情感分析名词概述
是什么
情感分析是文本分类的一个分支,是对带有情感色彩(褒义贬义/正向负向)的主观性文本进行分析,以确定该文本的观点、喜好、情感倾向。
例如说,文本”这是书读来爱不释手”归为正向,”这本书很难看”归为负向。
当然也有层次更多的分类。
为什么
被研究的主观性文本包括顾客对某个产品的评论,大众对某个新闻热点事件的观点等。
通过这些文本,商家可以为消费者提供决策参考,相关机构也可以了解舆情,但人工分析耗费大量成本。
怎么做
目前有基于情感词典的情感分析和基于机器学习的情感分析这两种主流方法。
【基于情感词典】是指根据已构建的情感词典,对待分析文本进行文本处理抽取情感词,计算该文本的情感倾向。最终分类效果取决于情感词典的完善性。
【基于机器学习】是指选取情感词作为特征词,将文本矩阵化,利用logistic Regression, 朴素贝叶斯(Naive Bayes),支持向量机(SVM)等方法进行分类。最终分类效果取决于训练文本的选择以及正确的情感标注。
(觉得有点抽象的后文有例解)
当然,特定情况下研究某些文本时也可以将两种方法结合起来。
比如说某些领域的文本没有标注,该领域的情感词典也不够完善,而人工标注需要耗费大量成本,数据的采集相对于人工成本小很多时;
可以选取部分文本,利用基本情感词典的方法粗略地计算这些文本的情感得分值,选取分值偏高或偏低的文本作为已标注的训练文本。
再结合机器学习的方法进行分析。
任务类型
当前研究中一般都不考虑情感分析五要素中的观点持有者和时间,故后文中的讨论都不考虑这两个因素。
根据对剩下三个要素的简化,当前情感分析的主要任务包括可按照图 3 所示:词级别情感分析、句子/文档级情感分析、目标级情感分析。

其中词级别和句子级别的分析对象分别是一个词和整个句子的情感正负向,不区分句子中具体的目标,如实体或属性,相当于忽略了五要素中的实体和属性这两个要素。
词级别情感分析,即情感词典构建,研究的是如何给词赋予情感信息,如“生日”对应的情感标签是“正面”。
句子级/篇章级情感分析研究的是如何给整个句子或篇章打情感标签,如“今天天气非常好”对应的情感标签是“正面”。
而目标级情感分析是考虑了具体的目标,该目标可以是实体、某个实体的属性或实体加属性的组合。
具体可分为三种:Target-grounded aspect based sentiment analysis (TG-ABSA), Target no aspect based sentiment analysis (TN-ABSA), Target aspect based sentiment analysis (T-ABSA).
其中 TG-ABSA 的分析对象是给定某一个实体的情况下该实体给定属性集合下的各个属性的情感分析,如下图中的实体是汽车,属性集合是动力、外观、空间和油耗。
情感分析流程例解
在本篇文章中,我试图用最简洁的语言和图例展现这两种分类方式。
基于情感词典的情感分析
以下是我一条猫眼上选取的《西游伏妖篇》影评:
Review1 =“周星驰+徐克,把观众期待度放到很大,看后小失望。特效场景、人物服饰、经典创新这些方面都很值得欣赏,可惜硬伤是一众主演演技尴尬,剧情超级无聊,走神好多次。”
情感词:设定positive的词+1,negative的词-1;
程度词:比如出现”小失望”就 -11,出现”非常失望”就-13
那么这句话的情感总分值就是 13-11+13-1-13 = 1
| 其中正向得分:13+13-1*3 = 3,负向得分 | -1*1-1 | =2 |
可输出[review1 : 1 ] or [review1: (3,2)].
分词
中文分词可利用jieba, THULAC,ICTCLAS
该方法的重点在于『构建适合的情感词典』,不在此赘述,会在后续文中填上。
基于机器学习的情感分析
若以下是一些政治方面的新闻文本
n xxx
n+1 xxx
n+2 xxx
(1)首先人工标注好其情感分类。正向为1,负向为0。
(2)我们要选取这些文本中的【特征词】,比如说做情感分类时的特征词要选取情感词,做商品分类时要选取商品名、商品特别的描述词等,构造词袋(bags of words)模型。
即统计各词词频,形成如下词矩阵:
其中A,B,C,D… 代表各情感词,每一行代表一个文本,每个数代表在该文本中该特征词词频。
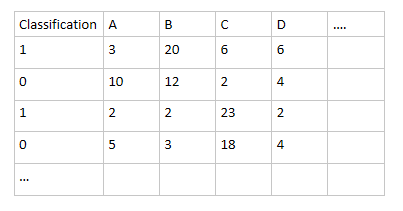
用numpy的数据类型将该数据储存起来
【生成词向量的方法英文处理可考虑库gensim, 并且Multiangle’s Notepad 这篇博客有详细介绍“利用gensim和sklearn搭建一般文本分类器方法”】
(1)分类算法
将数据集分为n份,其中n-1份为训练集,1份测试集,从库sklearn中载入svm, logisticRegression, NB等分类算法。
train_set = data[1:i,:] #i-1个数据作为训练集
test_set = data[i:,:] #剩余的数据作为测试集,训练集要远多于测试集
train = train_set[:,1:]
tag = train_set[:, 0] #第一列是类标签
import sklearn
from sklearn import svm
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
clf_svm = svm.LinearSVC()
clf_svm_res = clf_svm.fit(train,tag)
train_pred = clf_svm_res.predict(train)
test_pred = clf_svm_res.predict(test_set)
clf_lr = LogisticRegression()
...
clf_nb = GaussianNB()
...
将数据集分为n份,其中n-1份为训练集,1份测试集,从库sklearn中载入svm, logisticRegression, NB等分类算法。 train_set = data[1:i,:] #i-1个数据作为训练集 test_set = data[i:,:] #剩余的数据作为测试集,训练集要远多于测试集
train = train_set[:,1:] tag = train_set[:, 0] #第一列是类标签
import sklearn from sklearn import svm from sklearn.linear_model import LogisticRegression from sklearn.naive_bayes import GaussianNB
clf_svm = svm.LinearSVC() clf_svm_res = clf_svm.fit(train,tag) train_pred = clf_svm_res.predict(train) test_pred = clf_svm_res.predict(test_set)
clf_lr = LogisticRegression() …
clf_nb = GaussianNB() …
(2)选择最优
测试集轮换重复n次,使用交叉验证测试分类器的准确度。
在此另n=10,比较不同分类器的准确率,比较选出最优的。
from sklearn import cross_validation
kfold = cross_validation.KFold(len(x1), n_folds=10)
svc_accuracy = cross_validation.cross_val_score(clf_svm, train, tag, cv=kfold)
print 'SVM average accuary: %f' %svc_accuracy.mean()
这种方法的重点在于特征选取。
整体流程
数据抓取
爬虫获取基本数据
数据处理
分词
词性标注
移除停顿词
情感词典
- 知网 HOW NET
- 同义词词林拓展版
- 大连理工大学中文情感词汇本体库
褒贬与权重
基础情感词典
不同词语的褒贬不同
不同词语的权重也不同
程度副词
否定词
网络情感词典
领域情感词典
短文本情感分析
分词+移除停顿词+词性标注
权重
(1)否定词
(-1)^times * Ei
(2)程度副词
(Wi 累计) * Ei
长文本情感分析
可以将长文本拆分为多个短文本,然后处理。
条件概率
这里缺少了一个条件概率,不同的前置条件,决定了不同的修饰词正负也是完全不同的。
实现参考
github
python-基于情感词典、k-NN、Bayes、最大熵、SVM的情感极性分析。
中文语料库:包括情感词典 情感分析 文本分类 单轮对话 中文词典 知乎
Jiagu深度学习自然语言处理工具 知识图谱关系抽取 中文分词 词性标注 命名实体识别 情感分析 新词发现 关键词 文本摘要 文本聚类
提供中文分词, 词性标注, 拼写检查,文本转拼音,情感分析,文本摘要,偏旁部首
自然语言处理实验(sougou数据集),TF-IDF,文本分类、聚类、词向量、情感识别、关系抽取等
参考资料
paper-基于LSTM和注意力机制的情感分析服务设计与实现
Stanford NLP学习笔记:7. 情感分析(Sentiment)
| [NLP情感分析 | 流程概述(一)](https://zhuanlan.zhihu.com/p/25065579) |
