背景
进行市场的商品售卖,要避免出现超卖的现象。
最近在做一个关于库存服务的设计方案,在网上找了很多资料,都没有一个大而全的设计方案,于是就参考网上现有的电商库存设计,设计出一个自认为非常优秀的关于库存服务扣减的方案,仅供大家参考。
设计流程图
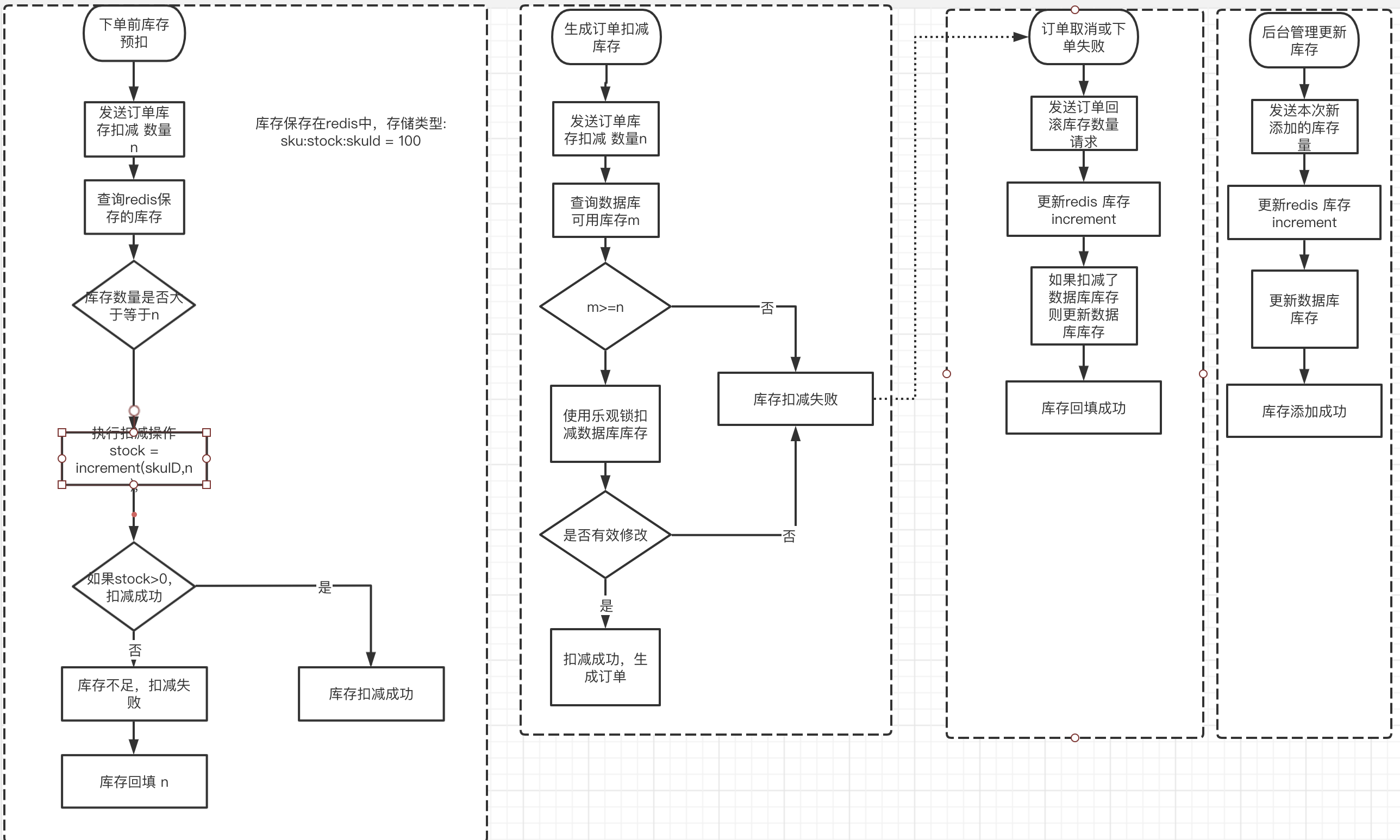
设计思路
为了扛住高并发,我这里在两个地方做了库存扣减,第一个使用redis做预扣库存,第二个是数据库扣除实际库存;
用户提交订单时,做的是reids中库存预扣,只有当实际支付完成后,才会做数据库层的库存扣减。
在用户提交订单时、支付完成时、订单取消或下单失败时、运营更新商品时,都会涉及到库存的操作,所以本文分别就这几种场景,设计出对应的库存扣减逻辑。
用户提交订单时库存预扣
(1)查询redis当前的库存
库存数量大于等于购买数量n,则继续后续操作
如果小于,则库存扣减失败,订单创建失败
(2)调用redis的原子方法(increment),执行扣减操作stock = increment(skuID,-n );
如果stock>=0,则代表扣减成功,则库存预扣成功,订单创建成功
否则库存扣减失败,订单创建失败,再次调用increment(skuID,+n ),重要的一步是将redis库存回填
用户支付完成时扣除实际库存
为什么要在用户支付完成后才实际的扣减库存呢?而不是下单时直接扣减实际库存呢?
优点:
防止用户支付前取消订单,进行库存回填的时候,还得操作实际库存,增加库存不一致的风险
为了提高并发,因为特别是在并发量比较大的时候,如果在下单时直接操作数据库库存,会导致创建订单花费的时间更长
防止用户恶意下单,不支付,占用库存(主要原因)
缺点:
用户支付时,有可能会出现库存不足,给用户造成不好的购物体验。
订单取消/下单失败,库存回滚
这里其实需要分为不同场景:
订单未支付前:订单取消或下单失败,则只需要回填redis库存
订单已经支付完成:订单取消/下单失败,则需要回填redis和数据库库存,并执行退款。
运营更新商品,操作库存
redis库存增加:使用increment(skuID,+n );原子操作更新库存
数据库库存增加:使用乐观锁进行更新。
每日凌晨定时维护redis与数据库的库存数量
为了防止redis和数据的库存出现不一致的情况,每天都需要进行检查;
库存以数据库中实际库存为主,将数据库中的库存减去未支付订单扣减的库存,更新到 redis 中。
关于订单库存扣减的最佳实践
一: 背景
在电商的业务场景中每个商品都是有库存的,而且可能存在很多限售的运营策略。
我们团队面临社区电商的业务场景更为复杂
。不仅仅是库存限售,存在区域,门店,用户,运营分组,物流等的限售策略。
如何面对日单量千万级别(未来更多),和多个维度的限售策略而不超卖,少卖是一个必须解决的问题。
下面就是库存扣减的流程图。
冲图种我们可以看出,要保证整个扣减库存不出问题,限购查询和库存的扣减必须是原子性的而且要单线程执行。
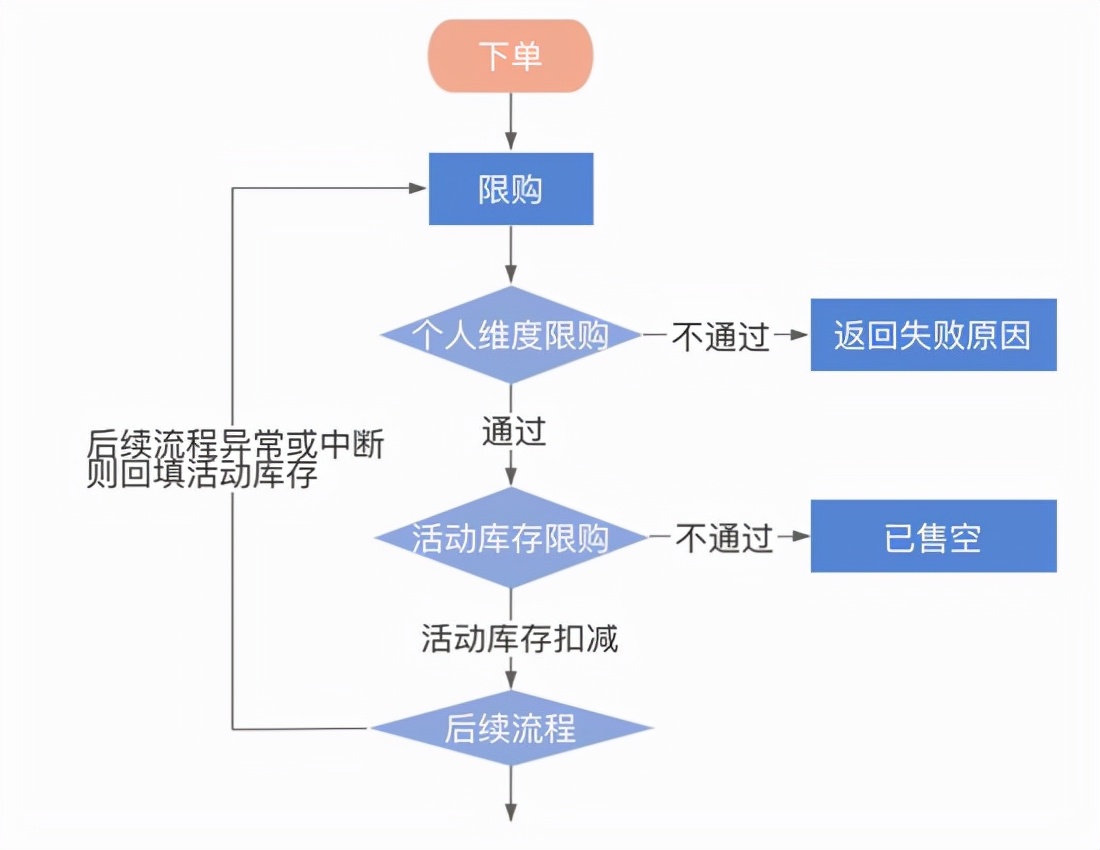
现在处理这种场景存在多种方案。但是要保证高性能和高可用,大部分方案并不满足。
二:探索
1. 历史数据库的事务特性和唯一主键的实现原子操作和单线程操作
基于数据库的事务,扣减库存的操作方法同一个事务中进行库存扣减,事务中任何操作失败,执行回滚操作。
从而保证原子性。单纯靠数据库的事务,只能在单体的项目中。如何要分布式的项目中,就无法保证单线程操作了。
那如何在多进程中实现单线程扣减库存呢?我们可以利用数据库的唯一索引。
具体操作步骤:
新建立一张表:
t_lock_tbl,同时将商品ID作为唯一索引。
进行扣减库存之前在表中插入商品ID,然后进行数据库更新。
更新结束后上次刚才插入数据库中的记录,释放锁。
A线程进程扣减库存时候,插入了该商品的id,当B线程扣减该商品的库存的时候,同样也会在数据库中插入该商品ID,A线程没有执行完B线程插入同一个商品ID就会报主键重复的错误,这样就扣减库存失败。
这种方案,功能上是可以实现,但是过分依赖数据库,无法满足性能要求,而且存在很多获取锁失败的情况,用户体验差。
2. 利用分布式锁
Redis 或者 ZooKeeper 来实现一个分布式锁,以商品维度来加锁,在获取到锁的线程中,按顺序去执行商品库存的查询和扣减,这样就同时实现了顺序性和原子性。
其实这个思路是可以的,只是不管通过哪种方式实现的分布式锁,都是有弊端的。
以 Redis 的实现来说,仅仅在设置锁的有效期问题上,就让人头大。
如果时间太短,那么业务程序还没有执行完,锁就自动释放了,这就失去了锁的作用;而如果时间偏长,一旦在释放锁的过程中出现异常,没能及时地释放,那么所有的业务线程都得阻塞等待直到锁自动失效,这样可能导致CPU飙升,系统吞吐量下降。
这与我们要实现高性能的系统是相悖的。
所以通过分布式锁的方式可以实现,但不建议使用。
3. Redis + lua 脚本
reids,单线程支持顺序操作,而且性能优异,但是不支持事务回滚。
但是通过redis+lua脚本可以实现redis操作的原子性。
这种方案同时满足顺序性和原子性的要求了。
这里能帮我们实现 Redis 执行 Lua 脚本的命令有两个,一个是 EVAL,另一个是 EVALSHA。
原生 EVAL 方法的使用语法如下:
EVAL script numkeys key [key ...] arg [arg ...]
其中 EVAL 是命令,script 是我们 Lua 脚本的字符串形式,numkeys 是我们要传入的参数数量,key 是我们的入参,可以传入多个,arg 是额外的入参。
但这种方式需要每次都传入 Lua 脚本字符串,不仅浪费网络开销,同时 Redis 需要每次重新编译 Lua 脚本,对于我们追求性能极限的系统来说,不是很完美。
所以这里就要说到另一个命令 EVALSHA 了,原生语法如下:
EVALSHA sha1 numkeys key [key ...] arg [arg ...]
可以看到其语法与 EVAL 类似,不同的是这里传入的不是脚本字符串,而是一个加密串 sha1。这个 sha1 是从哪来的呢?它是通过另一个命令 SCRIPT LOAD 返回的,该命令是预加载脚本用的,语法为:
SCRIPT LOAD script
这样的话,我们通过预加载命令,将 Lua 脚本先存储在 Redis 中,并返回一个 sha1,下次要执行对应脚本时,只需要传入 sha1 即可执行对应的脚本。
这完美地解决了 EVAL 命令存在的弊端,所以我们这里也是基于 EVALSHA 方式来实现的。
既然有了思路,也有了方案,那我们开始用代码实现它吧。首先我们根据以上介绍的库存扣减核心操作,完成核心 Lua 脚本的编写。
其主要实现的功能就是查询库存并判断库存是否充足,如果充足,则做相应的扣减操作,脚本内容如下:
-- 调用Redis的get指令,查询活动库存,其中KEYS[1]为传入的参数1,即库存key
local c_s = redis.call('get', KEYS[1])
-- 判断活动库存是否充足,其中KEYS[2]为传入的参数2,即当前抢购数量
if not c_s or tonumber(c_s) < tonumber(KEYS[2]) then
return 0
end
-- 如果活动库存充足,则进行扣减操作。其中KEYS[2]为传入的参数2,即当前抢购数量
redis.call('decrby',KEYS[1], KEYS[2])
然后我们将 Lua 脚本转成字符串,并添加脚本预加载机制。
预加载可以有多种实现方式,一个是外部预加载好,生成了 sha1 然后配置到配置中心,这样 Java 代码从配置中心拉取最新 sha1 即可。
另一种方式是在服务启动时,来完成脚本的预加载,并生成单机全局变量 sha1。
我们这里先采取第二种方式,代码结构如下图所示:
总结
技术的角度分析了库存超卖发生的两个原因。一个是库存扣减涉及到的两个核心操作,查询和扣减不是原子操作;另一个是高并发引起的请求无序。
所以我们的应对方案是利用 Redis 的单线程原理,以及提供的原生 EVALSHA 和 SCRIPT LOAD 命令来实现库存扣减的原子性和顺序性,并且经过实测也确实能达到我们的预期,且性能良好,从而有效地解决了秒杀系统所面临的库存超卖挑战。
以后再遇到类似的问题,你也可以用同样的解决思路来应对。
基于 redis 的秒杀方案
Redis预减库存
主要思路减少对数据库的访问,之前的减库存,直接访问数据库,读取库存,当高并发请求到来的时候,大量的读取数据有可能会导致数据库的崩溃。
思路:
系统初始化的时候,将商品库存加载到Redis 缓存中保存
收到请求的时候,现在Redis中拿到该商品的库存值,进行库存预减,如果减完之后库存不足,直接返回逻辑Exception就不需要访问数据库再去减库存了,如果库存值正确,进行下一步
将请求入队,立即给前端返回一个值,表示正在排队中,然后进行秒杀逻辑,后端队列进行秒杀逻辑,前端轮询后端发来的请求,如果秒杀成功,返回秒杀,成功,不成功就返回失败。
(后端请求 单线程 出队,生成订单,减少库存,走逻辑)前端同时轮询
前端显示
第一步:预减库存
/**
* 秒杀接口优化之--- 第一步: 系统初始化后就将所有商品库存放入 缓存
*/
@Override
public void afterPropertiesSet() throws Exception {
List<GoodsVo> goods = goodsService.getGoodsList();
if (goods == null) {
return;
}
for (GoodsVo goodsVo : goods) {
redisService.set(GoodsKey.getGoodsStock, "" + goodsVo.getId(), goodsVo.getStockCount());
isOverMap.put(goodsVo.getId(), false);//先初始化 每个商品都是false 就是还有
}
}
/**秒杀接口优化之 ----第二步:预减库存 从缓存中减库存
* 利用 redis 中的方法,减去库存,返回值为 减去1 之后的值
* */
long stock = redisService.decr(GoodsKey.getGoodsStock, "" + goodsId);
/*这里判断不能小于等于,因为减去之后等于 说明还有是正常范围*/
if (stock < 0) {
isOverMap.put(goodsId, true);//没有库存就设置 对应id 商品的map 为true
return Result.error(CodeMsg.MIAO_SHA_NO_STOCK);
}
预减库存:
1.先将所有数据读出来,初始化到缓存中,并以 stock + goodid 的形成存入Redis
2.在秒杀的时候,先进行预减库存检测,从redis中,利用decr 减去对应商品的库存,如果库存小于0,说明此时 库存不足,则不需要访问数据库。直接抛出异常即可。
内存标记:
由于接口优化很多基于Redis的缓存操作,当并发很高的时候,也会给Redis服务器带来很大的负担,如果可以减少对Redis服务器的访问,也可以达到的优化的效果。
于是,可以加一个内存map,标记对应商品的库存量是否还有,在访问Redis之前,在map中拿到对应商品的库存量标记,就可以不需要访问Redis 就可以判断没有库存了。
1.生成一个map,并在初始化的时候,将所有商品的id为键,标记false 存入map中。
private Map<Long, Boolean> isOverMap = new HashMap<Long, Boolean>();
/**
* 秒杀接口优化之--- 第一步: 系统初始化后就将所有商品库存放入 缓存
*/
@Override
public void afterPropertiesSet() throws Exception {
List<GoodsVo> goods = goodsService.getGoodsList();
if (goods == null) {
return;
}
for (GoodsVo goodsVo : goods) {
redisService.set(GoodsKey.getGoodsStock, "" + goodsVo.getId(), goodsVo.getStockCount());
isOverMap.put(goodsVo.getId(), false);//先初始化 每个商品都是false 就是还有
}
}
/**再优化:优化 库存之后的请求不访问redis 通过判断 对应 map 的值
* */
boolean isOver = isOverMap.get(goodsId);
if (isOver) {
return Result.error(CodeMsg.MIAO_SHA_NO_STOCK);
}
if (stock < 0) {
isOverMap.put(goodsId, true);//没有库存就设置 对应id 商品的map 为true
2.在预减库存之前,从map中取标记,若标记为false,说明库存
3.预减库存,当遇到库存不足的时候,将该商品的标记置为true,表示该商品的库存不足。这样,下面的所有请求,将被拦截,无需访问redis进行预减库存。
参考资料
https://blog.csdn.net/weixin_34311210/article/details/119011222
