拓展阅读
从零开始手写 mybatis (三)jdbc pool 如何从零手写实现数据库连接池 dbcp?
万字长文深入浅出数据库连接池 HikariCP/Commons DBCP/Tomcat/c3p0/druid 对比
Database Connection Pool 数据库连接池概览
Apache Tomcat DBCP(Database Connection Pool) 数据库连接池-01-入门介绍
vibur-dbcp 并发、快速且功能完备的 JDBC 连接池,提供先进的性能监控功能-01-入门介绍
拓展阅读
锁专题(13)使用 @sun.misc.Contended 避免伪共享
5.1 基本概念
几乎所有的程序都有某种CPU运算和等待某种I/O的交替周期。(即使是简单的从内存中读取数据相对于CPU速度而言也需要很长时间。)
在运行单个进程的简单系统中,等待I/O的时间被浪费了,那些CPU周期被永远地丢失了。
调度系统允许一个进程在另一个进程等待I/O时使用CPU,从而充分利用了本来会丢失的CPU周期。
挑战在于使整个系统在变化的并且通常是动态的条件下尽可能“高效”和“公平”,而“高效”和“公平”是一些主观的术语,通常受到不断变化的优先级政策的影响。
5.1.1 CPU-I/O 轮换周期
几乎所有的进程在一个连续的周期中交替两种状态,如下图所示:
执行计算的CPU突发,和
等待数据传输进入或离开系统的I/O突发。
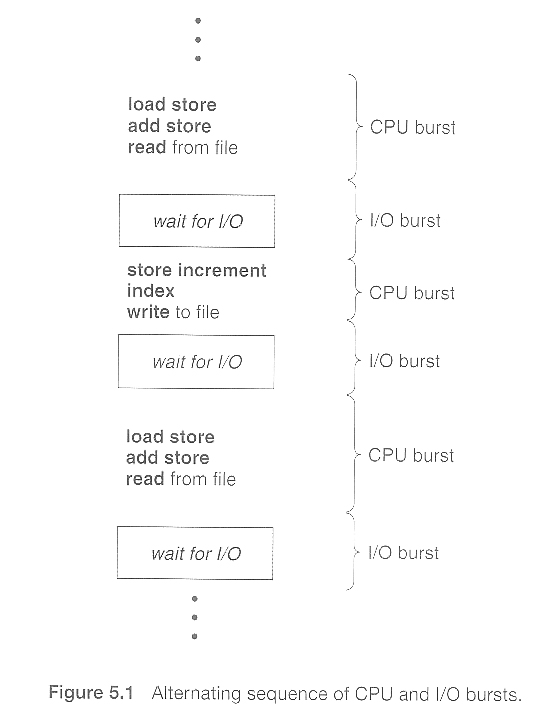
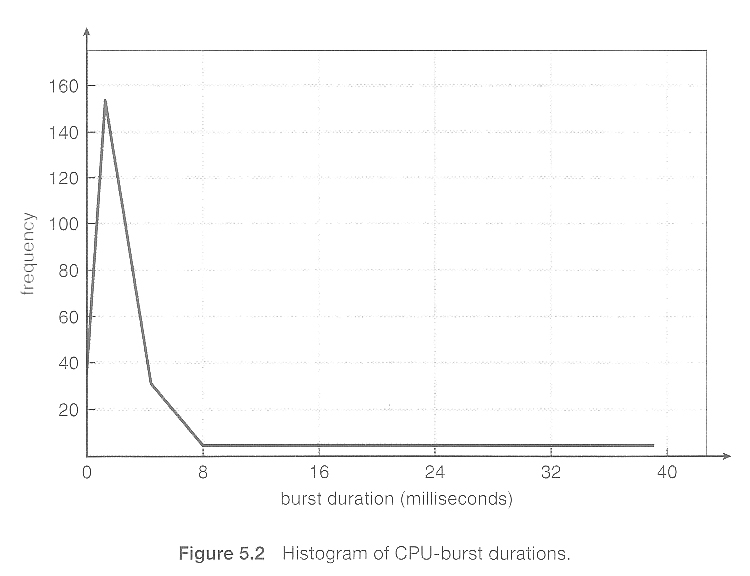
CPU突发的持续时间会因进程和程序的不同而有所变化,但广泛的研究显示了类似于图 5.2 中所示的频率模式:
5.1.2 CPU调度器
每当CPU变为空闲时,CPU调度器(也称为短期调度器)的工作就是从就绪队列中选择另一个进程来运行。
就绪队列的存储结构和选择下一个进程的算法不一定是一个先进先出队列。有几种备选方案可供选择,以及每种算法的许多可调参数,这是整个本章的基本主题。
5.1.3 抢占式调度
CPU调度决策发生在以下四种情况下:
-
当一个进程从运行状态切换到等待状态时,例如等待I/O请求或调用wait()系统调用。
-
当一个进程从运行状态切换到就绪状态,例如响应中断。
-
当一个进程从等待状态切换到就绪状态时,比如I/O完成或从wait()返回。
-
当一个进程终止时。
对于条件1和4,没有选择 - 必须选择一个新的进程。 对于条件2和3,有一个选择 - 要么继续运行当前进程,要么选择另一个进程。 如果调度仅在条件1和4下进行,则系统称为非抢占式或协作式。在这些条件下,一旦一个进程开始运行,它就会一直运行,直到它自愿阻塞或完成。否则,系统就被认为是抢占式的。 Windows在Windows 3.x之前使用了非抢占式调度,在Win95开始使用了抢占式调度。Macs在OSX之前使用了非抢占式调度,从那时起开始使用了抢占式调度。请注意,只有支持定时器中断的硬件才能实现抢占式调度。 请注意,当两个进程共享数据时,抢占式调度可能会导致问题,因为一个进程可能在更新共享数据结构的中间被中断。第6章将更详细地讨论这个问题。 如果内核正在忙于执行系统调用(例如更新关键内核数据结构)时发生抢占,抢占也可能是一个问题。大多数现代UNIX系统通过让进程等待系统调用完成或阻塞后才允许抢占来解决这个问题。不幸的是,对于实时系统来说,这个解决方案是有问题的,因为无法再保证实时响应。 一些关键代码的临界区通过在进入临界区之前禁用中断,并在退出临界区时重新启用中断来保护自己免受并发问题的影响。不用说,这应该只在罕见的情况下,并且只在将很快完成的非常短的代码中进行(通常只有几条机器指令)。
5.1.4 调度程序
调度程序是将CPU的控制权交给调度器选择的进程的模块。
这个功能涉及到:
-
切换上下文。
-
切换到用户模式。
-
跳转到新加载程序的适当位置。
-
调度程序需要尽可能快,因为它在每次上下文切换时都会运行。调度程序消耗的时间称为调度延迟。
5.2 调度标准
在尝试为特定情况和环境选择“最佳”调度算法时,有几个不同的标准需要考虑,包括:
CPU 利用率 - 理想情况下,CPU 应该在 100% 的时间内忙碌,以便浪费 0 个 CPU 周期。在实际系统中,CPU 使用率应该在 40%(轻负载)到 90%(重负载)之间。
吞吐量 - 单位时间内完成的进程数量。根据特定的进程,可能范围从每秒 10 个到每小时 1 个。
周转时间 - 从提交时间到完成时间所需的特定进程完成时间。(挂钟时间。)
等待时间 - 进程在准备队列中等待轮到CPU的时间。
(负载平均值 - 准备队列中等待轮到CPU的进程的平均数量。通过“uptime”和“who”报告的 1 分钟、5 分钟和 15 分钟的平均值。) 响应时间 - 交互式程序中从发出命令到开始响应该命令所需的时间。
通常,我们希望优化标准的平均值(最大化 CPU 利用率和吞吐量,并最小化其他所有标准)。
然而,有时我们希望做一些不同的事情,比如最小化最大响应时间。
有时,最希望最小化标准的方差而不是实际值。也就是说,用户更愿意接受一个一致可预测的系统,而不是一个不一致的系统,即使它稍微慢一点。
5.3 调度算法
以下小节将解释几种常见的调度策略,仅针对一小部分进程的单个 CPU 突发。
显然,实际系统必须处理更多同时执行其 CPU-I/O 突发周期的进程。
5.3.1 先来先服务调度,FCFS
FCFS 非常简单 - 就像顾客在银行、邮局或复印机前排队等待一样,只是一个先进先出的队列。
然而,不幸的是,FCFS 可能会导致一些非常长的平均等待时间,特别是如果第一个到达的进程花费了很长时间。
例如,考虑以下三个进程:
Process Burst Time
P1 24
P2 3
P3 3
在下面的第一个甘特图中,进程 P1 首先到达。这三个进程的平均等待时间是(0 + 24 + 27)/ 3 = 17.0 毫秒。
在下面的第二个甘特图中,相同的三个进程的平均等待时间为(0 + 3 + 6)/ 3 = 3.0 毫秒。这三个突发的总运行时间相同,但在第二种情况下,其中两个进程完成得更快,另一个进程只延迟了很短的时间。
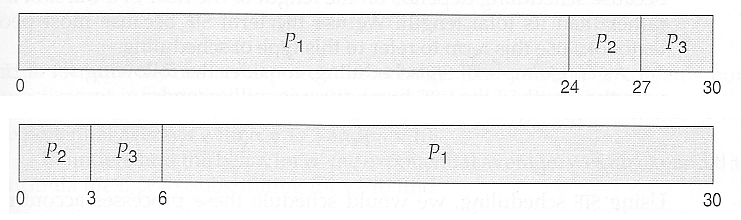
FCFS 还可以以另一种方式阻塞系统,在繁忙的动态系统中,这种方式被称为车队效应。
当一个 CPU 密集型进程阻塞了 CPU 时,一些 I/O 密集型进程可能会在其后面排队,导致 I/O 设备处于空闲状态。
当 CPU 负载最终释放 CPU 时,I/O 进程通过 CPU 速度很快,而 CPU 则空闲下来,所有人都排队等待 I/O,然后当 CPU 密集型进程回到准备队列时,该循环重复。
5.3.2 最短作业优先调度,SJF
SJF 算法的思想是选择最快的小作业先完成,然后选择下一个最小的快速作业。
(从技术上讲,该算法根据下一个最短的 CPU 突发选择进程,而不是整个进程时间。)
例如,下面的甘特图是基于以下 CPU 突发时间(以及所有作业同时到达的假设)。
Process Burst Time
P1 6
P2 8
P3 7
P4 3

在上面的情况中,平均等待时间为(0 + 3 + 9 + 16)/ 4 = 7.0 毫秒(而对于相同的进程,FCFS 的平均等待时间为 10.25 毫秒)。
SJF 被证明是最快的调度算法,但它遇到了一个重要的问题:你怎么知道下一个 CPU 突发将持续多长时间?
对于长期的批处理作业,可以根据用户提交作业时设置的限制来完成,这鼓励他们设置较低的限制,但如果他们将限制设置得太低,就会有重新提交作业的风险。然而,这对交互式系统的短期 CPU 调度并不适用。
另一种选择是统计测量作业的运行时间特性,特别是如果相同的任务反复运行且可预测。但再次强调,在现实世界中,这真的不是短期 CPU 调度的可行选择。
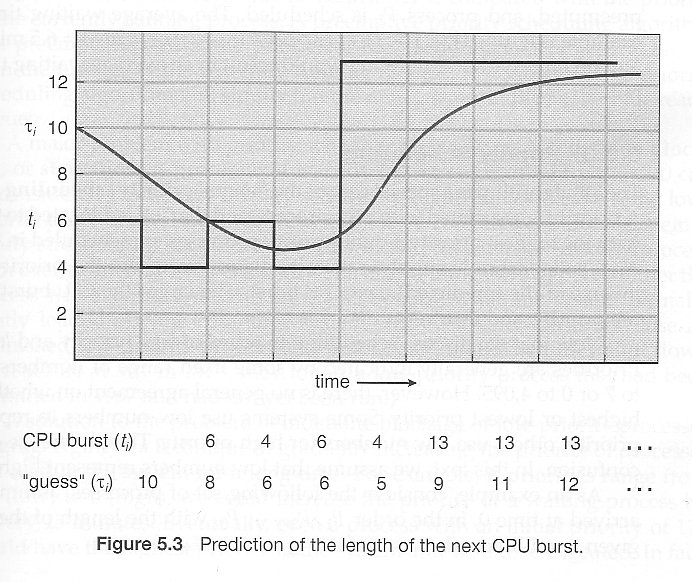
一个更实用的方法是根据进程最近突发时间的历史测量来预测下一个突发的长度。一种简单、快速和相对准确的方法是指数平均法,可以定义如下。(该书使用 tau 和 t 作为变量,但这些变量很难区分,并且在 HTML 中效果不佳。)
估计值[ i + 1 ] = alpha * 突发[ i ] + (1.0 - alpha)* 估计值[ i ]
在这种方案中,先前的估计值包含所有以前的时间历史,alpha 作为相对于过去历史的最近数据的权重因子。
如果 alpha 是 1.0,那么过去的历史将被忽略,我们假设下一个突发将与上一个突发持续相同的时间。
如果 alpha 是 0.0,那么所有测量的突发时间都将被忽略,我们只是假设一个恒定的突发时间。
通常 alpha 设置为 0.5,如图 5.3 所示:
SJF 可以是抢占式的或非抢占式的。当一个新的进程到达准备队列,其预测的突发时间比当前正在 CPU 上运行的进程剩余的时间短时,就会发生抢占。抢占式的 SJF 有时被称为最短剩余时间优先调度。
例如,下面的甘特图基于以下数据:
Process Arrival Time Burst Time
P1 0 8
P2 1 4
P3 2 9
p4 3 5

在这种情况下,平均等待时间为 ((5 - 3) + (10 - 1) + (17 - 2)) / 4 = 26 / 4 = 6.5 毫秒(与非抢占式 SJF 的 7.75 毫秒或 FCFS 的 8.75 毫秒相比)。
5.3.3 优先级调度
优先级调度是 SJF 的更一般情况,其中每个作业被分配一个优先级,并且具有最高优先级的作业首先被调度。
(SJF 使用下一个预期突发时间的倒数作为其优先级 - 预期突发时间越小,优先级越高。)
请注意,在实践中,优先级使用固定范围内的整数实现,但关于“高”优先级是否使用大数或小数没有达成一致的惯例。
该书使用较低的数字表示较高的优先级,其中 0 表示最高优先级。
例如,下面的甘特图基于这些进程突发时间和优先级,并产生了平均等待时间为 8.2 毫秒:
Process Burst Time Priority
P1 10 3
P2 1 1
P3 2 4
P4 1 5
P5 5 2

优先级可以通过内部或外部分配。内部优先级由操作系统使用诸如平均突发时间、CPU 到 I/O 活动比率、系统资源使用情况等标准进行分配。
外部优先级由用户分配,基于作业的重要性、支付的费用、政治等因素。
优先级调度可以是抢占式的或非抢占式的。
优先级调度可能会遇到一个重大问题,称为无限阻塞或饥饿,在这种情况下,低优先级任务可能永远等待,因为总是有其他优先级更高的作业存在。
如果允许发生这个问题,那么进程将在系统负载减轻时(比如凌晨 2 点)运行,或者最终在系统关闭或崩溃时丢失(有传言说有些作业已经卡了几年)。
解决这个问题的一种常见方法是老化(aging),在这种方案下,作业等待的时间越长,其优先级就越高。在这种方案下,低优先级的作业最终会将其优先级提高到足以运行的程度。
5.3.4 循环调度(Round Robin Scheduling)
循环调度类似于 FCFS 调度,但 CPU 突发被分配了称为时间片的限制。
当一个进程获得 CPU 时,一个计时器被设置为时间片的值。
如果进程在时间片计时器到期之前完成其突发,则它会像普通的 FCFS 算法一样被换出 CPU。
如果计时器先到期,则进程被换出 CPU 并移到准备队列的末尾。
准备队列被维护为循环队列,因此当所有进程都轮流一遍后,调度器会给第一个进程再次轮流,依此类推。
RR 调度可以产生所有处理器平均共享 CPU 的效果,尽管平均等待时间可能比其他调度算法长。
在下面的例子中,平均等待时间为 5.66 毫秒。
Process Burst Time
P1 24
P2 3
P3 3

RR 的性能对所选择的时间片敏感。
如果时间片足够大,那么 RR 就变成了 FCFS 算法;如果时间片非常小,那么每个进程将获得处理器时间的 1/n,并平均共享 CPU。
但是,真实系统在每次上下文切换时都会产生开销,而时间片越小,上下文切换就越频繁(见下图5.4)。
大多数现代系统使用的时间片在10到100毫秒之间,上下文切换的时间在10微秒左右,因此相对于时间片来说,开销很小。
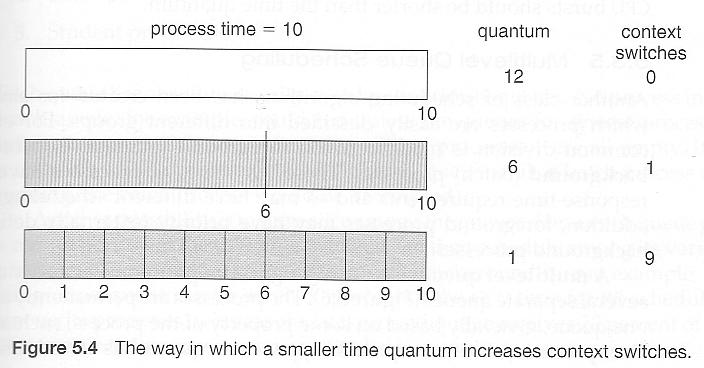
转换时间也随着时间片的变化而变化,但方式并不明显。
例如,考虑以下图中显示的进程:
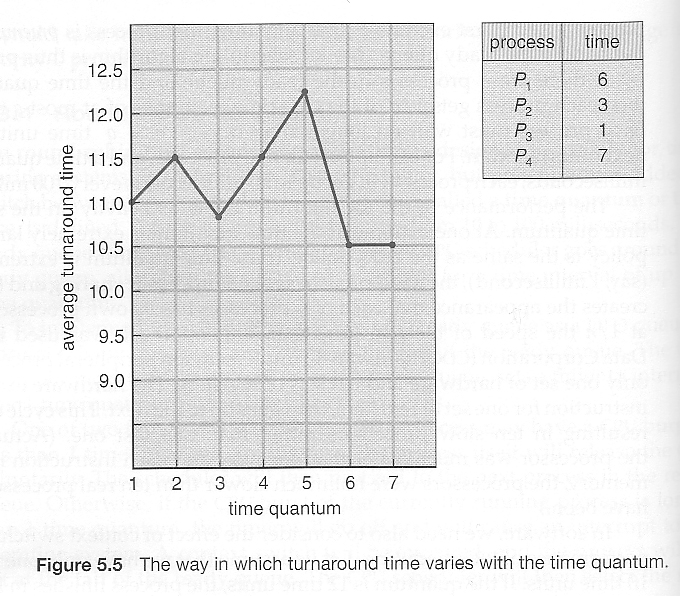
一般来说,如果大多数进程在一个时间片内完成它们的下一个 CPU 突发,那么周转时间会最小化。例如,对于三个每个都有10毫秒突发的进程,使用1毫秒时间片的平均周转时间为29,而使用10毫秒时间片则减少到20。然而,如果时间片过大,那么RR就会退化为FCFS。一个经验法则是,80% 的 CPU 突发应该小于时间片。
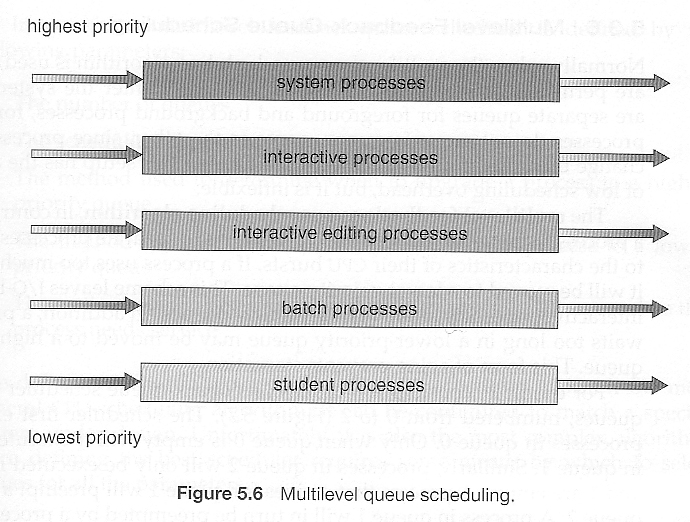
5.3.5 多级队列调度
当进程可以轻松分类时,可以建立多个独立的队列,每个队列都实施适合该类型作业的调度算法,和/或使用不同的参数调整。
还必须在队列之间进行调度,即调度一个队列相对于其他队列的时间。
两种常见的选项是严格优先级(较低优先级队列中没有作业运行,直到所有较高优先级队列都为空)和循环(每个队列依次获得时间片,可能大小不同)。
请注意,在这种算法下,作业不能从一个队列切换到另一个队列 - 一旦它们分配到一个队列,那就是它们的队列,直到完成。
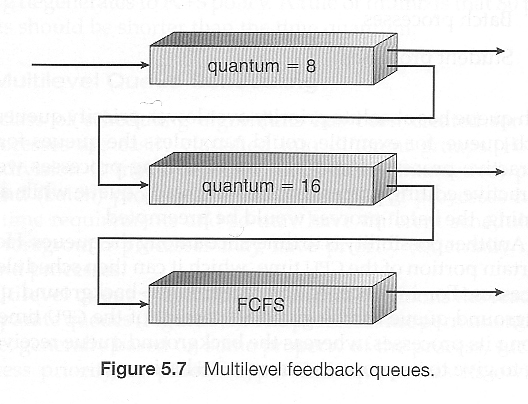
多级反馈队列调度与上述普通的多级队列调度类似,不同之处在于作业可能因各种原因从一个队列移动到另一个队列:
- 如果作业的特征在 CPU 密集型和 I/O 密集型之间发生变化,那么将作业从一个队列切换到另一个队列可能是适当的。
- 可以纳入老化机制,这样等待时间较长的作业可以暂时提升到更高优先级的队列中。 多级反馈队列调度是最灵活的,因为它可以针对任何情况进行调整。但由于可调参数的存在,它也是最复杂的实现。其中一些定义这种系统的参数包括:
- 队列的数量。
- 每个队列的调度算法。
- 用于将进程从一个队列提升或降级到另一个队列的方法(可能不同)。
- 用于确定进程最初进入哪个队列的方法。
5.4 线程调度
进程调度器仅调度内核线程。
用户线程由线程库映射到内核线程 - 操作系统(特别是调度器)对它们不知情。
5.4.1 竞争范围
竞争范围指的是线程竞争物理 CPU 使用的范围。
在实现多对一和多对多线程的系统中,存在进程竞争范围(Process Contention Scope,PCS),因为线程在同一个进程中竞争。这是在单个内核线程上管理/调度多个用户线程的线程库的工作。 系统竞争范围(System Contention Scope,SCS)涉及系统调度器调度内核线程在一个或多个 CPU 上运行。
实现一对一线程的系统(如 XP、Solaris 9、Linux)仅使用 SCS。
PCS 调度通常采用优先级,程序员可以设置和/或更改其程序创建的线程的优先级。即使在相同优先级的线程之间,也不能保证时间切片均匀。
5.4.2 Pthread 调度
Pthread 库支持指定范围竞争:
- PTHREAD_SCOPE_PROCESS 使用 PCS 进行线程调度,通过使用多对多模型将用户线程调度到可用的 LWPs。
- PTHREAD_SCOPE_SYSTEM 使用 SCS 进行线程调度,通过将用户线程绑定到特定的 LWPs,有效地实现一对一模型。 getscope 和 setscope 方法用于分别确定和设置范围竞争:
#include <pthread.h>
#include <stdio.h>
#define NUM_THREADS 5
int main(int argc, char *argv[]) {
int i, scope;
pthread_t tid[NUM_THREADS];
pthread_attr_t attr;
/* get the default attributes */
pthread_attr_init(&attr);
/* first inquire on the current scope */
if (pthread_attr_getscope(&attr, &scope) != 0)
fprintf(stderr, "Unable to get scheduling scope\n");
else {
if (scope == PTHREAD_SCOPE_PROCESS)
printf("PTHREAD_SCOPE_PROCESS");
else if (scope == PTHREAD_SCOPE_SYSTEM)
printf("PTHREAD_SCOPE_SYSTEM");
else
fprintf(stderr, "Illegal scope value.\n");
/* set the scheduling algorithm to PCS or SCS */
pthread_attr_setscope(&attr, PTHREAD_SCOPE_SYSTEM);
/* create the threads */
for (i = 0; i < NUM_THREADS; i++)
pthread_create(&tid[i], &attr, runner, NULL);
/* now join on each thread */
for (i = 0; i < NUM_THREADS; i++)
pthread_join(tid[i], NULL);
}
/* Each thread will begin control in this function */
void *runner(void *param) {
/* do some work */
pthread_exit(0);
}
}
5.5 多处理器调度
当有多个处理器可用时,调度变得更加复杂,因为现在需要让多个 CPU 保持忙碌并有效利用所有时间。
负载平衡涉及在多个处理器之间平衡负载。
多处理器系统可以是异构的(不同类型的 CPU),也可以是同构的(所有 CPU 都是相同类型)。即使在后一种情况下,也可能存在特殊的调度约束,例如通过专用总线连接到其中一个 CPU 的设备。本书将限制其讨论范围在同构系统上。
5.5.1 多处理器调度方法
一种多处理器调度方法是非对称多处理,其中一个处理器是主处理器,控制所有活动并运行所有内核代码,而另一个仅运行用户代码。这种方法相对简单,因为不需要共享关键系统数据。 另一种方法是对称多处理(SMP),其中每个处理器调度自己的作业,从一个公共就绪队列或每个处理器的单独就绪队列中选择。 几乎所有现代操作系统都支持 SMP,包括 XP、Win 2000、Solaris、Linux 和 Mac OSX。
5.5.2 处理器亲和性
处理器包含高速缓存内存,可以加速对相同内存位置的重复访问。
如果一个进程在每次获取时间片时都从一个处理器切换到另一个处理器,那么缓存中的数据(对于该进程)将被作废,并需要从主存中重新加载,从而抵消了缓存的好处。
因此,SMP 系统通过处理器亲和性试图保持进程在同一个处理器上。软亲和性发生在系统试图保持进程在同一个处理器上但不提供任何保证时。Linux 和一些其他操作系统支持硬亲和性,其中一个进程指定不在处理器之间移动。
主存储器架构也可能影响进程亲和性,如果特定的 CPU 对同一芯片或板上的内存具有更快的访问速度,而不是其他地方加载的内存(非均匀存储器访问,NUMA)。
如下所示,如果进程对特定 CPU 有亲和性,那么它应优先分配“本地”快速访问区域的内存存储。
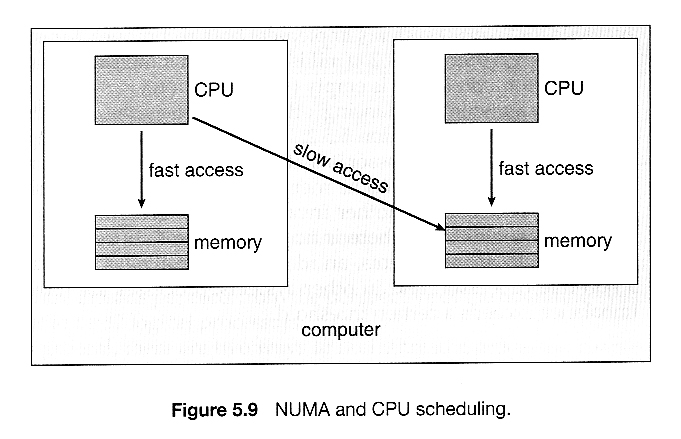
5.5.3 负载平衡
显然,多处理器系统中的一个重要目标是平衡处理器之间的负载,以防止一个处理器处于空闲状态,而另一个处理器过载。
使用共享就绪队列的系统自然是自平衡的,不需要任何特殊处理。然而,大多数系统维护每个处理器的单独就绪队列。
平衡可以通过推送迁移或拉取迁移来实现:
推送迁移涉及一个单独的进程定期运行(例如每200毫秒),并将进程从负载较重的处理器移动到负载较轻的处理器上。
拉取迁移涉及空闲处理器从其他处理器的就绪队列中获取进程。
推送迁移和拉取迁移不是互斥的。
请注意,为了实现负载平衡而将进程从处理器迁移到处理器,这与处理器亲和性的原则相抵触,如果不谨慎管理,通过平衡系统获得的节省可能会在重建缓存时丧失。一种选择是仅在不平衡超过给定阈值时允许 迁移。
5.5.4 多核处理器
传统 SMP 需要多个 CPU 芯片才能同时运行多个内核线程。
最近的趋势是将多个 CPU(核心)集成到单个芯片上,这对系统来说就像多个处理器一样。
每当所需数据不在缓存中时,计算周期都会受到访问内存所需的时间阻塞(缓存未命中)。
在图5.10中,多达一半的 CPU 周期都会丢失到内存停滞中。
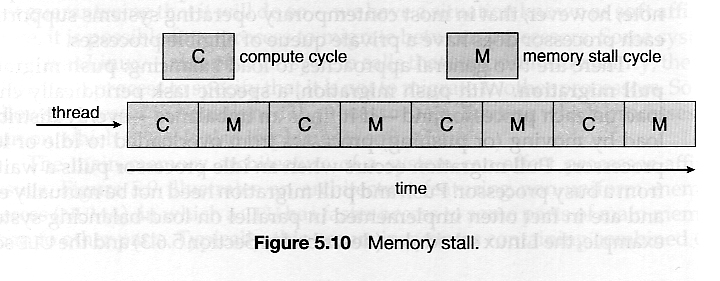
通过将多个内核线程分配给单个处理器,可以通过在处理器上运行一个线程,而另一个线程等待内存来避免(或减少)内存停顿。
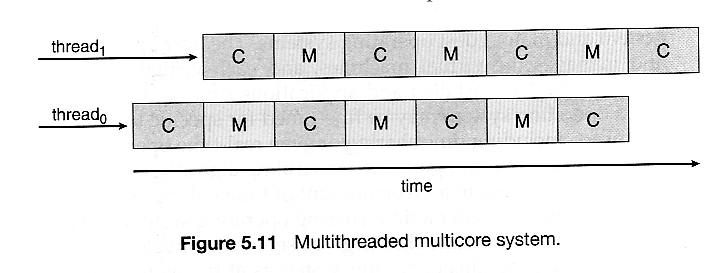
双线程双核系统具有四个逻辑处理器可供操作系统使用。UltraSPARC T1 CPU每个芯片有8个核心和每个核心4个硬件线程,总共每个芯片有32个逻辑处理器。
多线程处理器有两种方式:
1) 粗粒度多线程在一个线程阻塞时(例如在内存读取时)才会切换线程。上下文切换类似于进程切换,具有相当大的开销。
2) 细粒度多线程在较小的常规间隔上发生,例如在指令周期边界上。然而,该架构设计支持线程切换,因此开销相对较小。
值得注意的是,对于多线程多核系统,存在两个级别的调度,即在内核级别:
1) 操作系统调度哪些内核线程分配给哪些逻辑处理器,并在何时进行上下文切换,使用如上所述的算法。
2) 在较低级别,硬件使用其他算法调度每个物理核心上的逻辑处理器。
UltraSPARC T1使用简单的循环调度方法来调度每个物理核心上的4个逻辑处理器(内核线程)。
Intel Itanium是一款双核芯片,使用7级优先级方案(紧急性)确定发生5种不同事件时应调度哪个线程。
5.5.5 虚拟化和调度
虚拟化增加了另一层复杂性和调度。
通常有一个主机操作系统在“真实”处理器上运行,以及一些客户操作系统在虚拟处理器上运行。
主机操作系统创建一些虚拟处理器,并将它们呈现给客户操作系统,就好像它们是真实的处理器一样。
客户操作系统不知道它们的处理器是虚拟的,并且在假设有真实处理器的情况下做出调度决策。
因此,客户系统的交互性和尤其是实时性能可能会受到严重影响。时间钟也经常不准确。
5.6 操作系统示例
5.6.1 Solaris 调度示例
基于优先级的内核线程调度。
四个类别(实时、系统、交互和时间共享),每个类别内有多个队列/算法。
默认为时间共享。
进程优先级和时间片动态调整在多级反馈优先级队列系统中。
时间片与优先级成反比 - 优先级越高的作业获得的时间片越小。
交互式作业比CPU密集型作业具有更高的优先级。
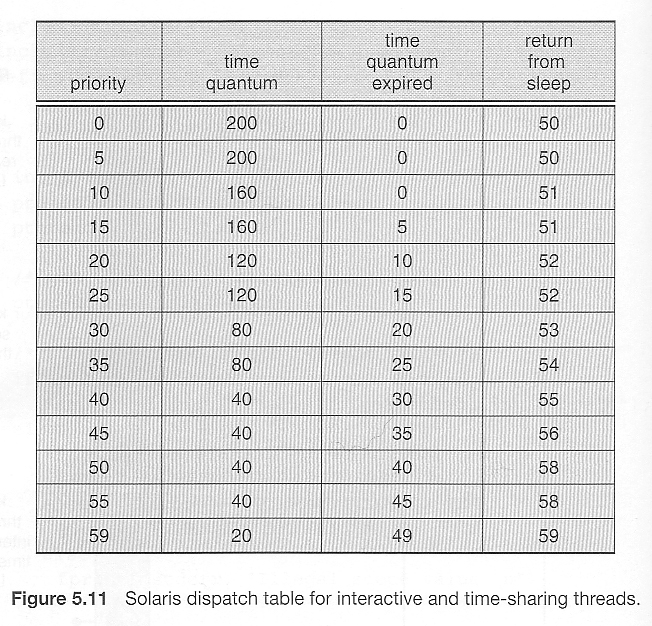
请参阅下表,了解一些60个优先级级别以及它们如何变化。
“时间片到期”和 “从睡眠状态返回” 表示发生这些事件时的新优先级。 (较大的数字表示较高,即更好的优先级。)
Solaris 9引入了两种新的调度类别:固定优先级和公平共享。
固定优先级类似于时间共享,但不会动态调整。
公平共享使用CPU时间份额而不是优先级来调度作业。一定份额的可用CPU时间被分配给一个项目,该项目是一组进程。
系统类别被保留供内核使用。(在内核模式下运行的用户程序不属于系统调度类别。)
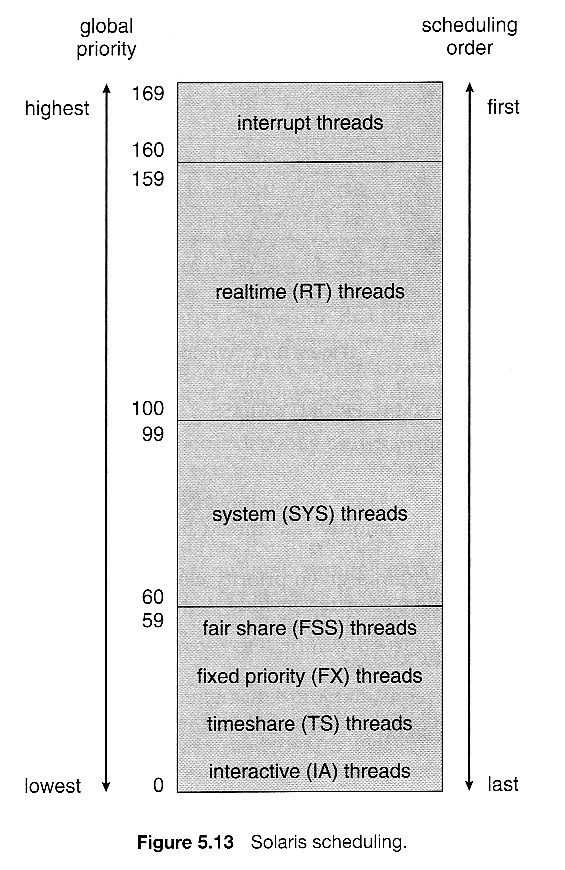
Windows XP使用基于优先级的抢占式调度算法。
调度程序使用32级优先级方案来确定线程执行的顺序,分为两类 - 变量类从1到15,实时类从16到31(加上优先级为0的线程管理内存)。
还有一个特殊的空闲线程,当没有其他线程准备就绪时,它会被调度。
Win XP标识了7个优先级类别(表格下的行),以及每个类别内的6个相对优先级(列)。
每个进程还被赋予其优先级类别内的基本优先级。当变量类进程消耗完其整个时间配额时,它们的优先级会降低,但不会低于它们的基本优先级。
前台进程(活动窗口)的调度配额乘以3,以提供更好的响应时间给前台的交互式进程。

现代Linux调度提供了对SMP系统的改进支持,以及一个随着进程数量增加而在O(1)时间内运行的调度算法。
Linux调度程序是一个基于优先级的抢占式算法,有两个优先级范围 - 实时从0到99,良好范围从100到140。
与Solaris或XP不同,Linux给较高优先级的任务分配了较长的时间片。
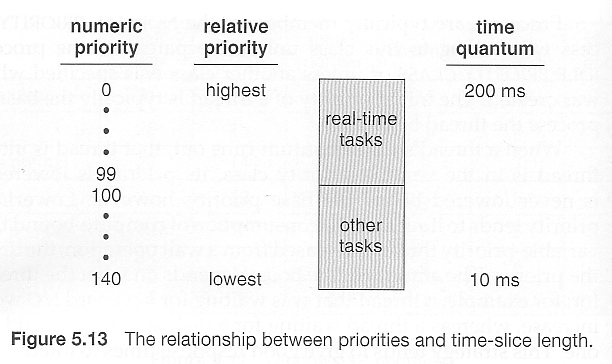
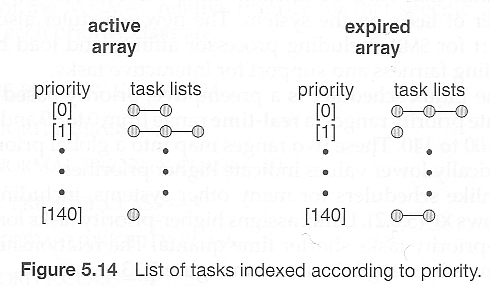
一个可运行的任务被认为有资格执行,只要它尚未消耗完其时间片中的所有时间。这些任务存储在一个活动数组中,根据优先级进行索引。
当一个进程消耗完其时间片时,它被移动到一个过期的数组中。在转移过程中,任务的优先级可能会被重新分配。
当活动数组变为空时,这两个数组会交换位置。
这些数组存储在运行队列结构中。在多处理器机器上,每个处理器都有自己的调度器,具有自己的运行队列。
5.7 算法评估 Algorithm Evaluation
确定对于特定操作环境来说哪种算法(以及该算法内的哪些参数设置)是最佳的第一步是确定要使用的标准,要达到的目标以及必须应用的任何约束条件。
例如,可能希望“最大化 CPU 利用率,但响应时间最多为 1 秒”。
一旦确定了标准,就可以分析不同的算法,并确定“最佳选择”。下面的部分概述了确定“最佳选择”的一些不同方法。
5.7.1 确定性建模 Deterministic Modeling
如果已知特定的工作负载,那么可以相对容易地计算出主要标准的确切值,并确定“最佳”值。
例如,考虑以下工作负载(所有进程在时间 0 到达),以及由三种不同算法确定的结果调度:
Process Burst Time
P1 10
P2 29
P3 3
P4 7
P5 12
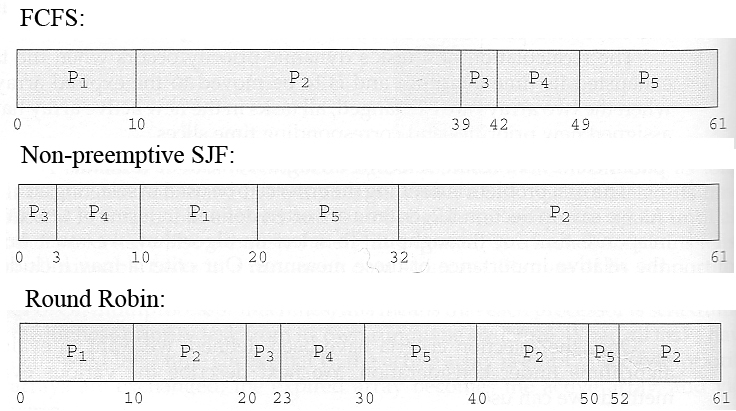
FCFS、SJF 和 RR 的平均等待时间分别为 28ms、13ms 和 23ms。
确定性建模快速简单,但需要具体已知的输入,并且结果仅适用于该特定输入。然而,通过检查多个类似的情况,可以观察到某些趋势(比如,对于同时到达的进程,SJF 总是产生最短的平均等待时间)。
5.7.2 排队模型 Queuing Models
通常情况下,特定进程数据是不可用的,特别是对于将来的时间。
但是,对历史性能的研究通常可以产生对某些重要参数的统计描述,例如新进程到达的速率,CPU 周期与 I/O 时间的比率,CPU 周期时间和 I/O 周期时间的分布等。
有了这些概率分布和一些数学公式,可以计算出单个等待队列的某些性能特征。
例如,小队公式表明,对于平均队列长度为 N,队列中平均等待时间为 W,新工作的平均到达率为 Lambda,则这三个术语可以通过以下关系相互联系:
N = Lambda * W
排队模型将计算机视为相互连接的队列网络,每个队列由其概率分布统计和小队公式等公式描述。
然而,现实系统和现代调度算法非常复杂,以至于在许多情况下与实际系统的数学问题难以解决。
另一种方法是在不同的负载条件下运行对不同提议算法(以及调整参数)的计算机模拟,并分析结果以确定特定负载模式的“最佳”操作选择。
5.7.3 模拟 Simulations
模拟的操作条件通常使用类似于上述描述的分布函数随机生成。
在可能的情况下,更好的选择是生成跟踪记录,通过监视和记录真实系统在典型预期工作负载下的性能。
这更好,因为它们提供了更准确的系统负载情况,并且因为它们允许对相同的进程负载进行多次模拟,而不仅仅是统计上等效的负载。
一种折衷的方法是随机确定系统负载,然后将结果保存到文件中,以便所有模拟可以针对相同的随机确定的系统负载运行。
尽管跟踪记录提供了更准确的输入信息,但它们可能难以收集和存储,使用它们会显著增加模拟的复杂性。
还有一些问题,即新系统的未来性能是否真的会与旧系统的过去性能相匹配。(如果系统运行速度更快,则用户可能会减少喝咖啡的时间,每小时提交的进程也会更多。
相反,如果作业的周转时间较长,智能用户可能会更加谨慎地考虑他们提交的作业,而不是随机提交作业,希望其中一个能成功。)
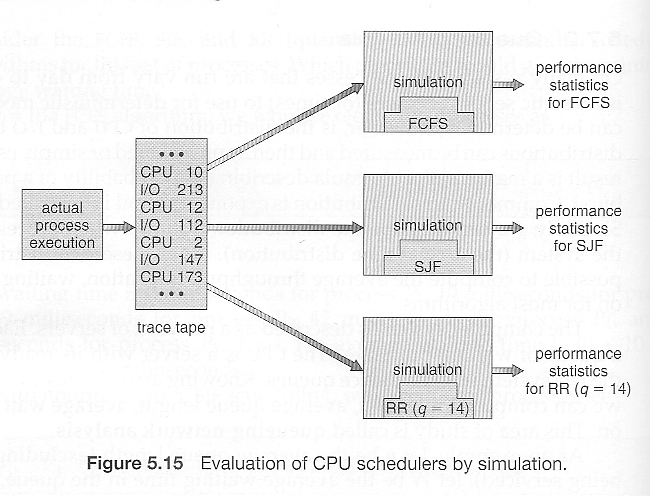
确定一个提议的调度算法如何运行的唯一真实方法是在实际系统上实现它。
对于实验性算法和正在开发中的算法,这可能会引起用户的困扰和抵触,因为他们不关心操作系统的开发,而只是试图完成他们的日常工作。
即使在这种情况下,测量结果也可能不是最终的,至少有两个主要原因:
(1)系统工作负载并不是静态的,而是随着时间的推移而改变,随着新程序的安装、新用户的加入、新硬件的可用性、新的工作项目的开始,甚至是社会变化。
(例如,互联网的爆炸性增长已经大大改变了系统看到的网络流量量以及处理它所需的快速响应时间的重要性。)
(2)如上所述,更改调度系统可能会影响工作负载以及用户使用系统的方式。
(该书举了一个例子,一个程序员修改了他的代码,以便定期向屏幕写入任意字符,以便他的作业被分类为交互式,并被放入更高优先级的队列中。)
大多数现代系统都提供了一些功能,让系统管理员调整调度参数,无论是在线调整还是重新启动或内核重建后进行调整。
5.8 总结
第八版省略的内容:
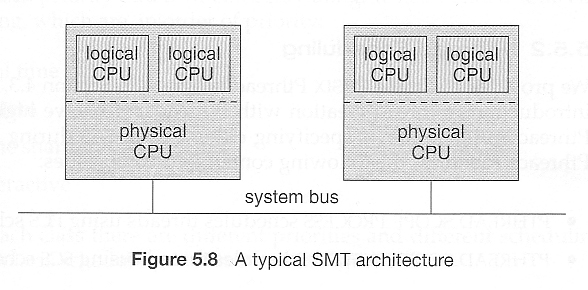
5.4.4 对称多线程(第八版省略)
SMP 的另一种策略是 SMT,对称多线程,在这种策略中使用多个虚拟(逻辑)CPU,而不是(或与之组合)多个物理CPU。
SMT 必须在硬件中得到支持,因为每个逻辑CPU都有自己的寄存器,并处理自己的中断。(英特尔将 SMT 称为超线程技术。)
在某种程度上,操作系统不需要知道它正在管理的处理器是真实的还是虚拟的。另一方面,如果调度器知道虚拟处理器到真实CPU的映射关系,一些调度决策可以进行优化。(考虑下面显示的体系结构上两个CPU密集型进程的调度。)
参考资料
https://www.cs.uic.edu/~jbell/CourseNotes/OperatingSystems/5_CPU_Scheduling.html
Abraham Silberschatz、Greg Gagne 和 Peter Baer Galvin,《操作系统概念,第八版》,第 5 章
