SequoiaDB
SequoiaDB 巨杉数据库是一款金融级分布式关系型数据库。
自研的原生分布式存储引擎支持完整 ACID,具备弹性扩展、高并发和高可用特性,支持 MySQL、PostgreSQL 和 SparkSQL 等多种 SQL 访问形式。
SequoiaDB 适用于核心交易、数据中台、内容管理等应用场景。
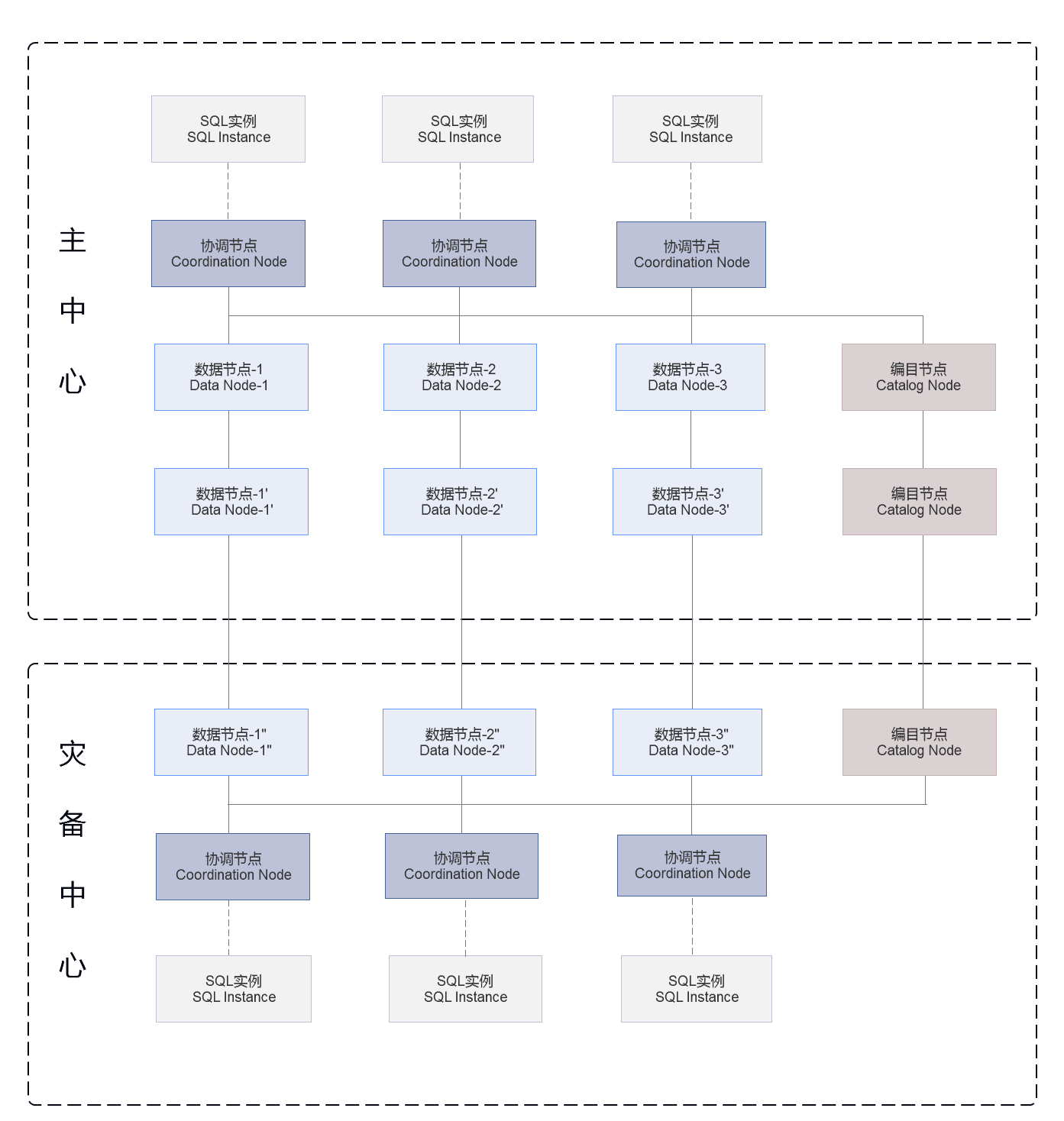
系统架构
个人感受
技术看起来前叉万变,实际技术本身差别不大。
都是索引+锁+持久化+网络访问。
数据中台
SequoiaDB 巨杉数据库提供了企业历史与实时数据的统一纳管平台,激活企业数据核心价值。
通过对海量历史与实时数据的采集、计算、存储、加工,数据中台为应用上层多变的业务逻辑与底层稳定的数据结构提供中间层统一的标准与口径,满足企业业务和数据的沉淀,实现生产系统瘦身、历史数据在线化,降低重复建设、减少烟囱式协作的成本,增强企业差异化竞争优势。
行业痛点及现状
近年来,随着IT技术与大数据的不断发展,越来越多的企业将数据作为自身宝贵的资产进行长期保留。
同时,微服务与分布式技术的不断发展,使得联机应用程序不再使用“烟囱式”方式构建,而是需要由众多原子服务组件在一个数据池中进行灵活的数据访问。
这使得一些传统联机应用程序的历史数据包袱越来越重,灵活性大幅度下降,导致最终数据库不堪重负、应用整体性能低下。
另一方面,随着大数据需求的不断增加,曾经已经归档的数据需要重新在线以满足在线化、实时化使用、查询和分析等等要求,这就要求将原有庞大的离线数据进行“在线化”与“服务化”。
这些需求使得数据中台系统成为各大企业IT建设与投入的方向。
解决方案
数据中台方案并非某一种特殊的技术或产品,而是在企业中提供数据整合并对外提供联机服务的一组数据服务。
不同于大数据以面向内部分析统计挖掘为主,数据中台主要面向外部的最终客户,提供高并发低延时的联机类业务支持。
数据中台体系可以分为四大部分,包括ODS区、贴源数据存储区、数据加工调度区、以及对外服务区。
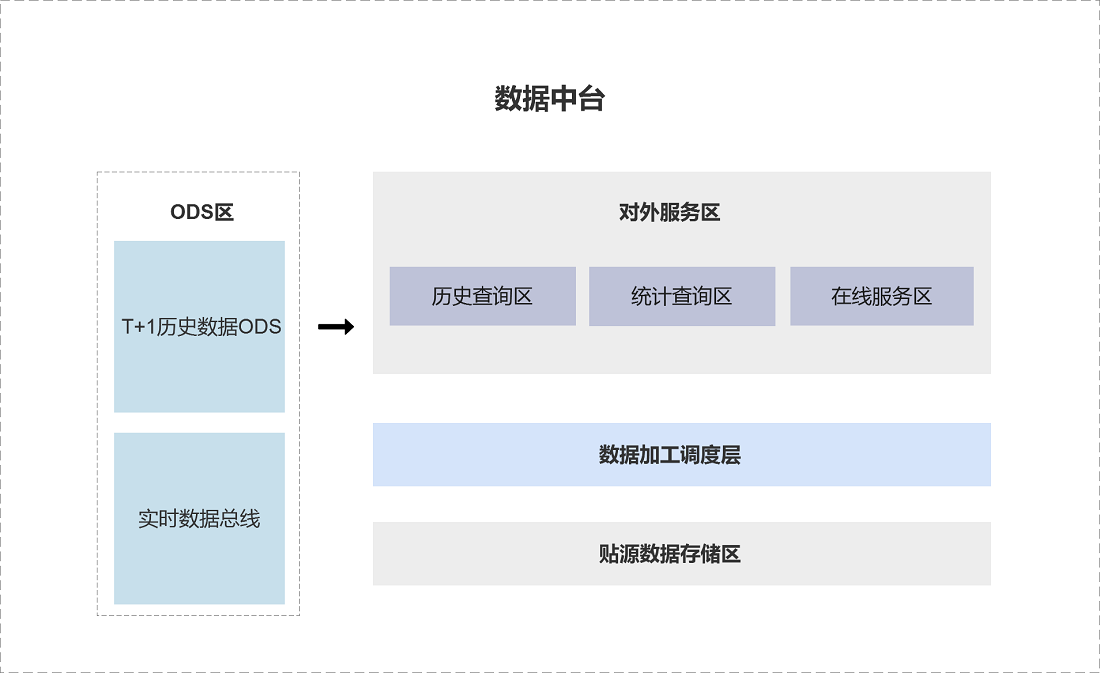
ODS层是数据接入的同步层,它源于各个业务系统,同时面向后续的数据清洗和加工,提供了最初的数据统一接入(数据准备区),涉及到离线数据和(准)实时数据。
贴源数据存储区存放的是用户的明细数据与原始未加工数据。
一般来说, 贴源数据存储区中的数据结构与内容和原始业务系统保持一致,用户也可以将该区域用于数据的在线归档服务。
数据加工调度区则是将贴源数据进行清洗加工,形成可以直接面向对外联机应用的数据结构。
随着应用程序不断迭代变化,数据加工调度区作为原始明细数据与对外应用数据之间的桥梁,屏蔽了外部应用与企业内部数据结构之间的差异,弱化了应用之间数据交换的壁垒。
对外服务区则是应用程序真实访问的业务数据。针对应用程序类型的不同,对外服务区可以分为历史明细查询区、自由查询区以及在线服务区。
其中,历史明细查询区可以作为视图映射接口,直接将外部应用对接到创建了合适索引的历史明细数据,使得外部应用直接对海量历史明细数据进行访问。
同时,对于一些需要简单加工的明细数据,也可以通过数据加工调度区的梳理后独立存放访问。
自由查询区主要面对类似审计后督、自助报表等非固定查询业务。一般来说,提供给自由查询服务的数据往往未经过复杂的数据加工,允许应用直接访问部分原始数据。
而在线服务区则提供T+0(准)实时的数据访问能力,其数据源往往直接对接ODS层的(准)实时数据同步服务,使得应用程序通过数据中台(准)实时地访问联机业务系统中的最新数据。
