
Dubbo3.x-36-生态集成之 在 Dubbo 中使用 Zipkin 进行全链路追踪
回顾
大家好,我是老马。
最近 dubbo3.x 在公司内部分享,于是想系统梳理一下。
总体思路是官方文档入门+一些场景的问题思考+源码解析学习。
在 Dubbo 中使用 Zipkin 进行全链路追踪
文章介绍
随着业务的发展,应用的规模不断扩大,传统的应用架构无法满足需求,服务化架构改造势在必行。以 Dubbo 为代表的分布式服务框架成为了服务化改造架构中的基石。微服务理念的逐渐被接受,应用进一步向更细粒度拆分,不同的应用由不同的开发团队独立负责,整个分布式系统变得十分复杂。没有人能够清晰及时地知道当前系统整体的依赖关系。当出现问题时,也无法及时知道具体是链路上的哪个环节出了问题。
在这个背景下,Google 发表了 Dapper 的论文,描述了如何通过一个分布式追踪系统解决上述问题。基于该论文,各大互联网公司实现并部署了自己的分布式追踪系统,其中比较出名的有阿里巴巴的 EagleEye。本文中提到的 Zipkin 是 Twitter 公司开源的分布式追踪系统。下面会详细介绍如何在 Dubbo 中使用 Zipkin 来实现分布式追踪。
Zipkin 简介
Zipkin 是基于 Dapper 论文实现,由 Twitter 开源的分布式追踪系统,通过收集分布式服务执行时间的信息来达到追踪服务调用链路、以及分析服务执行延迟等目的。
Zipkin 架构
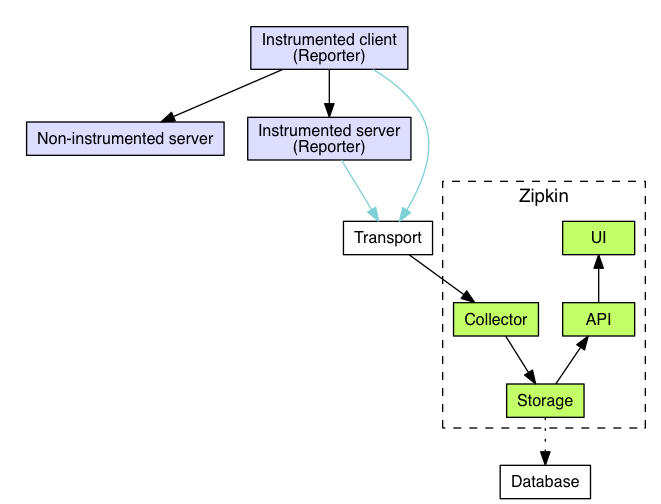
Collector 收集器、Storage 存储、API、UI 用户界面等几部分构成了 Zipkin Server 部分,对应于 GitHub 上 openzipkin/zipkin 这个项目。而收集应用中调用的耗时信息并将其上报的组件与应用共生,并拥有各个语言的实现版本,其中 Java 的实现是 GitHub 上 openzipkin/brave。除了 Java 客户端实现之外,openzipkin 还提供了许多其他语言的实现,其中包括了 go、php、JavaScript、.net、ruby 等,具体列表可以参阅 Zipkin 的 Exiting instrumentations。
Zipkin 的工作过程
当用户发起一次调用时,Zipkin 的客户端会在入口处为整条调用链路生成一个全局唯一的 trace id,并为这条链路中的每一次分布式调用生成一个 span id。span 与 span 之间可以有父子嵌套关系,代表分布式调用中的上下游关系。span 和 span 之间可以是兄弟关系,代表当前调用下的两次子调用。一个 trace 由一组 span 组成,可以看成是由 trace 为根节点,span 为若干个子节点的一棵树。
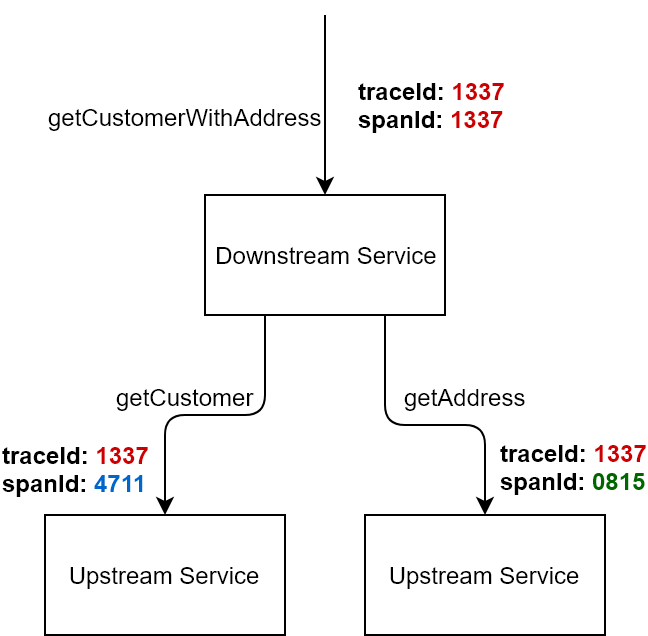
Span 由调用边界来分隔,在 Zipkin 中,调用边界由以下四个 annotation 来表示:
- cs - Client Sent 客户端发送了请求
- sr - Server Receive 服务端接受到请求
- ss - Server Send 服务端处理完毕,向客户端发送回应
- cr - Client Receive 客户端收到结果
显然,通过这四个 annotation 上的时间戳,可以轻易地知道一次完整的调用在不同阶段的耗时,比如:
- sr - cs 代表了请求在网络上的耗时
- ss - sr 代表了服务端处理请求的耗时
- cr - ss 代表了回应在网络上的耗时
- cr - cs 代表了一次调用的整体耗时
Zipkin 会将 trace 相关的信息在调用链路上传递,并在每个调用边界结束时异步的把当前调用的耗时信息上报给 Zipkin Server。Zipkin Server 在收到 trace 信息后,将其存储起来,Zipkin 支持的存储类型有 inMemory、MySql、Cassandra、以及 ElasticSearch 几种方式。随后 Zipkin 的 Web UI 会通过 API 访问的方式从存储中将 trace 信息提取出来分析并展示。
在 Dubbo 中使用
由于 Brave 对 Dubbo 已经主动做了支持,在 Dubbo 中集成基于 Zipkin 的链路追踪变得十分简单。下面会按照 Brave 中关于 Dubbo RPC 支持的指引来说明如何在 Dubbo 中使用 Zipkin。
安装 Zipkin Server
按照 Zipkin 官方文档中的快速开始 来安装 Zipkin,如下所示:
$ curl -sSL [https://zipkin.io/quickstart.sh ](https://zipkin.io/quickstart.sh ) | bash -s
$ java -jar zipkin.jar按照这种方式安装的 Zipkin Server 使用的存储类型是 inMemory 的。当服务器停机之后,所有收集到的 trace 信息会丢失,不适用于生产系统。如果在生产系统中使用,需要配置另外的存储类型。Zipkin 支持 MySql、Cassandra、和 ElasticSearch。推荐使用 Cassandra 和 ElasticSearch,相关的配置请自行查阅官方文档。
本文为了演示方便,使用的存储是 inMemory 类型。成功启动之后,可以在终端看到如下的提示:
$ java -jar zipkin.jar
Picked up JAVA_TOOL_OPTIONS: -Djava.awt.headless=true
********
** **
* *
** **
** **
** **
** **
********
****
****
**** ****
****** **** ***
****************************************************************************
******* **** ***
**** ****
**
**
***** ** ***** ** ** ** ** **
** ** ** * *** ** **** **
** ** ***** **** ** ** ***
****** ** ** ** ** ** ** **
:: Powered by Spring Boot :: (v2.0.5.RELEASE)
...
o.s.b.w.e.u.UndertowServletWebServer : Undertow started on port(s) 9411 (http) with context path ''
2018-10-10 18:40:31.605 INFO 21072 --- [ main] z.s.ZipkinServer : Started ZipkinServer in 6.835 seconds (JVM running for 8.35)然后在浏览器中访问 http://localhost:9411 验证 WEB 界面。
配置 Maven 依赖
引入 Brave 依赖
新建一个新的 Java 工程,并在 pom.xml 中引入 Brave 相关的依赖如下:
5.4.2
2.7.9
io.zipkin.brave
brave-bom
${brave.version}
pom
import
io.zipkin.reporter2
zipkin-reporter-bom
${zipkin-reporter.version}
pom
import
io.zipkin.brave
brave-instrumentation-dubbo-rpc
io.zipkin.brave
brave-spring-beans
io.zipkin.brave
brave-context-slf4j
io.zipkin.reporter2
zipkin-sender-okhttp3引入 Dubbo 相关依赖
Dubbo 相关的依赖是 Dubbo 本身以及 Zookeeper 客户端,在下面的例子中,我们将会使用独立的 Zookeeper Server 作为服务发现。
org.apache.curator
curator-framework
2.12.0
io.netty
netty
com.alibaba
dubbo
2.6.2配置 Dubbo 和 Zipkin
配置 Dubbo Provider 和 Consumer
在 resources 目录下创建 dubbo-provider.xml 和 dubbo-consumer.xml 文件,分别用于配置 Dubbo 的服务提供者和消费者。
dubbo-provider.xml:
dubbo-consumer.xml:
配置 Zipkin
在 resources 目录下创建 application.yml 文件,配置 Zipkin 的相关信息。
zipkin:
enabled: true
base-url: http://localhost:9411
service:
name: dubbo-provider编写代码
服务接口和实现
DemoService.java:
package com.example;
public interface DemoService {
String sayHello(String name);
}DemoServiceImpl.java:
package com.example;
public class DemoServiceImpl implements DemoService {
@Override
public String sayHello(String name) {
return "Hello, " + name;
}
}启动 Provider 和 Consumer
ProviderApp.java:
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class ProviderApp {
public static void main(String[] args) throws Exception {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("classpath:dubbo-provider.xml");
context.start();
System.in.read(); // 按任意键退出
}
}ConsumerApp.java:
import com.example.DemoService;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class ConsumerApp {
public static void main(String[] args) {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("classpath:dubbo-consumer.xml");
context.start();
DemoService demoService = (DemoService) context.getBean("demoService");
String result = demoService.sayHello("World");
System.out.println(result);
}
}运行并查看结果
- 启动 Zipkin Server。
- 启动
ProviderApp。 - 启动
ConsumerApp。
在 Zipkin 的 Web UI 中(http://localhost:9411),你可以看到 Dubbo 调用的链路追踪信息。
总结
通过以上步骤,我们成功在 Dubbo 中集成了 Zipkin,实现了分布式系统的全链路追踪。这对于排查问题、分析系统性能瓶颈非常有帮助。希望本文能帮助你在实际项目中更好地使用 Dubbo 和 Zipkin。