Lucene 的索引
到目前为止,我们一直把 Lucene 的索引或多或少地当作一个黑盒来对待,并且把注意力放在它的逻辑视图上。虽然如果只是为了使用 Lucene, 可能没有必要去深入理解索引结构的细节,但是你可能对 Lucene 索引的“魔力”非常好奇。
Lucene 的索引结构是对它本身高效数据结构、性能最大化和资源使用最小化之间巧妙安排(arrangement) 的一个个案研究。
你可以把它看作一个单纯的技术成果,或者你也能把它当作一个精巧的艺术品。
有一些东西能够使用尽可能最有效率的方式来表现一个复杂的结构,有着一种自然赋予的美丽(分形公式表示的信息和DNA 结构都可以作为这一事实存在大自然中的例证)。
在本附录中,我们开始着眼于 Lucene 索引的逻辑视图,在逻辑视图中把文档传给Lucene 并且在搜索过程中检索这些文档。然后,我们会揭密 Lucene 倒排索引的内部结构。
B.1 逻辑索引视图
首先让我们开始快速回顾一下,你已经了解了的关于 Luccnc 索引的知识点。
参照图B.1的内容, 从一个使用 Lucene API 的软件开发者的角度来看,一个索引可看作一个黑盒,用抽象 Directory 类表示。在索引过程中,创建 Lucene 的 Document 类的实例并用成对的名称和值组成的域(Field) 填充该实例。
接下米这个 Document实例就会被引,索引是通过将它传递给 IndexWriter.addDocument(Document)方法来运行的。
当搜索时,你会再次用到抽象类 Directory 来表示索引。把该 Directory类实例传递给 IndexSearcher 类,然后通过将封装在 Query 对象中的搜索项传递给一个IndexSearcher 类的 search 方法,从而获得匹配给出查询语句的文档(Doucument 对象)。匹配文档的结果集用 Hits 对象表示。
B.2关于索引结构
在1.5小节讲述 Lucene 的 Directory 类时, 我们提到了它的一个具体实现的子类FSDirectory, 该子类用于在文件系统的目录中保存索引。在程序1.1中,我们还使用了一个名为的 Indexer 程序,用于索引文本文件。回忆我们在命令行中运行 Indexer 时, 曾经指定了几个参数,其中一个参数就是用来指定 Indexer 创建 Lucene 索引存放目录路径的。一旦 Indexer 运行完毕,这个目录是什么样的呢?目录里面包含那些内容?在本小节,我们将深入探索 Lucene 的索引并讲解它的结构。
Lucene 支持两种索引结构:多文件索引 (multifile indexes) 和复合索引 (compoundindexes)。前者是原来旧版本的索引结构;后者是从Lucene1.3中开始新引入的,并且在1.4版中成为了默认的索引结构。现在我们来对这两种索引结构分别进行阐述,首先来看看多文件索引(multifile indexes)。
B.2.1 理解多文件索引结构
如果查看 Indexer 程序创建的索引目录,你会看到许多文件,初看起来这些文件名是杂乱无章的。
这些列出的索引文件类似于下面所示的形式:
-rw-rw-r--1 otis 51 4Nov 22 22:43 deletable
-rw-rw-r--1 otis otis 1000000Nov 22 22:43 lfyc.f1
-rw-rw-r- 1 otis otis 1000000Nov 22 22:43 1fye.f2
-rw-rw-r otis otis 31030502Nov 22 22:281fyc.fdt
-IW-rW-I otis otis 8000000Nov 22 22:28_lfyc.fdx
-rW-rW-r otis otis 16Nov 22 22:28 1fyc.fnm
-rw-rw-r· 1 otis 之总1253701335Nov 22 22:43
-IW-EW-I--1otis otis1871279328Nov 22 22:43 1fyc.prx
-rw-EW-r--1otis aig 14122Nov 22 22:43IEye,t
-rW-rw-r--1 otis otis 1082950Nov 22 22:43_lfyc.tis
-rw-rW-r--i otis otis 18Nov 22 22:43 segments
值得注意的是,其中的一些文件具有相同的前缀。在本例的索引中,一些文件名是以_Ifyc 为前缀的,而后是不同的扩展名。
这一现象让我们注意到了索引中的段的存在。
索引段
Lucene 索引由一个或多个段 (segments)组成,而每个段又由多个索引文件组成。
属于同一个段 (scgments) 的索引文件具有相同的前缀名以及不同的后缀(扩展名)名。
上面例子中的索引目录由单个段组成,该段的文件名都以_lfyc 作为开始。
下面的例子中显示了一个具有两个分别名为_lfyc 和_gabh 的段 (segments)的索引目录:
你可以把一个段看作为一个子索引 (subindex), 虽然每个段不是一个完全独立的索引。
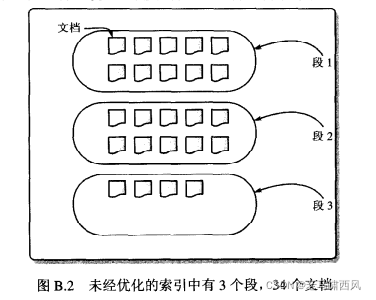
如你在图 B.2中所看到的那样,每个段(segment) 包含了一个或多个 Lucene 文档(Document 对象),这些文档就是我们利用 Index Writer 类中 addDocument(Document)方法添加到索引中的那些文档。现在你可能很想知道段(segment) 在 Lucene 索引中到底扮演什么样的角色,下面的内容就是这个问题的答案。
增量索引
段的使用可以让你通过将文档添加到新创建索引段中并只需周期性地与其他现存段合并的方法,快速地将新文档添加到索引中。[0]这个过程提高了效率,因为它最大程度地减少了物理存储的索引文件的修改。
图B.2显示了一个拥有34个文档的索引。这个图中的索引并未经过优化——它包含了多个段 (segments)。 如果使用 Lucene 默认的索引参数来优化该索引,那么它所有的34个文档都会合并到一个段中。
Lucene 的优势之一就是支持增量索引 (Incremental indexing),这个功能并不是所有的信息检索库都支持的。
有一些信息检索库,在向索引中添加新的数据时需要重新索引整个文档集,而 Lucene 不需要这样。在索引中添加了一个新文档之后,就可以立即搜索该文档的内容了。
在信息检索的领域里,增量索引(Incremental indexing) 是一个很重要的特性。
Lucene 对增量索引 (Incremental indexing) 的支持使得 Lucene 适合在处理大量信息的环境下工作,在这种环境下重建索引的方法将显得效率很低。
因为当索引一个新的文档的同时也会创建一个新段,段的数量以及索引文件在索引过程中是变化的。
一旦一个索引被完全创建好后,索引文件和段的数量将保持稳定。
剖析索引文件
每个索引文件都携带了某种格式的 Lucene 的重要信息。
如果任何一个索引文件被Lucene 自身以外程序的修改或者删除,索引将会被破坏。而惟一的补救方法就是重新从原始数据索引。另一方面,你可以随心所欲地将任意文档添加到 Lucene 的索引目录中,而不会造成索引的损坏。
例如,如果我们添加一个文件名为 random-document.txt 的文件到索引目录中, Lucene 将忽略这个文件,而索引不会损坏,情况如下所示:
能解开这个秘密的钥匙就是段文件(segments file)。
顾名思义,段文件保存了所有现有索引段的名称。在访问索引目录中任何一个文件之前, Lucene 都会根据段文件的内容判断应该打和读取哪个索引文件。
在我们例子中,索引只包含了一个段_lfyc,它的名字保存在段文件中,所以 Lucene 知道只需要查找那些以_lfyc 为前缀的文件就可以了。
Lucene 当然也会限制自己只处理那些已知后缀的文件,如.fdt、.fdx 和其他例子中列举的那些后缀,所以即使我们将一个和段文件前缀相同的文件如_lfyc.txt 保存到索引目录中,Lucene 还是能正常工作。
当然了,我们强烈建议不要向索引目录中添加非 Lucene 的文件。Lucene 索引和段中确切的文件数量因索引而异,它取决于索引中包含的域的数量。但是每个索引包含一个段文件和一个可删除文件 (deletable file)。后者含有索引当中已标记为删除的文档的信息。如果你回顾一下前一个例子,会注意到有两个以.fN为后缀的文件,其中的N为数字。这些文件与现有的被索引的文档(Document 对象)中的索引域(indexed field) 相对应。
回忆一下程序1.1中的 Indexer 程序,它创建了一个带有两个域的文档:一个文本内容 (contents) 域和一个关键字(keyword)文件名域。这个索引含有两个索引域,因此索引含有两个以,fN为后缀的文件。如果这个索引含有三个索引域,那么一个名为_lfyc.f3的文件将会在索引目录中出现。所以只要查看一下带有这种后缀的索引文件,你就可以很容易地判断出一个索引拥有多少个索引域。另外值得注意的有趣的一点是.fN文件的大小,它反映了该域对应文档的数量。了解了以上内容后,你现在只用浏览一下索引日录中的文件,就能知道之前的索引中拥有 1,000,000个文档。
创建一个多文件索引
现在你对多文件索引结构应该有了深刻的了解。但是如何利用 API 来命令 Lucene创建一个多索引文件而不是默认的复合文件的索引呢?
回顾一下我们在程序1.1中那个使用得稳定可靠的程序 Indexer。在那个程序中,会发现有以下代码:
IndexWriter writer m new IndexWriter(indexDir,
new StandardAnalyzer(), true);
writer.setUseCompoundFile(false);
因为复合文件索引结构是默认的,我们在 IndexWriter 实例 中调用setUseCompoundFile(false)将默认的结构禁止,并切换到多文件索引结构。
B.2.2 理解复合索引结构
在描述多文件索引时,我们说过索引文件的数量取决于当前索引中索引域 (indexedfields)的数量。
我们还提到了新文档添加到索引的同时会创建一个新段。既然一个段由一系列索引文件组成,这样可能会导致在索引目录中产生大量文件。虽然多文件索引结构简单直接,并适于在大多数的环境下工作。但是它不适合运行存在大量索引且索引包含大量域的环境下,以及使用Lucene 产生了大量索引文件的情况下。
目前大部分的操作系统对在系统中同时打开文件数量有所限制。
之前提到过,Lucene在添加一个文档的同时会创建一个新段,并且以比较高的频率合并这些段以减少索引文件。但是,执行合并过程的同时,索引文件数量会成为之前的两倍。如果 Lucene 在索引数量非常大的环境下使用,并且搜索和索引在同时进行,这种情况下很有可能会达到操作系统对打开文件设置的上限。这种情况也会发在单索引结构的情况下,比如索引未经优化或者其他应用程序在与 Lucene 同时运行时打开了大量文件。Lucene 对打开文件句柄(handles)的使用取决于索引的结构和状态。在本附录的后半部分,我们将向你介绍Lucene 处理索引所需打开文件的数量的计算公式。
复合索引文件
复合索引与多文件索引之间惟一外在的差别就是索引目录的内容。
下面是复合索引的一个范例:
-rW-rW-r-- otis 418 Oct 12 22:13 _2.cfs
-rw-rW-r--1 otis otis 4 0ct 12 22:13 deletable
-rW-rW-r--1 otis otis 15 0ct 12 22:13 segments
与多文件索引中必须要从索引中打开并读取10个文件相比,访问复合索引时Lucene只需打开两个文件,从而消耗的系统资源更少。复合索引减少了索引文件的数量,但是段、文档、域和项的概念仍然适用。存在的差别是复合索引中每个段包含了一个.cfs文件,而在多文件索引中每个段由七个不同的文件组成。复合结构把独立的索引文件封装在同一个.cfs 文件中。
创建一个复合索引
由于 Lucene 默认创建的是复合索引结构,因此不需要特别指定创建类型。但是如果你倾向于使用显示代码来指定,你可以调用 setUseCompound(boolean)方法,将该方法的参数设为 true。
IndexWriter writer = new IndexWriter(indexDir,
new StandardAnalyzer(), true);
writer.setUseCompoundrile(true);
对于使用者来说,令人高兴的是不需要固定的使用多文件格式还是复合索引格式的索引。
所以,在索引完毕后,你仍然可以从一种格式转换为另一种格式。
B.2.3转换索引结构格式
值得注意的是,你可以在索引的过程中的任何时间点上切换上述的两种索引结构。所需要做就只是在索引过程中的任意时刻,调用 IndexWriter 类的 setUseCompoundFiles(boolcan)方法。下一次合并索引段时, Lucene 会将索引转换到你指定的结构格式。同样,你也可以在不添加额外文档的情况下转换现有索引的结构。例如,为了在使用 Lucene 吋减少打开文件数量,而想把一个手上的多文件索引转换为复合索引。为了达到这个目的,可以利用 Index Writer类打开索引,指定复合索引结构,优化索引,然后关闭 IndexWriter。
IndexWriter writer - new IndexWriter(indexDir,
new standardAnalyzer(), false);
writer.satUseCompoundrile(true);
writer.optimize();
writer.close();
注意到Index Writer构造函数的第三个参数设置为 false,它用来确保现有的索引不被损坏。我们在2.8小节探讨了优化索引。优化操作迫使 Lucene 合并索引段,从而通过调用 setUseCompoundFile(boolean)方法, 为 Lucene 提供一个将索引重写为指定的新格式的机会。
B.3 选择索引结构
尽管在这两种索引结构之间切换非常简单,不过你可能还想了解一下,当访问索引时 Lucene将使用多少个打开的文件资源。如果你正在设计拥有多个同时索引数据和搜索索引的系统,不如干脆拿出一支笔和一张纸跟我们一起做下面这些简单的数学计算。
B.3.1 计算打开文件的数量
首先,我们来考虑多文件索引的情况。多文件索引中,每个段包含了七个索引文件,每个段的每个索引域对应了一个附加文件,此外整个索引还对应了一个可删除文件和一个段文件。设想一个系统包含了100个 Lucene 索引,每个索引有10个索引域。又假设这些索引未经优化且每个索引含有9个段,这些段尚未合并到单一的段中,这是在索引操作中一个很常见的情况。如果这100个索引同时都被打开用于搜索,结果就是需要打开15,300个文件。
下面是我们获得这个结果的计算方法:
100个索引*(每个索引9段*(每段7个文件+索引域的10个文件))=100*9*17=15300 个打开文件
尽管当前计算机通常可以处理这么多数量的打开文件,但是绝大多数的计算机预先设置的同时打开文件的数目远远比这一数字低。在2.7.1小节中,我们可以了解到如何在某些操作系统上检查和修改该设置。
接下来,我们考虑同样的100个索引,但是这次使用复合结构索引。每个段只创建一个以.cfs 为扩展名的文件,再加上为整个段服务的一个可删除文件和一个段文件。所以,如果我们使用复合索引而不是多文件索引,打开文件的数量将减少到900。
100个索引*(每个索引9段*(每段1个文件))
=100*9*1
=900个打开文件
由此我们可以得到这样的经验:如果你需要开发一个运行在大量索引域环境下的基于Lucene 的软件,那你就应该考虑使用复合索引结构。当然,即使在编写一个简单的应用程序处理单个 Lucene索引,你也可以考虑使用复合索引。
B.3.2 性能对比
当选择索引结构时,性能是另一个需要考虑的因素。有报告显示创建复合索引结构比同等的多文件索引慢5-10%;在我们的性能测试如程序B.1所示,这一点得到了证实。在这个测试中,我们创建了两个并行索引,每个索引里面人为地创建了25,000个文档。
在 testTiming()方法里,我们为每种类型索引的索引过程计时,结果标明创建复合索引花费的时间比创建多文件索引更长。
①本测试表明创建复合结构索引的速度在某种程度上慢于创建多文件索引的速度。具体慢多少并不确定,要取决于域的数量、长度以及所使用的索引参数等等。例如通过调整在2.7小节详细分析过的一些索引参数,你可能会在使用复合文件时获得比多文件索引更好的性能。
我们的建议是:如果要将 Lucene 的索引性能发挥到极限,请使用多文件索引结构。
但是在此之前,请先试着利用在2.7小节介绍的索引参数来调整复合结构索引操作。两种结构性能的差异和它们使用的系统资源的总量的差异是二者仅有的显著区别。在这两种不同类型索引的情况下,所有 Lucene 的功能特性都表现得一样出色。
B.4 倒排索引
Lucene 使用了众所周知的索引结构:倒排索引。
很容易就能想到,倒排索引就是对文档的逆向排列,在该索引中文档的项处于中心地位,从每一项为起点关联包含它的文档。让我们来仔细研究一下之前的样例书籍数据索引,来对索引目录中的文件做更深入的了解。
不管你正在使用的是 RAMDirectory (内存目录), 是 FSDirectory(文件系统目录)还是其他类型的目录,其内部结构都是一组文件。在内存目录中,文件是虚拟的、完全保存在内存(RAM)中。从字面上就可以看出 FSDirectory 表示的是一个文件系统目录,就如本附录之前描述的那样。
复合文件模式 (Lucene1.3 新增的特性)新增加了一种手段来处理目录 (Directory对象)中的文件。当 IndexWriter 类设置为复合文件模式时,“文件”被写入到一个.cfs文件中,这解决了耗尽文件句柄的这个常见难题。请查看本附录中“复合索引文件”小节,以获得更多关于复合文件模式的内容。
B.4.1索引揭密
Lucene 索引格式具体的细节在 Lucene web 站点 http//jakarta.apache.org/lucene/docs/fileformats.html 上有全面详细的描述。
如果我们在这里重复这些细节内容,对我们来说是完全没有必要的,对读者来说也是单调乏味的。
相反地,我们可用我们的样例书籍数据作为具体的例子来对总体文件结构进行概述。
我们的概述略过了大部分在实际数据表示中使用的复杂的数据压缩。
采用这种方式的目的是为了给你一个对结构的整体感性认识,而不会让你在细节上纠缠不清(同样这些细节内容也可以在 Lucene 的网站上看到)。
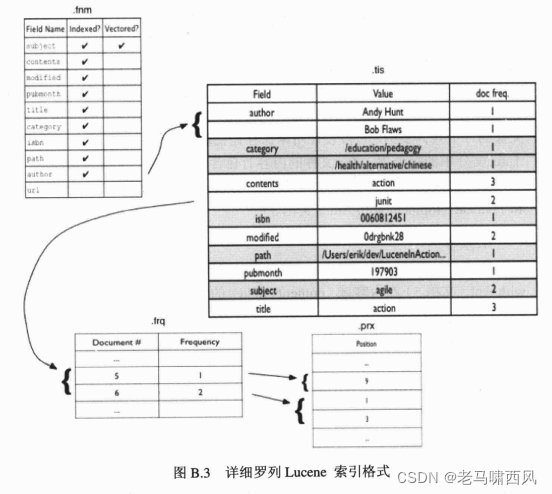
图 B.3 表示了我们样例书籍索引的一个片断。这是一个段的片断(本例中,我们使用了一个经过优化的包含一个段的索引)。一个段指定惟一的前缀名(本例为_c)。
下面的小节将更具体地描述在图 B.3中出现的每个文件。
域名(.fnm)
.fnm 文件存储了段中相关的文档包含的所有的域名。
其中每个域都被标记过了,以此来反映它是否被索引或被向量化过。
.fnm 文件中域名的排列顺序由索引过程决定,没有必要是字母顺序。
.fnm 文件中域的位置用于将域和标准化文件关联(文件以.f[0-9]*为后缀)。在这里我们不去详细研究标准化文件,参阅 Lucene 的 web站点可获得具体内容。
在我们的范例索引中,只有主题域(subject field) 经过向量化。域 url 作为一个Field.UnIndexed 类型的域添加,它没有被索引也不被向量化。图B.3 所示的.fnm 文件一个实际文件的完整视图。
项词典(.tis)
段中的所有项(由域名和值构成的元组)保存在.tis 文件中。项首先以域名的字母顺序排列,然后,同一域中的项以值的顺序排列。每个项条目包含了它的文档频率:段中包含该项的文档数量。
图B.3展示的只将我们的索引中项的一部分作为了例子,这些项是来自每个域中的一个或多个项。读者可能注意到域 url 并不在其中,因为它是作为一个 UnIndexed 域来添加的,所以只被存储而不能作为一个有效的项。没有显示出来的是.tii 文件,该文件是.tis文件的一个具体实例,它被设计用来保存在物理存储中以实现对.tis文件的随机访问。对于.tis 文件中的每个项, .frg文件的内容有包含了项的每个文档的条目。
在我们的范例索引中,两本书籍在内容域中含有值“junit”: JUnit in Action(文档6)和 Java Development with Ant (文档5)。
项频率
每个文档中的项频率在.frq文件列出。在我们的范例索引中,文档 Java Developmentwith Ant (文档5)在内容域 (contents field) 的值出现了一次“junit”。 JUnit in Action (文档6)中“junit”出现了两次,一次在标题中,一次在主题里面。我们的内容域是标题,主题和作者三者的一个结合体。文档中项的频率是计算评分的一个因子(详情查看3.3小节),通常更高的出现频率也会增强文档的相关度。
对于每个在.frq文件列出的文档,位置文件(.prx 文件)包含了每个项在文档中的每次出现记录的条目。
项位置
.prx 文件列出了文档中每个项的位置。在执行如短语查询和跨度查询(span query)等查询操作时,就会使用位置信息。经过语汇单元化的域的位置信息直接来源于分析过程指定的语汇单元位置(token position) 增量。
图 B.3显示了3个位置,每一个都是项 junit 出现的位置。第一次出现的位置是在文档5 (Java Development with Ant) 的位置9。在文档5中,该域值(经过分析之后)为“java development ant apache jakarta ant build tool junit java development erik hatcher steveloughran”, 我们用类 StandardAnalyzer 来分析,从而停用词(用 Java Development with Ant作为例子)被移除而不会占用位置信息(请见4.7.3小节中关于停用词移除和位置信息的详细内容)。文档6——JUnit in Action 的内容域中“junit”出现了两次,一次在位置1,另一次在位置了:“junit action junit unit testing mock objects vincent massol ted husted”①
B.5小结
索引结构的基本原理分为两个部分:性能的最大化和资源利用的最小化。
例如,如果一个域未被索引,通过操作可以很快地基于.fnm 文件中的索引标记从查询中完全去除整个域。
.tii 文件缓存在内存中,这是为了快速随机存取项词典.tis文件。
如果项本身不出现,短语和跨度查询不需要查找位置信息。这些信息在很多情况下需要串行化,并且在搜索过程中将访问文件的数量最小化也是需要考虑的问题。这些只是如何很好地考虑索引结构设计的一些例子。
如果你对这种底层的优化非常感兴趣,请参阅 Lucene 的 web 站点关于 Lucene 索引文件格式的具体内容,在那里可以找到我们在这里略过的一些细节。
参考资料
《Lucene in Action II》
