
Netty-08-linux 通讯模型之 Reactor
Reactor 模式是什么
白皮书
libevent 的设计是一个典型的Reactor模型,理解Reactor模型是理解libevent的基石,因此本节主要介绍典型的事件驱动设计模式---Reactor模式
The Reactor design pattern handles service requests that are delivered concurrently to an application by one or more clients.在 reactor.pdf 第一句话就直接说到 Reactor 设计模式可以为一个应用同时处理一个或者多个客户端请求服务
wiki
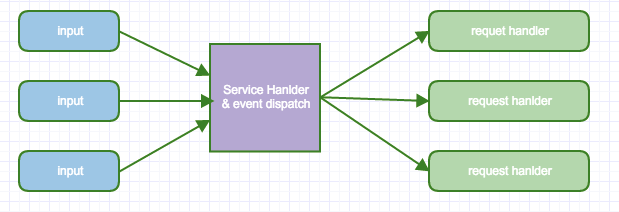
The reactor design pattern is an event handling pattern for handling service requests delivered concurrently to a service handler by one or more inputs.
The service handler then demultiplexes the incoming requests and dispatches them synchronously to the associated request handlers.从上述文字中我们可以看出以下关键点 :
事件驱动(event handling)
可以处理一个或多个输入源(one or more inputs)
通过 Service Handler 同步的将输入事件(Event)采用多路复用分发给相应的 Request Handler(多个)处理
处理方式
自 POSA2 中的关于Reactor Pattern 介绍中,我们了解了Reactor 的处理方式:
同步的等待多个事件源到达(采用select()实现)
将事件多路分解以及分配相应的事件服务进行处理,这个分派采用server集中处理(dispatch)
分解的事件以及对应的事件服务应用从分派服务中分离出去(handler)
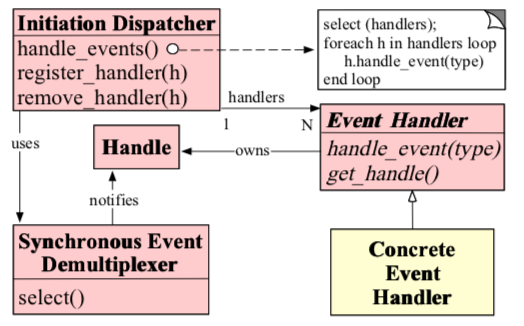
设计类图
关于 Reactor Pattern 的 OMT 类图设计:
为何要用Reactor
常见的网络服务中,如果每一个客户端都维持一个与登陆服务器的连接。
那么服务器将维护多个和客户端的连接以出来和客户端的contnect 、read、write ,特别是对于长链接的服务,有多少个c端,就需要在s端维护同等的IO连接。
这对服务器来说是一个很大的开销。
ps: 其实主要是出于性能的考虑,下面逐步揭开为什么要这么做。
1、BIO
比如我们采用BIO的方式来维护和客户端的连接:
// 主线程维护连接
public void run() {
try {
while (true) {
Socket socket = serverSocket.accept();
//提交线程池处理
executorService.submit(new Handler(socket));
}
} catch (Exception e) {
e.printStackTrace();
}
}
// 处理读写服务
class Handler implements Runnable {
public void run() {
try {
//获取Socket的输入流,接收数据
BufferedReader buf = new BufferedReader(new InputStreamReader(socket.getInputStream()));
String readData = buf.readLine();
while (readData != null) {
readData = buf.readLine();
System.out.println(readData);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}线程池
很明显,为了避免资源耗尽,我们采用线程池的方式来处理读写服务。但是这么做依然有很明显的弊端:
同步阻塞IO,读写阻塞,线程等待时间过长
在制定线程策略的时候,只能根据CPU的数目来限定可用线程资源,不能根据连接并发数目来制定,也就是连接有限制。否则很难保证对客户端请求的高效和公平。
多线程之间的上下文切换,造成线程使用效率并不高,并且不易扩展
状态数据以及其他需要保持一致的数据,需要采用并发同步控制
线程池的做法增加了复杂度,而且需要处理并发的下的数据同步问题。
2、NIO
那么可以有其他方式来更好的处理么,我们可以采用NIO来处理,NIO中支持的基本机制:
非阻塞的IO读写
基于IO事件进行分发任务,同时支持对多个fd的监听
public NIOServer(int port) throws Exception {
selector = Selector.open();
serverSocket = ServerSocketChannel.open();
serverSocket.socket().bind(new InetSocketAddress(port));
serverSocket.configureBlocking(false);
serverSocket.register(selector, SelectionKey.OP_ACCEPT);
}
@Override
public void run() {
while (!Thread.interrupted()) {
try {
//阻塞等待事件
selector.select();
// 事件列表
Set selected = selector.selectedKeys();
Iterator it = selected.iterator();
while (it.hasNext()) {
it.remove();
//分发事件
dispatch((SelectionKey) (it.next()));
}
} catch (Exception e) {
}
}
}
private void dispatch(SelectionKey key) throws Exception {
if (key.isAcceptable()) {
register(key);//新链接建立,注册
} else if (key.isReadable()) {
read(key);//读事件处理
} else if (key.isWritable()) {
wirete(key);//写事件处理
}
}
private void register(SelectionKey key) throws Exception {
ServerSocketChannel server = (ServerSocketChannel) key
.channel();
// 获得和客户端连接的通道
SocketChannel channel = server.accept();
channel.configureBlocking(false);
//客户端通道注册到selector 上
channel.register(this.selector, SelectionKey.OP_READ);
}
}我们可以看到上述的NIO例子已经差不多拥有 reactor 的影子了
基于事件驱动-> selector(支持对多个socketChannel的监听)
统一的事件分派中心-> dispatch
事件处理服务-> read & write
事实上NIO已经解决了上述BIO暴露的1&2问题了,服务器的并发客户端有了量的提升,不再受限于一个客户端一个线程来处理,而是一个线程可以维护多个客户端(selector 支持对多个socketChannel 监听)。
Reactor Pattern
但这依然不是一个完善的 Reactor Pattern, 首先Reactor 是一种设计模式,好的模式应该是支持更好的扩展性,显然以上的并不支持,另外好的Reactor Pattern 必须有以下特点:
更少的资源利用,通常不需要一个客户端一个线程
更少的开销,更少的上下文切换以及 locking
能够跟踪服务器状态
能够管理 handler 对 event 的绑定
下面让我们一起看看 Reactor 的思想及其细节。
Reactor 的事件处理机制
Reactor Bing 中文翻译为 "反应堆,反应器",是一种事件驱动机制。
与普通函数调用的不同之处在于:应用程序不是主动的调用某个API完成处理,而是恰恰相反,Reactor逆置了事件处理流程,应用程序需要提供相应的接口并注册到Reactor上,如果相应的事件发生,Reactor将主动调用应用程序注册的接口,这些接口又称为"callback function"(回调函数).
在使用libevent时,需要向libevent框架注册相应的事件和会调函数,当注册的相应事件发生时,libevent会调用回调函数处理相应的时间(I/O读写,定时器,信号)
用"好莱坞原则"来形容Reactor再合适不过了: 不要打电话给我们,我们会打电话通知你。
Reactor 模式结构
在 Reactor 模式中,有 5 个关键参与者。
描述符(handle)
描述符(handle):由操作系统提供,用于识别每个事件,如Socket描述符、文件描述符等。在Linux中,它用一个整数来表示。事件可以来自外部,如来自客户端的连接请求、数据等。事件也可以来自内部,如定时器事件。
同步事件分离器(synchronous event demultiplexer)
同步事件分离器(synchronous event demultiplexer):是一个函数,用于等待一个或多个事件的发生。调用者会被阻塞,直到分离器分离的描述符集上有事件发生。Linux的select函数是一个经常被使用的分离器。
事件处理器接口(event handler)
事件处理器接口(event handler):是有一个或多个模板函数组成的接口。这些模板函数描述了和应用程序相关的对于某个事件的操作。
具体的事件处理器(concrete event handler)
具体的事件处理器(concrete event handler):是事件处理器接口的实现,它实现了应用程序提供的某个服务。每个具体的事件处理器总和一个描述符相关。它使用描述符来识别事件、识别应用程序提供的服务。
Reactor 管理器(dispatcher)
Reactor 管理器(dispatcher):定义了一些接口,用于应用程序控制事件调度,以及应用程序注册、删除事件处理器和相关的描述符。
它是事件处理器的调度核心。
Reactor管理器使用同步事件分离器来等待事件的发生。
一旦事件发生,Reactor管理器先是分离每个事件,然后调度事件处理器,最后调用相关模板函数来处理这个事件。
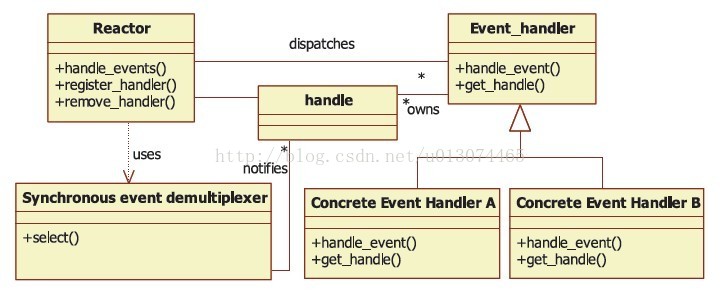
可以看出,是Reactor管理器并不是应用程序负责等待事件、分离事件和调度事件。
Reactor并没有被具体的事件处理器调度,而是管理器调度具体的事件处理器,由事件处理器对发生的事件作出处理,这就是Hollywood原则。
应用程序要做的仅仅是实现一个具体的事件处理器,然后把它注册到Reactor管理器中。
接下来的工作由管理器来完成:如果有相应的事件发生,Reactor会主动调用具体的事件处理器,由事件处理器对发生的事件作出处理。
Reactor 理论模型
Reactor 中的组件
- Reactor
Reactor: Reactor是IO事件的派发者。
- Acceptor
Acceptor: Acceptor接受client连接,建立对应client的Handler,并向Reactor注册此Handler。
- Handler
Handler: 和一个client通讯的实体,按这样的过程实现业务的处理。
一般在基本的Handler基础上还会有更进一步的层次划分,用来抽象诸如decode,process和encoder这些过程。
比如对Web Server而言,decode通常是HTTP请求的解析,process的过程会进一步涉及到Listener和Servlet的调用。
业务逻辑的处理在Reactor模式里被分散的IO事件所打破,所以Handler需要有适当的机制在所需的信息还不全(读到一半)的时候保存上下文,并在下一次IO事件到来的时候(另一半可读了)能继续中断的处理。
为了简化设计,Handler 通常被设计成状态机,按GoF的state pattern来实现。
对比 NIO
对应上面的 NIO 代码来看:
Reactor:相当于有分发功能的 Selector
Acceptor:NIO 中建立连接的那个判断分支
Handler:消息读写处理等操作类
线程模型
Reactor 从线程池和 Reactor 的选择上可以细分为如下几种:
单 Reactor 单线程模型
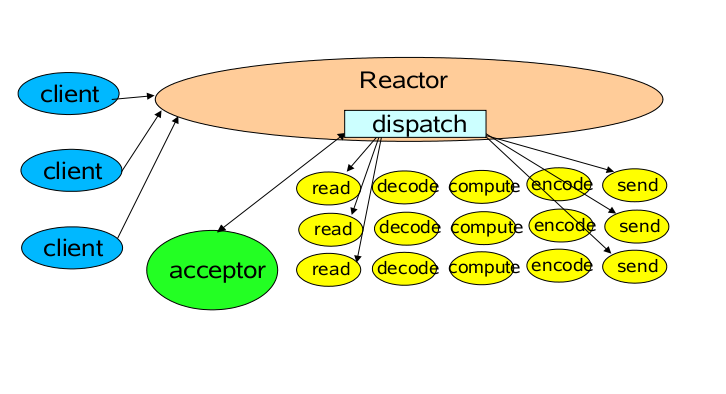
这个模型和上面的NIO流程很类似,只是将消息相关处理独立到了 Handler 中去了!
- 源码实现
/**
* 等待事件到来,分发事件处理
*/
class Reactor implements Runnable {
private Reactor() throws Exception {
SelectionKey sk =
serverSocket.register(selector,
SelectionKey.OP_ACCEPT);
// attach Acceptor 处理新连接
sk.attach(new Acceptor());
}
public void run() {
try {
while (!Thread.interrupted()) {
selector.select();
Set selected = selector.selectedKeys();
Iterator it = selected.iterator();
while (it.hasNext()) {
it.remove();
//分发事件处理
dispatch((SelectionKey) (it.next()));
}
}
} catch (IOException ex) {
//do something
}
}
void dispatch(SelectionKey k) {
// 若是连接事件获取是acceptor
// 若是IO读写事件获取是handler
Runnable runnable = (Runnable) (k.attachment());
if (runnable != null) {
runnable.run();
}
}
}/**
* 连接事件就绪,处理连接事件
*/
class Acceptor implements Runnable {
@Override
public void run() {
try {
SocketChannel c = serverSocket.accept();
if (c != null) {// 注册读写
new Handler(c, selector);
}
} catch (Exception e) {
}
}
}后,交由Acceptor进行处理,有IO读写事件之后交给hanlder 处理。
Acceptor主要任务就是构建handler ,在获取到和client相关的SocketChannel之后 ,绑定到相应的hanlder上,对应的SocketChannel有读写事件之后,基于racotor 分发,hanlder就可以处理了(所有的IO事件都绑定到selector上,有Reactor分发)。
该模型适用于处理器链中业务处理组件能快速完成的场景。
不过,这种单线程模型不能充分利用多核资源,所以实际使用的不多。
我们看一个客户端的情况,如果这个客户端多次进行请求,如果在Handler中的处理速度较慢,那么后续的客户端请求都会被积压,导致响应变慢!
所以引入了 Reactor 多线程模型。
单 Reactor 多线程模型
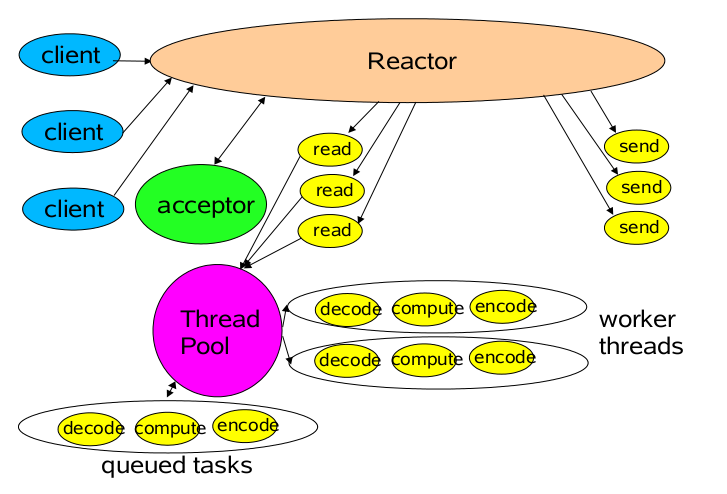
相对于第一种单线程的模式来说,在处理业务逻辑,也就是获取到IO的读写事件之后,交由线程池来处理,这样可以减小主reactor的性能开销,从而更专注的做事件分发工作了,从而提升整个应用的吞吐。
我们看下实现方式:
/**
* 多线程处理读写业务逻辑
*/
class MultiThreadHandler implements Runnable {
public static final int READING = 0, WRITING = 1;
int state;
final SocketChannel socket;
final SelectionKey sk;
//多线程处理业务逻辑
ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
public MultiThreadHandler(SocketChannel socket, Selector sl) throws Exception {
this.state = READING;
this.socket = socket;
sk = socket.register(selector, SelectionKey.OP_READ);
sk.attach(this);
socket.configureBlocking(false);
}
@Override
public void run() {
if (state == READING) {
read();
} else if (state == WRITING) {
write();
}
}
private void read() {
//任务异步处理
executorService.submit(() -> process());
//下一步处理写事件
sk.interestOps(SelectionKey.OP_WRITE);
this.state = WRITING;
}
private void write() {
//任务异步处理
executorService.submit(() -> process());
//下一步处理读事件
sk.interestOps(SelectionKey.OP_READ);
this.state = READING;
}
/**
* task 业务处理
*/
public void process() {
//do IO ,task,queue something
}
}Reactor多线程模型就是将Handler中的IO操作和非IO操作分开,操作IO的线程称为IO线程,非IO操作的线程称为工作线程!这样的话,客户端的请求会直接被丢到线程池中,客户端发送请求就不会堵塞!
但是当用户进一步增加的时候,Reactor会出现瓶颈。
因为 Reactor 既要处理IO操作请求,又要响应连接请求。
为了分担 Reactor 的负担,所以引入了主从 Reactor 模型。
多 Reactor 多线程模型
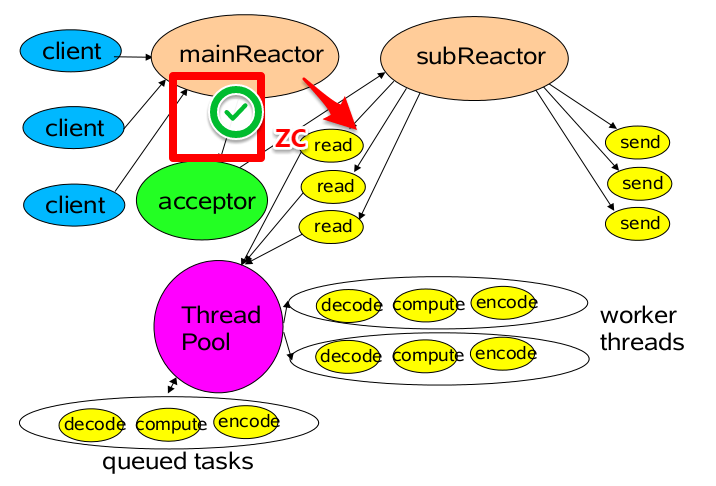
第三种模型比起第二种模型,是将Reactor分成两部分,
mainReactor负责监听server socket,用来处理新连接的建立,将建立的socketChannel指定注册给subReactor。
subReactor维护自己的selector, 基于mainReactor 注册的socketChannel多路分离IO读写事件,读写网络数据,对业务处理的功能,另其扔给worker线程池来完成。
- 实现方式
我们看下实现方式:
/**
* 多work 连接事件Acceptor,处理连接事件
*/
class MultiWorkThreadAcceptor implements Runnable {
// cpu线程数相同多work线程
int workCount =Runtime.getRuntime().availableProcessors();
SubReactor[] workThreadHandlers = new SubReactor[workCount];
volatile int nextHandler = 0;
public MultiWorkThreadAcceptor() {
this.init();
}
public void init() {
nextHandler = 0;
for (int i = 0; i = workThreadHandlers.length) {
nextHandler = 0;
}
}
}
} catch (Exception e) {
}
}
}/**
* 多work线程处理读写业务逻辑
*/
class SubReactor implements Runnable {
final Selector mySelector;
//多线程处理业务逻辑
int workCount =Runtime.getRuntime().availableProcessors();
ExecutorService executorService = Executors.newFixedThreadPool(workCount);
public SubReactor() throws Exception {
// 每个SubReactor 一个selector
this.mySelector = SelectorProvider.provider().openSelector();
}
/**
* 注册chanel
*
* @param sc
* @throws Exception
*/
public void registerChannel(SocketChannel sc) throws Exception {
sc.register(mySelector, SelectionKey.OP_READ | SelectionKey.OP_CONNECT);
}
@Override
public void run() {
while (true) {
try {
//每个SubReactor 自己做事件分派处理读写事件
selector.select();
Set keys = selector.selectedKeys();
Iterator iterator = keys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
if (key.isReadable()) {
read();
} else if (key.isWritable()) {
write();
}
}
} catch (Exception e) {
}
}
}
private void read() {
//任务异步处理
executorService.submit(() -> process());
}
private void write() {
//任务异步处理
executorService.submit(() -> process());
}
/**
* task 业务处理
*/
public void process() {
//do IO ,task,queue something
}
}第三种模型中,我们可以看到,mainReactor 主要是用来处理网络IO 连接建立操作,通常一个线程就可以处理,而subReactor主要做和建立起来的socket做数据交互和事件业务处理操作,它的个数上一般是和CPU个数等同,每个subReactor一个县城来处理。
此种模型中,每个模块的工作更加专一,耦合度更低,性能和稳定性也大量的提升,支持的可并发客户端数量可达到上百万级别。
关于此种模型的应用,目前有很多优秀的矿建已经在应用了,比如mina 和netty 等。上述中去掉线程池的第三种形式的变种,也 是Netty NIO的默认模式。下一节我们将着重讲解netty的架构模式。
代码
在上图中,可以看到Rector管理器(dispatcher)是Reactor模式中最为关键的角色,它是该模式最终向用户提供接口的类。
用户可以向 Reactor 中注册 event handler,然后 Reactor 在 react 的时候,发现用户注册的 fd 有事件发生,就会调用用户的事件处理函数。
下面是一个典型的 reactor 声明方式:
class Reactor
{
public:
//构造函数
Reactor();
//析构函数
~Reactor();
//向reactor中注册关注事件evt的handler(可重入)
//@param handler 要注册的事件处理器
//@param evt 要关注的事件
//@retval 0 注册成功
//@retval -1 注册出错
int RegisterHandler(EventHandler *handler, event_t evt);
//从reactor中移除handler
//param handler 要移除的事件处理器
//retval 0 移除成功
//retval -1 移除出错
int RemoveHandler(EventHandler *handler);
//处理事件,回调注册的handler中相应的事件处理函数
//@param timeout 超时事件(毫秒)
void HandlerEvents(int timeout = 0);
private:
ReactorImplementation *m_reactor_impl; //reactor的实现类
}SynchrousEventDemultiplexer 也是 Reactor 中一个比较重要的角色,它是 Reactor 用来检测用户注册的 fd 上发生的事件的利器,
通过 Reactor 得知了那些 fd 上发生了什么样的事件,然后以这些为依据,来多路分发事件,回调用户事件处理函数。
下面是一个简单的设计:
class EventDemultiplexer
{
public:
/// 获取有事件发生的所有句柄以及所发生的事件
/// @param events 获取的事件
/// @param timeout 超时时间
/// @retval 0 没有发生事件的句柄(超时)
/// @retval 大于0 发生事件的句柄个数
/// @retval 小于0 发生错误
virtual int WaitEvents(std::map * events, int timeout = 0) = 0;
/// 设置句柄handle关注evt事件
/// @retval 0 设置成功
/// @retval 小于0 设置出错
virtual int RequestEvent(handle_t handle, event_t evt) = 0;
/// 撤销句柄handle对事件evt的关注
/// @retval 0 撤销成功
/// @retval 小于0 撤销出错
virtual int UnrequestEvent(handle_t handle, event_t evt) = 0;
};Event Handler事件处理程序提供一组接口,每个接口对应了一种类型的事件,供Reactr在相应的事件发生时调用,执行相应的事件处理。
通常它会绑定一个有效的句柄。
对应到libevent中,就是event结构体。
下面是典型的Event Handler类两种声明方式。
class Event_Handler
{
public:
//处理读事件的回调函数
virtual void handle_read() = 0;
//处理写事件的回调函数
virtual void handle_write() = 0;
//处理超时的回调函数
virtual void handle_timeout() = 0;
//关闭对应的handle句柄
virtual void handle_close() = 0;
//获取该handler所对应的句柄
virtual HANDLE get_handle() = 0;
};or
class Event_Handler
{
public:
//event maybe read/write/timeout/close .etc
virtual void hand_events(int events) = 0;
virtual HANDLE get_handle() = 0;
}ConcreteEventHandler 具体事件处理器是 EventHanler 的子类,EventHandler 是 Reactor 所用来规定接口的基类,
用户自己的事件处理器都必须从 EventHandler 继承。
Reactor 模式的优缺点
优点
Reactor 模式是编写高性能网络服务器的必备技术之一,它具有如下优点:
响应快,不必为单个同步时间所阻塞,虽然Reactor本身依然是同步的
编程相对简单,可以最大程度的避免复杂的多线程及同步问题,并且避免多线程或者多进程的切换开销
可扩展性,可以方便的通过增加Reactor实例个数来充分利用CPU资源
可复用性,Reactor 框架本身与具体事件处理逻辑无关,具有很高的复用性
缺点
相比传统的简单模型,Reactor增加了一定的复杂性,因而有一定的门槛,并且不易于调试。
Reactor 模式需要底层的Synchronous Event Demultiplexer支持,比如Java中的Selector支持,操作系统的select系统调用支持,如果要自己实现Synchronous Event Demultiplexer可能不会有那么高效。
Reactor模式在IO读写数据时还是在同一个线程中实现的,即使使用多个Reactor机制的情况下,那些共享一个Reactor的Channel如果出现一个长时间的数据读写,会影响这个Reactor中其他Channel的相应时间,比如在大文件传输时,IO操作就会影响其他Client的相应时间,因而对这种操作,使用传统的Thread-Per-Connection或许是一个更好的选择,或则此时使用 Proactor 模式。
Proacotr模型
Proactor是和异步I/O相关的。
在Reactor模式中,事件分离者等待某个事件或者可应用或个操作的状态发生(比如文件描述符可读写,或者是socket可读写),事件分离器就把这个事件传给事先注册的处理器(事件处理函数或者回调函数),由后者来做实际的读写操作。
在Proactor模式中,事件处理者(或者代由事件分离者发起)直接发起一个异步读写操作(相当于请求),而实际的工作是由操作系统来完成的。
发起时,需要提供的参数包括用于存放读到数据的缓存区,读的数据大小,或者用于存放外发数据的缓存区,以及这个请求完后的回调函数等信息。
事件分离者得知了这个请求,它默默等待这个请求的完成,然后转发完成事件给相应的事件处理者或者回调。
可以看出两者的区别:Reactor是在事件发生时就通知事先注册的事件(读写由处理函数完成);
Proactor是在事件发生时进行异步I/O(读写由OS完成),待IO完成事件分离器才调度处理器来处理。
例子
举个例子,将有助于理解Reactor与Proactor二者的差异,以读操作为例(类操作类似)。
同步
在 Reactor(同步)中实现读:
注册读就绪事件和相应的事件处理器
事件分离器等待事件
事件到来,激活分离器,分离器调用事件对应的处理器。
事件处理器完成实际的读操作,处理读到的数据,注册新的事件,然后返还控制权。
异步
Proactor(异步)中的读:
处理器发起异步读操作(注意:操作系统必须支持异步IO)。在这种情况下,处理器无视IO就绪事件,它关注的是完成事件。
事件分离器等待操作完成事件
在分离器等待过程中,操作系统利用并行的内核线程执行实际的读操作,并将结果数据存入用户自定义缓冲区,最后通知事件分离器读操作完成。
事件分离器呼唤处理器。
事件处理器处理用户自定义缓冲区中的数据,然后启动一个新的异步操作,并将控制权返回事件分离器。
现行做法
开源C++框架:ACE
开源C++开发框架 ACE 提供了大量平台独立的底层并发支持类(线程、互斥量等)。
同时在更高一层它也提供了独立的几组C++类,用于实现Reactor及Proactor模式。
尽管它们都是平台独立的单元,但他们都提供了不同的接口。
ACE Proactor在MS-Windows上无论是性能还在健壮性都更胜一筹,这主要是由于Windows提供了一系列高效的底层异步API。(这段可能过时了点吧) 不幸的是,并不是所有操作系统都为底层异步提供健壮的支持。
举例来说,许多Unix系统就有麻烦。
因此, ACE Reactor可能是Unix系统上更合适的解决方案。
正因为系统底层的支持力度不一,为了在各系统上有更好的性能,开发者不得不维护独立的好几份代码: 为Windows准备的ACE Proactor以及为Unix系列提供的ACE Reactor。
真正的异步模式需要操作系统级别的支持。由于事件处理者及操作系统交互的差异,为Reactor和Proactor设计一种通用统一的外部接口是非常困难的。这也是设计通行开发框架的难点所在。
ACE是一个大型的中间件产品,代码20万行左右,过于宏大,一堆的设计模式,架构了一层又一层,使用的时候,要根据情况,看从那一层来进行使用。支持跨平台。
设计模式 :ACE主要应用了Reactor,Proactor等;
层次架构 :ACE底层是C风格的OS适配层,上一层基于C++的wrap类,再上一层是一些框架 (Accpetor,Connector,Reactor,Proactor等),最上一层是框架上服务;
可移植性 :ACE支持多种平台,可移植性不存在问题,据说socket编程在linux下有不少bugs;
事件分派处理 :ACE主要是注册handler类,当事件分派时,调用其handler的虚挂勾函数。实现 ACE_Handler/ACE_Svc_Handler/ACE_Event_handler等类的虚函数;
涉及范围 :ACE包含了日志,IPC,线程池,共享内存,配置服务,递归锁,定时器等;
线程调度 :ACE的Reactor是单线程调度,Proactor支持多线程调度;
发布方式 :ACE是开源免费的,不依赖于第三方库,一般应用使用它时,以动态链接的方式发布动态库;开发难度 :基于ACE开发应用,对程序员要求比较高,要用好它,
必须非常了解其框架。在其框架下开发,往往new出一个对象,不知在什么地方释放好。
C 网络库:libevent
libevent是一个C语言写的网络库,官方主要支持的是类linux操作系统,最新的版本添加了对windows的IOCP的支持。
在跨平台方面主要通过select模型来进行支持。
设计模式 :libevent为Reactor模式;
层次架构:livevent在不同的操作系统下,做了多路复用模型的抽象,可以选择使用不同的模型,通过事件函数提供服务;
可移植性 :libevent主要支持linux平台,freebsd平台,其他平台下通过select模型进行支持,效率不是太高;
事件分派处理 :libevent基于注册的事件回调函数来实现事件分发;
涉及范围 :libevent只提供了简单的网络API的封装,线程池,内存池,递归锁等均需要自己实现;
线程调度 :libevent的线程调度需要自己来注册不同的事件句柄;
发布方式 :libevent为开源免费的,一般编译为静态库进行使用;
开发难度 :基于libevent开发应用,相对容易,具体可以参考 memcached 这个开源的应用,里面使用了 libevent这个库。
改进方案:模拟异步
在改进方案中,我们将Reactor原来位于事件处理器内的read/write操作移至分离器(不妨将这个思路称为“模拟异步”),以此寻求将Reactor多路同步IO转化为模拟异步IO。
以读操作为例子,改进过程如下:
注册读就绪事件及其处理器,并为分离器提供数据缓冲区地址,需要读取数据量等信息。
分离器等待事件(如在select()上等待)
事件到来,激活分离器。分离器执行一个非阻塞读操作(它有完成这个操作所需的全部信息),最后调用对应处理器。
事件处理器处理用户自定义缓冲区的数据,注册新的事件(当然同样要给出数据缓冲区地址,需要读取的数据量等信息),最后将控制权返还分离器。
如我们所见,通过对多路IO模式功能结构的改造,可将Reactor转化为Proactor模式。
改造前后,模型实际完成的工作量没有增加,只不过参与者间对工作职责稍加调换。
没有工作量的改变,自然不会造成性能的削弱。对如下各步骤的比较,可以证明工作量的恒定:
标准/典型的Reactor:
步骤1:等待事件到来(Reactor负责)
步骤2:将读就绪事件分发给用户定义的处理器(Reactor负责)
步骤3:读数据(用户处理器负责)
步骤4:处理数据(用户处理器负责)
改进实现的模拟Proactor:
步骤1:等待事件到来(Proactor负责)
步骤2:得到读就绪事件,执行读数据(现在由Proactor负责)
步骤3:将读完成事件分发给用户处理器(Proactor负责)
步骤4:处理数据(用户处理器负责)
对于不提供异步IO API的操作系统来说,这种办法可以隐藏socket API的交互细节,从而对外暴露一个完整的异步接口。
借此,我们就可以进一步构建完全可移植的,平台无关的,有通用对外接口的解决方案。
上述方案已经由Terabit P/L公司(http://www.terabit.com.au/)实现为TProactor。
它有两个版本:C++和JAVA的。C++版本采用ACE跨平台底层类开发,为所有平台提供了通用统一的主动式异步接口。
Boost.Asio 类库
Boost.Asio类库,其就是以Proactor这种设计模式来实现,
参见:Proactor(The Boost.Asio library is based on the Proactor pattern. This design note outlines the advantages and disadvantages of this approach.),
其设计文档链接:http://asio.sourceforge.net/boost_asio_0_3_7/libs/asio/doc/design/index.html
事件处理模式
事件处理模式
在 Douglas Schmidt 的大作《POSA2》中有关于事件处理模式的介绍,其中有四种事件处理模式:
Reactor
Proactor
Asynchronous Completion Token
Acceptor-Connector
Proactor
本文介绍的Reactor就是其中一种,而Proactor的整体结构和reacotor的处理方式大同小异,不同的是Proactor采用的是异步非阻塞IO的方式实现,对数据的读写由异步处理,无需用户线程来处理,服务程序更专注于业务事件的处理,而非IO阻塞。
Asynchronous Completion Token
简单来说,ACT就是应对应用程序异步调用服务操作,并处理相应的服务完成事件。
从token这个字面意思,我们大概就能了解到,它是一种状态的保持和传递。
比如,通常应用程序会有调用第三方服务的需求,一般是业务线程请求都到,需要第三方资源的时候,去同步的发起第三方请求,而为了提升应用性能,需要异步的方式发起请求,但异步请求的话,等数据到达之后,此时的我方应用程序的语境以及上下文信息已经发生了变化,你没办法去处理。
ACT 解决的就是这个问题,采用了一个token的方式记录异步发送前的信息,发送给接受方,接受方回复的时候再带上这个token,此时就能恢复业务的调用场景。
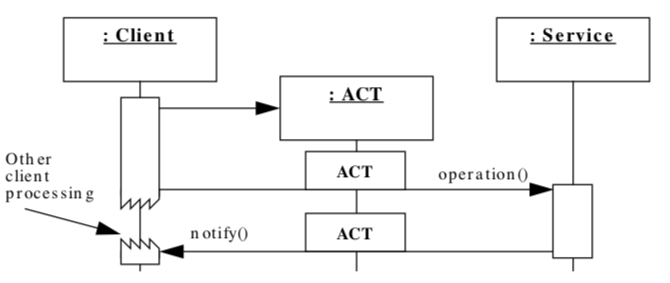
上图中我们可以看到在client processing 这个阶段,客户端是可以继续处理其他业务逻辑的,不是阻塞状态。service 返回期间会带上token信息。
Acceptor-Connector
Acceptor-Connector 是于 Reactor 的结合,也可以看成是一种变种,它看起来很像上面介绍的Reactor第三种实现方式,但又有本质的不同。
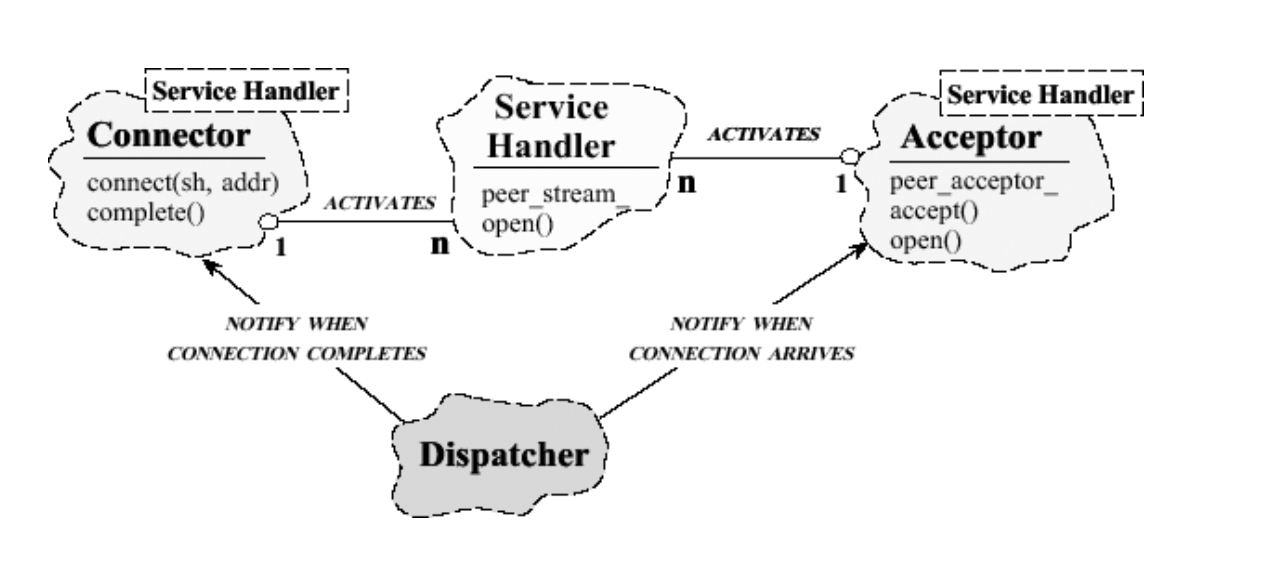
Acceptor-Connector模式是将网络中对等服务的连接和初始化分开处理,使系统中的连接建立及服务一旦服务初始化后就分开解除耦合。
连接器主动地建立到远地接受器组件的连接,并初始化服务处理器来处理在连接上交换的数据。
同样地,接受器被动地等待来自远地连接器的连接请求,在这样的请求到达时建立连接,并初始化服务处理器来处理在连接上交换的数据。
随后已初始化的服务处理器执行应用特有的处理,并通过连接器和接受器组件建立的连接来进行通信。
优点
一般而言,用于连接建立和服务初始化的策略变动的频度要远小于应用服务实现和通信协议。
容易增加新类型的服务、新的服务实现和新的通信协议,而又不影响现有的连接建立和服务初始化软件。
比如采用IPX/SPX通信协议或者TCP协议。
连接角色和通信角色的去耦合,连接角色只管发起连接 vs. 接受连接。通信角色只管数据交互。
将程序员与低级网络编程API(像socket或TLI)类型安全性的缺乏屏蔽开来。业务开发关系底层通信
拓展阅读
个人收获
思想 vs 实现
比起实现,思想是通用的。
但还是要至少掌握一种实现。
知识渠道的获取
目前对于知识渠道的获取太匮乏,没事应该多读读英文原版的 pdf。
感觉国内的博客就是翻译+copy。
包括我这一篇==