文本分类:
1. 啥是文本分类(Text Classification):
将一篇文档分到其中一个或者多个类的过程,例 :判断分类出垃圾邮件
类型:包括类别数目(Binary、multi-class)、每篇文章赋予的标签数目(Single label、Multi label)
基础知识
一. 概率论基础
- 条件概率公式:
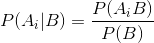
- 全概率公式:
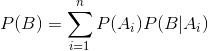
- 由条件概率公式和全概率公式可以导出贝叶斯公式
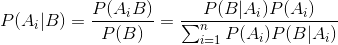
二. 文本分类
要计算一篇文章D所属的类别c(D),相当于计算生成D的可能性最大的类别 Ci(Ci属于C),即:
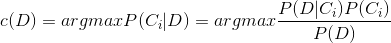
其中 P(D) 与 C 无关,故:
c(D) = argmax P(D|C_i) * P(C_i)
三. 朴素贝叶斯分类模型
朴素贝叶斯假设:在给定类别C的条件下,所有属性Di相互独立,即,
P(D|C, D_j) = P(D_i|C)
根据朴素贝叶斯假设,可得
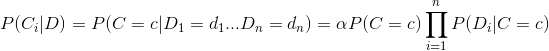
其中,
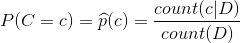
count(c|D):类别c中的训练文本数
count(D):总训练文本数
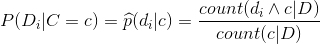
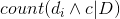 单词di在类别c中出现的次数
单词di在类别c中出现的次数
综上可得,
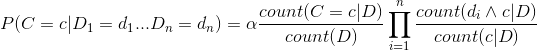
这个是最核心的公式,直接根据这个计算的结果就可以推断出最大的概率了。
朴素贝叶斯理论:
1. 分类规则:
根据贝叶斯定律,并由于分母对所有类别都一样,故可以去掉,求得:
上式存在过多的参数,每个参数都是一个类别和一个词语序列的组合,要估计这么多的参数,必须需要大量的训练样例,但是,训练的规模总是有限的。于是,出现数据稀疏性(data sparseness)问题
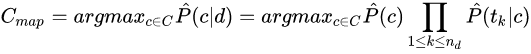
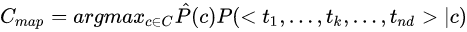
2.条件独立性假设:
为了减少参数数目,给出朴素贝叶斯条件独立性假设
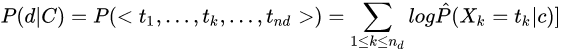
3. 位置独立性假设:
对于类别 c 中的一篇文档,词项 t_k 在文档中的位置不影响生成它的概率
以上两个独立性假设实际上是词袋模型(Bag of words model)
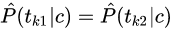
特征选择:
1. 含义:
从训练集合出现的此项中选出一部分子集的过程,在文本分类过程中也仅仅使用这个子集作为特征
2. 目的:
第一,减小词汇空间来提高分类器训练和应用的效率;
第二,去除噪音特征(Noise Feature),从而提高分类精度
3. 基本的特征选择算法:
给定类别 c ,对词汇表中的每个词项 t ,我们计算效用指标 A(t,c) ,然后选择k个具有最高值的词项作为最后的特征,其他词项则在分类中被忽略
常用选择方法
-
互信息
-
x^2 统计量
-
词频统计
朴素贝叶斯的实现方式比较:
1、贝努利模型(Multivariate Bernoulli Model):
不考虑词在文档中出现的次数,只考虑出不出现,因此在这个意义上相当于假设词是等权重的,其是一种以文档位计算粒度的方法
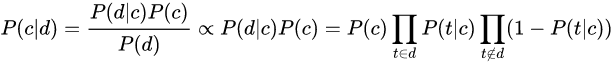
2、多项式模型:
各单词类条件概率计算考虑了词出现的次数,是一种以词作为计算粒度的方法
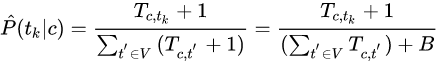
3、高斯朴素贝叶斯:
对特征向量 {x1, x2, …, xn} ,如果特征值 xi 取连续值,比如温度,则可采用高斯模型求解
朴素贝叶斯分类器(Naive Bayes Classifier ):
1. 朴素贝叶斯是一个概率分类器
文档 d 属于类别 c 的概率计算如下(多项式模型):
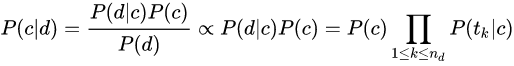
n_d 是文档的长度(词条个数)
P(t_k | c) 是词项 t_k 出现在类别 c 中文档的频率,即类别 c 文档的一元语言模型
P(t_k | c) 度量的是当 c 是正确类别时 t_k 的贡献
p(c)是类别 c 的先验概率
如果文档的词项无法提供属于哪个类别的信息,那么我们直接选择 P(c) 最高的那个类别
2. 对数计算:
朴素贝叶斯分类的目标是寻找“最佳”的类别
最佳类别是指具有最大后验概率(Maximum A Posterior,MAP)的类别:
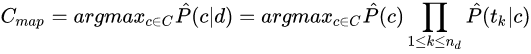
很多小概率的乘积会导致浮点数下溢出
由于 log(xy)=log(x)+log(y) ,可以通过取对数将原来的乘积计算变成求和计算
由于 log 是单调函数,因此得分最高的类别不会发生改变,因此,实际中常用的是:
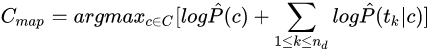
ps: 这个转换非常重要,而且性能较好。分词时其实也有类似的操作。
每个条件参数 P(t_k| c) 是反映 t_k 对 c 的贡献高低的一个权重
先验概率 P(c) 是反映类别 c 的相对频率的一个权重
因此,所有权重的求和反映的是文档属于类别的可能性。
3. 最大似然估计
如何从训练集中估算出 P(t_k| c) 和 P(c):
(1) 先验概率 P(c) = Nc/N
Nc: 类 c 中的文档数目; N :所有文档的总数
(2)条件概率:
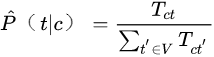
T_ct 是训练集中类别 c 中的词条 t 的个数(多次出现要计算多次)
4. MLE估计的零概率问题:
如果 t_k 在训练集中没有出现在类别 c 中,那么就会有零概率估计:
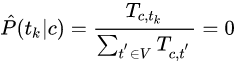
那么,对任意包含 t_k 的文档 d , P(c|d) = 0
一旦发生零概率,将无法判断类别
5. laplace 平滑
避免零概率:加一平滑
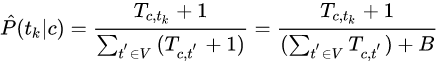
B是不同词语个数(这种情况下 |V| = B ),利用加1平滑从训练集中估计参数
6. 训练过程 & 测试应用:
对于新文档,对于每个类别,计算:
先验的对数值之和以及词项条件概率的对数之和
7. 时间复杂度分析:
朴素贝叶斯对训练集的大小和测试文档的大小而言是线性的,这在某种意义上是最优的
文本分类器评估(Classifier Evaluation)
1. 防止过拟合的情况:
评估必须基于测试数据进行,且该测试数据是与训练数据完全独立的(通常两者样本之间无交集)
2. 评估指标:
正确率(P)、召回率(R)、 F_1 值、分类精确率(Classification accuracy)
正确率(P) = TP/(TP+FP)
召回率(R) = TP/(TP+FN)
F_1 值是在正确率和召回率之间达到某种平衡
F_1 = 2PR / (P+R)
F_1 也就是P和R的调和平均值:
1/F_1 = 1/2 * (1/P + 1/R)
3. 综合性能
如果我们希望得到所有类别上的综合性能。则可以用宏平均(macro-averaging)和微平均(Micro-averaging)
实现方式
训练数据
可以从资源数据中获取,以搜狗实验室的新闻分类为例。
数据的处理
(1)数据预处理
针对原始数据的分类
根据 url 可以判断对应的分类。
可以跳过一些空内容。
(2)特征数据
对原始的文章进行分词、停顿词移除、key-word(基于 TI-DF 算法)得到每一篇文章的关键词及对应的权重。
(3)直接根据贝叶斯计算
使用拉普拉斯平滑,避免零概率
使用 log 将乘法转换为加法,避免计算溢出 。
参考代码
核心分类代码
import java.io.File;
import java.io.IOException;
import java.util.Vector;
public class TrainDataManager {
private static final String dirName = "trainingData/Sample"; // 训练集所在目录
CountDirectory countDir = new CountDirectory();
private int zoomFactor = 5; // 放大倍数
/**
* 计算先验概率 p(ci)=某个类别文章数/训练文本总数
*
* @param className 类别名称
*
* @return 类别的先验概率
*/
public double priorProbability(String className) {
double probability = 0.0;
probability = (double) countDir.countClass(className) / countDir.countSum();
return probability;
}
public void execute(String article) throws IOException {
// 进行分词
Vector<String> strs = ChineseSpliter.splitWords(article);
File dir = new File(dirName);
File[] files = dir.listFiles(); // 目录下的所有文件
String className;
double countc;
double product = 1;
Vector<Double> probability = new Vector<Double>();
double temp;
// 计算文本属于每个类别的概率
for (File f : files) {
className = f.getName();
countc = countDir.countClass(className);
// 计算文本中某个词属于特定类别中的概率
for (String word : strs) {
temp = (countDir.countWordInClass(word, className) + 1)
/ countc * zoomFactor;// 避免所得结果过小,对结果进行放大
product *= temp;
}
probability.add(priorProbability(className) * product);
product = 1;
}
double max = 0;
int maxId = 0;
for (int i = 0; i < files.length; i++) {
if (max < probability.get(i)) {
max = probability.get(i);
maxId = i;
}
}
System.out.println("文章所属分类为:" + files[maxId].getName());
}
}
用于计算训练集中的各种频次
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
/**
* 计算各种频次
*
* @author Administrator
*
*/
public class CountDirectory {
private static final String dirName = "trainingData/Sample"; // 训练集所在目录
public int countSum() {
File dir = new File(dirName);
File[] files = dir.listFiles(); // 目录下的所有文件
String subName = ""; // 子目录的路径名称
int sum = 0; // 训练集中所有类别的总文本数
// 计算所有文件的总数
for (int i = 0; i < files.length; i++) {
subName = files[i].getName();
sum += countClass(subName);
}
return sum;
}
/**
* 用于计算某个类别下的文章总数
*
* @param className
* 类别名称
* @return 给定类别目录下的文件总数
*/
public int countClass(String className) {
String classPath = dirName + "/" + className;
File subDir = new File(classPath);// 子目录
File[] subFiles = subDir.listFiles(); // 子目录下的所有文件
return subFiles.length;
}
/**
* 计算某个类别中包含给定词的文章数目
*
* @param word
* 给定的词
* @param className
* 类别名称
* @return className中包含word的文章数
*/
public int countWordInClass(String word, String className)
throws IOException {
int count = 0;// 总数
String classPath = dirName + "/" + className;
File subDir = new File(classPath);
File[] subFiles = subDir.listFiles();
String filePath = "";
// 计算word在各篇文章中出现的次数
for (int i = 0; i < subFiles.length; i++) {
// 读取文章
filePath = subFiles[i].getAbsolutePath();
InputStreamReader is = new InputStreamReader(new FileInputStream(
filePath), "gbk");
BufferedReader br = new BufferedReader(is);
String temp = br.readLine();
String line = "";
while (temp != null) {
line += temp;
temp = br.readLine();
}
br.close();
if (line.contains(word))
count++;
}
return count;
}
}
个人的实现思路
数据整理 + 训练
将相同类别的文章放在一起。
计算出每一个词对应的 TF-DF 频率,做好持久化。
先验概率,就是 = 某个类别的文章数/总的文章数量。
将数据整理的过程,变为训练的过程:
训练的结果,将先验概率+TF-DF 放在一个固定的文件中。每一个词的的权重已经提前计算好。
结果可以放在一个文件中,每个词按照类别分别计算好概率(可能比较稀疏)
结果按照类别放在不同的文件中。
测试验证
新的文本需要归类时:
(1)分词
(2)去停顿词
(3)循环计算每一个的权重
如果对应的词库中没有,p = 1 / count,或者直接获取 minFreq(建议这个。)
(4)选出最大的概率
(5)可以计算当前概率占总概率的百分比,输出每一个。
抽象,进一步抽象。
能否做成一个模板,只需要提供数据即可
当然文件的格式必须固定。
资源数据
拓展阅读
常见方法
90年代以来,随着信息存储技术和通讯技术的发展,大量的信息呈爆炸式增长,信息自动分类己经成为人们获取有用信息不可或缺的工具。
文本分类是中文信息处理的一个重要的研究领域。
其目标是在分析文本内容的基础上,给文本分配一个或多个比较合适的类别,从而提高文本检索等应用的处理效率。
目前已经有许多方法应用到该领域,如支持向量机方法(SVM)、K近邻方法(KNN)、朴素贝叶斯方法(NaiveBayes)、决策树方法(DecisionTree)等等。
朴素贝叶斯分类以其坚实的数学基础和丰富的概率表达能力,尤其是它能充分利用先验信息的特性越来越受到人们的重视,是目前公认的一种简单有效的概率分类方法,在某些领域中表现出很好的性能。
贝叶斯方法的一大优点是利用了先验信息,能够在不确定性的推理中提供一种模式和处理方法。
朴素贝叶斯与其他分类法相比,具有更小的出错率、健壮性和效率。
贝叶斯常见优化思路
但方法的数据稀疏的问题以及所采用的laplace平滑方法还存在一定的缺陷还不是最优。
因此,我们提出用uni-gram的平滑方法来改进数据稀疏状况,通过对贝叶斯分类的平滑方法进行改进提高其分类效果。
本文利用了贝叶斯理论对文本进行了分类。
主要完成了以下几个方面的任务:
-
描述了文本分类系统的一般过程,包括文本信息的表示、提取,文本分类的方法,介绍了贝叶斯理论。
-
分析了朴素贝叶斯文本分类方法的特点及缺陷,并提出用一元统计语言模型的平滑技术对其数据稀疏问题引起的零概率进行改进的可行性。
-
用uni-gram模型的三种平滑方法即Jelinek-Mercer平滑方法、Dirichiet平滑方法、绝对折扣法对贝叶斯分类器进行改进,提出了具体的算法和实现框图,这是本文的核心内容。
-
通过实验分析确定平滑算法的参数取值,比较改进了的贝叶斯分类器与原来采用laplace平滑的分类器的性能,提高了分类准确率和召回率。
今后,应该用统计语言模型的二元、三元模型来更好的改善贝叶斯的分类效果。同时可以考虑将贝叶斯分类系统的特征提取方法中将tf.idf和MI两种标准结合以提高分类器性能。
遗传算法
最接近神的算法,也可以和贝叶斯进行结合。
