现象
实时链路,同时支持多个 oracle/mysql 的数据源配置
然后,发现 oracle dump 大量的内存数据信息,导致频繁的 GC。
其中占比比较大的一个对象就是 oracle.jdbc.driver.BufferCache
个人解决方式
-
移除 fetchSize 设置
-
druid 添加连接属性
oracle.jdbc.maxCachedBufferSize=10485761MB 的缓存大小。
效果
待发布验证。
内存 dump
个人的情况和 JDBC BufferCache内存占用过高致docker容器被k8s kill(OOMKilled)问题排查 比较类似,记录一下。
dump 文件
在物理内存快满了的时候,生成了堆快照:
jmap -dump:live,format=b,file=/tmp/dump.hprof <pid>
将dump文件下载到了本地,使用Eclipse Memory Analyzer分析:
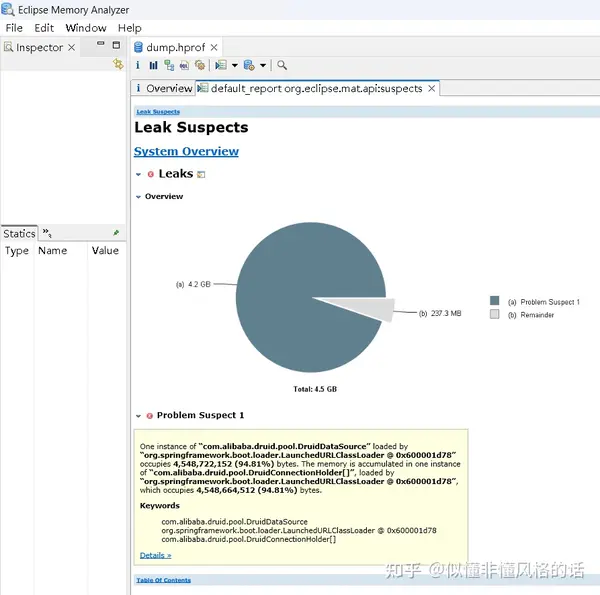
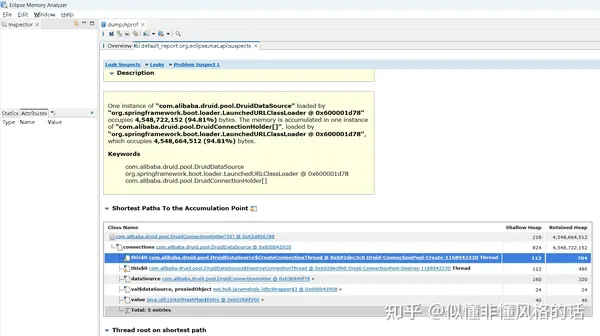
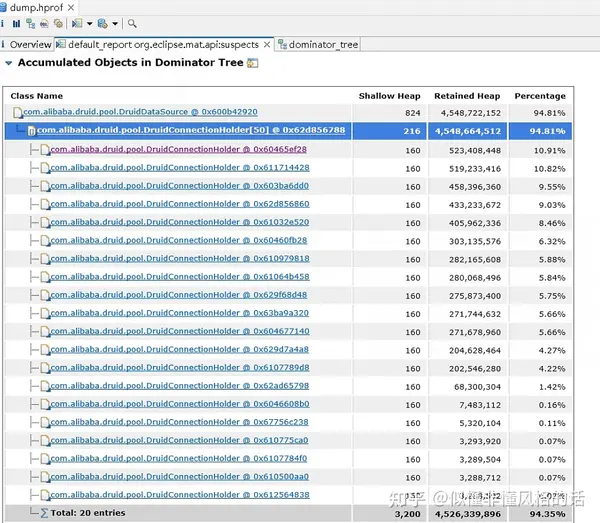
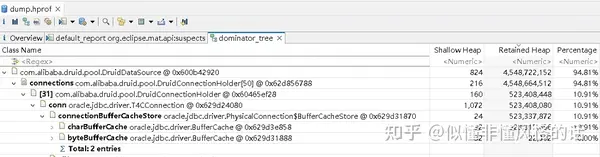
4G多的内存(94.81%)都被数据库连接(20个)的charBufferCache占用了:
DruidDataSource(com.alibaba.druid.pool.DruidDataSource)->
connections(com.alibaba.druid.pool.DruidConnectionHolder[50])->
[31](com.alibaba.druid.pool.DruidConnectionHolder)->
conn(oracle.jdbc.driver.T4Connection)->
connectionBufferCacheStore(oracle.jdbc.driver.PhysicalConnection$BufferCacheStore)->
charBufferCache(oracle.jdbc.driver.BufferCache)
查资料
搜了下Oracle JDBC和Druid内存相关问题:
1、在github Druid项目Issues中,搜”内存”、”DruidDataSource”等关键词,发现了类似但不一样的问题。
com.alibaba.druid.pool.DruidDataSource 内存溢出 v1.1.10 · Issue #2772 · alibaba/druid · GitHub
生产环境使用Druid内存很高,通过mat分析如下 · Issue #3039 · alibaba/druid · GitHub
2、在搜索引擎中搜索“oracle.jdbc.driver.BufferCache memory”,搜到了Oracle JDBC Memory Management 12c.pdf文档、JDBC Developer’s Guide(19c)
- jdbc-memory-management-12c.pdf
管理缓冲区大小
用户可以做几件事来管理这些缓冲区使用的内存量。
1仔细定义表
2仔细编码查询
3仔细设置fetch Size
当VARCHAR2(20)可以实现时,将列定义为VARCHAR2(4000)对10i和11g驱动程序有很大的不同。VARCHAR2(4000)列每行需要8K字节。VARCHAR2(20)列每行只需要40字节。如果列实际上不超过20个字符,那么10i或11g驱动程序为VARCHAR2(4000)列分配的大部分缓冲区空间都被浪费了。这对12c驱动程序没有影响。
当只需要几个列时,做SELECT*有很大的性能影响,除了buffer的大小。获取行内容、转换行内容、通过网络发送行内容并将其转换为Java表示需要一些时间。当只需要一些列时返回几十列,会迫使10i和11g驱动分配大的缓冲区来存储那些不需要的结果。它强制12c驱动为实际的列值分配存储空间。虽然这可能比10i和11g要小,但仍然是一种浪费。12c驱动程序必须为每个值分配15个字节,即使是nul1。
控制内存使用的主要工具是fetchSize。虽然2MB相当大,但大多数Java环境在分配这个大小的缓冲区时不会遇到任何问题。如果fetchSize设置为1,即使Oracle数据库最坏的结果是255个VARCHAR2(4000)列,在大多数应用程序中也不会有问题。Oracle数据库最坏的情况是1000VARCHAR2(32000),需要10i和11g驱动程序为每行分配64MB。即使fetchSize为1,对于许多Java环境来说,这也可能是一个问题。12c驱动程序只会分配存储实际数据所需的内存。
解决内存使用问题的第一步是回顾SQL。为每个查询计算每行的大致大小,并查看取指大小。如果每行的大小非常大,考虑是否有可能获取更少的列,或者修改模式以更严格地限制数据大小。最后设置取指大小,使缓冲区保持在合理的大小。什么是“合理”取决于应用程序的细节。
Oracle建议fetchSize不超过100,尽管在某些情况下更大的大小可能是合适的。100的fetchSize对于某些查询来说可能太大了,即使返回了很多行。
Oracle数据库发布11.1.0.7.0 Oracle JDBC驱动程序
11.1.0.7.0驱动引入了一个连接属性来解决大缓冲区问题。该属性限制了将保存在缓冲区缓存中的缓冲区的最大大小。当将PreparedStatement放入隐式语句缓存中时,将释放所有较大的缓冲区,并在从缓存中检索PreparedStatement时重新分配缓冲区。如果大多数PreparedStatements需要一个中等大小的缓冲区,例如小于100KB,但有一些需要更大的缓冲区,那么将属性设置为110KB就可以重用经常使用的小缓冲区,而不会增加分配许多最大大小缓冲区的负担。设置此属性可以提高性能,甚至可以防止 outofmemoryexception异常。
connection属性为 oracle.jdbc.maxCachedBufferSize
它的值是一个int字符串,例如"100000"。默认值为Integer.MAX_VALUE。这是存储在内部缓冲区缓存中的缓冲区的最大大小。char[]和byte[]缓冲区都使用同一个大小。
char[]缓冲区的大小以char为单位,byte[]缓冲区的大小以bytes为单位。它是缓冲区的最大大小,而不是预定义的大小。如果maxCachedBufferSize设置为100KB,但小于100KB的最大缓冲区大小仅为50KB,则缓冲缓存中的缓冲区将为50KB。maxCachedBufferSize值的变化只有在驱动程序的内部缓存中包含或排除char[]和byte[]缓冲区时才会对性能产生影响。巨大的变化,即使是兆字节的变化,可能也不会有什么区别。同样,当更改1导致包含或排除PreparedStatement的缓冲区时,也会产生差异。此属性可以通过-D设置为系统属性,也可以通过getConnection设置为连接属性。
如果需要设置maxCachedBufferSize,首先估计需要最大缓冲区的SQL查询的缓冲区大小。在这个过程中,你可能会发现,通过调整这些查询的权指大小懂非通以实现所需的性能。考虑到频率
代码的差异
检查了下代码,定时任务的功能与其它功能的查询,差异主要在select时用到了fetchSize,fetchSize是之前性能优化时加的
大概伪代码如下:
String sql = "select id, name from table";
PreparedStatement preparedStatement = dataSource.getConnection().prepareStatement(sql);
preparedStatement.setFetchSize(99999);
preparedStatement.executeQuery();
这里的 fetchSize 默认指定了一个 99999 的值,本来是为了避免结果值太大,现在感觉估计有问题。
问题修复:
项目中druid数据库连接池配置:
spring.datasource.druid.driverClassName=oracle.jdbc.driver.OracleDriver
spring.datasource.druid.min-idle=5
spring.datasource.druid.max-active=50
spring.datasource.druid.initial-size=5
spring.datasource.druid.keep-alive=true
项目中使用的JDBC驱动是ojdbc6(适合Oracle 12c+JDK6),实际项目连的Oracle数据库是19c,所以将JDBC驱动升级到ojdbc10(适合Oracle数据库是19c+JDK11),且将druid版本由12.11升级到最新版本(12.2.20)。
并将driverClassName由oracle.jdbc.driver.OracleDriver替换为oracle.jdbc.OracleDriver,关闭了druid的监控,启用了prepared-statements缓存,由于主要是数据库连接池中的连接占用的内存,所以缩短max-evictable-idle-time-millis时间为1小时(默认7小时),加快连接池中空闲连接的close。
spring.datasource.druid.filter.stat.enabled=false
spring.datasource.druid.filter.config.enabled=false
spring.datasource.druid.web-stat-filter.enabled=false
spring.datasource.druid.stat-view-servlet.enabled=false
spring.datasource.druid.pool-prepared-statements=true
spring.datasource.druid.max-pool-prepared-statement-per-connection-size=100
spring.datasource.druid.validation-query=SELECT 1 FROM dual
spring.datasource.druid.test-while-idle=true
spring.datasource.druid.min-evictable-idle-time-millis=1800000
spring.datasource.druid.max-evictable-idle-time-millis=3600000
spring.datasource.druid.time-between-eviction-runs-millis=60000
JVM参数:-Xms14g -Xmx14g -XX:MetaspaceSize=200m -XX:MaxMetaspaceSize=256m -XX:MaxDirectMemorySize=1024m -Xlog:gc*
重新部署项目,并观测内存使用情况:
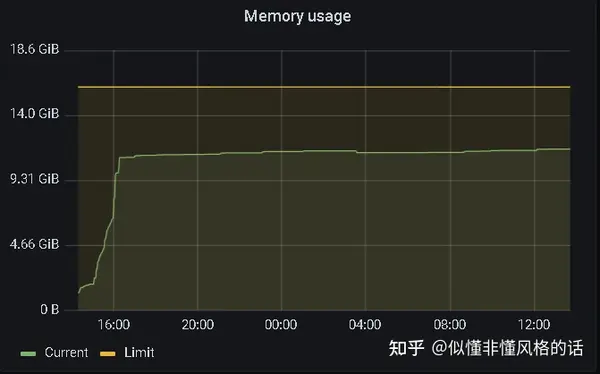
效果:物理内存在11.5G多的时候有下降(之前只增不降),且比较平稳,JVM内存每次GC基本上都降到了1G左右(之前GC是降到了3~5G左右,只有Full GC才会降到1.5G左右)
GC日志分析报告:优化前:gceasy.ycrash.cn,优化后:gceasy.ycrash.cn
Oracle JDBC Memory Management中的客户端缓存
对于oracle jdbc中,一个容易忽略的参数是:prepared-statement-cache-size,这次转来http://xulingbo.net/?p=109这篇好文,详细讲解了这个参数用法。
从Oracle10g开始在JDBC驱动中,增加了对执行每个Statement的缓存。目的就是对相同的SQL缓存其查询结果,从而提高查询的性能。这种缓存形式,在服务端做的比较多,但是Oracle是通过JDBC将结果缓存在离应用程序最近的地方(客户端),不知道其他数据库是否有同样的功能。
缓存的意义
为什么要通过Statement来缓存数据,这样做的前提是PreparedStatement或者是CallableStatement而不是Statement,因为前两者数据库可以根据用户提交的SQL做预编译,只要是SQL语句是一样的,数据库就认为是同一次查询,数据库就可以根据查询结果做缓存或者优化。那什么样的SQL语句数据库认为是一样的呢?如下面:
Select * from userinfo where username = 'junshan' and id = 1
Select * from userinfo where username = 'bobo' and id = 2
显然这两条SQL语句是不一样的,如果你通过下面这样执行
statement.execute("Select * from userinfo where username = 'junshan' and id = 1")
或者
statement.execute("Select * from userinfo where username = 'bobo' and id = 2")
数据库完全认为这是两个毫不相干的SQL操作,不仅要重新解释这个SQL,构造SQL语法树,语法树的优化,准备执行环境等等。所有这些操作都用做一遍。但是很明显这两个SQL除了参数不一样,其他都是一样的,而对数据库来说,唯一不同的是,只要在第一次查询出来的结果集中根据参数值重新过滤一下即可,而前面的SQL解释,构建语法树,甚至数据都可能不要在数据库中重新捞一把。
为此JDBC提供一种根据理想的PreparedStatement、和其子类CallableStatement。
他们就是将单纯的SQL语句和SQL中的参数值分开,然后将值再映射过去。
关于映射这一部分可以参数《深入分析Ibatis框架之系统架构与映射原理》。
这样数据库就可以根据单纯的SQL做更多优化。上面的SQL应该这样写更为合理
Connection conn= DriverManager.getConnection(url,user,password);
java.sql.PreparedStatement st = conn.prepareStatement("Select * from userinfo where username = ? and id = ?");
st.setString(0,'junshan');
st.setInt(1,1);
st.execute();
前面说到都是在数据库服务端,但是在Oracle10g以后的JDBC中,在客户端以做了数据的缓存,这里的缓存只是针对和一个PreparedStatement对应的数据的缓存。
这样做就可以让相同的SQL的执行完全不需要请求道数据库,达到更好的性能,但是这样必然会给客户端增加内存负担,在Oracle的官方说明中也提到了可能会导致严重的内存问题。
Oracle JDBC驱动如何缓存
下面看一下Oracle JDBC客户端如何缓存:
客户端可以指定缓存一定数量的Statement,每个Statement持有两个buffers,一个是byte[]一个是char[]。
这些buffers又在一个叫做Implicit Statement Cache的cache中。char[]主要是存储char类型的数据,而byte[]存储所有其他类型的数据。
当一个Statement被执行时这来两个buffer就将被创建,由于buffer创建是在获取数据之前,所以是不知道应该创建多大的buffer来存查询返回结果,为此只能按照Statement中申明的字段类型来分配buffer大小。
分配的规则就是声明的字段类占用的字节数乘以最大的存储数量如VARCHAR2(10)就是10*2 bytes其他的类型如NUMBER、DATE都是安装22bytes分配还有一些如CLOB、BLOB存储的是数据地址,最大地址空间能达到4k所以至少分配4K给他们。
10g的Oracle JDBC驱动程序,具有比以前的版本更大、更复杂的类层次结构。这些类的对象存储了更多的信息,所以需要更多的内存。这确实增加了内存的使用,但并这并不是真正的问题所在。真正的问题是用来存储查询结果的buffer。每个语句(包括PreparedStatement和CallableStatement的)都持有两个缓冲区,一个byte[](字节数组)和一个char [](字符数组)。char[]用来保存所有字符类型的行数据,如:CHAR,VARCHAR2,NCHAR等,byte[]用来保存所有的其它类型的行数据。这些buffer在在SQL被解析的时候分配,一般也就是在第一次执行该Statement的时候。Statement会持有这两个buffer,直到它被关闭。
由于buffer是在SQL解析的时候被分配的,buffer的大小并不取决于查询返回的行数据的实际长度,而是行数据可能的最大的长度。
在SQL解析时,每列的类型是已知的,从该信息中驱动程序可以计算存储每一列所需的内存的最大长度。
驱动程序也有fetchSize属性,也就是每次fetch返回的行数。有了每列有大小和行数的大小,驱动程序可以由此计算出一次fetch所返回的数据最大绝对长度。这也就是所分配的buffer的大小。
某些大类型,如LONG和LONG RAW,由于太大而无法直接存于buffer中会采取另外一种不同的处理方式。如果查询结果包含一个LONG或LONG RAW,将fetchSize设置为1之后,所遇见的内存问题就会变得明朗很多了。这种类型的问题不在这里讨论了。
字符数据存储在char[] buffer中。Java中的每个字符占用两个字节。一个VARCHAR2(10)列将包含最多10个字符,也就是10个Java的字符,也就是每行20个字节。一个VARCHAR2(4000)列将占用每行8K字节。重要的其实是column的定义大小,而不是实际数据的大小。一个VARCHAR2(4000)但是只包含了NULL的列,仍然需要每行8K字节。buffer是在驱动程序看到的查询结果之前被分配的,因此驱动程序必须分配足够的内存,以应付最大可能的行大小。一个定义为VARCHAR2(4000)的列最多可包含4000个字符。Buffer必须大到足以容纳4000个字符分配,尽管实际的结果数据可能没有那么大。
BFILE,BLOB和CLOB会被存储为locator。Locator可高达4K字节,每个BFILE,BLOB和CLOB列的byte[]必须有至少每行4K字节。
RAW列最多可以包含4K字节。其它类型的则需要很少的字节。一个合理的近似值是假设所有其它类型的列,每行占用22个字节。
范例
CREATE TABLE TAB (ID NUMBER(10), NAME VARCHAR2(40), DOB DATE)
ResultSet r = stmt.executeQuery("SELECT * FROM TAB");
当驱动器执行executeQuery方法,数据库将解析SQL。数据库会返回结果集将有三列:一个NUMBER(10),一个VARCHAR2(40),和一个DATE。第一列的需要(约)每行22个字节。第二列需要每行40个字符。第三列的需要(约)每行22个字节。
因此,每行需要 22 +(40 * 2)+ 22 = 124 个字节。
请记住,每个字符需要两个字节。fetchSize默认是10行,所以驱动程序将分配一个 char[] 10 * 40 = 400 个字符(800字节)和一个 byte[] 10 *(22 + 22)= 440 个字节,共1240字节。 1240字节不会导致什么内存问题。但有一些查询结果会比较更大一些。
在最坏的情况下,考虑一个返回255个VARCHAR(4000)列查询。每行每列需要8K字节。乘以255列,每行2040K字节也就是2MB。
如果fetchSize设置为1000行,那么驱动程序将尝试分配一个2GB的char[]。
这将是很糟糕的。
Oracle的建议是:
小心的定义每列的数据类型和最大的数据大小如不要每个VARCHAR2都需要定义为VARCHAR2(4000);还有就是设置fetchSize这个参数,就是分配多少行的缓存量,如有的SQL最多都是查询一行的数据你设置10行,那就是完全的浪费。
通常单个Statement引起的内存问题可能性有但是很小,最大的可能就是客户端会同时创建多个Statement并执行,还有一个潜在的问题就是缓存住Statement而不关闭,通常当Statement被关闭时这个 Statement持有的buffer也就被释放。
但是如果被缓存的Statement都是比较大的数据很可能会撑爆内存。
如果发现每条Statement分配的buffer较多,但是缓存的Statement数量有很多的话,就应该将缓存Statement的数量调小一点。
通常这个配置是下面的选项:
<datasources>
<local-tx-datasource>
<jndi-name>DB1DataSource_cm2</jndi-name>
<connection-url>jdbc:oracle:oci:@tbdb1_cm2</connection-url>
<connection-property name=”SetBigStringTryClob”>true</connection-property>
<connection-property name=”defaultRowPrefetch”>50</connection-property>
<driver-class>oracle.jdbc.driver.OracleDriver</driver-class>
<min-pool-size>2</min-pool-size>
<max-pool-size>3</max-pool-size>
<idle-timeout-minutes>10</idle-timeout-minutes>
<prepared-statement-cache-size>75</prepared-statement-cache-size>
<exception-sorter-class-name>org.jboss.resource.adapter.jdbc.vendor.OracleExceptionSorter</exception-sorter-class-name>
<metadata><type-mapping>Oracle9i</type-mapping></metadata>
<user-name>taobao</user-name>
<password>taobao</password>
<security-domain>EncryptDB1Password_cm2</security-domain>
</local-tx-datasource>
上面提到是在向数据库查询时Oracle驱动缓存的数据量。但是在写入时Oracle驱动同样会分配空间给写入的参数。但是这个数据和查询的数据相比会小很多。同时数据的实际大小也是知道的,不需要想查询时都是分配最大的数量。
但是如果是批量插入时Oracle为了提高执行性能不是按照每个Statement执行然后再重新配置另一个Statement的buffer而是同时缓存每个Statement的参数数据,然后一次执行所有的Statement,这样也可能会有大数据缓存的情况。但是这种情况在淘宝通常比较少爷容易控制。
不同版本的区别
Oracle10g的以后版本对上面的方式增加了更多的控制,更加灵活一点。
10.2.0.4这个版本增加了oracle.jdbc.freeMemoryOnEnterImplicitCache这个选项,这选项可以控制当Statement被缓存时,可以控制这个Statement的锁持有的buffer要不要也一起缓存。例如前面缓存75个Statement但是可以设置不缓存这75个Statement的buffer,也就是每当重新使用被缓存的Statement时,驱动会重新再分配buffer给他们。设为TRUE时在Statement被缓存之前会释放他持有的buffer,为FALSE将会同时缓存Statement的buffer,默认是FALSE。
11.1.0.6.0对Statement的buffer控制更加精准。与前面相比,这个版本将每个Statement的buffer转移出来,组合成一个buffer cache,上面意思呢?就是当某个Statement被缓存时,他持有的buffer将不再是有freeMemoryOnEnterImplicitCache控制,而是将其buffer放到buffer cache中,当这个Statement被重新使用时再从buffer cache中重新恢复出来,这样做的好处就是不需要每次Statement从缓存中回复时都用给他重新分配buffer了。这样做也有另一个问题:就是每个Statement持有的buffer都不一样,怎么能把这些buffer放到buffer cache 中。打个比喻就是首先建一个大水池,水池中有多个形状的水箱,这些水箱的形状是可以变化,然后根据使用情况重新组成一个水箱,使用时把这个水箱装的水打走,不使用时再将这个水箱和水一起放到这个大水池中。这样就能充分利用这个大水池的水了。
11.1.0.7.0这个版本在前面版本的基础上给buffer cache又增加了一个控制项 oracle.jdbc.maxCachedBufferSize,他就是控制在buffercache 中最大的buffer的大小。
Oracle驱动把个别非常大的buffer不保存在buffer cache中,这些比较大的buffer还是根据前面的方式当持有的Statement被缓存时释放buffer,当重新使用时再重新分配。
这种方式主要是优化了大水池的水的重复利用情况,防止水被少数几个大买家独占,而大部分小买家却老是没水喝。
这个版本中还有一个控制项是oracle.jdbc.useThreadLocalBufferCache,通常前面所说的buffer cache都是和一个connection像关联的,但是通常一个应用会建立多个connection,在pool中。但是通常一个客户端查询数据同一时刻都是通过一个线程来完成的,这样又可以将buffer cache关联到用户的线程而不是connection。
11.2中又增加了一个控制项是oracle.jdbc.implicitStatementCacheSize,他可以控制statement cache的大小。默认是0。
以上说的这些控制项都可以通过OracleConnection.setXXX来设置。
此外,在http://www.dbafree.net/?p=287中提到:
BaseWrapperManagedConnection是一个连接管理的抽象类,对于每一个数据库的连接,都有独立的PreparedStatementCache。
在ORACLE数据库中,使用PreparedStatementCache能够显著的提高系统的性能,前提是SQL都使用了绑定变量,因为对于ORACLE数据库而言,在PreparedStatementCache中存在的SQL,不需要open cursor,可以减少一次网络的交互,并能够绕过数据库的解析,即所有的SQL语句,不需要解析即可以直接执行。但是PreparedStatementCache中的PreparedStatement对象会一直存在,并占用较多的内存。
在MYSQL数据库中,因为没有绑定变量这个概念,MYSQL本身在执行所有的SQL之前,都需要进行解析,因此在MYSQL中这个值对性能没有明显的影响,这个值可以不设置,但是我觉得设置了这个值,可以避免在客户端频繁的创建PreparedStatement,并且对于相同的SQL,可以避免从服务器频繁的获取metadata,也有一定的好处(这是我所知道益处,总的来说,意义并没有ORACLE那么大)。
另外,PreparedStatementCache也不是设置越大越好,毕竟,PreparedStatementCache是会占用JVM内存的。
之前出现过一个核心系统因为在增加了连接数(拆分数据源)后,这个参数设置没有修改,导致JVM内存被撑爆的情况。
(JVM内存占用情况=连接总数*PreparedStatementCache设置大小*每个PreparedStatement占用的平均内存)
补充:关于MYSQL的PreparedStatement,其C API中也提供了这个方法(mysql_prepare, mysql_execute and mysql_real_query),但是其具体实现,我并不清楚,不过可以肯定的时,能带来的性能提升并不会很大,这个我也实际测试过。
可以用下面这句话来解释:prepared statement只需要获取数据库SQL的metadata一次,而 statement必需每次都获取一下metadata。
这应该就是MYSQL中(也包含其它所有的数据库)的主要区别
chat
详细介绍一下 oracle jdbc 的 fetchSize
在 Oracle JDBC 中,fetchSize 是一个重要的参数,用于控制从数据库中一次性获取的行数。它影响性能,特别是在处理大量数据时。fetchSize 参数决定了 JDBC 驱动程序在每次从数据库读取数据时,向数据库服务器请求多少行。调整 fetchSize 可以优化查询的执行速度和内存使用。
主要概念
- 默认行为:
- 当你执行查询时,JDBC 驱动程序默认一次只获取一定数量的行,默认值依赖于驱动实现。Oracle JDBC 驱动的默认值通常是 10 行。
- 也就是说,如果你执行一个返回 1000 行结果的查询,JDBC 会先从数据库获取前 10 行,然后在你消费这些行时再继续获取下一批,直到所有数据被读取。
- fetchSize 作用:
- 通过设置
fetchSize,你可以控制每次从数据库获取的行数。这可以减少网络往返次数,从而提高性能,特别是在处理大规模查询时。 - 如果
fetchSize设得过小,JDBC 将频繁地与数据库进行通信,导致网络开销增加。如果设得过大,可能会消耗过多的内存,因为一次性加载了太多的数据。
- 通过设置
使用方法
你可以通过以下方式设置 fetchSize:
Statement stmt = connection.createStatement();
stmt.setFetchSize(50); // 设置每次从数据库获取 50 行
ResultSet rs = stmt.executeQuery("SELECT * FROM your_table");
while (rs.next()) {
// 处理结果
}
或者,对于 PreparedStatement,用法是类似的:
PreparedStatement pstmt = connection.prepareStatement("SELECT * FROM your_table");
pstmt.setFetchSize(100); // 设置 fetchSize 为 100
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
// 处理结果
}
fetchSize 对性能的影响
- 网络开销:
- 设置较大的
fetchSize可以减少客户端与数据库之间的往返通信次数。如果你的网络延迟较高,较大的fetchSize可以明显减少延迟对查询速度的影响。
- 设置较大的
- 内存消耗:
- 较大的
fetchSize会增加客户端的内存消耗,因为需要在内存中缓存更多的数据行。对于非常大的查询,可能会导致内存不足问题。因此需要平衡fetchSize的大小,以适应具体的内存和性能需求。
- 较大的
- 性能优化场景:
- 当查询结果非常大时,设置较大的
fetchSize(例如 500 或 1000)可以显著提升性能,特别是当网络带宽充足的情况下。 - 当处理小型查询或结果集时,设置一个较小的
fetchSize可以减少内存开销,同时依然保持良好的性能。
- 当查询结果非常大时,设置较大的
调优建议
- 小型查询:对于返回少量行的查询,保持默认的
fetchSize通常是足够的。 - 大型查询:对于返回上百万行数据的大型查询,可以尝试设置
fetchSize到 500 或 1000,甚至更高,视网络条件和内存容量而定。 - 批量处理:如果你需要批量处理大量行数据,可以结合
fetchSize来减少批量处理的频率,并避免频繁的网络通信。
其他相关参数
除了 fetchSize,Oracle JDBC 驱动程序还支持 defaultRowPrefetch 参数,它在某种程度上和 fetchSize 类似。defaultRowPrefetch 是用于控制默认预取的行数,适用于 Oracle 特有的优化,但通常情况下,fetchSize 是跨数据库通用的更灵活的方式。
((OracleStatement) stmt).setRowPrefetch(50);
这种方式专门针对 Oracle 扩展功能。如果你想要更精细地控制 Oracle JDBC 的优化,可以结合 setRowPrefetch 与 setFetchSize 使用。
总结
Oracle JDBC 的 fetchSize 是一个重要的性能调优参数,合理设置它可以显著改善查询性能,尤其是在处理大量数据时。
需要根据你的查询大小、网络延迟、内存使用情况进行调整,找到最合适的值。
如果实际返回结果为1,但是查询时设置 fetch 为 99999,客户端内存会怎么样?
如果你在查询时将 fetchSize 设置为 99999,但实际返回的结果只有 1 行,那么客户端的内存使用不会有太大的变化。具体原因如下:
1. fetchSize 只是一个提示:
fetchSize只是向 JDBC 驱动程序和数据库提供的一个提示,表示希望每次从数据库中获取多少行数据。但它并不意味着驱动程序会分配 99999 行的内存来容纳查询结果。- 在你查询到的数据行少于
fetchSize时,驱动程序会智能地处理。例如,如果你的查询只返回 1 行数据,驱动程序只会获取这一行,不会额外消耗大量内存去分配 99999 行的缓存空间。
2. 内存分配取决于实际结果集:
- 驱动程序在每次从数据库中获取数据时,实际分配的内存量取决于返回的结果集大小。如果结果集只有 1 行,驱动程序只会为这一行分配内存,无论
fetchSize设置为多少。 - 即使设置了一个非常大的
fetchSize,但返回的结果集很小,实际占用的内存量将会接近返回结果集所需的大小,而不会与fetchSize成正比。
3. 不会浪费额外内存:
- 设置一个较大的
fetchSize不会直接导致内存浪费。只有在返回数据量足够大时,fetchSize才会影响内存使用。因为 JDBC 驱动程序只会为实际接收到的数据分配内存。 - 在这个例子中,如果查询结果只有 1 行,设置 99999 的
fetchSize不会显著增加内存消耗。
举个例子
假设你查询了一个返回 1 行数据的表,即使你将 fetchSize 设置为 99999,过程如下:
- JDBC 驱动从数据库获取数据,并看到返回结果集只有 1 行。
- 它会直接获取这 1 行,而不会再尝试去获取更多行,也不会预留多余的内存给 99999 行的空间。
可能的影响
虽然设置过大的 fetchSize 在处理小查询时不会产生实际的内存问题,但在以下情况下,可能会带来不必要的影响:
- 网络通信成本增加:虽然这在处理非常小的结果集时影响不大,但较大的
fetchSize在特定的数据库或 JDBC 实现中,可能导致数据库和驱动间的预取策略发生变化,造成不必要的开销,尤其在大规模查询中。 - 处理大结果集时的内存问题:如果你对一个返回非常大的结果集的查询设置了过大的
fetchSize,那就可能导致内存耗尽的风险。
总结
在查询结果很小时,设置一个超大的 fetchSize(例如 99999)并不会对内存产生明显的影响,因为 JDBC 驱动只会根据实际结果分配内存。
但在处理大规模结果集时,设置一个合适的 fetchSize 能有效平衡性能和内存的使用。
oracle 客户端处理这部分的逻辑代码在哪里?那个类 oracle 11
在 Oracle JDBC 驱动程序中,处理 fetchSize 的逻辑主要涉及以下几个类和方法,这些类负责从数据库获取结果集并管理客户端和数据库之间的数据传输。对于 Oracle 11g 及其 JDBC 驱动,以下是相关的类:
1. OracleStatement 类
OracleStatement 是 Oracle JDBC 的一个核心类,继承自 java.sql.Statement,并且负责执行 SQL 查询和管理结果集。
-
setFetchSize(int rows)方法: 这是设置fetchSize的方法,调用时会影响从数据库获取的行数。public void setFetchSize(int rows) throws SQLException { // Implementation of setting fetch size in Oracle JDBC } -
内部预取逻辑:Oracle JDBC 有特有的预取机制,除了
fetchSize,它还会根据setRowPrefetch(int rows)方法调整默认预取大小。通过fetchSize和rowPrefetch,Oracle JDBC 会控制从服务器批量获取数据的行数。
2. OracleResultSetImpl 类
该类是 ResultSet 的实现类,负责从服务器获取数据行并将它们缓存到客户端。
-
fetchRows方法: 这个方法内部负责根据设置的fetchSize向数据库请求新的数据行。它决定每次获取多少行,主要根据fetchSize和defaultRowPrefetch的设置。protected void fetchRows(int numRows) throws SQLException { // Logic to fetch rows from the database }
具体的实现会检查当前结果集中剩余的行数,如果不足,则向数据库发起新的请求,获取更多行,并将它们缓存在内存中。
3. T4CPreparedStatement 和 T4CResultSet 类
这些类是 Oracle Thin JDBC 驱动的核心部分,特别是 T4CPreparedStatement 继承了 OraclePreparedStatement,主要用于 Thin 模式下的 JDBC 实现(T4C 代表 “Type 4 Connection”)。
T4CPreparedStatement:执行查询和管理fetchSize。T4CResultSet:处理从数据库读取的结果集。
具体来说,T4CPreparedStatement 会根据 fetchSize 设置,在执行 SQL 查询时,通知数据库每次应该返回多少行。
4. PhysicalConnection 类
PhysicalConnection 类是 JDBC 连接的核心类,负责处理数据库连接和 SQL 语句的执行。它与 OracleStatement 和 ResultSet 类协作,处理与 fetchSize 相关的设置和获取数据的逻辑。
示例代码大致流程
// 在执行查询时,OracleStatement 和 OracleResultSetImpl 类会发挥作用:
OracleStatement stmt = (OracleStatement) connection.createStatement();
stmt.setFetchSize(100); // 设置 fetchSize
ResultSet rs = stmt.executeQuery("SELECT * FROM some_table");
while (rs.next()) {
// 获取每一行的数据
// OracleResultSetImpl 会根据 fetchSize 决定从数据库读取多少行
}
关键部分
OracleStatement是设置fetchSize的关键类。OracleResultSetImpl是实际获取数据的类,根据fetchSize发起数据库请求。T4CPreparedStatement和T4CResultSet是具体执行 SQL 查询和处理结果集的类,尤其在 Oracle Thin 驱动中。
你可以通过反编译 Oracle JDBC 驱动的类来查看具体的实现细节。
Oracle JDBC 驱动的 JAR 文件通常可以在 Oracle 数据库的安装目录或下载的驱动程序包中找到(如 ojdbc6.jar 或 ojdbc7.jar)。
