Hypertable
Hypertable 是一个使用 C++语言开发的开源、高性能、可伸缩的数据库,其以 Google的 BigTable 相关论文为基础指导,采用与 HBase 非常相似的分布式模型,其目的是要构建一个针对分布式海量数据的高并发数据库。
概述
目前 Hypertable 只支持最基本的添、删、改、查功能,对于事务处理和关联查询等关系型数据库的高级特性都尚未支持。
同时,就少量数据记录的查询性能和吞吐量而言,Hypertable 可能也不如传统的关系型数据库。
和传统关系型数据库相比,Hypertable 最大的优势在于以下几点。
-
支持对大量并发请求的处理。
-
支持对海量数据的管理。
-
扩展性良好,在保证可用性的前提下,能够通过随意添加集群中的机器来实现水平扩容。
-
可用性极高,具有非常好的容错性,任何节点的失效,既不会造成系统瘫痪也不会影响数据的完整性。
Hypertable的整体架构如图3-3所示。
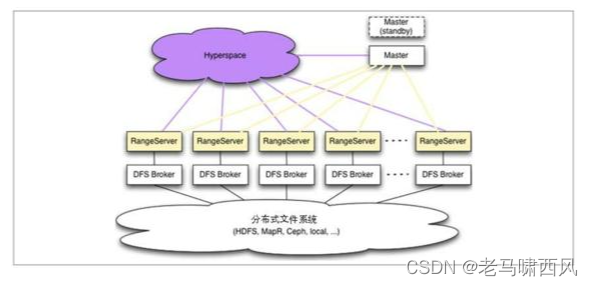
图3-3.Hypertable整体架构图
Hypertable的核心组件包括Hyperspace、RangeServer、Master和DFS Broker四部分。
其中Hyperspace是Hypertable中最重要的组件之一,其提供了对分布式锁服务的支持以及对元数据的管理,是保证 Hypertable 数据一致性的核心。Hyperspace 类似于 Google BigTable 系统中的 Chubby,在这里我们可以认为它是一个文件存储系统,主要用来存储一些元数据信息,同时提供分布式锁服务,另外还负责提供高效、可靠的主机选举服务。
RangeServer 是实际对外提供服务的组件单元,负责数据的读取和写入。在 Hypertable的设计中,对每一张表都按照主键进行切分,形成多个Range(类似于关系型数据库中的分表),每个 Range由一个 RangeServer(RangeServer调用 DFSBroker来进行数据的读写)负责管理。
在Hypertable中,通常会部署多个RangeServer,每个RangeServer都负责管理部分数据,由Master来负责进行RangeServer的集群管理。
Master是元数据管理中心,管理包括创建表、删除表或是其他表空间变更在内的所有元数据操作,同时负责检测 RangeServer 的工作状态,一旦某一个 RangeServer 宕机或是重启,能够自动进行Range的重新分配,从而实现对RangeServer集群的管理和负载均衡。
DFS Broker则是底层分布式文件系统的抽象层,用于衔接上层Hypertable和底层文件存储。所有对文件系统的读写操作,都是通过 DFS Broker 来完成的。
目前已经可以接入Hypertable中的分布式文件系统包括HDFS、MapR[7]、Ceph[8]和KFS[9]等,针对任何其他新的文件系统,只需要实现一个对应的 DFS Broker,就可以将其快速接入到整个Hypertable系统中。
算法实现
从上面的讲解中我们了解到,Hyperspace是整个Hypertable中最为核心的部分之一。
基于对底BDB的封装,通过对Paxos算法的实现,Hyperspace能够很好地保证Hypertable中元数据的分布式一致性。
接下来我们就看看Hyperspace是如何实现分布式数据一致性的。
Active Server
Hyperspace通常以一个服务器集群的形式部署,一般由5~11台服务器组成,在运行过程中,会从集群中选举产生一个服务器作为 Active Server,其余的服务器则是 Standby Server,同时,Active Server和Standby Server之间会进行数据和状态的实时同步。
在Hypertable启动初始化阶段,Master模块会连接上Hyperspace集群中的任意一台服务器,如果这台 Hyperspace 服务器恰好处于 Active 状态,那么便完成了初始化连接;如果连接上的Hyperspace服务器处于Standby状态,那么该Hyperspace服务器会在此次连接创建后,将当前处于Active状态的Hyperspace服务器地址发送给Master模块,Master模块会重新与该Active Hyperspace服务器建立连接,并且之后对Hyperspace的所有操作请求都会发送给这个Hyperspace服务器。换句话说,只有Active Hyperspace才能真正地对外提供服务。
事务请求处理
在Hyperspace集群中,还有一个非常重要的组件,就是BDB。BDB服务也是采用集群部署的,也存在Master的角色,是Hyperspace底层实现分布式数据一致性的精华所在。
在Hyperspace对外提供服务时,任何对于元数据的操作,Master模块都会将其对应的事务请求发送给 Hyperspace 服务器。
在接收到该事务请求后,Hyperspace 服务器就会向BDB集群中的Master服务器发起事务操作。BDB服务器在接收到该事务请求后,会在集群内部发起一轮事务请求投票流程,一旦 BDB 集群内部过半的服务器成功应用了该事务操作,就会反馈 Hyperspace 服务器更新已经成功,再由 Hyperspace 响应上层的Master模块。
举个例子来说,假设有一个由5台服务器组成的Hyperspace集群,其Active Hyperspace在处理一个建表请求时,需要获得至少 3 台 BD B 服务器的同意才能够完成写入。
虽然这样的事务更新策略显然会严重影响其对写操作的响应速度,但由于其存入的元数据更新并不特别频繁,因此对写性能的影响还在可接受的范围内——毕竟数据的可靠一致才是最重要的。
Active Hyperspace选举
当某台处于 Active 状态的 Hyperspace 服务器出现故障时,集群中剩余的服务器会自动重新选举出新的Active Hyperspace,这一过程称为Hyperspace集群的Active选举。
Active选举过程的核心逻辑就是根据所有服务器上事务日志的更新时间来确定哪个服务器的数据最新——事务日志更新时间越新,那么这台服务器被选举为Active Hyperspace的可能性就越大,因为只有这样,才能避免集群中数据不一致情况的发生。
完成 Active Hyperspace选举之后,余下所有的服务器就需要和Active Hyperspace服务器进行数据同步,即所有Hyperspace服务器对应的BDB数据库的数据都需要和Master BDB保持一致。
从上面的讲解中我们可以看出,在整个Hyperspace的设计中,为了使整个集群能够正常地对外提供服务,那么就必须要求Hyperspace集群中至少需要有超过一半的机器能够正常运行。
另外,在 Hyperspace集群正常对外提供服务的过程中,只有Active Hyperspace才能接受来自外部的请求,并且交由底层的 BDB 事务来保证一致性——这样就能够保证在存在大量并发操作的情况下,依然能够确保数据的一致性和系统的可靠性。
小结
对于不少工程师来说,Paxos 算法本身晦涩难懂的算法描述,使得学习成本非常高,但Paxos 算法超强的容错能力和对分布式数据一致性的可靠保证,使其在工业界得到了广泛的应用。
本章通过对Google Chubby和Hypertable这两款经典的分布式产品中Paxos算法应用的介绍,向读者阐述了Paxos算法在实际工业实践中的应用,为读者更好地理解Paxos算法提供了帮助。
拓展阅读
参考资料
《分布式一致性原理与实践》
