语法分析
前儿章讨论过了用符号代替正则表达式的简化机制,这种机制在使用时是很方便的:
digits=[0-9] +
sum=(digits“+") *digits
这些正则表达式定义了28+301+9的和。又如:
digits=[0-9] +
Sum=expr“+"expr
expr="("sum") " | digits
所定义的表达形式如下所示:
(109+23)
61
(1+(250+3))
其中的括号是匹配的。
但这些匹配括号对于有限自动机来说是不可识别的(因为一个只有N个状态的自动机不能记忆长于N的嵌套括号) , 所以sum和expr不是正则表达式。 那么, 词法分析器如何实现像digits这样的正则表达式呢?
解决办法就是在翻译成有限自动机以前,在所有正则表达式出现digits的地方都简单地用右边的式子( [0-9]+ ) 代替。
但这在sum-expr语言中是不可行的, 比如:
expr="("expr"+"expr") " | digits
再用expr的右侧表达式替换expr,如下所示:
expr="("("("expr"+"expr") " | digits) "+"expr") " | digits
现在右边出现expr的次数并没有比以前少, 反而增加了。
因此,简化的概念并没有增强正则表达式的描述能力(因为没有定义附加的语言),除非简化形式是递归的(或者是相互递归的, 如sum和expr) 。
这种递归附加功能正是在语法分析中所需要的。一旦使用了递归简化形式,就不再需要进行迭代.除非是表达式的首部,因为定义:
expr=ab(c|d)e
可以用附加定义重写:
aux=c d
expr=a b aux e
实际上,为了避免使用交替符号,对于同一符号,这里使用了一些辅助扩充:
aux=c
aux=d
expr=a b aux e
不必使用Kleene闭包, 因为可以将:
expr=(abc) *
重写为:
expr=(abc) expr
expr=epolison
剩余的就是非常简单的表示法,叫做上下文无关文法。
正如正则表达式可以用静态声明的方式定义词法结构一样,文法也可以用声明的方式定义语法结构,但需要比有限自动机更强大的方式来分析文法描述的语言。
实际上,虽然正则表达式完全可以实现,甚至可以更好地完成这项工作,但常常使用文法来描述词法记号结构。
上下文无关文法
前两章中曾经介绍过,语言就是一个字符串集,每个字符串是一个字母表中的确定字符序列。
对于语法分析,字符串就是源程序,符号就是词法记号,字母表就是词法分析器返回的记号类型集。
一个上下文无关文法描述了一个语言。一个文法有如下形式的产生式集:
symbol→symbol symbol...symbol
有0个或多于0个的记号在产生式的右边。这些符号要么是终结符,即描述语言中字符串在字母表中的记号;要么是非终结符,即出现在产生式左边的记号。产生式的左边不会出现终结符的记号。最后,还需要使用一个非终结符作为文法的开始符号。
文法 3.1 是一个直线编程的文法示例。开始符号是 S (当开始符号未明确给出时,习惯上认为第一个产生式左边的非终结符为开始符号)。
此例中终结符为:
id print num+:=;
非终结符为:S,E 和 L,该文法语言的一个句子为:
id:=num; id:=id+(id:=num+num, id)
文法 3.1 直线程序的语法
S-> S:S
S-> id := E
S-> print(L)
E-> id
E-> num
E-> E+E
E-> (S, E)
L-> E
L-> L, E
这里,(词法分析前的)源程序可能是:
a:=7;
b:=+(d:=5+6,d)
(终结符的) 记号类型为id, num,=,等等,名字(a,b,c,d)和数字(7,5,6)对应着一些有语义价值的记号
推导
为了说明句子在某一文法语言中,可以进行如下推导:从开始符号出发,对于任一个非终结符,用其产生式的右侧部分进行替换并重复进行这一操作。
如推导3.2所示。
- 推导3.2
S'
S;S'
S';id:=E
id:=E';id:=E
id:=num; id:=E'
id:=num; id:=E+E'
id:=num; id:=E'+(S, E)
id:=num:id:=id+(S',E)
id:=num; id:=id+(id:=E', E)
id:=num; id:=id+(id:=E+E, E')
id:=num; id:=id+(id:=E'+E, id)
id:=num; id:=id+(id:=num+E', id)
id:=num; id:=id+(id:=num+num, id)
对于同一个句子有很多种不同的推导方式。
最左推导不断地对最左边的非终结符号进行替换;最右推导不断地对最右边的非终结符进行替换。
推导3.2既不是最左推导,也不是最右推导。
句中的一个最左推导如下所示:
S'
S': S
id:=E':S
id:=num; S'
id:=num; id:=E'
id:=num; id:=E'+E
分析树
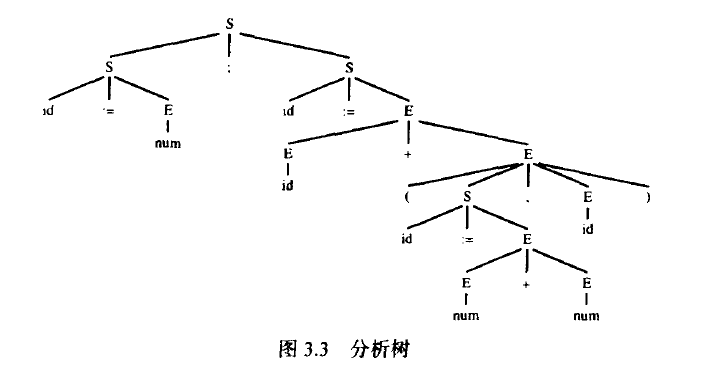
分析树就是将推导式中的每个符号同其派生符号连接而成的,如图3.3所示。
两个不同的推导可能生成同一棵分析树
二义性文法
若一个文法可以用两棵不同的分析树派生出同一个句子,那么该文法就是二义性的。
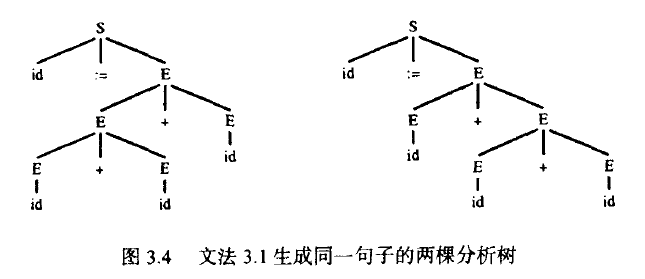
文法3.1就是二义性的,因为句子 id := id+id+id 有两棵分析树(参见图3.4)。
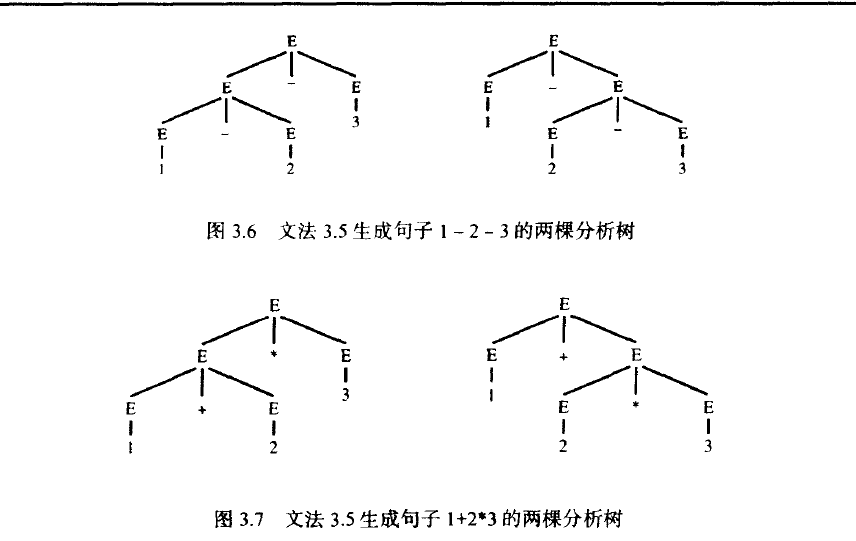
文法3.5也是二义性文法。图3.6为句子1-2-3生成了两棵分析树,图3.7为1+2*3生成了两棵分析树。
显然,若使用分析树来解释表达式的含义,那么生成句子1-2-3的两棵分析树表达了不同的内容:(1-2)-3=-4和1-(2-3)=2。
同样地,(1+2)x3与1+(2x3)也包含了不同的含义实际上,编译器是使用分析树来导出含义的。
- 文法3.5
E→id
E→num
E→E*E
E→E/E
E→E+E
E→E-E
E→(E)
因此,二义性文法对于编译器来说是不确定的文法。
通常,我们总是希望得到非二义性文法。
非二义性文法
不过,可以将二义性文法转换成非二义性文法。
下面考虑如何生成文法3.5中同样语言的非二义性文法。
首先,设*的优先级高于+,然后,设每个操作符是左结合的,那么就得到了(1-2)-3,而不是1-(2~3)。
引人一些新的非终结符号可以得到文法3.8。
- 文法3.8
E→E+T
T→T*F
F→id
E→E-T
T→T/F
F→num
E→T
T→F
F→(E)
符号E,T和F分别代表表达式、项和因子。习惯上,因子用月于乘法,项用于加法。
| 该文法接收与二义性文法同样的字符集,但是现在每个句 | 子都对应一个确定的分析树。 |
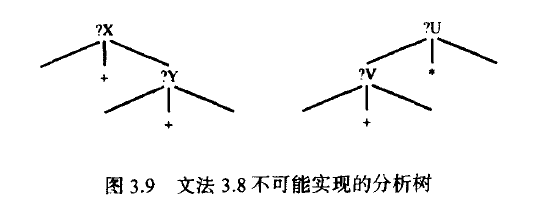
文法3.8不会生成如图3.9所示的分析树(参见习题3.7)。
若要将*号放于左边,产生式可以写为T→F*T。
消除二义性的通常做法是转换文法,虽然这些文法只是在文法上存在二义性,但是它们在编程时也会出现二义性、因为语义上的二义性可能导致编写程序和理解程序上的问题。
文件结束符
分析器不仅要读人像+.-、num这样的终结符,还要读人全文结束符。
通常使用 $ 符号代表全文的结束设S为文法的开始符号。
为了说明 $ 必须出现在完整的一段S文法之后,需要引人一个新的开始符号 S’ 以及一个新的产生式 S’→S$。
在文法 3.8 中,E是开始符号,修改后的文法参见文法3.10.
- 文法3.10
S→E$
E→E+T
E→E-T
E→T
T→T*F
T→T/F
T→F
F→id
F→num
F→(E)
参考资料
《现代编译原理 java》
