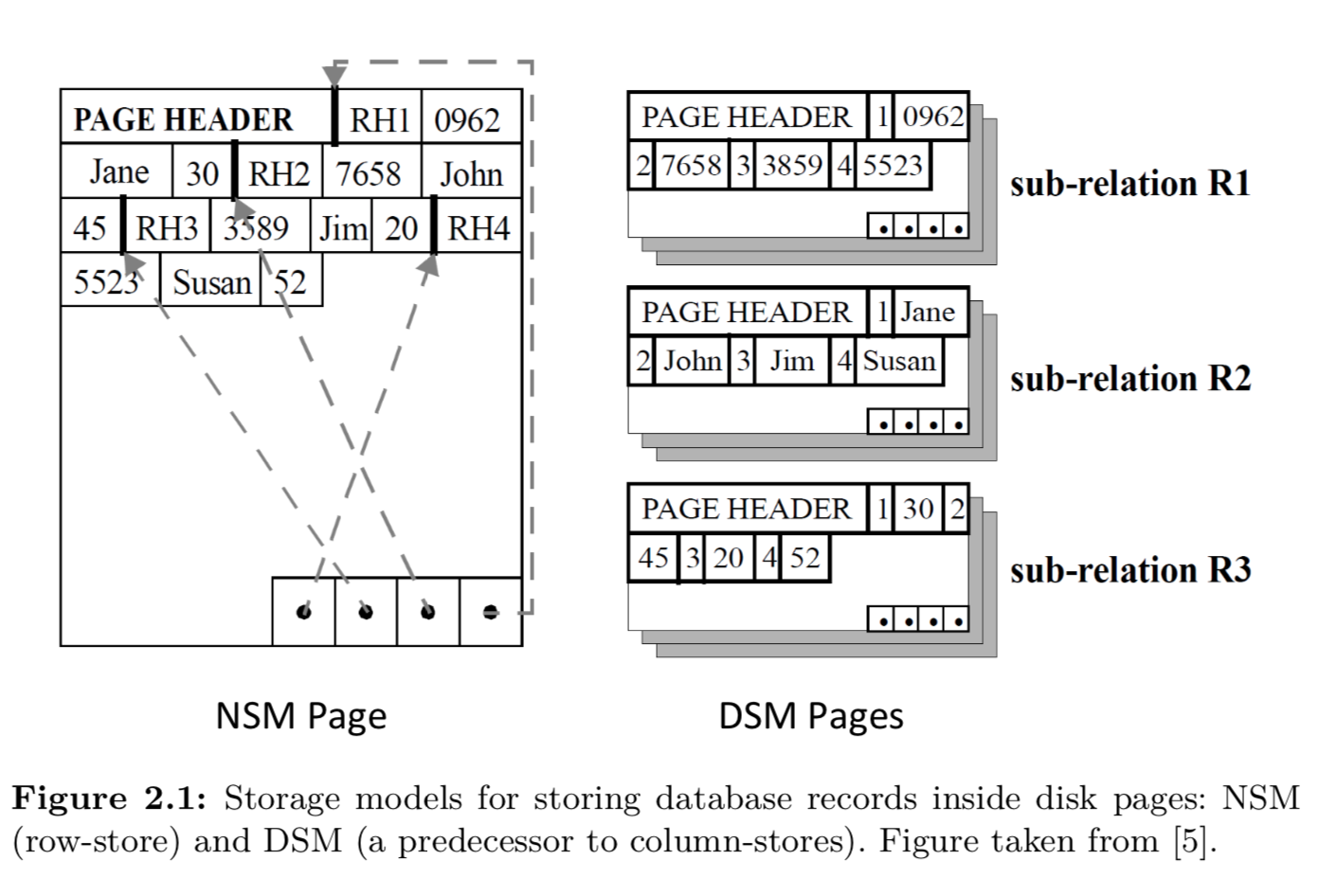
通常把这两种不同存储形式的数据库称为行存数据库或列存数据库。
列存数据库形式出现的也很早,只是在当时硬件条件下,列存数据库只有在select很少列的情况下,性能才会稍好于各类行存数据库。
这也形成了现在很多人固有的观念:”如果查询很多列,行存数据库完胜列存数据库;”。
加之以前数据库覆盖的都是OLTP场景,用户存取数据遵守三范式原则,只要读取一两个列的情形也比较少。
但随着硬件技术发展,列存数据库的能力又需要被重新审视。
下图列举了到2010年为止,已知的一些列存数据库读取多列数据性能的增长, 横轴为查询列占该关系所有列的比例。
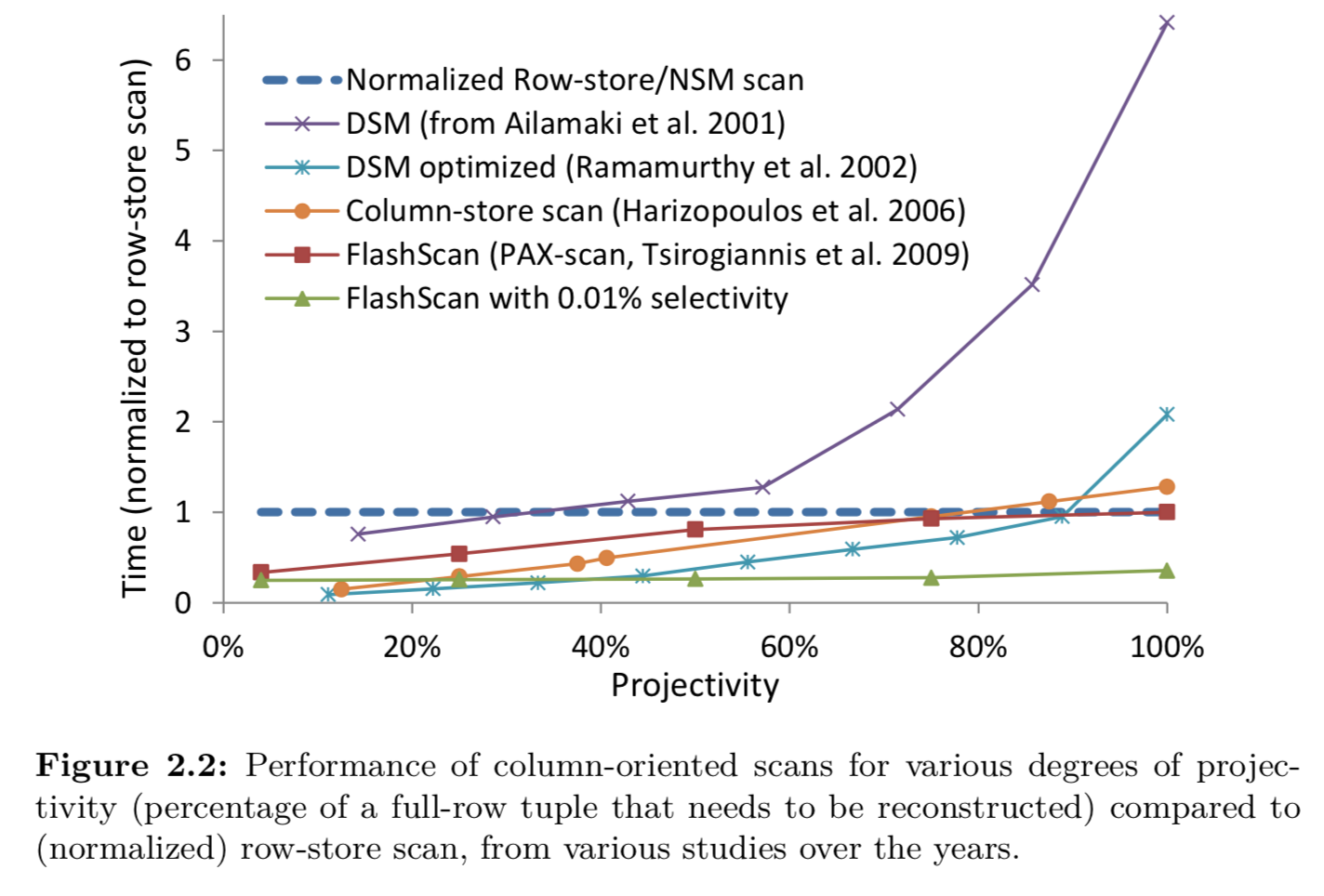
可以看到,近年来,即使是SELECT所有列数据,列存数据库的性能也不输行存数据库。
尤其在一些数据仓库或OLAP的场合,数据组织不在遵守三范式,而是为了节省关联时间存储成大宽表。
反而SELECT部分列更贴合需求。
经典行存数据库的性能分析
理论分析
除了数据存储方式的异同,查询执行层的设计也可能略有差异。
经典关系数据库基于一个称之为 Tuple-at-a-time 的迭代模型,各种关系算子按照一定的拓扑结构串联成查询计划。
查询执行时,数据按照算子之间拓扑关系构成pipeline。
如下图右侧所示,查询语句为:
SELECT Id,Name,Age,(Age-30) * 50 as Bonus FROM People WHERE Age > 30;
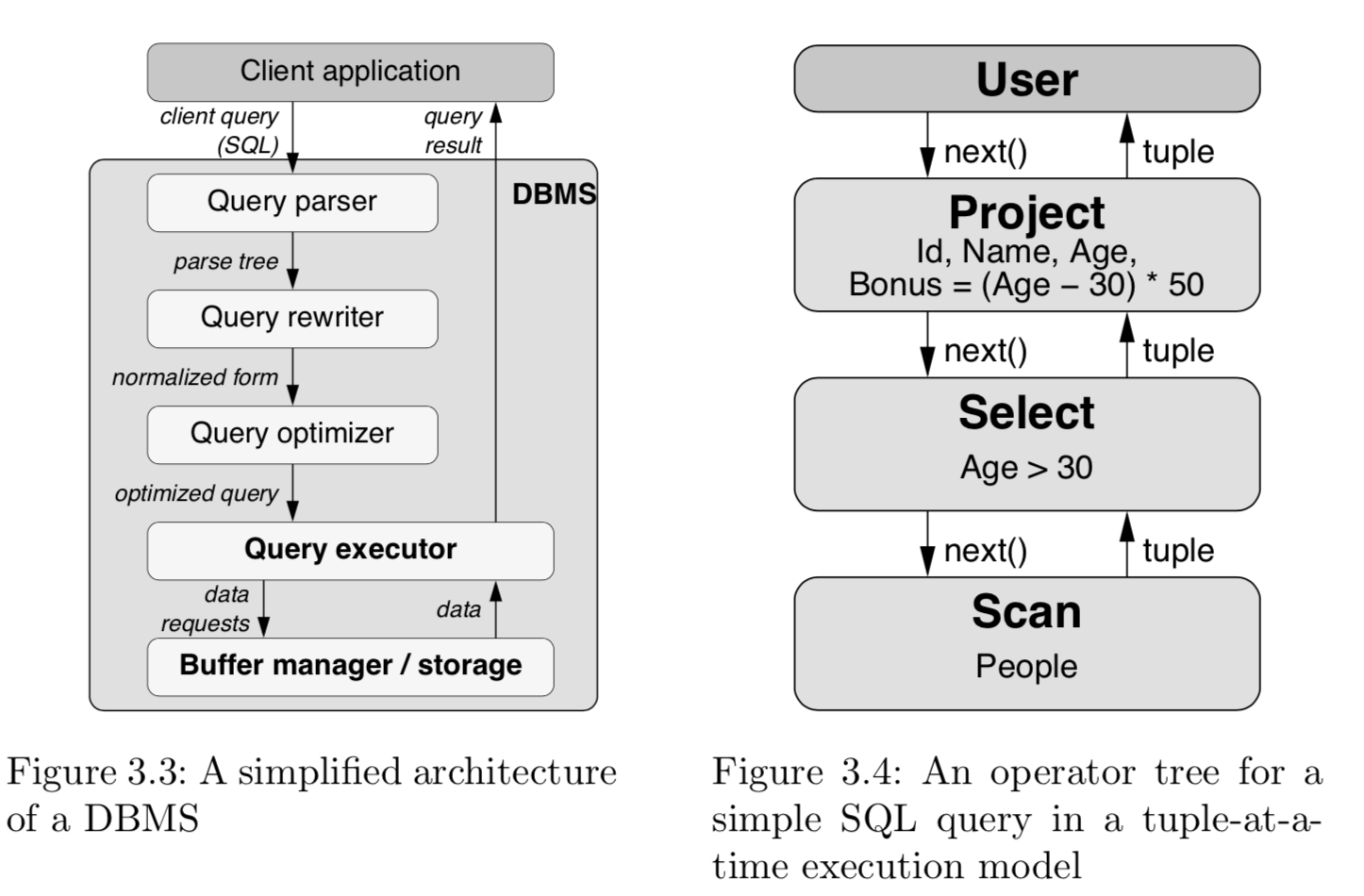
图中,子算子(位于上层的算子)调用next()函数向父算子(位于下层的算子)请求数据,最底层父算子从存储层获取数据,处理后返回给子算子,以此类推,每次next请求只返回一条数据(Tuple)。
整个执行模型是基于子算子的Pull模型,也称之为‘Pull based iterator model’。
Tuple-at-a-time 迭代模型下,每个Tuple从存储层读取出来后,都要经历很多个函数调用。
例如,每个父子算子之间的next()函数,Select算子调用filter函数,Project算子要调用代数运算函数等等。整个执行过程中,很多函数,代码,状态被重复很多次的频繁读取,调用,更新。从而导致了一些性能缺陷。
性能缺陷的相关理论
有学者从理论上分析了一下一些性能问题:
CPU Instruction Cache: 由于查询计划可能包含很多不同类型的算子,其组合到一起的所有指令的大小可能超过了I-Cache的容量。
每处理一个Tuple,CPU都需要在不同的算子之间不断的切换上下文(包括算子的计算指令,状态数据等),如果I-Cache不足以容纳所有指令,cache-miss会在整个执行过程频繁发生。
Function call overhead: 函数调用本身需要额外的CPU-Cycle, 尤其是当参数很多的时候。另外,如果是dynamically-dispatched的函数,可能需要几十个CPU-Cycle(因为跳转导致了Pipeline bubble)。
Tuple manipulation: 每个Tuple都包含多个属性, 对几个属性的操作(例如Select Age > 30)需要先定位并读取出Age属性,这种对Tuple的解释在每个Tuple处理时都要被重复很多次,花费很多额外的指令。
Superscalar CPUs utilization: 由于在Tuple-at-a-time模型中,每个算子一次只处理一个Tuple, 因此无法有效利用现代CPU Superscalar的特性。从而对现代CPU而言,每个CPU-Cycle, 只能执行很少的指令(low instructions-per-cycle)。
data volume : 由于按行存储的原因,计算中每个Tuple所有属性都被完整的读取出来,从磁盘到主存,到Cache。如果计算只需要部分属性,即浪费了RAM和Cache的空间,也浪费了Disk->RAM->Cache的带宽。
实验分析
也有学者 Trace TCP-H Query 1 的执行,从实验角度证明经典关系数据库在CPU利用率的低效。
# TPC-H Query 1
SELECT returnflag, sum(extprice * 1.19) as sum_vat_price FROM lineitem WHERE shipdate <= date ‘1998-09-02’ GROUP BY returnflag.
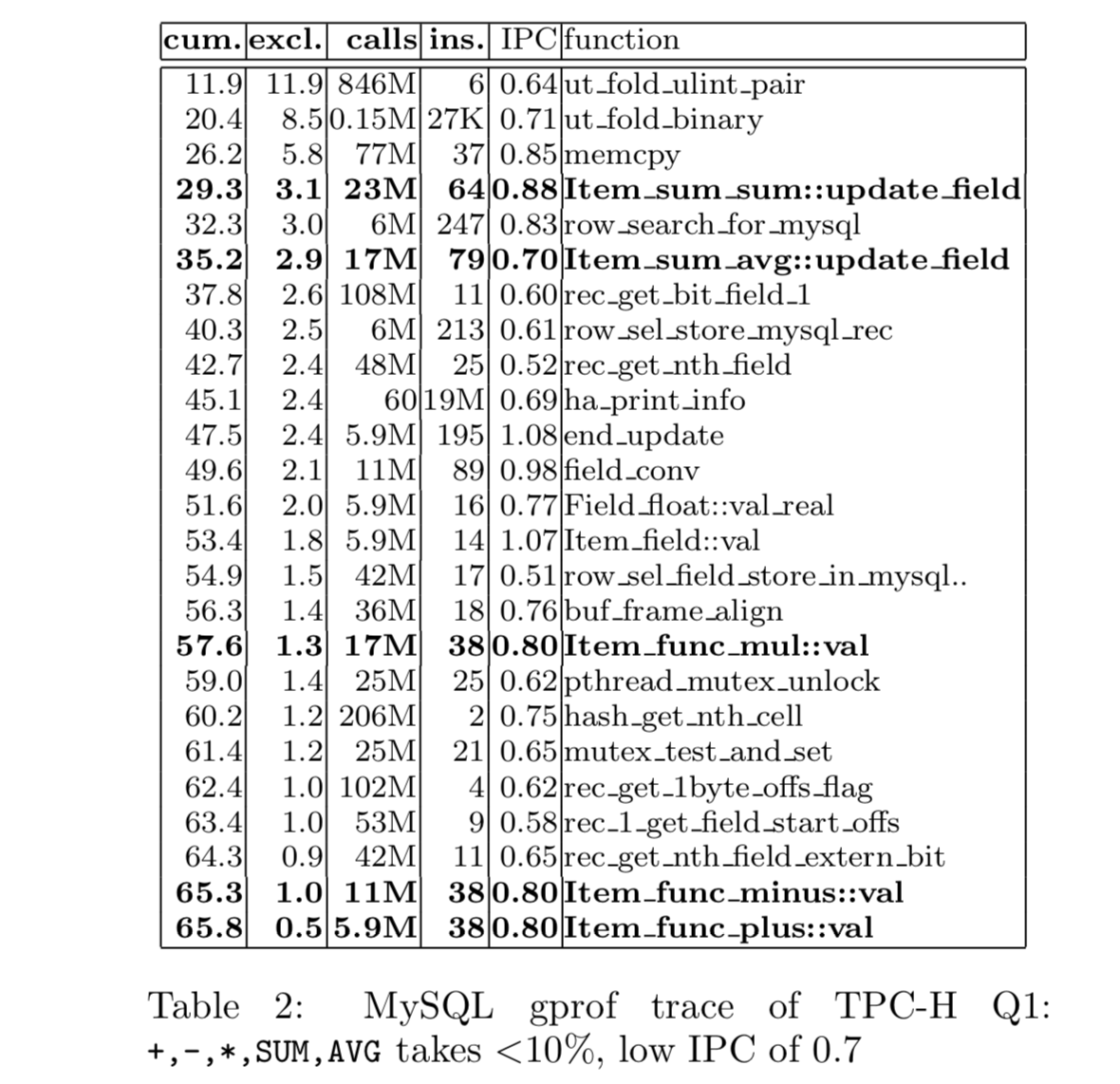
上图Benchmark, 查询执行过程中所有的函数调用按照其被调用的先后顺序排序,第一列为表示查询总时间,第二列表示当前Function执行耗时。第三列表示Function被调用执行的总次数,第四第五列表示每次Function执行所需的平均指令数以及平均IPC(Instruction-per-cycle)。
Benchmark至少说明了,在Tuple-at-a-time的经典行存数据库查询中,用户定义的数据计算的函数(+,-,*,sum,avg),其执行时间占查询总时间比例约10%。28%的时间耗费在聚合操作时,对Hash-Table的查找,写入。而62%的时间耗费在像rec_get_nth_field这样函数执行上,他们的主要功能,就是解释Tuple, 例如定位,读取或写入Tuple中的某些属性。
如此来看,对于每一个Tuple, 需要被执行的指令(instructions-per-tuple)非常多。
另一方面,所有函数执行的平均IPC约为0.7, 极大的低于现代Superscalar 处理器的计算水平。
总结起来,在经典关系数据库中,一个很高的instructions-per-tuple, 和一个很低的instructions-per-cycle, 导致了查询时很高的cycles-per-tuple。也就是说,即使是很简单的计算操作,每个Tuple的处理也很可能需要几百个CPU Cycle。
CPU的计算能力没有被充分利用,数据库查询的性能还有很大的提升空间。
正是为了解决这些问题,才有了MonetDB这些高性能列存数据库DBMS。
MonetDB
也许正是因为现有的数据库系统都没有充分利用现代计算器巨大潜力,才有了一些列像MonetDB这些高性能数据库的出现。
MonetDB被设计为面向数据密集型应用,使用新的查询模型,更高效的处理数据。
MonetDB里提出的所有数据处理技术都围绕两个点:一是面向CPU-Efficient计算, 二是存储带宽优化。
存储模型
区别于经典关系数据库,MonetDB采用DSM模型作为数据存储格式。
Tuple的各个属性被分开存储,相同属性的值被存储在一起,即典型的按列存储方式。
逻辑上,MonetDB中每一列被存储为一个Binary Association Table(BAT),简单来说,就是一个只有两列的表,第一列存储虚拟ID,第而列存储属性值。
同一个Tuple的不同属性具有相同的虚拟ID, 即可以通过相同虚拟ID来关联同一Tuple的不同属性,从而构建Tuple的完整数据。
物理上,虚拟ID并不一定被真的被存储,例如,对于定长属性, 其所有值按紧凑数据格式存储,相应的虚拟ID就是数组的下标。
对于不定长属性, 其不定长的数据内容存储在连续存储空间,用一个定长的指针来关联真实值,而虚拟ID就是指针数组的下标。
如下图,左边数据按BAT的格式组织,右边描绘了该格式下执行
SELECT Id,Name,Age,(Age-30) * 50 as Bonus FROM People WHERE Age > 30;
查询的方式:
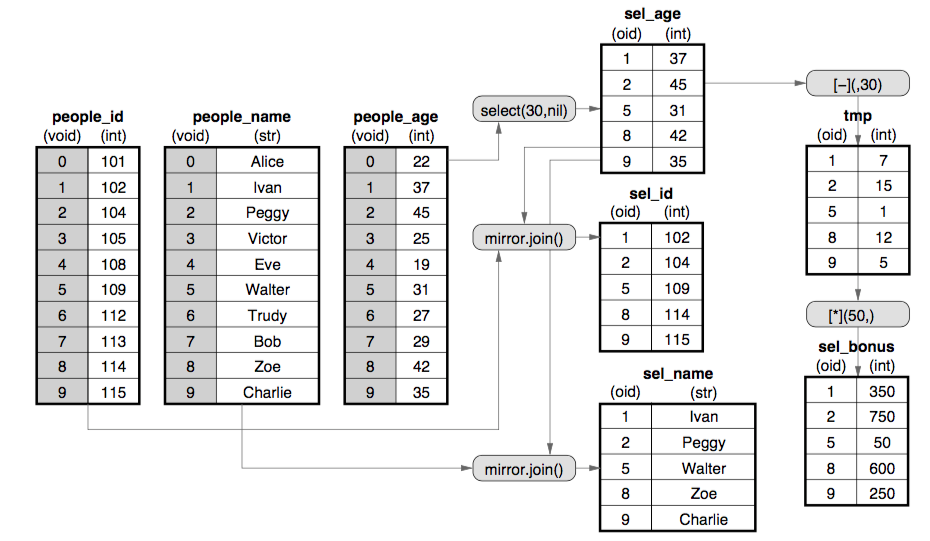
这样存储的好处有,
第一,相同属性的值存储在一起,可以比较高效的应用一些压缩算法,减少其占用存储空间大小。
第二, 针对特定列的计算只需要读取该特定列的值, 既可以较大提升存储的I/O性能,也可以减少内存使用。
第三, 每列数据按紧凑数组的方式存储,大部分针对属性的计算简化为对数组值的遍历计算,可以比较高效的利用CPU的计算能力(如SIMD等)。
计算模型
在以上列存格式的数据存储的基础上,MonetDB为应对数据密集型应用,专门研发了一套高效的查询执行引擎,该引擎创造性的提出了一种新的执行模型,称之为“Vectorized in-cache execution model”。
首先,和传统的Pipelined模型一样, MonetDB的查询计划是由各种算子(operator)构成了一个树(或DAG)。
但不同的是,传统Pipelined模型中的算子每次计算的对象是一个Tuple,而MonetDB中,算子每次计算的,是一组由相同属性的不同属性值构成的向量(数组)。
在每个算子内部,针对其计算属性的类型,使用高度优化的代码(primitive)来处理向量数据。
向量是 MonetDB 执行模型中最基本的数据处理单元和传输单元(作为计算中间结果在算子之间传递), 向量其实是一个由同一属性的多个不同属性值构成的一维数组,根据属性类型的异同,向量的大小也有差异。
采用这种针对向量的计算模式的优势是,每个算子在计算过程中不在需要像传统Pipelined模型里那般,要从Tuple里定位,读取某些属性,计算完成后再定位写入到输出Tuple中, 而是完全顺序的内存读写,省去了这些Tuple解释操作,即高效的利用了内存带宽,也节省了data-access的时间。同时,为CPU自动优化SIMD指令提供了机会。
以下通过 TPC-H Query 1 举例说明 MonetDB 查询执行过程:
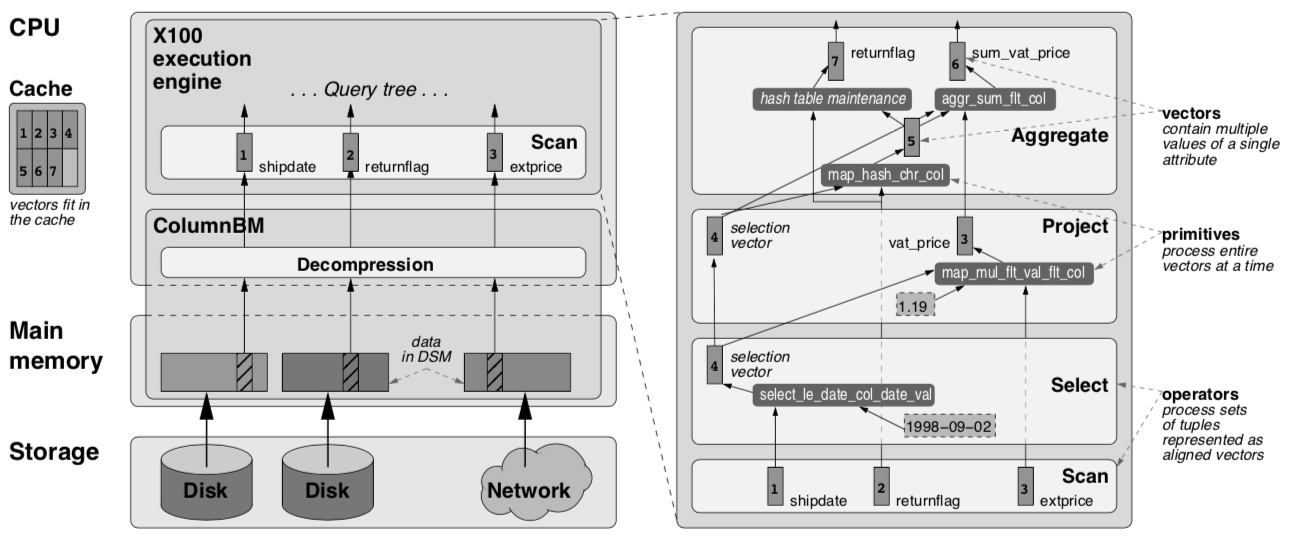
左图为查询执行时数据在不同存储单元的传输过程。
MonetDB提出了一种名为ColumnBM的列式数据组织方式,可以在有限带宽条件下,尽可能提升scan的性能。
磁盘和内存的数据都是压缩数据,当他们被以向量的形式加载的CPU Cache时才被解压,有助于提升内存利用率。
不同列上的计算是分开的,直到最后才被物化为用户需要的行式结果。
右图是查询执行计划和向量数据流,整个查询计划从下到上有四类算子: Scan, Select, Project, Aggregate。
但计算不同类型列的同种算子,其内部代码也不同。
例如,负责处理’shipdate’列的Scan算子,内部代码(primitive)是对Date数据类型的紧凑遍历, 同时按条件筛选值。
而负责处理’extprice’的Scan算子,其内部代码(primitive)只是对Double的顺序读。
所有算子的输入和输出都是向量,整个查询计划是由向量构成的pipeline (详细的向量计算算法这里不展开)。
由于主存带宽无法满足CPU-Efficient的代码(primitive)对数据的饥渴需求, MonetDB打算充分利用cache-memory带宽来缓解问题。
由此提出了in-cache计算: 所有的向量都被用特殊的方式组织,已使他们的大小可以完全放入CPU Cache。
因此,一些计算的结果可以被保存在CPU Cache,而不需要写回到内存。后续的计算可以直接读取这些Cache中的结果,节省了主存读的时间。
仍然以一个 SQL 查询的例子说明计算过程:
SELECT l_quantity * l_extendedprice AS netto_value,
netto_value * l_tax AS tax_value,
netto_value + tax_value AS total_value
FROM lineitem
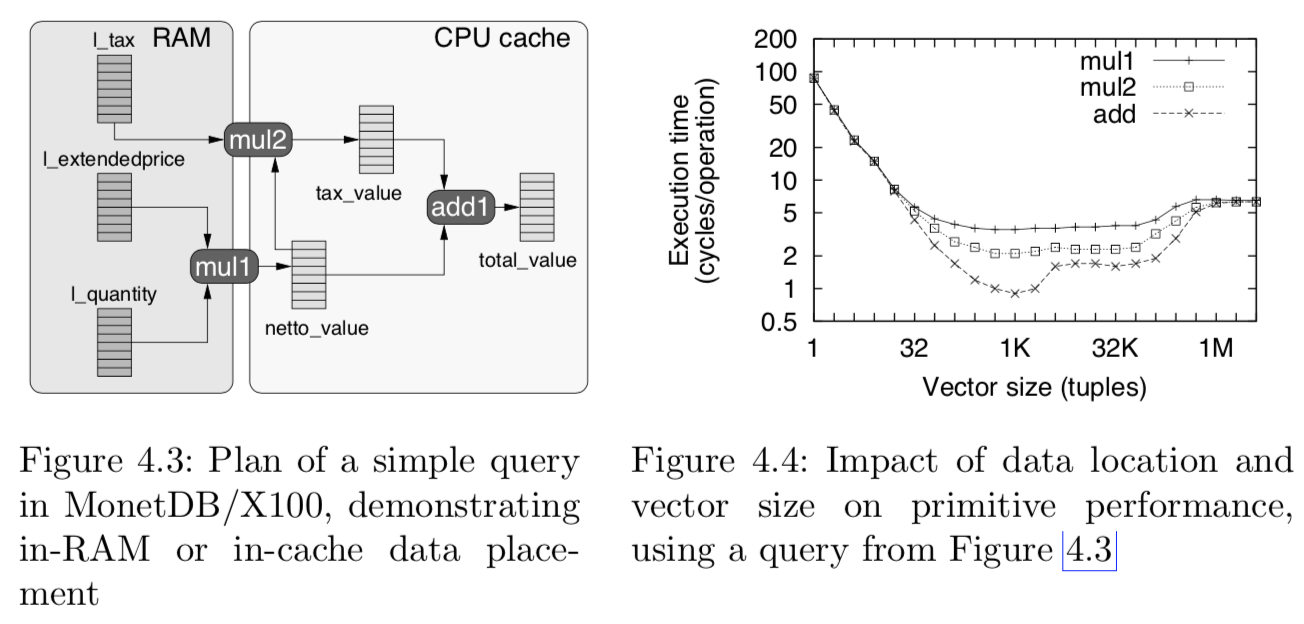
如图, ‘l_quantity * l_extendedprice’ 的结果‘netto_value’被保存在CPU-Cache中,当计算‘tax_value’时,只需要从主存读取‘l_tax’的向量值就可以了,同时,计算结果也被保存在CPU-Cache中,当计算‘total_value’时不再需要从主存读数据。
由此,减轻了主存读写带宽瓶颈对计算的限制。
右图表明, “add”操作的性能要好于”mu1”和”mu2”, 因为它的输入数据都在CPU Cache中。
同时,也证明了不同向量大小对计算性能的影响,当向量较小时(向量总数较多),没有充分利用CPU-Cache的空间。
向量较大时,因为无法全部放入CPU-Cache,导致部分数据必须从主存获取。当向量大小接近CPU-Cache时,达到了平衡,此时的计算性能是最优。
性能分析
对于现代计算机的主要硬件, MonetDB 有以下优化:
CPU: MonetDB 查询执行过程中,负责处理数据的代码(primitive)通常都是非常简单的逻辑,即使有函数调用,也大都被设计为在一个函数调用中处理多组数据。
大大减少了函数调用次数。对于单个数据来说,发生函数调用的overhead被多组数据所分摊。
加上 SIMD 等优化,每条数据计算所需的指令数被减少,也就得到了一个很低的 instructions-per-tuple 值。
Cache: 查询过程中,各算子之间以向量(vector)的形式交换数据,向量被设计为一个比较优化的大小,可以完全放入内存(fully cache-resident), 节省了主存数据读写的大延时。处理数据的代码(primitive)也被优化为采用cache-efficient的算法来实现。
RAM: 数据按列存储,并高效压缩。相同容量的RAM可以放入更多的数据。
Disk: MonetDB 中几乎没有随机读,所有的查询计算都是基于Scan。
当数据需要存储在磁盘上时,MonetDB优化了数据结构,形成了一套名为ColumnBM I/O Subsystem的机制来提升磁盘Scan的性能。
对照上文经典关系行存数据库的理论分析的维度,分析MonetDB:
instruction-cache: 虽然 MonetDB 也采用 pipelined 的方式执行查询,其各算子的所需的指令总和也可能超过I-Cache的容量大小。
但不同于Tuple-at-a-time模型,MonetDB中各算子计算的是向量,CPU也需在不同算子之间切换,但即使发生指令的cache-miss,其重新load的时间可以被向量中所有数据所分摊。
Function call overhead: 绝大多数算子实现都是对向量调用函数,而不是对单条数据的频繁调用。大大减少了函数调用的次数。
Tuple manipulation: 所有算子的输入输出都是向量的形式,即一个连续的紧凑数组。计算过程直接读写数据,不需要任何对数据做任何解释。
Superscalar CPUs utilization: 因为计算都是针对向量的,即相同的指令处理一系列数据。MonetDB 还特别针对数据处理代码(primitive)做了优化,使其尽可能不包含跳转指令,充分发挥SuperScalar CPU向量计算的能力。
Data volume: 由于采用了按列存储的方式,只有计算所需要的列才会被读取,并且,列式数据被高效的压缩,即节省了RAM空间,使其可以Keep更多的数据,也提高了Disk->RAM->Cache 的带宽利用率。
Benchmark
MonetDB中的数据读是基于Scan的,因此数据存储介质的不同,性能差异也会比较大。
在实现中,MonetDB采用Memory mapped file的方式,将所有数据存储映射为虚拟内存地址,从代码层面忽略了存储介质的类型,依赖系统的MMU换入物理内存地址以外的数据页。
在实际查询计算过程中, MonetDB为了保证向量计算的性能,通常尽可能一次换入当前计算所需列的所有数据,如果真实数据的某一列的大小超过MonetDB可支配物理内存的总大小,针对该列的查询性能损耗会比较严重,但相对来说,还是优于使用相同硬件存储数据,并且未建索引的行存DBMS。
说到索引,MonetDB 目前支持两类索引 IMPRINTS 和 ORDERED。
但这两类索引只支持定长数值类型,并且不支持复合索引。如果出现上面提到的情形,某列大小超过可支配物理内存,并且该列支持建索引,那么建索引后可以极大提升查询性能。
MonetDB paper 中给出了 TPC-H Query 1 的查询性能(如下), 证明其基于向量计算的性能已经接近 hand-code C 代码的性能:

为了体验MonetDB, 以下是SQLite-In-Memory和MonetDB 的对比测试。
数据来自AMPLab : https://amplab.cs.berkeley.edu/benchmark 中的用户访问数据(uservisit),采样了32,00万数据,DDL语句:
CREATE TABLE "user_visit" (
"sourceid" BIGINT,
"destid" BIGINT,
"sourceip" VARCHAR(116),
"desturl" VARCHAR(100),
"visitdate" DATE,
"adrevenue" DOUBLE,
"useragent" VARCHAR(256),
"countrycode" CHAR(3),
"languagecode" CHAR(6),
"searchword" VARCHAR(32),
"duration" INTEGER
);
其中,souceid 和 destid 分别是对 sourceip 和 desturl 做 Murmur 哈希得到的 long 值。
批量数据导入: SQLite-In-Memory导入到内存, MonetDB导入到磁盘 ,原始CSV文件大小6.3G :
| DBMS | DDL | Cost /s | Total Size/G | |
| SQLite-In-Memory | .mode csv; .import raw.csv user_visit | 347 | 6.37 | |
| MonetDB | COPY | INTO user_visit FROM raw.csv | 88 | 2.2 |
结论
对于MonetDB而言, 内存很重要。查询的性能完全取决于数据是否In-Memory。
在实验中,我们尝试更换不同性能的磁盘,有SATA盘,SSD, 和内存挂载盘,其随机读性能有千百倍的差异,但对MonetDB的查询影响不大(因为MonetDB依赖顺序读)。
MonetDB Paper中宣称在In-Memory模式下,单核可以每秒处理多达GB数据。
对定长列的查询要比对不定长列查询要快很多。
对有很多重复值的列的查询要比对值是Unique的列的查询快很多。
查询列的个数对查询性能影响不大。
参考资料的学习方法
背景
参考资料中参考的资料如下:
Zukowski M. Balancing vectorized query execution with bandwidth-optimized storage[J]. University of Amsterdam, PhD Thesis, 2009.
Abadi, Daniel, et al. "The design and implementation of modern column-oriented database systems." Foundations and Trends® in Databases 5.3 (2013): 197-280.
Zukowski, Marcin, et al. "MonetDB/X100-A DBMS In The CPU Cache." IEEE Data Eng. Bull. 28.2 (2005): 17-22.
Boncz, Peter A., Marcin Zukowski, and Niels Nes. "MonetDB/X100: Hyper-Pipelining Query Execution." Cidr. Vol. 5. 2005.
个人收获
可以根据这些信息,拓展自己的信息来源。
而不是只会根据百度的结果。
