分析
分析(Analysis), 在 Lucene 当中指的是将域(Field) 文本转换为最基本的索引表示单元——-项(Term)的过程。
在搜索过程中,这些项用于决定什么样的文档能匹配查询条件。
例如,如果这句话“For example. if this sentence were indexed into a field”被索引到一个域(Field)中(假设域类型为 Field.Text), 相应产生的项可能是以 for 和 example两个单词打头,其它的项随之按照它在句子中出现的先后顺序逐个排列。分析器(analyzer) 对分析操作进行了封装。分析器通过执行若干操作,将文本语汇单元化,这些操作可能包括提取单词、去除标点符号、去掉语汇单元上的音调符号、将字母转换为小写(也称为规格化)、移除常用词、将单词转换为词干形式(词干还原),或者将单词转换为基本形(lemmatization) 等。这个过程也称为语汇单元化过程 (tokenization),而从文本流中得到的文本块称为语汇单元(tokens)。各语汇单元与关联的域(Field)名相结合就形成了各个项(Term)。
开发 Lucene 的主要日的是为了让信息检索变得更容易。强调检索是很重要的。用户一定希望向 Lucene 中装载大量文本,并且希望通过文本中的单词迅速的找到相关的文档。为了让Lucene 理解“单词”是什么,就要在索引时分析文本,并将项从文本中提取出来。而这些项构成了搜索的基础构件。
使用 Lucene时,选择一个合适的分析器是非常关键的。对分析器的选择没有惟一的标准。待分析的语种是影响分析器选择的因素之一,因为每种语言都有其自身的特点。影响分析器选择的另一个因素是被分析的文本所属的领域,不同的行业有不同的术语、缩写词和缩略语,我们在分析过程中一定要注意这一点。尽管我们在选择分析器时考虑了很多因素,但是不存在任何一个分析器能适用于所有情况。有可能所有的内置分析器都不能满足你的需求,这时就得创建一个自定义分析解决方案;令人振奋的是, Lucene的构件模块让这一过程变得十分容易。
当读者研究分析过程时,可能经常会问“Google 是怎么做的?”。
Google 目前的算法是公司私有并且相对保密的,但是从搜索结果中我们可以看出一些端倪。
让我们做一个有趣的实验,在带引号和不带引号的情况下分别搜索短语“to be or not to be”。
令人惊讶的是,在不带引号的情况下, Google(在本书写作期间)惟一考虑的单词是: not:其他单词都被当作常用词被移除掉了。但是, Google 在索引期间并没有移除这些停止词(stop words), 通过搜索带引号的短语你就可以明白这一点。这里有一个有趣的现象:目前搜索引擎中索引的停用词数量多得惊人!
Google 是怎样做到在索引 Internet 上网页中每个单词的同时,又不耗尽存储资源的呢?
基于 Lucene 的分析器为我们提供了这个问题的解决方案,正如我们下面将要讨论的一样。
这一章我们将涉及 Lucene 分析过程的方方面面,包括怎样、在何处使用分析器、内置分析器的具体作用,以及怎样利用 Lucene 中的核心API所提供的构件模块编写自定义的分析器等内容。
4.1 使用分析器
在深入了解分析器内部的繁琐细节之前,让我们先看一下分析器在 Lucene 中是如何被使用的。
分析操作发生在两个阶段:建立索引以及使用 QueryParser 对象时。在下面的两节中,我们将详细讨论如何在这两个场景下如何使用分析器。
在我们着手介绍具体代码之前,先阅读程序4.1以便对分析过程有一个总体的认识。
我们使用4个内置分析器对两个短语进行了分析。
这两个短语分别是:“The quick brownfox jumped over the lazy dogs”和“XY&Z Corporation-xyz@example.com”.
在输出结果里,每个语汇单元都由方括号分隔开。
进行索引时,分析期间提取出的语汇单元就是后来被编入到索引中的项。
此外,最重要的就是,索引后的项就是可以用于搜索的项。
索引创建
public void simpleTest() throws IOException {
final String indexDir = "index/chap04";
//1. 构建 writer
Directory directory = FSDirectory.open(Paths.get(indexDir));
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig iwConfig = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(directory, iwConfig);
//2. 写入 document
List<String> contentList = Arrays.asList("The quick brownfox jumped over the lazy dogs", "go with lucene", "go with java");
int id = 0;
for(String text : contentList) {
id++;
Document document = new Document();
document.add(new StringField("id", id+"", Field.Store.YES));
document.add(new TextField("content", text, Field.Store.YES));
indexWriter.addDocument(document);
}
//3. 关闭属性
indexWriter.commit();
indexWriter.close();
}
4.1.2 QueryParser分析
Analyzer 类对那些经过索引后的项而言也是非常重要的。正如在第3章中所看到的样,你必须通过查询那些经过索引的项,才能搜索到所需要的文档(我们在3.1.2和3.5小节中讲述了 QueryParser 类对查询表达式的解析过程及其使用细节)。
当你使用由构造函数创建的诸如 TermQuery 等Query 对象时,程序开发者必须确保他所使用的项能够和被索引的内容相匹配。
开发人员会经常被要求实现这样的需求:为用户提供形式自由的查询,此时使用QueryParser便可以轻松地处理用户输入的各种查询表达式。
QueryParser 对象使用分析器来尽可能匹配索引过的项。
我们可以在 QueryParser 类的静态方法 parse()中指定一个特定的分析器:
Query query = QueryParser.parse(expression, "contents", analyzer);
或者,如果你需要使用QueryParser实例,那么也可以在 QueryParser 的构造函数中指定分析器的类型:
QueryParser parser = new OueryParser("contents", analyzer);
query = pareer.parse(expression):
QueryParser 对象分析了表达式 expression 对象中每个独立的片断,而并不是将其作为一个整体进行分析。这个表达式整体可能包括了操作符、圆括号或其它表示范围、通配符以及模糊搜索等在内的特殊表达式语法。
QueryParser 对全部的文本进行的都是同样的分析,而不管这些文本究竟是如何被索引的。这使得查询 Field.Keyword 类型域时,会出现一个相当棘手的问题。我们将在4.4小节中详细解释这种情况。
进行查询时, QueryParser 所使用的分析器和索引时所使用的分析器必须相同吗?最简洁准确的回答是:“看情况”,如果你采用了基本的内置分析器,那么你在以上两种情况下使用相同的分析器可能会行得通。
但是,当使用更复杂的分析器时,在索引时和查询分析(QueryParser) 两种情况下,使用不同的分析器会获得最好的效果,这真是有点离奇。
我们将在4.6小节详细地讨论这一问题。
4.1.3 解析vs分析:分析器何时不适用
在 Lucene 内部,分析器用于将域的内容语汇单元化,这是分析器的一个重点任务HTML、Microsoft Word、XML 以及其他格式的文档,包括了如作者、标题、最新修改时间等许多潜在的元数据(meta-data)。
当你索引富文档(rich documents)时,这些元类据需要被分离出来,并索引为单独的域。分析器可以用于每次分析一个特定的域并且料域内的内容分解为语汇单元;但是在分析器内不可以创建新的域。
分析器不能用于从文档中分离和提取出域,因为分析器的职责范围只是每次处理一个域。
所以为了对域进行分离,就要在分析之前预先解析这些文档。
例如,一个常见的做法就是把 HTML 文档中的 <title> 和 <body> 部分分离为一些单独的域。
在这种情况下,文档应该被解析或者预处理过,从而用独立的文本块表示每个域。
第7章中介绍了几特殊的文档类型,并提供了索引这些文档的一些可选方案,并讨论了对不同文档类型送行解析的更多细节。
4.2 剖析分析器
为了完全认识和理解 Lucene 分析文本的工作原理,我们需要进行一些深入的剖析以认识它真实的面目。
因为将来你可能会需要创建自己的分析器,所以对 Lucene 所提架构和构件模块的理解就显得非常重要了。
Analyzer 类是所有分析器的基类。它以一种良好的方式将文本逐字地转换为语汇元流, 一个 TokenStream 实例。
唯一要求分析器实现的方法声明就是:
/**
* Wrap the given {@link TokenStream} in order to apply normalization filters.
* The default implementation returns the {@link TokenStream} as-is. This is
* used by {@link #normalize(String, String)}.
*/
protected TokenStream normalize(String fieldName, TokenStream in) {
return in;
}
需要注意的是,分析器可屏蔽域名。因为域名是任意的,且依赖于具体的应用程序因此所有的内置分析器都忽略了域名。自定义分析器可以自由地应用到域上,或者更单方法的是,通过特殊的PerFieldAnalyzerWrapper 类的对象可以将分析每个域的任务多托给与域名相关联的分析器(详细内容请见4.4节)。
SimpleAnalyzer 源码浅析
我们从简单的 SimpleAnalyzer 类开始观察分析器是怎样工作的。
以下代码是Lucene 的代码库中直接复制的:
/** An {@link Analyzer} that filters {@link LetterTokenizer}
* with {@link LowerCaseFilter}
**/
public final class SimpleAnalyzer extends Analyzer {
/**
* Creates a new {@link SimpleAnalyzer}
*/
public SimpleAnalyzer() {
}
@Override
protected TokenStreamComponents createComponents(final String fieldName) {
return new TokenStreamComponents(new LowerCaseTokenizer());
}
@Override
protected TokenStream normalize(String fieldName, TokenStream in) {
return new LowerCaseFilter(in);
}
}
LowerCaseTokenizer
LowerCaseTokenizer 一起执行 LetterTokenizer 和 LowerCaseFilter 的功能。
它以非字母划分文本并将它们转换为小写。
虽然它在功能上等同于 LetterTokenizer 和 LowerCaseFilter 的组合,但同时执行这两个任务具有性能优势,因此是这种(冗余)实现。
4.2.1 语汇单元的组成
语汇单元流是经过分析所产生的基木单元。在索引时, Lucene 使用特定的分析器来处理需要被语汇单元化的指定域,并且将每个语汇单元以项的形式写入索引中。
语汇单元和项之间的区别乍一看似乎并不明显。我们先来看看 Token 对象的组成部分,再在稍后的部分回到从语汇单元到项的转换过程上来。
我们以对文本“the quick brown fox”的分析来为例。
该文本中每个语汇单元都表示一个独立的单词(word)。一个语汇单元携带了一个文本值(这个单词本身)和其他一些元数据:原文本从起点到终点的偏移量、语汇单元的类型和位置增量(position increment)。
- 图4.1带有位置和偏移信息的语汇单元流
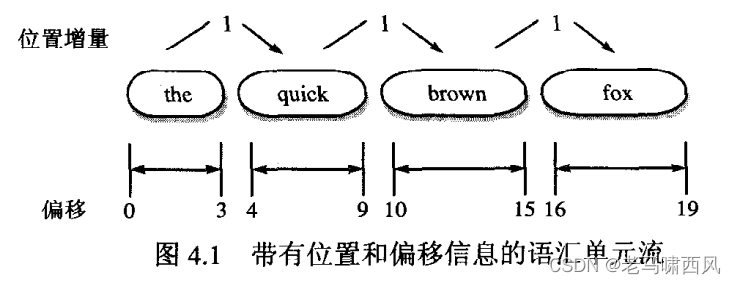
起点的偏移量是指语汇单元文本的起始字符在原文本中的位置,而终点的偏移量则表示语汇单元文木终止字符的下一个位置。语汇单元的类型以一个 String 对象表示,其值默认为“word”, 如果需要的话,读者可以在语汇单元的过滤过程中控制和利用到其类型属性。文本被语汇单元化之后,相对于前一个语汇单元的位置信息被保存为位置增量值。所有的内置语汇单元化器将位置增量的默认值设置为1,表示所有语汇单元都是连续的,位置上是一个紧接一个的。
### 语汇单元转换为项
当文本在索引过程中经过分析后,每个语汇单元都作为一个项被传递给索引。
位置增量是语汇单元携带到索引中的惟一的附加元数据。起点和终点偏移量和语汇单元类型都被抛充了——这些元数据仅在分析过程中使用。
位置增量
位置增量为1,表示每个单词存在于域中唯一且连续的位置上。位置增量因子会直接影响短语查询(见3.4.5节)和跨度查询的执行情况(见5.4节),因为这些查询需要知道域中各个项之间的距离。
如果位置增量大于1,则允许单词之间有空隙,它用来表示那个空缺的位置上有一些单词已经被删除了。在4.7.1小节移除停用词的例子中, Lucene 通过位置增量保留了移除停用此后产生的空隙。
位置增量值为0的语汇单元,会将该语汇单元放置在前一个语汇单元的位置上。
用于加入单词别名的分析器可以通过零位置增量来放置某个单词的同义词。这样做使得Lucene 在进行短语查询时,输入任意一个同义词都能匹配到相应的结果。
在4.6小节中的 SynonymAnalyzer 程序是使用0位置增量的一个例子。
4.2.2 TokenStream 揭密
TokenStream 有两个不同的子类: Tokenizer 和 TokenFilter。
关于它们之间区别,有一个很好的概括性的解释就是 Tokenizer 用于处理单个字符,而 TokenFilter 则用于处理单词。
Tokenizer 是 TokenStream 的子类,它将 Reader 对象中的数据切分成语汇单元。
当你索引Field.Text (String, String) 域或者 Field.UnStored (String, String)域(即被索引域的构造函数接受一个 String 对象作为其参数时)中的 String 对象时, Lucene 会将构造函数中的 String 对象包装在 StringReader 中,以便进行语汇单元的切分。
TokenStream 类的第二个子类——TokenFilter,允许你将多个 TokenStream 对象连接在一起。这个强大机制使它成为了一个名副其实的流过滤器。一个TokenStream 对象被传递到 TokenFilter 中,并在传递过程中,由过滤器对其进行添加、删除或者更改等操作。
图 4.3 展示了 TokenStream 类在 Lucene 中完整的继承层次。注意 TokenFilter 类中所中所使用的组合模式。
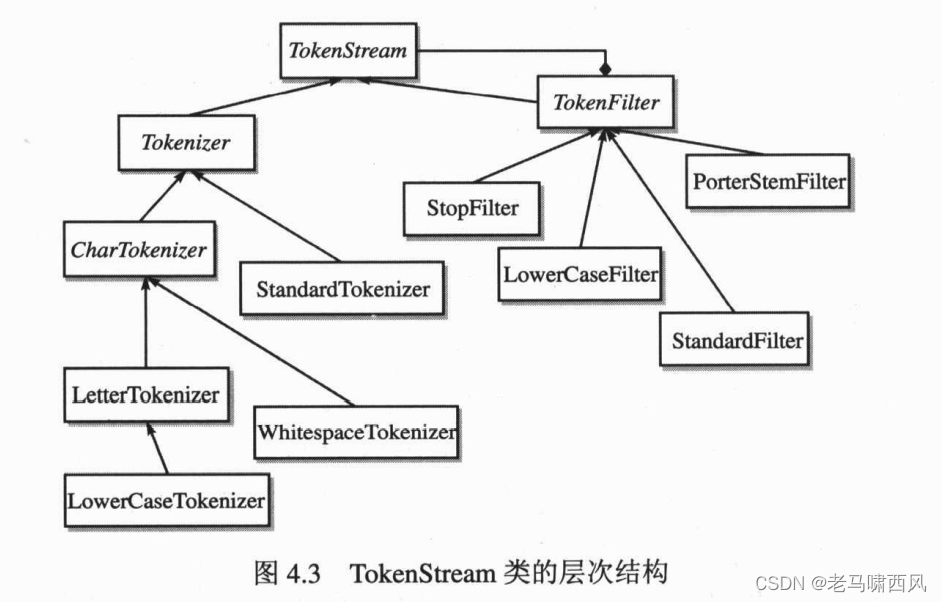
利用 TokenFilter 类链接模式的优点,你可以通过简单的 Tokenizer/TokenFilter构造模块构建出复杂的分析器。
Tokenizer 类通过将输入字符转换为语汇单元(通常也就是原文本中的单词)来开始分析过程。
TokenFilter 则负责完成分析过程中剩余的其他工作:首先封装一个 Tokenizer 对象,接着封装嵌套的 TokenFilter 对象。
在 StopAnalyzer 对象中, LowerCaseTokenizer 对象作为参数传递给了 StopFilter 的构造函数。LowerCaseTokenizer 在分析过程中将字符转换为小写,并输出语汇单元,这些语汇单元是原文本中相邻的单词。
LowerCaseTokenizer 以非字母字符作为切割语汇单元的边界,这些非字母字符将不包含在任何输出的语汇单元中。在经过语汇单元切分器和小写转换器的处理之后, StopFilter 移除在停用词表中出现的单词(详见4.3.1节)。
在 TokenStream 的执行过程中,缓存通常是必要的特性。底层的 Tokenizer 使用缓存存储字符,以便在语汇单元边界(如空格和其他非字母字符)处生成语汇单元。
TokenFilter向过滤流中输出语汇单元,它必须对输入的语汇单元和附加的语汇单元进行排列,并且每次只能输出一个语汇单元;
在4.6节中 SynonymFilter 是一个队列过滤器的例子。
4.2.3 观察分析器
理解各种分析器对文本进行的处理是很重要的内容。观察分析器的处理结果是帮助我们理解这一过程的有效的方法。
程序4.2使用四个主要的内置分析器分析了两个样例文本,并提供了观察返回结果的便捷途径。
AnalyzerDemo程序中包含了两个预定义的词组和本小节所关注的四种分析器,四个内置分析器都对这两个短语进行了分析,带方括号的输出表示将要被索引的项。
除非需要对域分析的结果进行详细的诊断或需要了解某些分析过程中的细节信息,否则,一般说来,读者是不必显式地调用分析器的 tokenStream()方法的。
但是,我们还是通过调用这个方法在我们的一个应用程序中实现了在查询结果中高亮显示查询项的功能,如本书8.7节中所示。
AnalyzerDemo 程序输出了列表4.1中所示的结果。其中还有如下一些要点值得我们在此指出:
-
WhitespaccAnalyzer 不会把指定的单词转换为小写形式,它会保留原文中的破折号(——),它以空格作为边界,将空格间的内容切分为最小的语汇单元。
-
SimpleAnalyzer 会保留那些所谓的停用词,但是它会把指定域中的所有单词转换为小写形式,并以非字母字符作为单个语汇单元的边界。
-
SimpleAnalyzer 和 StopAnalyzer 会把公司的名字 (XY&Z) 分且分成XY和Z,并且去掉了其中的“&”符号。
-
StopAnalyzer 和 StandardAnalyzer 都删除了单词“the”。
-
StandardAnalyzer保持了完整的公司名称,将其转换为小写形式,并去掉了破折号-),此外,该分析器还会把 e-mail 地址完整地保留下来。而其它的分析器,没有任 何一个能像它一样完成得如此彻底。
建议你在应用程序中保留以上例程中输出语汇单元的功能,以便能确定程序在所选定的分析器中都分离出了哪些语汇单元。
事实上,要实现这个功能不需要自己再编写额外的代码,只需要用 AnalyzerUtils 或 AnalyzerDemo 就可以进行实验。
AnalyzerDemo 程序使你能够从命令行中指定一个或多个需要进行分析的字符串,而不只限于使用程序代码内指定的那些字符串样本:
测试代码
String text = "To be or not to be —— that's a question?";
System.out.println("SimpleAnalyzer: ");
AnalysisUtils.displayTokenList(text, new SimpleAnalyzer());
System.out.println("WhitespaceAnalyzer: ");
AnalysisUtils.displayTokenList(text, new WhitespaceAnalyzer());
System.out.println("StopAnalyzer: ");
AnalysisUtils.displayTokenList(text, new StopAnalyzer());
System.out.println("StandardAnalyzer: ");
AnalysisUtils.displayTokenList(text, new StandardAnalyzer());
日志如下:
SimpleAnalyzer:
[to][be][or][not][to][be][that][s][a][question]
WhitespaceAnalyzer:
[To][be][or][not][to][be][——][that's][a][question?]
StopAnalyzer:
[s][question]
StandardAnalyzer:
[that's][question]
4.3 使用内置的分析器
Lucene 中包含了一些内置的分析器。表4.2中列出了其中几个主要的分析器。两个针对特定语言的分析器 RussianAnalyzer 和 GermanAnalyzer 将留到4.8.2节讨论, 而PerFieldAnalyzerWrapper 这个类则用于封装那些按域进行分析的分析器,我们将在4.4节对这个特殊的类进行介绍。
- 表 4.2 Lucene 中几个主要可用的分析器
| 分析器 | 内部操作步骤 |
|---|---|
| WhitespaceAnalyzer | 在空格处进行语汇单元的切分 |
| SimipleAnalyzer | 在非字母字符处切分文本,并将其转换为小写形式 |
| StopAnalyzer | 在非字母字符处切分文本,然后小写化,再移除停用词 |
| StandardAnalyzer | 基于复杂的语法来实现语汇单元化;这种语法规则可以识别 e-mail 地址、首字母缩写词、汉语-日语-汉语字符、字母数字等:小写化:并移除停用词 |
在本节中,我们将会讨论 WhitespaceAnalyzer、SimpleAnalyzer、StopAnalyzer 和StandardAnalyzer 等几个内置的分析器,这些分析器几乎可以用于分析所有的西方(主要指欧洲)语言。
我们从4.2.3节各个分析器的输出中可以看到每个分析器不同的分析效果。
WhitespaceAnalyzer 和 SimpleAnalyzer 都很好理解,在这里我们就不深入介绍了。
由于StopAnalyzer 和 StandardAnalyzer 这两个分析器都具有比较特殊而又突出的处理效果,我们将更深入地对它们进行了解。
其他
同音字
近音字
形近字
同义词
拼写错误
停顿词
词干分析
参考资料
《Lucene in Action II》
