题目
给定一个整数 n,求以 1 … n 为节点组成的二叉搜索树有多少种?
输出所有的解法结果。
示例:
Input: n = 3
Output: [[1,null,2,null,3],[1,null,3,2],[2,1,3],[3,1,null,null,2],[3,2,null,1]]
解释:
给定 n = 3, 一共有 5 种不同结构的二叉搜索树:
1 3 3 2 1
\ / / / \ \
3 2 1 1 3 2
/ / \ \
2 1 2 3
解法一:回溯法
常规的回溯思想,就是普通的一个 for 循环,尝试插入 1, 2 … n,然后进入递归,在原来的基础上继续尝试插入 1, 2… n。直到树包含了所有的数字。就是差不多下边这样的框架。
递归{
递归出口;
for(int i = 1;i<=n;i++){
add(i);
进入递归;
remove(i);
}
java 实现
public List<TreeNode> generateTrees(int n) {
List<TreeNode> ans = new ArrayList<TreeNode>();
if (n == 0) {
return ans;
}
TreeNode root = new TreeNode(0); //作为一个哨兵节点
getAns(n, ans, root, 0);
return ans;
}
private void getAns(int n, List<TreeNode> ans, TreeNode root, int count) {
if (count == n) {
//复制当前树并且加到结果中
TreeNode newRoot = treeCopy(root);
ans.add(newRoot.right);
return;
}
TreeNode root_copy = root;
//尝试插入每个数
for (int i = 1; i <= n; i++) {
root = root_copy;
//寻找要插入的位置
while (root != null) {
//在左子树中插入
if (i < root.val) {
//到了最左边
if (root.left==null) {
//插入当前数字
root.left = new TreeNode(i);
//进入递归
getAns(n, ans, root_copy, count + 1);
//还原为 null,尝试插入下个数字
root.left = null;
break;
}
root = root.left;
//在右子树中插入
} else if (i > root.val){
//到了最右边
if (root.right == null){
//插入当前数字
root.right = new TreeNode(i);
//进入递归
getAns(n, ans, root_copy, count + 1);
//还原为 null,尝试插入下个数字
root.right = null;
break;
}
root = root.right;
//如果找到了相等的数字,就结束,尝试下一个数字
} else {
break;
}
}
}
}
重复解的问题
然而,理想很美丽,现实很骨感,出错了,就是回溯经常遇到的问题,出现了重复解。
//第一种情况
第一次循环添加 2
2
第二次循环添加 1
2
/
1
第三次循环添加 3
2
/ \
1 3
//第二种情况
第一次循环添加 2
2
第二次循环添加 3
2
\
3
第三次循环添加 1
2
/ \
1 3
是的,因为每次循环都尝试了所有数字,所以造成了重复。
解法二 递归
我们可以利用一下查找二叉树的性质。
分析
左子树的所有值小于根节点,右子树的所有值大于根节点。
所以如果求 1…n 的所有可能。
我们只需要把 1 作为根节点,[ ] 空作为左子树,[ 2 … n ] 的所有可能作为右子树。
2 作为根节点,[ 1 ] 作为左子树,[ 3…n ] 的所有可能作为右子树。
3 作为根节点,[ 1 2 ] 的所有可能作为左子树,[ 4 … n ] 的所有可能作为右子树,然后左子树和右子树两两组合。
4 作为根节点,[ 1 2 3 ] 的所有可能作为左子树,[ 5 … n ] 的所有可能作为右子树,然后左子树和右子树两两组合。
…
n 作为根节点,[ 1… n ] 的所有可能作为左子树,[ ] 作为右子树。
至于,[ 2 … n ] 的所有可能以及 [ 4 … n ] 以及其他情况的所有可能,可以利用上边的方法,把每个数字作为根节点,然后把所有可能的左子树和右子树组合起来即可。
如果只有一个数字,那么所有可能就是一种情况,把该数字作为一棵树。而如果是 [ ],那就返回 null。
实现
/**
* 1 <= n <= 8
* @param n 整数
* @return 结果
*/
public List<TreeNode> generateTrees(int n) {
List<TreeNode> ans = new ArrayList<>();
return getList(1, n);
}
private List<TreeNode> getList(int start, int end) {
List<TreeNode> results = new ArrayList<>();
//此时没有数字,将 null 加入结果中
if(start > end) {
results.add(null);
return results;
}
//只有一个数字,当前数字作为一棵树加入结果中
if(start == end) {
TreeNode treeNode = new TreeNode(start);
results.add(treeNode);
return results;
}
// 遍历所有的可能
for(int i = start; i <= end; i++) {
// 所有的左子树
List<TreeNode> lefts = getList(start, i-1);
// 所有的右子树
List<TreeNode> rights = getList(i+1, end);
// 整合为一棵树
for(TreeNode left : lefts) {
for(TreeNode right : rights) {
TreeNode root = new TreeNode(i);
root.left = left;
root.right = right;
results.add(root);
}
}
}
return results;
}
效果:
Runtime: 1 ms, faster than 93.81% of Java online submissions for Unique Binary Search Trees II.
Memory Usage: 39.2 MB, less than 88.47% of Java online submissions for Unique Binary Search Trees II.
解法三 动态规划
大多数递归都可以用动态规划的思想重写,这道也不例外。
例子
举个例子,n = 3
数字个数是 0 的所有解
null
数字个数是 1 的所有解
1
2
3
数字个数是 2 的所有解,我们只需要考虑连续数字
[ 1 2 ]
1
\
2
2
/
1
[ 2 3 ]
2
\
3
3
/
2
如果求 3 个数字的所有情况。
[ 1 2 3 ]
利用解法二递归的思路,就是分别把每个数字作为根节点,然后考虑左子树和右子树的可能
1 作为根节点,左子树是 [] 的所有可能,右子树是 [ 2 3 ] 的所有可能,利用之前求出的结果进行组合。
1
/ \
null 2
\
3
1
/ \
null 3
/
2
2 作为根节点,左子树是 [ 1 ] 的所有可能,右子树是 [ 3 ] 的所有可能,利用之前求出的结果进行组合。
2
/ \
1 3
3 作为根节点,左子树是 [ 1 2 ] 的所有可能,右子树是 [] 的所有可能,利用之前求出的结果进行组合。
3
/ \
1 null
\
2
3
/ \
2 null
/
1
然后利用上边的思路基本上可以写代码了,就是求出长度为 1 的所有可能,长度为 2 的所有可能 … 直到 n。
但是我们注意到,求长度为 2 的所有可能的时候,我们需要求 [ 1 2 ] 的所有可能,[ 2 3 ] 的所有可能,这只是 n = 3 的情况。如果 n 等于 100,我们需要求的更多了 [ 1 2 ] , [ 2 3 ] , [ 3 4 ] … [ 99 100 ] 太多了。
优化思路
能不能优化呢?
仔细观察,我们可以发现长度是为 2 的所有可能其实只有两种结构。
x
/
y
y
\
x
看之前推导的 [ 1 2 ] 和 [ 2 3 ],只是数字不一样,结构是完全一样的。
[ 1 2 ]
1
\
2
2
/
1
[ 2 3 ]
2
\
3
3
/
2
所以我们 n = 100 的时候,求长度是 2 的所有情况的时候,我们没必要把 [ 1 2 ] , [ 2 3 ] , [ 3 4 ] … [ 99 100 ] 所有的情况都求出来,只需要求出 [ 1 2 ] 的所有情况即可。
推广到任意长度 len,我们其实只需要求 [ 1 2 … len ] 的所有情况就可以了。下一个问题随之而来,这些 [ 2 3 ] , [ 3 4 ] … [ 99 100 ] 没求的怎么办呢?
举个例子。n = 100,此时我们求把 98 作为根节点的所有情况,根据之前的推导,我们需要长度是 97 的 [ 1 2 … 97 ] 的所有情况作为左子树,长度是 2 的 [ 99 100 ] 的所有情况作为右子树。
[ 1 2 … 97 ] 的所有情况刚好是 [ 1 2 … len ] ,已经求出来了。但 [ 99 100 ] 怎么办呢?我们只求了 [ 1 2 ] 的所有情况。答案很明显了,在 [ 1 2 ] 的所有情况每个数字加一个偏差 98,即加上根节点的值就可以了。
[ 1 2 ]
1
\
2
2
/
1
[ 99 100 ]
1 + 98
\
2 + 98
2 + 98
/
1 + 98
即
99
\
100
100
/
99
所以我们需要一个函数,实现树的复制并且加上偏差。
private TreeNode clone(TreeNode n, int offset) {
if (n == null) {
return null;
}
TreeNode node = new TreeNode(n.val + offset);
node.left = clone(n.left, offset);
node.right = clone(n.right, offset);
return node;
}
通过上边的所有分析,代码可以写了,总体思想就是求长度为 2 的所有情况,求长度为 3 的所有情况直到 n。而求长度为 len 的所有情况,我们只需要求出一个代表 [ 1 2 … len ] 的所有情况,其他的话加上一个偏差,加上当前根节点即可。
java 实现
public List<TreeNode> generateTrees(int n) {
ArrayList<TreeNode>[] dp = new ArrayList[n + 1];
dp[0] = new ArrayList<TreeNode>();
if (n == 0) {
return dp[0];
}
dp[0].add(null);
//长度为 1 到 n
for (int len = 1; len <= n; len++) {
dp[len] = new ArrayList<TreeNode>();
//将不同的数字作为根节点,只需要考虑到 len
for (int root = 1; root <= len; root++) {
int left = root - 1; //左子树的长度
int right = len - root; //右子树的长度
for (TreeNode leftTree : dp[left]) {
for (TreeNode rightTree : dp[right]) {
TreeNode treeRoot = new TreeNode(root);
treeRoot.left = leftTree;
//克隆右子树并且加上偏差
treeRoot.right = clone(rightTree, root);
dp[len].add(treeRoot);
}
}
}
}
return dp[n];
}
private TreeNode clone(TreeNode n, int offset) {
if (n == null) {
return null;
}
TreeNode node = new TreeNode(n.val + offset);
node.left = clone(n.left, offset);
node.right = clone(n.right, offset);
return node;
}
效果:
Runtime: 1 ms, faster than 93.81% of Java online submissions for Unique Binary Search Trees II.
Memory Usage: 39.3 MB, less than 83.50% of Java online submissions for Unique Binary Search Trees II.
值得注意的是,所有的左子树我们没有 clone ,也就是很多子树被共享了,在内存中就会是下边的样子。
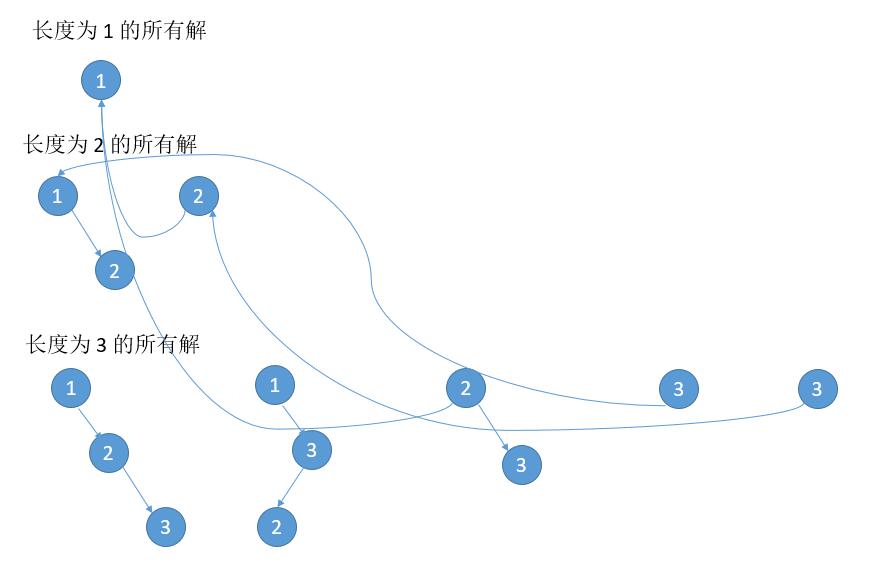
也就是左子树用的都是之前的子树,没有开辟新的空间。
解法四 动态规划 2
解法三的动态规划完全是模仿了解法二递归的思想,这里再介绍另一种思想,会更好理解一些。
例子
考虑 [] 的所有解
null
考虑 [ 1 ] 的所有解
1
考虑 [ 1 2 ] 的所有解
2
/
1
1
\
2
考虑 [ 1 2 3 ] 的所有解
3
/
2
/
1
2
/ \
1 3
3
/
1
\
2
1
\
3
/
2
1
\
2
\
3
仔细分析,可以发现一个规律。
首先我们每次新增加的数字大于之前的所有数字,所以新增加的数字出现的位置只可能是根节点或者是根节点的右孩子,右孩子的右孩子,右孩子的右孩子的右孩子等等,总之一定是右边。
其次,新数字所在位置原来的子树,改为当前插入数字的左孩子即可,因为插入数字是最大的。
对于下边的解
2
/
1
然后增加 3
1.把 3 放到根节点
3
/
2
/
1
2. 把 3 放到根节点的右孩子
2
/ \
1 3
对于下边的解
1
\
2
然后增加 3
1.把 3 放到根节点
3
/
1
\
2
2. 把 3 放到根节点的右孩子,原来的子树作为 3 的左孩子
1
\
3
/
2
3. 把 3 放到根节点的右孩子的右孩子
1
\
2
\
3
以上就是根据 [ 1 2 ] 推出 [ 1 2 3 ] 的所有过程,可以写代码了。
由于求当前的所有解只需要上一次的解,所有我们只需要两个 list,pre 保存上一次的所有解, cur 计算当前的所有解。
public List<TreeNode> generateTrees(int n) {
List<TreeNode> pre = new ArrayList<TreeNode>();
if (n == 0) {
return pre;
}
pre.add(null);
//每次增加一个数字
for (int i = 1; i <= n; i++) {
List<TreeNode> cur = new ArrayList<TreeNode>();
//遍历之前的所有解
for (TreeNode root : pre) {
//插入到根节点
TreeNode insert = new TreeNode(i);
insert.left = root;
cur.add(insert);
//插入到右孩子,右孩子的右孩子...最多找 n 次孩子
for (int j = 0; j <= n; j++) {
TreeNode root_copy = treeCopy(root); //复制当前的树
TreeNode right = root_copy; //找到要插入右孩子的位置
int k = 0;
//遍历 j 次找右孩子
for (; k < j; k++) {
if (right == null)
break;
right = right.right;
}
//到达 null 提前结束
if (right == null)
break;
//保存当前右孩子的位置的子树作为插入节点的左孩子
TreeNode rightTree = right.right;
insert = new TreeNode(i);
right.right = insert; //右孩子是插入的节点
insert.left = rightTree; //插入节点的左孩子更新为插入位置之前的子树
//加入结果中
cur.add(root_copy);
}
}
pre = cur;
}
return pre;
}
private TreeNode treeCopy(TreeNode root) {
if (root == null) {
return root;
}
TreeNode newRoot = new TreeNode(root.val);
newRoot.left = treeCopy(root.left);
newRoot.right = treeCopy(root.right);
return newRoot;
}
