设计理念
云数据库POLARDB基于Cloud Native设计理念,其架构示意图及特点如下:
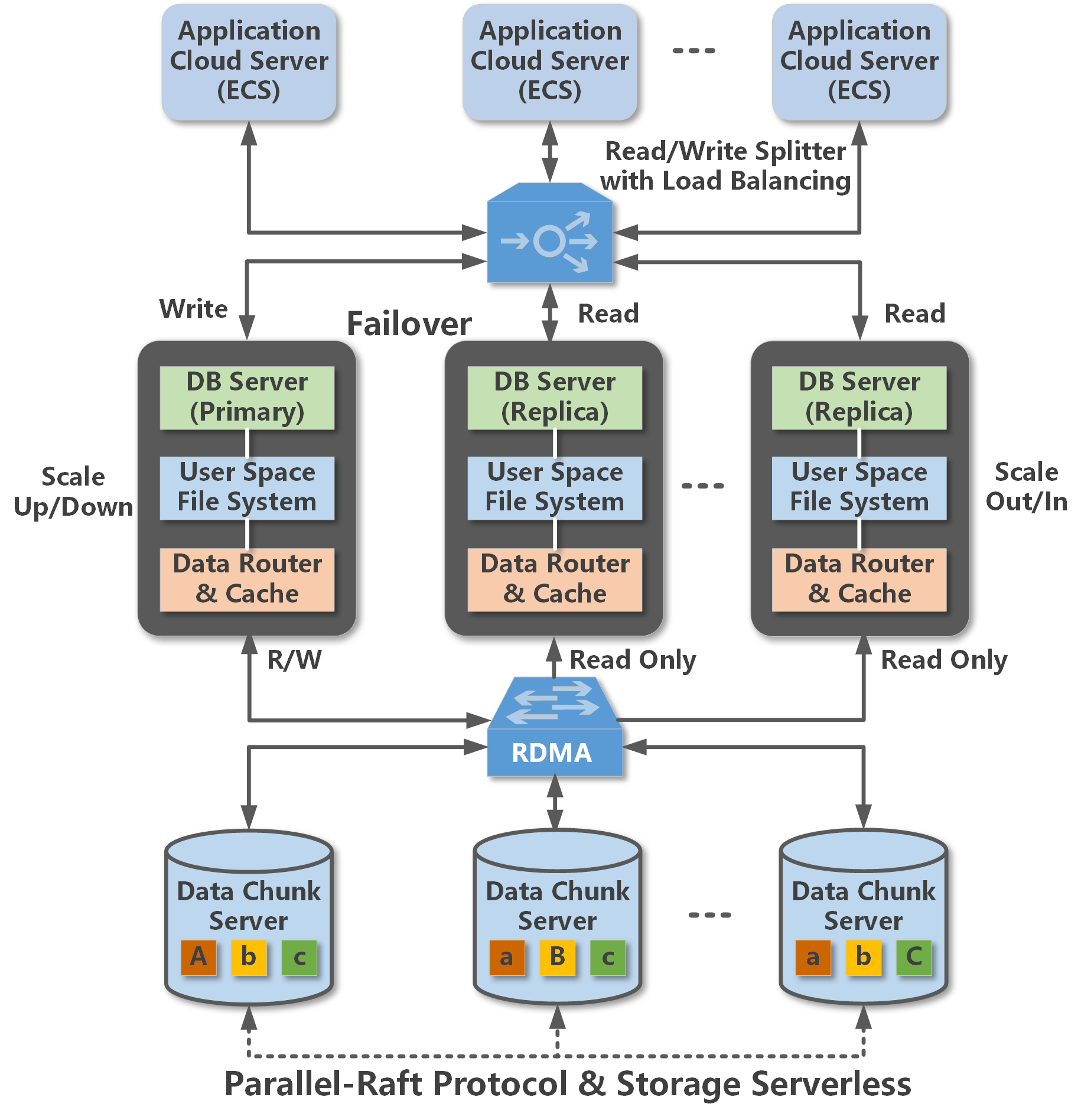
一写多读
POLARDB采用分布式集群架构,一个集群包含一个主节点和最多15个只读节点(至少一个,用于保障高可用)。
主节点处理读写请求,只读节点仅处理读请求。
主节点和只读节点之间采用Active-Active的Failover方式,提供数据库的高可用服务。
计算与存储分离
POLARDB采用计算与存储分离的设计理念,满足公共云计算环境下用户业务弹性扩展的刚性需求。
数据库的计算节点(DB Server)仅存储元数据,而将数据文件、Redo Log等存储于远端的存储节点(Chunk Server)。
各计算节点之间仅需同步Redo Log相关的元数据信息,极大降低了主节点和只读节点间的延迟,而且在主节点故障时,只读节点可以快速切换为主节点。
读写分离
读写分离是POLARDB for MySQL集群默认免费提供的一个透明、高可用、自适应的负载均衡能力。
通过集群地址,SQL请求自动转发到POLARDB集群的各个节点,提供聚合、高吞吐的并发SQL处理能力。
高速链路互联
数据库的计算节点和存储节点之间采用高速网络互联,并通过RDMA协议进行数据传输,使I/O性能不再成为瓶颈。
共享分布式存储
多个计算节点共享一份数据,而不是每个计算节点都存储一份数据,极大降低了用户的存储成本。
基于全新打造的分布式块设备和文件系统,存储容量可以在线平滑扩展,不会受到单机服务器配置的影响,可应对上百TB级别的数据规模。
数据多副本、Parallel-Raft协议
数据库存储节点的数据采用多副本形式,确保数据的可靠性,并通过Parallel-Raft协议保证数据的一致性。
基本概念
集群(Cluster)
POLARDB采用集群架构,一个集群包含一个主节点和多个读节点。
集群可以跨可用区(AZ),不能跨地域(Region)。
节点 (Node)
POLARDB集群由多个物理的节点构成,目前每个集群中的所有节点可分为两类,分别为主节点(Writer)和只读节点(Reader)。
每类节点关系对等,规格相同。
主节点(Writer)
主节点,也叫读写节点,一个集群有一个主节点,可读可写。
读节点(Reader)
只读节点,一个集群最多15个。
故障切换(主备切换/Failover)
提升一个只读节点为主节点。
规格(Class)
每个节点的资源配置,例如2核4GB。
访问点(Endpoint)
访问点(Endpoint)定义了数据库的访问入口,也可以称之为接入点。
一个集群提供多个Endpoint,每个Endpoint后面接一个或多个节点。
例如,主访问点永远指向主节点,集群Endpoint提供了读写分离能力,后挂主节点和只读节点。
Endpoint 中主要包含的是数据库链路属性,例如读写状态、节点列表、负载均衡、一致性级别等配置信息。
访问地址(Address)
访问地址是访问点在不同网络平面中的载体,一个Endpoint可能包含私网和公网两种访问地址。
访问地址中包含了一些网络属性,例如,域(Domain)、IP地址、专有网络 (VPC)、交换机(VSwitch)等。
主访问点(主地址/Primary Endpoint)
主节点(Writer)的访问点,当发生故障切换(Failover)后,会自动指向到新的主节点。
集群访问点(集群地址/Cluster Endpoint)
整合集群下所有节点,对外提供一个统一的访问入口,可以设置为只读或可读可写(自动读写分离),具有自动弹性、读写分离、负载均衡、一致性协调等能力。
地域(Region)
地域是指物理的数据中心。一般情况下,POLARDB集群应该和ECS实例位于同一地域,以实现最高的访问性能。
可用区(Availability Zone(AZ))
可用区是指在同一地域内,电力和网络互相独立的物理区域。在同一地域内可用区与可用区之间内网互通,可用区之间能做到故障隔离。
主可用区(Primary AZ)
POLARDB主节点所在可用区。
集群可用区(Cluster AZ)
集群数据分布的可用区。一个集群的数据会自动在两个可用区间做冗余,用于灾难恢复。
只支持在这些可用区间进行节点迁移。
